
Wprowadzenie do Hasura GraphQL Engine dla dynamicznych interfejsów API z PostgreSQL
Opublikowany: 2019-11-07Ogólnie rzecz biorąc, w ciągu ostatnich lat interfejsy API REST były krytykowane jako nieelastyczne, a jednocześnie radzą sobie z szybko zmieniającymi się wymaganiami technologicznymi. Patrząc wstecz, wielu uważa, że GraphQL został stworzony, aby sprostać potrzebie dodatkowej elastyczności i wydajności w rozwoju API. W ten sposób łagodzi braki interfejsów API REST. W wyniku przejścia Facebooka z aplikacji HTML5 na bardziej niezawodne i natywne konfiguracje, GraphQL zyskał na popularności i adopcji w ciągu ostatnich pięciu lat nie bez powodu. W tym blogu zagłębimy się w fenomen GraphQL, PostgreSQL, a później przedstawimy dokładne wprowadzenie do silnika Hasura GraphQL. We fragmencie, relacja i ekosystem Hasura GraphQL Engine-PostgreSQL.
GraphQL: bunt na Facebooku
Chociaż wielu uważa, że GraphQL powstał jako bunt wobec interfejsów API REST, może to być dalsze od prawdy. Jak na ironię, został stworzony, aby po prostu zaspokoić wewnętrzną potrzebę na Facebooku. Pierwotnie zaprojektowany i otwarty przez zespół Facebooka, GraphQL jest często mylony jako technologia bazy danych. Zasadniczo, pomimo błędnego przekonania, GraphQL jest technicznie językiem zapytań dla interfejsów API, a nie baz danych. W konsekwencji zmniejsza złożoność budowania interfejsów API, abstrahując wszystkie żądania do jednego punktu końcowego. W przeciwieństwie do tradycyjnych interfejsów API REST, GraphQL jest deklaratywny, co oznacza, że zwracane jest wszystko, co jest wymagane. Chociaż, aby uzyskać trochę więcej kontekstu, musimy cofnąć się o krok i ponownie odwiedzić interfejsy API REST.
Architektura REST
Zazwyczaj interfejsy API to reguły, procedury lub protokoły, które określają sposób interakcji komponentów oprogramowania. Representational State Transfer (REST) jest w zasadzie architekturą projektowania interfejsu API zwykle wykorzystywaną w implementacji usług internetowych, w których wszystko jest uważane za „zasób”. Niestety metodologia RESTful była konsekwentnie ograniczana do zajmowania się pojedynczymi zasobami. W związku z tym, jeśli potrzebne były dane pochodzące z dwóch lub więcej zasobów, na przykład postów i użytkowników, wymagane byłyby wielokrotne podróże do serwera, aby zebrać wszystko, co jest potrzebne. Ponadto REST napotkał problemy z pobieraniem „nad” i „poniżej”. Wszystko to nie było idealne, zwłaszcza w obliczu pojawienia się większej liczby aplikacji opartych na danych obsługujących duże zestawy danych łączące powiązane zasoby. Co może wyjaśniać kłopoty, z jakimi zmierzył się Facebook.
W związku z tym potrzeba architektury API, która przyjęłaby bardziej elastyczne i progresywne podejście.
Tworzenie alternatywy
Alternatywnie GraphQL nie myśli o danych w kategoriach adresów URL zasobów, kluczy pomocniczych lub tabel, ale w kategoriach wykresu obiektów i modeli wykorzystujących NSObjects lub JSON. W szczególności GraphQL nie wymaga dedykowanych punktów końcowych na przypadek użycia, ponieważ różne możliwości i przypadki użycia mogą być reprezentowane w jednym „wykresie”. Używając języka zapytań GraphQL, możesz dokładnie opisać, jak powinna wyglądać odpowiedź, dzięki czemu nie są potrzebne żadne dodatkowe objazdy serwera. Jako język zapytań warstwy aplikacji jest przeznaczony do interpretowania ciągu znaków z serwera/klienta i zwracania tych danych w stabilnym, zrozumiałym i przewidywalnym formacie. To po prostu narzędzie do lepszej konsolidacji danych.
Prostota, stabilność i wydajność.
