
Kafka: doskonały wybór dla brokerów wiadomości w mikrousługach
Opublikowany: 2022-11-19Kafka to rozproszona platforma streamingowa. Jest często używany do agregacji dzienników, przetwarzania strumieni w czasie rzeczywistym i pozyskiwania zdarzeń. Ostatnio Kafka zyskuje na popularności jako broker wiadomości dla mikroserwisów. Kafka nie jest tradycyjną kolejką komunikatów, jak ActiveMQ czy RabbitMQ. Nie ma centralnego serwera, który przechowuje wszystkie wiadomości. Zamiast tego wykorzystuje model publikowania-subskrybowania. Wiadomości są przechowywane w tematach, a każdy temat może mieć wiele partycji. Kafka jest wysoce dostępna i skalowalna. Może obsłużyć miliardy wiadomości dziennie. Kafka jest również bardzo szybki. Może przetwarzać wiadomości w czasie rzeczywistym. Kafka to świetny wybór do budowania brokera komunikatów dla mikroserwisów. Jest wysoce dostępny, skalowalny i szybki.
Umożliwia to Kafka, system przesyłania wiadomości w czasie rzeczywistym. Strumienie danych są chronione przed zakłóceniami i mogą być dystrybuowane lub odporne na uszkodzenia. Magistrala integracji danych Kafka to protokół wymiany danych, który umożliwia szerokiemu gronu producentów i konsumentów udostępnianie danych. Możliwości Kafki są podobne do MongoDB i RDS, które służą jako bufor danych na końcu Twojej aplikacji.
KSQL, język skryptowy oparty na języku SQL, służy do analizowania i przetwarzania danych przesyłanych strumieniowo w czasie rzeczywistym w Apache Kafka . KSQL zawiera Interaktywną Szkielet Przetwarzania Strumieniowego, który ma na celu umożliwienie wykonywania czynności Przetwarzania Strumieniowego, takich jak agregacja danych, filtrowanie, łączenie, sesjonowanie, okienkowanie i tak dalej.
To coś więcej niż tylko doskonały broker wiadomości, jak pokazał Apache Kafka. Implementacja frameworka ma wiele funkcji podobnych do bazy danych, które sprawiają, że nadaje się do użycia w bazie danych. W rezultacie służy teraz jako zapis zdarzenia biznesowego, zamiast polegać na relacyjnych bazach danych.
Aplikacja Kafka oszczędza czas i energię, przesyłając strumieniowo dane z MongoDB w prosty i wydajny sposób. MongoDB jest wymagane, aby przedsiębiorstwa mogły publikować duże ilości danych innym subskrybentom, a także zarządzać wieloma strumieniami danych. Usługa Kafka MongoDB Connection umożliwia programistom tworzenie wielu asynchronicznych strumieni za pomocą MongoDB, które jest popularnym narzędziem branżowym.
W bazie danych jako model służy Apache Kafka. Setki firm używają go do udzielania gwarancji ACID i wykonywania zadań o znaczeniu krytycznym. Jednak w większości przypadków Kafka nie jest tak konkurencyjna jak inne bazy danych.
Jakim typem bazy danych jest Kafka?

Kafka to rodzaj bazy danych, która służy do przechowywania i pobierania wiadomości. Jest to system rozproszony zaprojektowany tak, aby był skalowalny i odporny na awarie.
Jest to platforma przetwarzania strumieniowego typu open source napisana w Scali i Javie, która jest częścią projektu Kafka Apache Software Foundation. Strumień w informatyce to zbiór elementów informacji, które są udostępniane w czasie. Strumienie można zdefiniować jako elementy na taśmie przenośnika przetwarzane pojedynczo. Strumienie, w swojej najbardziej podstawowej formie, mogą być serią pozornie niezwiązanych ze sobą wydarzeń. Koncepcje pozyskiwania zdarzeń różnią się od koncepcji hurtowni danych i analizy danych, do których przyzwyczajeni są programiści. Jak używać Kafki jako bazy danych? Blue to firma, która zgadza się na umowę.
