
Czy Spark jest dla Nosql
Opublikowany: 2023-02-05Spark to potężne narzędzie do pracy z danymi, zwłaszcza dużymi zbiorami danych. Został zaprojektowany z myślą o szybkości i wydajności oraz obsługuje różne formaty danych, w tym bazy danych NoSQL . Bazy danych NoSQL stają się coraz bardziej popularne, ponieważ dobrze nadają się do obsługi dużych ilości danych. Spark może pomóc w efektywnym wyszukiwaniu danych NoSQL i manipulowaniu nimi.
Do efektywnej pracy niezbędne jest zarządzanie bazami danych aplikacji przy użyciu Apache Spark i NoSQL ( Apache Cassandra i MongoDB). Celem tego bloga jest zapewnienie wskazówek dotyczących tworzenia aplikacji Apache Spark przy użyciu zaplecza NoSQL. Jest to park rozrywki, a TCP/IP sPark oferuje przejażdżki zarówno w CassandraLand, jak i MongoLand. Kiedy próbowaliśmy zapytać o dane DOE, nasza aplikacja Spark zaczęła obracać się poza własną osią. Lekcja jest taka, że kiedy pytasz Cassandrę, ważne są sekwencje klawiszy. CassandraLand oferuje również kolejkę górską Partitioner, która jest jedną z najpopularniejszych atrakcji. Podczas gdy klienci cieszą się jazdą kolejką górską, operatorzy kolejki mogą śledzić, kto jechał nią każdego dnia, przechowując swoje informacje.
W pierwszej lekcji omówimy zarządzanie połączeniami MongoDB. Kiedy musisz zaktualizować informacje o parku, takie jak nowy status członkostwa w parku Departamentu Energii, możesz użyć indeksów mongo . MongoDB i Spark powinny być używane, aby zapewnić prawidłowe zarządzanie połączeniem, a także indeksy w określonych przypadkach.
Apache Spark to popularny system przetwarzania rozproszonego, który jest open-source i zbudowany do użytku w dużych obciążeniach danych. Ta funkcja, oprócz buforowania w pamięci i zoptymalizowanego wykonywania zapytań, umożliwia szybkie zapytania analityczne dotyczące dużych ilości danych.
Dzięki prawie takiemu samemu kodowi jest bardziej wydajny i wszechstronny, umożliwiając jednoczesne przetwarzanie danych wsadowych i danych w czasie rzeczywistym. W rezultacie starsze narzędzia Big Data stają się coraz bardziej przestarzałe ze względu na brak tej funkcjonalności.
Jakim typem bazy danych jest Spark?
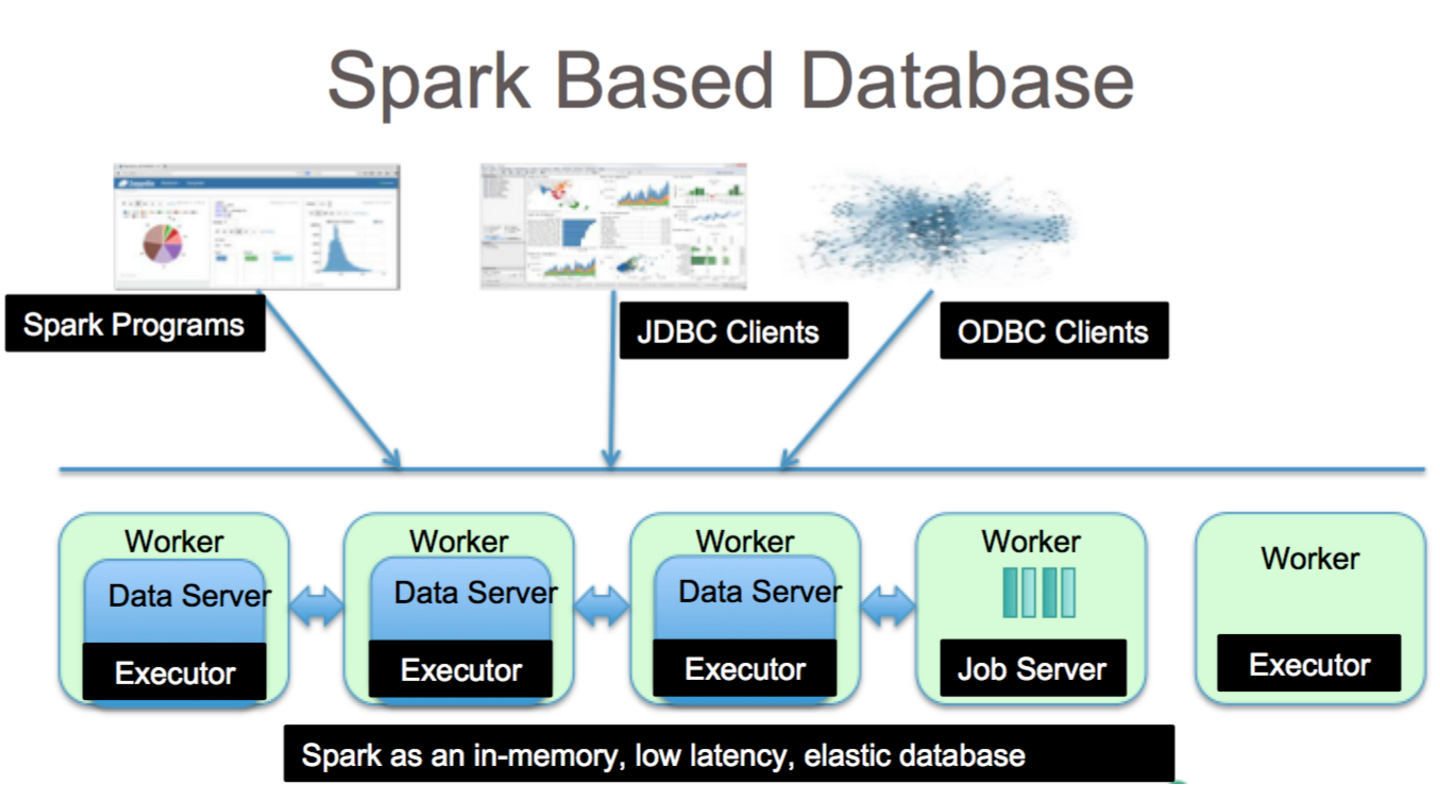