Prawda jest taka, że nie wszystkie projekty wymagają GraphQL pomimo jego dobrze zdefiniowanego schematu, więc wiemy na pewno, że nie przesadzimy. Jeśli jednak mamy produkt korporacyjny, który opiera się na danych z wielu źródeł, na przykład MySQL, Postgres i innych API, to GraphQL jest lepszym rozwiązaniem. GraphQL szczyci się prostotą, zwłaszcza jeśli chodzi o pobieranie danych, ponieważ dane są zbierane pod wspólnym punktem końcowym lub wywołaniem. Zasadniczo, ponieważ klienci otrzymują dokładnie to, czego potrzebują, skutecznie zmniejsza to rozmiar każdego żądania wysyłanego przez klienta, co skutkuje aplikacjami o wysokiej wydajności. Ponieważ GraphQL ujednolica dane, które w innym przypadku wymagałyby wielu punktów końcowych, ułatwia złożone powtarzanie pobierania, a tym samym lepszą wydajność zapytań. W konsekwencji, z jego prostotą wiąże się większa stabilność zaplecza, planowanie, budowa, wykonanie i ciągłość działania w czasie.
Zalety GraphQL
W skrócie, GraphQL umożliwia ekstrakcję danych za pomocą łatwo zrozumiałych zapytań, umożliwia szybkie tworzenie lekkich i szybkich aplikacji, ponieważ dostęp do danych jest bardziej bezpośredni niż przez serwer. Co więcej, umożliwia pobieranie kilku zasobów za pomocą jednego zapytania bez używania kilku adresów URL lub łączenia zasobów przy użyciu jednego punktu końcowego dla wszystkich danych. Pamiętaj, że dane są definiowane na serwerze za pomocą schematu opartego na wykresie, więc są dostarczane jako pakiet, a nie za pośrednictwem wielu wywołań. Pozwala to zwiększyć operacyjną agregację odpowiedzi API podczas rozwoju API.
To z kolei zmniejsza obciążenie zespołów programistycznych front-end, ułatwia wersjonowanie interfejsu API, upraszcza konserwację i oszczędza zapotrzebowanie na transfer danych. Ponadto zapewnia większą przewidywalność podczas odbierania danych, obsługuje deklaratywne pobieranie danych i łagodzi nadmierne i niedostateczne pobieranie danych. Zasadniczo nadmierne pobieranie występuje, gdy klient pobiera więcej informacji niż jest to faktycznie wymagane w aplikacji, podczas gdy niedostateczne pobieranie oznacza, że określony punkt końcowy nie dostarczył wystarczającej ilości informacji, co wymaga od klienta dodatkowych żądań w celu pobrania tego, czego potrzebuje.
Z technicznego punktu widzenia GraphQL to wrapper, który można zdefiniować, co oznacza, że nie trzeba w pełni zastępować systemu REST. Zasadniczo oznacza to, że GraphQL jest kompatybilny z systemami, z którymi są kompatybilne interfejsy API zorientowane na REST. Dodatkowo GraphQL umożliwia płynny i niezależny rozwój frontu i back-endu. Dzieje się tak, ponieważ gdy schemat jest dobrze zdefiniowany, zespoły pracujące na front-endzie i back-endzie są świadome określonej struktury danych. Wszystkie te korzyści są postrzegane jako korzystne przez wielu inżynierów zajmujących się pełnymi stosami. Wreszcie, GraphQL ma niesamowitą zdolność do dokładnej introspekcji i samodzielnej dokumentacji.

Przypadki użycia GraphQL w rozwoju API
Uważany za niezwykle potężny, GraphQL jest używany przez programistów Full-stack poszukujących stabilnej czytelności z dużą szybkością i indeksowaniem. W szczególności GraphQL jest przydatny przy opracowywaniu API, które wymaga dużej przepustowości danych. W rzeczywistości minimalizuje ilość danych wymaganych do przesyłania przez sieć. Jest to bardzo korzystne dla użytkowników mobilnych, urządzeń o niskim poborze mocy i niechlujnych sieci. To jeden z pierwszych powodów, dla których Facebook zaprojektował GraphQL. Wbrew pozorom GraphQL ma zastosowanie nie tylko w ogromnych, złożonych bazach danych, ale może tworzyć stosunkowo proste bazy danych z większą wydajnością.