Według Team Red programiści popełniają ogromny błąd, przechodząc z konwencjonalnych baz danych na Kafkę. Według Martina Kleppmanna przesłanie Team Red, że Kafka jest dla wszystkich, jest protekcjonalne. Problem, jaki Team Red ma z Kafką i strumieniami, polega na tym, że mają problem z programistami wyrzucającymi RDMS. Kiedy prezentowany jest stały dziennik zdarzeń, zawsze będzie on miał swój kontekst historyczny, co ułatwi jego audyt. Administracja bazą danych ma wiele zalet, ale jest też jednym z jej najtrudniejszych aspektów. Tradycyjna baza danych działa na dwa zupełnie różne sposoby: łączy odczyty i zapisy. Kluczowe znaczenie dla programistów ma utrzymanie i synchronizacja zduplikowanych danych w wielu tabelach.
Skala zmienia wzór w miarę upływu czasu. Strumienie wyróżniają się wyraźnym rozróżnieniem między obawami czytelników i pisarzy. Nie ma związku między tym, jak szybko Kafka zapisuje do pliku, a tym, jak szybko Elastic Search może przesyłać do niego aktualizacje. W rezultacie użytkownicy Kafki przetwarzają logi w celu wygenerowania różnych zmaterializowanych widoków. Sprawienie, by widoki zmaterializowane działały jako wygodny mechanizm buforowania, wiąże się z pewnymi kosztami początkowymi. Zmaterializowane widoki, oprócz przechowywania własnych danych i skalowania, są ważnymi składnikami infrastruktury. Dla 99% firm DBMS to najlepsza podstawa.
Twoja aplikacja może należeć do tej kategorii i możesz mieć prawo do nowatorskiej architektury opartej na Twoim doświadczeniu. Wiele krytycznych funkcji zostanie utraconych, jeśli zastąpisz bazy danych dziennikami. Funkcje obejmują ograniczenia klucza obcego, transakcje atomowe (wszystko albo nic) oraz techniki izolacji proceduralnej, które pomagają w problemach ze współbieżnością. Arjun zakłada, że integralność Twojej aplikacji jest utrzymywana przez cały czas. Podstawowe funkcje, które większość ludzi uważa za oczywiste, stają się dodatkowymi obowiązkami podczas pracy nad transmisjami. Bardzo ważne jest oddzielenie intencji od pisemnego oświadczenia. Typową konfiguracją jest użycie Kafki wraz z systemem przechwytywania zmian danych.
Według Team Red funkcje integralności danych w bazach danych mają kluczowe znaczenie dla uzyskania kontroli nad danymi. Transakcje muszą być odizolowane od konwencjonalnych baz danych, aby mogły być brane pod uwagę. W rezultacie pojedynczy tekst może być kosztowny. Jeśli Twoja aplikacja nie radzi sobie z ilością kosztownych zapisów, możesz być zmuszony do migracji do bardziej konwencjonalnej bazy danych. Team Red nie wspomina, że używanie bazy danych przed Kafką ogranicza jej najlepsze funkcje.
Zalety tego projektu są znaczące w porównaniu z tradycyjnymi systemami przesyłania wiadomości. Pierwszą zaletą Kafki jest to, że może obsłużyć dużą liczbę żądań. Ponadto, ponieważ dane są zapisywane na dysku tylko wtedy, gdy są potrzebne, Kafka może obsłużyć ogromne ilości danych.
SQL Server to narzędzie bazy danych, które należy do kategorii narzędzi. To podręczne urządzenie jest wszechstronne i niezawodne, ale czasami może być trudne w użyciu. Zarówno Kafka, jak i Azure to niezwykle wydajne platformy, ale Kafka jest skalowana w górę, podczas gdy Azure jest skalowana w dół.
SQL Server to doskonałe narzędzie dla firm, które wymagają przechowywania dużych ilości danych, ale może nie być najlepszym wyborem dla tych, którzy wymagają szybkiego skalowania lub dużej przepustowości. Dla firm, które muszą przetwarzać duże ilości danych bez uszczerbku dla wydajności, Kafka jest lepszym wyborem niż SQL Server.
Kafka: rozproszony system pamięci masowej dla telemetrii szeregów czasowych
Kafka Distributed Storage System, który wykorzystuje model oparty na tematach, przechowuje dane. Dane mogą być przechowywane w modelu opartym na tematach bazy danych Kafka, a nie w relacyjnej bazie danych. Zachowuje się podobnie do kolejki w Kafka Topic , ale nie w taki sam sposób jak kolejka. Może przechowywać dużą liczbę szeregów czasowych w ramach Kafki, a nie w bazie danych szeregów czasowych.