Apache Spark to platforma przetwarzania danych, która może obsługiwać dane z różnych repozytoriów danych, w tym (HDFS), baz danych NoSQL i relacyjnych baz danych.
Chociaż pojawiło się wiele cykli szumu wokół relacyjnych baz danych, nadal będą one popularne, niezależnie od najnowszych postępów i rozwoju baz danych NoSQL. Z biegiem czasu przechowywanie danych w relacyjnych bazach danych stawało się coraz trudniejsze. W tym artykule przyjrzymy się niektórym znaczącym postępom w wykorzystaniu mocy relacyjnej bazy danych w skali globalnej. Kiedy został wydany po raz pierwszy, interfejs między Spark i Big Data Analysis był minimalny. Wiele osób napisało dużo kodu w celu uruchomienia tego programu, który był potężny, ale stosunkowo wolny. Użytkownicy będą mogli z łatwością łączyć te dwa modele w bazie danych Spark SQL . Akceptuje również szeroki zakres formatów danych z różnych źródeł.
Najbardziej aktywny jest projekt open source Apache Spark, w którym biorą udział setki współpracowników. Oprócz tego, że jest darmowym projektem open source, Spark SQL zaczął zyskiwać popularność w głównych branżach. Oprócz Spark SQL około dwie trzecie klientów usługi Databricks Cloud (usługa hostowana z uruchomioną platformą Spark) korzysta z innych języków programowania. Po zakończeniu naszego pierwszego studium przypadku w tym praktycznym studium przypadku zademonstrujemy, jak zastosować kostki danych do przypadku. Spark DataFrame to zestaw wierszy (typów wierszy), które są dystrybuowane z tym samym schematem. Każda kolumna w zestawie danych jest oznaczona nazwą. API DataFrame umożliwia programistom integrację kodu proceduralnego i relacyjnego.
Spark może również obsługiwać zaawansowane funkcje, takie jak UDF. Tabela w relacyjnej bazie danych jest analogiczna do ramki danych w bazie danych ramek danych, ale wymaga więcej optymalizacji. Można nimi manipulować w taki sam sposób, jak natywne kolekcje rozproszone (RDD) Sparka. Ogólnie rzecz biorąc, zapytanie Spark SQL jest szybsze niż zapytanie Shark i jest bardziej konkurencyjne w stosunku do Impulsy. W zapytaniu 3a, gdzie selektywność zapytań powoduje, że jedna z tabel jest bardzo mała, istnieje znacząca różnica między Impala i Impala.