Ponadto można go zastosować na różnych unikalnych platformach i platformach front-end, zapewniając heterogeniczny krajobraz utrzymywany za pomocą jednego interfejsu API, aby spełnić wszystkie wymagania użytkownika. Co więcej, ułatwia szybki rozwój funkcji, ponieważ znacznie zwiększa prędkość działania funkcji dla zespołów programistów z pełnymi stosami. Czyni to poprzez zmniejszenie komunikacji wymaganej między zespołami podczas opracowywania nowych funkcji, ponieważ programiści front-end mogą wysyłać żądania API, na przykład w celu wprowadzenia nowych funkcji lub zmiany istniejących bez konieczności czekania na dostarczenie przez programistów zaplecza. To krótkie podsumowanie GraphQL powinno na razie wystarczyć, gdy przejdziemy do naszego wprowadzenia do silnika Hasura GraphQL. Przejdźmy jednak do PostgreSQL, aby uzyskać nieco więcej kontekstu.
Co to jest PostgreSQL?
Jako darmowy, oparty na społeczności system zarządzania relacyjnymi bazami danych, PostgreSQL nie jest własnością żadnej pojedynczej firmy. Uważany za najpotężniejszy, wewnętrznie spójny dostępny RDBMS, Postgres został napisany w C i obsługuje wiele języków programowania, takich jak C/C++, JavaScript, Java, Python, R, Go, Lisp, .Net itp. Coraz bardziej preferowany spośród większości PostgreSQL jest bardziej bogaty w funkcje niż jego siostrzany MySQL, zyskując popularność dzięki swoim funkcjom, skalowalności i wydajności. PostgreSQL jest popularny w projektach, w których wymagania obracają się wokół złożonych procedur, skomplikowanych projektów, integracji na zamówienie i integralności danych.
Zalety Postgresa dla programistów Full-Stack
Ogólnie rzecz biorąc, funkcje takie jak wyszukiwanie pełnotekstowe, kolumny JSON, replikacja logiczna dają Postgresowi przewagę nad MySQL. Jest to optymalne rozwiązanie dla wymagań wydajności typowych komercyjnych baz danych, a jednocześnie umożliwia konsolidację kilku systemów bazodanowych w jeden przy mniejszych nakładach i kosztach. Ponadto jego nowsze funkcje dla Key-Value-Storage (typy kolumn JSON / JSONB) sprawiają, że jest to odpowiednia alternatywa dla baz danych NoSQL. Dodatkowo obsługuje klastrowanie lub architekturę master-slave, dzięki czemu dobrze nadaje się do środowisk podobnych do chmury. Ponadto, jego popularne rozszerzenie dla obcokrajowców pozwala na odpytywanie źródeł zewnętrznych bezpośrednio z poziomu PostgreSQL, gdy jest to konieczne. W szczególności najlepiej nadaje się do systemów wymagających wykonywania złożonych zapytań, hurtowni danych i dynamicznej analizy danych.
W rzeczywistości PostgreSQL lepiej obsługuje pewne funkcje, których MySQL nie obsługuje. Na przykład sprawdź ograniczenia, bogate typy danych (takie jak tablice, mapy, JSON), bogatsza obsługa geoprzestrzenna (PostGIS) i bogatsza obsługa pełnego tekstu. Dodatkowo obsługuje nieblokujące tworzenie indeksów, częściowe indeksy, wspólne wyrażenia tabelowe i bardziej dynamiczne funkcje analityczne. Niezależnie od tego, PostgreSQL oferuje natywną obsługę SSL dla połączeń w celu szyfrowania komunikacji klient/serwer, a także wbudowane rozszerzenie o nazwie SE-PostgreSQL, które zapewnia dodatkową kontrolę dostępu w oparciu o politykę SELinux.

Dzięki wielu bogatym funkcjom produktów klasy korporacyjnej PostgreSQL jest odpowiedni dla dużych systemów, w których dane wymagają uwierzytelnienia, a szybkość odczytu/zapisu ma kluczowe znaczenie dla powodzenia projektu. Co więcej, obsługuje również wiele wzmacniaczy wydajności, które są zwykle dostępne w zastrzeżonych rozwiązaniach. Należą do nich: współbieżność bez blokad odczytu, serwer SQL i obsługa danych geoprzestrzennych, aby wymienić tylko kilka.