Jaka jest różnica między Kafką a Mongodbem?

Jest to rozproszona, partycjonowana i replikowana usługa dziennika zatwierdzeń oparta na systemie rozproszonym. Pomimo swojej unikalnej konstrukcji jest ważnym elementem systemu przesyłania wiadomości. Z drugiej strony MongoDB jest opisywany jako „Baza danych gigantycznych pomysłów”.
Ponieważ Kafka nie obsługuje kolejkowania po wyjęciu z pudełka, musisz włamać się do konsumenckiej wersji systemu. Jeśli wymagana jest relacyjna baza danych, bardziej przydatne może być inne narzędzie. MongoDB to doskonały wybór z wielu powodów, w tym łatwości użytkowania i elastyczności. Dostępna jest obsługa użytkowników Apache. Confluent ma Kafkę (jeśli chcesz zapłacić), która została utworzona na Linkedin w tym samym czasie co projekt Kafka. Posiadanie dostawcy, który wykonuje automatyczne kopie zapasowe i automatycznie skaluje klaster, jest niezwykle wygodne. Jeśli nie masz administratora systemu lub administratora baz danych, który zna MongoDB, dobrym pomysłem jest skorzystanie z usług firmy zewnętrznej, która specjalizuje się w hostingu MongoDB.
Kafka, w swojej najbardziej podstawowej formie, ma pozwolić nam na kolejkowanie wiadomości. Mechanizm pamięci masowej Cassandry zapewnia stały czas zapisu danych bez względu na ich wielkość. MongoDB zapewnia niestandardową implementację map/redukcji, a także natywną obsługę Hadoop do analiz, podczas gdy Cassandra tego nie robi. Nie ma znaczenia, czy jest hostowane przez Ciebie, czy przez innego dostawcę, ponieważ koszt jest zwykle rozsądny.
Kafka vs. Tradycyjne systemy baz danych
Należy zauważyć, że istnieje kilka różnic między Kafką a tradycyjnym systemem baz danych.
Ponieważ Kafka jest platformą do przesyłania strumieniowego, może obsłużyć wysokie tempo pozyskiwania danych bez konieczności wcześniejszego przetwarzania.
Dane są zużywane przez odczyty z ogona, a nie odczyty z dysku podczas uruchamiania platformy Kafka.
Korzystanie z buforowania stron zmniejsza potrzebę wizyt w bazie danych w obie strony dla Kafki.
Aby wysłać dane do dalszych klientów, Kafka wykorzystuje komunikację pub/sub.
Co to jest baza danych Kafki
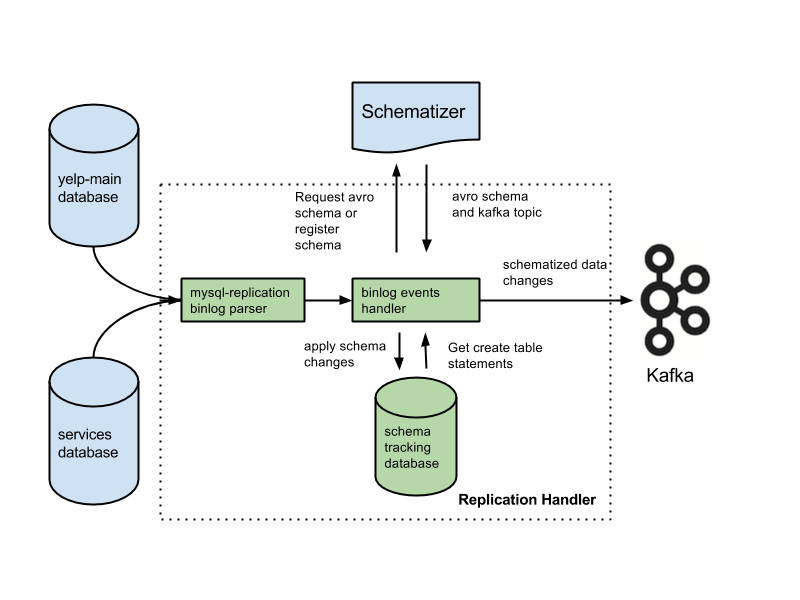
Kafka to baza danych, która jest często używana do przechowywania danych przesyłanych strumieniowo. Jest to system rozproszony zaprojektowany tak, aby był skalowalny i odporny na awarie. Kafka jest często używana do tworzenia potoków danych w czasie rzeczywistym i aplikacji do przesyłania strumieniowego. Może obsłużyć wysoką przepustowość i małe opóźnienia.