To fantastyczne narzędzie do analizy danych za pomocą Spark SQL. Dostęp do składni HiveQL, Hive SerDes i HiveDFs można uzyskać za pośrednictwem składni HiveQL, a także Hive SerDes i HiveDFs. Metastores Hive , SerDes i UDF zostały już zaimplementowane. Pomimo tego, że Spark jest bazą danych, jest również bazą danych NoSQL. W rezultacie podczas tworzenia zarządzanej tabeli w Spark będziesz mógł używać różnych narzędzi zgodnych z SQL do przechowywania danych. Wyrażenia SQL mogą być używane do uzyskiwania dostępu do tabel w Spark przez połączenie z JDBC za pośrednictwem łączników z jdbc.org. W rezultacie możesz także korzystać z narzędzi innych firm, takich jak Tableau, Talend i Power BI. Możliwość korzystania ze Sparka jest idealna do analizy danych i jest użytecznym narzędziem dla wielu branż.
Spark Sql: najlepsze z obu światów
Wypełnia lukę między dwoma wspomnianymi wcześniej modelami, modelami proceduralnymi i relacyjnymi, poprzez włączenie dwóch podstawowych komponentów. W rezultacie możesz wykonywać operacje relacyjne na dużą skalę na zewnętrznych źródłach danych i wbudowanych kolekcjach rozproszonych platformy Spark za pomocą interfejsu API DataFrame.
Co to jest iskra w bazie danych? Jest to platforma typu open source, która wykorzystuje uczenie maszynowe, interaktywne przetwarzanie zapytań i obciążenia w czasie rzeczywistym. Ta firma nie ma własnego systemu przechowywania; zamiast tego wykorzystuje analizy innych systemów pamięci masowej, takich jak HDFS, Amazon Redshift, Amazon S3, Couchbase i inne, oprócz własnych. Jeśli chodzi o przetwarzanie danych strukturalnych, Spark SQL to nie tylko baza danych; to też moduł Zdecydowana większość jest napisana w DataFrame, które są programistycznymi abstrakcjami, które działają w połączeniu z zapytaniami SQL.
Jaki jest typ sql SQL dla „sparksql”? Hive SQL obsługuje składnię HiveQL, a także Hive SerDes i UDF, umożliwiając dostęp do utworzonych wcześniej magazynów Hive. Używanie istniejących magazynów metadanych Hive, SerDes i UDF w Spark SQL nie jest trudne.
Czy Mongodb może uruchomić Spark?
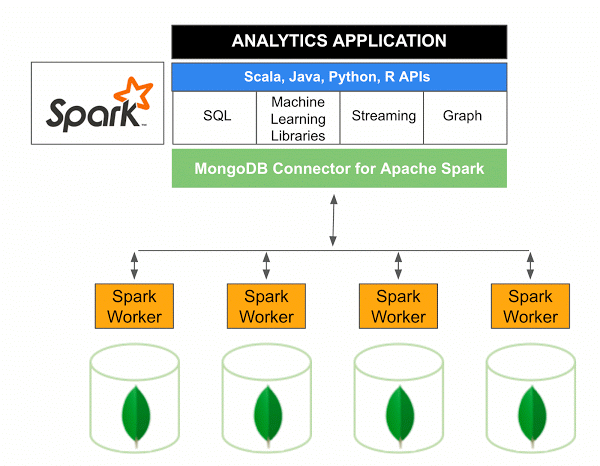
Wersja 10.0 złącza MongoDB dla Apache Spark obejmuje obsługę strumieniowania strukturalnego Spark za pośrednictwem nowego interfejsu API źródeł danych Spark w wersji 2, a także implementację nowego interfejsu API źródeł danych Spark w wersji 2.
Złącze MongoDB dla Spark to projekt open source, który umożliwia zapisywanie danych z MongoDB i odczytywanie ich z MongoDB przy użyciu Scali. Ze względu na metody użytkowe konektorów interakcje między Spark i MongoDB są uproszczone, dzięki czemu jest to potężna kombinacja do tworzenia zaawansowanych aplikacji analitycznych. Korzystając z wbudowanych funkcji replikacji i dzielenia na fragmenty, Spark można wdrożyć w różnych obciążeniach, które korzystają z baz danych MongoDB .
Spark: szybki sposób tworzenia aplikacji bogatych w dane
Z pomocą Spark, potężnego narzędzia, możesz szybko tworzyć bardziej funkcjonalne aplikacje. Włączając MongoDB, programiści mogą przyspieszyć proces programowania, wykorzystując technologię pojedynczej bazy danych. Co więcej, Spark jest natywny dla chmury i obejmuje obsługę magazynów danych NoSQL , dzięki czemu idealnie nadaje się do aplikacji intensywnie korzystających z danych.