Kolejną główną zaletą architektury Postgres jest jej wyjątkowa rozszerzalność. Umożliwia użytkownikom dodawanie funkcji, takich jak typy danych, metody dostępu do indeksu, języki programowania serwera, zewnętrzne opakowania danych (FDW) i ładowalne rozszerzenia bez zmiany podstawowego kodu systemu. Wykorzystuje nowoczesną architekturę procesora wielordzeniowego, dzięki czemu jego wydajność rośnie niemal liniowo wraz ze wzrostem liczby rdzeni. Jest to ważne Ogólnie rzecz biorąc, funkcje takie jak wyszukiwanie pełnotekstowe, kolumny JSON, replikacja logiczna dają Postgresowi przewagę nad MySQL. Jest to optymalne rozwiązanie dla wymagań wydajności typowych komercyjnych baz danych, a jednocześnie umożliwia konsolidację kilku systemów bazodanowych w jeden przy mniejszych nakładach i kosztach. Ponadto jego nowsze funkcje dla Key-Value-Storage (typy kolumn JSON / JSONB) sprawiają, że jest to odpowiednia alternatywa dla baz danych NoSQL. Dodatkowo obsługuje klastrowanie lub architekturę master-slave, dzięki czemu dobrze nadaje się do środowisk podobnych do chmury. Ponadto, jego popularne rozszerzenie dla obcokrajowców pozwala na odpytywanie źródeł zewnętrznych bezpośrednio z poziomu PostgreSQL, gdy jest to konieczne. W szczególności najlepiej nadaje się do systemów wymagających wykonywania złożonych zapytań, hurtowni danych i dynamicznej analizy danych.

Wady PostgreSQL
Ogólnie rzecz biorąc, jeśli masz ochotę na standardy ANSI SQL, rozważ PostgreSQL, ale jeśli wolisz standardy ODBC, wybierz MySQL. Niestety, Postgres od czasu do czasu traci wydajność w środowiskach produkcyjnych na żywo. Dodatkową wadą Postgresa jest fakt, że jego replikacja jest zaimplementowana na poziomie silnika pamięci masowej. To sprawia, że jest droższy niż replikacja MySQL, która jest bardziej dojrzała i zaimplementowana na „poziomie silnika zapytań”.
Wprowadzenie do silnika Hasura GraphQL
Ponieważ pokrótce omówiliśmy rozwój GraphQL API i PostgreSQL, powinniśmy mieć wystarczający kontekst do wprowadzenia do silnika Hasura GraphQL. Zasadniczo Hasura jest po prostu silnikiem GraphQL dla PostgreSQL RDBMS, zapewniającym uproszczony sposób ładowania i zarządzania rozwojem API GraphQL. Patrząc wstecz, Hasura jest obecnie jedynym łatwo dostępnym rozwiązaniem, które natychmiast dodaje GraphQL-as-a-Service do istniejących aplikacji opartych na PostgreSQL. Zasadniczo pomijając czasochłonne zadanie pisania kodu zaplecza, który przetwarza GraphQL.
Hasura uproszczona
Poświęćmy chwilę na dalsze uproszczenie Hasury. Zasadniczo API to interfejsy, które pozwalają żądać informacji (zapytanie), a tym samym odpowiadać, wysyłając dane JSON lub XML. Ta baza danych jest zwykle hostowana i pobierana z serwera. Tu właśnie pojawia się Hasura, aby uprościć sprawy. Z perspektywy czasu, silnik Hasura GraphQL to serwer, który obsługuje Twoje zapytania GraphQL w bazie danych Postgres. To skutecznie skraca czas przygotowania aplikacji do produkcji, umożliwiając łatwe tworzenie, przeglądanie i modyfikowanie tabel bazy danych za pomocą zaledwie kilku kliknięć. W konsekwencji umożliwia to programistom z pełnym stosem budowanie skalowalnych aplikacji GraphQL na PostgreSQL w krótszym czasie. Oszczędza to programistom tygodnie kodowania z góry i może zapobiec przedostawaniu się problematycznych błędów z wyciekiem danych do produkcji.
Jaki problem rozwiązuje Hasura w rozwoju API?
Ogólnie rzecz biorąc, Hasura upraszcza zarządzanie cyklem życia API podczas produkcji na dużą skalę, szczególnie w przypadku złożonych interfejsów API. Przede wszystkim silnik GraphQL przyciąga programistów z pełnym stosem, którzy mają zaległości w projektach rozwojowych API dla przedsiębiorstw wykorzystujących istniejące bazy danych PostgreSQL. Idealnie, ponieważ GraphQL pozwala na błyskawiczne cykle rozwoju API, Hasura zapewnia uproszczony sposób na stopniowe przejście organizacji na GraphQL, bez wpływu na istniejące aplikacje, bazy danych lub użytkowników. Oprócz lekkości i wysokiej wydajności, silnik jest wyposażony w interfejs administratora, który pozwala eksplorować interfejsy API GraphQL i wizualnie zarządzać schematem bazy danych i danymi.