Broker wiadomości, taki jak Kafka, zyskał w ostatnich latach na popularności. Według zwolenników Kafka jest zmianą paradygmatu w zarządzaniu danymi. Bardzo ważne jest, aby pamiętać, że używanie Kafki jako podstawowego magazynu danych nie zapewnia izolacji. Każdy problem napotkany przez systemy bazodanowe zostanie rozwiązany w przyszłości. Hakerzy mogą kraść dane, wykorzystując luki w autonomicznych architekturach. Jeśli dwóch użytkowników spróbuje kupić ten sam przedmiot w tym samym czasie, obaj odniosą sukces i zabraknie zapasów dla nich obu. Te architektury, które wykorzystują funkcje podróży w czasie podczas uruchamiania urządzeń gaslight, opierają się na architekturach sterowanych zdarzeniami.
Zarządzanie dużymi wolumenami danych to doskonałe wykorzystanie Kafki. Transakcje nadal powinny być izolowane przy użyciu tradycyjnego systemu DBMS. Używaj baz danych OLTP do kontroli dostępu, CDC do generowania zdarzeń i modeluj kopie podrzędne w miarę pojawiania się widoków, aby wywrócić bazę danych do góry nogami.
Kafkę można również wykorzystać do przechowywania dużych ilości danych i codziennego ich przetwarzania. Możliwość przetwarzania dużych zbiorów danych w trybie wsadowym lub strumieniowym jest zaletą w stosunku do innych metod. Proces Kafka może służyć do pobierania plików dziennika z wielu serwerów i przechowywania ich na przykład w bazie danych lub indeksie wyszukiwania. Dostępny jest również interfejs API przesyłania strumieniowego, którego można używać do przetwarzania danych w czasie rzeczywistym.
Kafka kontra Sql
Ogólnie rzecz biorąc, Kafka i MySQL dzielą się na dwa typy: kolejki wiadomości i aplikacje bazodanowe. Większość programistów uważa Kafkę za rozwiązanie o wysokiej przepustowości, rozproszeniu i skalowalności, podczas gdy MySQL jest postrzegany jako najpopularniejszy ze względu na swoją prostotę, wydajność i łatwość użytkowania.
Komunikacja pub-sub w Kafce to rozproszony, odporny na awarie system o dużej przepustowości, który może obsługiwać duże ilości danych. MySQL to najpopularniejsza na świecie baza danych typu open source, która jest przeznaczona do użytku w systemach produkcyjnych o znaczeniu krytycznym i dużym obciążeniu. Rozwój uważa Kafkę za potężniejszą niż MySQL ze względu na jego wysoką przepustowość, rozproszoną architekturę i skalowalność; mając na uwadze, że SQL, Free i Easy to główne powody, dla których preferują go użytkownicy MySQL. Polecam PostgreSQL, jeśli chcesz zdobyć praktyczne doświadczenie z systemami zarządzania bazami danych (DBMS). W Vital Beats używamy Postgres przede wszystkim dlatego, że pozwala nam osiągnąć pożądaną równowagę między efektywnym zarządzaniem danymi a tworzeniem kopii zapasowych przy jednoczesnym wsparciu wiersza poleceń. Jeśli planujesz hostować swoją bazę danych lokalnie lub w chmurze, pierwszym punktem kontaktu są bazy danych PaaS (Platform as a Service). Ponieważ MongoDB zapisuje dane na tym samym poziomie co jeden dokument, spójność jest trudna bez transakcji.