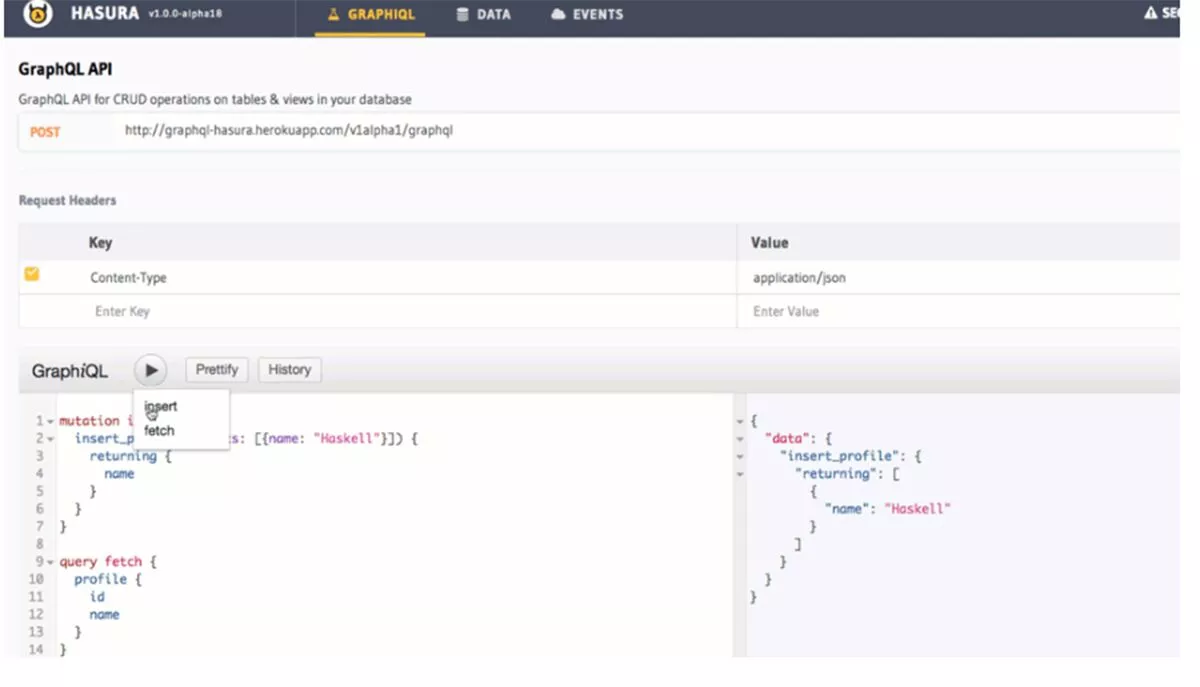
Zalety Hasury
Po pierwsze, Hasura posiada solidny, stabilny model zarządzania zmianami bazy danych lub „migracjami”. Jest to korzystne, ponieważ zarządzanie schematem bazy danych jest często trudne. Na przykład zadania takie jak; śledzenie zmian w czasie i kojarzenie zmian schematu z ulepszeniami API (zarządzanie schematem). Co więcej, rutynowe zadania, takie jak konserwacja skryptów, które mogą wdrożyć nową bazę danych lub cofnąć zmiany, mogą okazać się nużące i powodować trudne do zdiagnozowania błędy lub przestoje. Jako pozytywna uwaga, komponenty migracji bazy danych Hasura są zwykłym SQL, dlatego można je przenosić poza zestaw narzędzi Hasura. Podsumowując, Hasura ma świetne funkcje zarządzania schematami i nie musisz pisać kodu do obsługi połączeń z gniazdem internetowym.
Po drugie, silnik Hasura GraphQL ułatwia pobranie wymaganych danych za pomocą jednego zapytania. Czyni to, umożliwiając dodawanie widoków jako relacji do tabel lub innych widoków. Ponadto umożliwia pisanie niestandardowych programów rozpoznawania nazw z łączeniem schematów i integracją funkcji bezserwerowych lub interfejsów API mikrousług, które są wyzwalane przez zdarzenia bazy danych. Może się to przydać i ułatwia budowanie aplikacji 3factor. W rzeczywistości Hasura to niezwykle lekki silnik. Z perspektywy czasu zużywa tylko do 50 MB pamięci RAM, nawet obsługując ponad 1000 żądań na sekundę. Genialny zwrot z inwestycji!
W szczególności Hasura dodatkowo ułatwia szczegółową autoryzację na poziomie danych API i uwierzytelnianie. Umożliwia połączenie z preferowanym dostawcą uwierzytelniania za pośrednictwem webhooka, JWT, Auth0 lub niestandardowych implementacji. I tak, określenie ról dla użytkowników, określające kto może mieć dostęp do różnych danych, np. admin, anonimowi użytkownicy itp. Generalnie jego granularny system kontroli dostępu opiera się na strukturze tabeli bazy danych podobnej do schematu GraphQL. Dodatkowo niestandardowe reguły uprawnień są ściśle określone na podstawie operacji i wartości bazy danych.
Wreszcie, Hasura znakomicie obsługuje wydajne stronicowanie za pomocą prostego, podobnego do SQL modelu przesunięcia/limitu. Na przykład wykorzystuje model kontroli dostępu, aby ograniczyć liczbę wierszy zwracanych dla danego zapytania. Jego model umożliwia dostosowanie limitów według roli. Na przykład użytkownicy, którzy narzucają znacznie wyższą częstotliwość żądań, są ograniczeni do mniejszych limitów wierszy. Pozwala to uniknąć obciążania bazy danych i silnika GraphQL. Co więcej, Hasura nie ogranicza Cię tylko do GraphQL. Nadal możesz uruchamiać REST lub inne mikrousługi inne niż GraphQL w odniesieniu do tabel Postgres, którymi zarządza Hasura. Jest to możliwe dzięki automatycznemu łączeniu schematów Hasury. Pozwala to na połączenie usługi GraphQL innej niż Hasura i zaplecza w jeden ujednolicony schemat, łącząc nowe, zarządzane przez Hasura interfejsy API ze starszymi interfejsami API i danymi.
Przypadki użycia Hasury
Odpowiedni dla środowisk o wysokiej wydajności, Hasura Engine oferuje szybkość, automatyzując implementację GraphQL-Postgres na istniejących bazach danych. W konsekwencji zapewnia to firmom, które już używają Postgresa, mniej stresujący i przyrostowy sposób przejścia na GraphQL poprzez połączenie istniejących tabel w „wykres”. Hasura sprawnie zajmuje się łączeniem schematów, umożliwiając łatwe zastosowanie niestandardowej logiki biznesowej. Dzięki zdalnym schematom GraphQL, Hasura może być wykorzystana jako brama dla niestandardowej logiki biznesowej, umożliwiając zapisywanie na serwerach GraphQL w Twoim ulubionym języku, a następnie udostępnianie danych w jednym punkcie końcowym. Co więcej, Hasura ma świetną składnię zapytań i mutacji z wbudowanymi zapytaniami na żywo zwanymi subskrypcjami w GraphQL.
Kilka ograniczeń Hasury
Niestety, model systemu kontroli dostępu Hasury nie będzie w pełni działał dla każdej aplikacji. Na przykład nie obsługuje w pełni autoryzacji dostępu API na poziomie poszczególnych parametrów wejściowych. Nie wspominając już o tym, że w większości przypadków ogranicza się to do bazy danych Postgres wymagającej migracji. Choć nieistotne, komunikaty o błędach zwracane przez API GraphQL w przypadku zniekształconych żądań są dość nieprzyjazne dla Hasury. W przeciwnym razie niewiele jest rzeczy, których Hasura nie może zrobić, jak widzieliśmy w tym wprowadzeniu do Hasura GraphQL Engine.
Wniosek
Podsumowując, wraz z rozwojem GraphQL, będzie to kwintesencja dalszego uproszczenia rozwoju API w przedsiębiorstwach w celu budowania w skali internetowej. Dzięki szybkiemu wdrażaniu GraphQL na szeroką skalę w różnych branżach, Hasura ma potencjał do dalszej automatyzacji tworzenia i zarządzania interfejsami API za pomocą standardowych technologii branżowych, GraphQL i Postgres. Hasura upraszcza tworzenie backendów CRUD (Tworzenie, odczytywanie, aktualizowanie i usuwanie) GraphQL. Co ważniejsze, Hasura jest zdecydowanie najlepszą i jedyną opcją, jeśli zaczynasz od zera z API i Postgresem zorientowanym na GraphQL, bez pisania kodu zaplecza. W przypadku jakichkolwiek pytań lub konsultacji dotyczących możliwości biznesowych GraphQL i Hasura, skontaktuj się z nami. To tyle, jeśli chodzi o nasze wprowadzenie do Hasura GraphQL Engine.