Magazyny dokumentów, takie jak te znajdujące się w Amazon DynamoDB i AWS RedShift, bardzo różnią się od par klucz-wartość (lub magazynów kolumn) występujących w MongoDB. Wykonywanie zapytań przy użyciu bazy danych #Nosql jest szybsze i łatwiejsze, ponieważ skraca się czas programowania. Jako pierwszy pracownik w branży nieruchomości chciałbym wybrać bazę danych, która będzie bardzo produktywna przez długi czas. Jeśli uruchamiasz Aurora Postgres na AWS z wdrożeniem w jednym regionie, jest to jedna z najlepszych platform, które polecam. Jeśli używasz PostgreSQL w trzech środowiskach chmurowych, uzyskasz lepszą replikację wielu regionów. Jeśli skonfigurujesz je poprawnie, każda z tych trzech baz danych będzie działać wydajnie, skalowalnie i długoterminowo niezawodnie. Uber przeszedł z Postgres na MySql z różnych powodów, w tym z potrzeby bardziej sprawnego i niezawodnego systemu transmisji danych.
Dyrektor ds. technologii w OPS Platform stwierdził, że Postgres był najskuteczniejszym długoterminowym wyborem dla ich produktu ze względu na szybkość i łatwość obsługi. W porównaniu z MySQL 7.x transakcje są obsługiwane szybciej w MySQL 8.0. Czy baza danych jest bezpieczniejsza? Czy można losowo zmienić klucz szyfrowania? MySQL i MongoDB to dwie najpopularniejsze bazy danych typu open source. Oprócz łatwości przechowywania danych, MongoDB może służyć do przechowywania dużych ilości danych przychodzących za pośrednictwem sieci dystrybucji treści (CDN). Podstawową przewagą Postgres nad innymi obiektowymi bazami danych jest nacisk na rozszerzalność i zgodność ze standardami.
Można tworzyć regularne indeksy B-drzewa i skrótu, a także indeksy wyrażeń i częściowe (te, które wpływają tylko na część tabeli). Najbardziej podstawową różnicą między Redis i Kafką jest wykorzystanie przez nie ram wiadomości korporacyjnych. Szukam technologii, która jest natywna dla chmury, kiedy ją wybieram. Oprócz wykrywania usług, NATS może zastąpić równoważenie obciążenia, globalne multiklastry i inne operacje. Jedyne, czego Redis nie robi, to służy jako czysty broker wiadomości (w chwili pisania). W rezultacie jest to bardziej ogólny magazyn klucz-wartość w pamięci. Pomimo posiadania obszernej biblioteki muzycznej, moje utwory często trwają ponad dwie godziny.

Problem z przechowywaniem plików audio w wierszu bazy danych przez kilka godzin polega na tym, że nie można ich łatwo przeszukiwać. Jeśli wolisz, rozważ przechowywanie plików audio w usłudze przechowywania w chmurze, takiej jak Backblaze b2 lub AWS S3. Czy istnieje rozwiązanie wykorzystujące MQTT Broker w IoT World? Mieści się w jednym z centrów danych. Obecnie przetwarzamy je w celach związanych z alertami i alarmami. Naszym głównym celem jest stosowanie lżejszych produktów, które zmniejszają złożoność operacyjną i koszty konserwacji. Byłoby idealnie, gdybyśmy mogli zintegrować Apache Kafka z tymi dodatkowymi wywołaniami API stron trzecich.
Aplikacja RabbitMQ to doskonały wybór zarówno do ponawiania prób, jak i kolejkowania. Jeśli nie potrzebujesz, aby każda wiadomość była przetwarzana przez więcej niż jednego użytkownika, możesz użyć RabbitMQ. Nie ma sensu używać Kafki do dostarczania systemu z potwierdzeniami. Menedżer stanu zdarzeń Kafki, podobnie jak menedżer stanu utrwalonych zdarzeń, umożliwia przekształcanie i wysyłanie zapytań do różnych źródeł danych przy użyciu strumieniowego interfejsu API. Framework RabbitMQ jest idealny dla indywidualnego wydawcy lub subskrybenta (lub konsumenta) i uważam, że wymianę fanoutów można skonfigurować tak, aby umożliwić wielu konsumentom. Projekt Pushnami pokazuje, jak przeprowadzić migrację danych na żywo z jednej bazy danych do drugiej. Ponieważ każdy frontend (Angular), backend (Node.js) i frontend (MongoDB) jest natywny, wymiana danych była znacznie łatwiejsza.
Aby uniknąć warstwy tłumaczenia, pominąłem część relacyjną do hierarchicznej. Bardzo ważne jest, aby zachować skończony rozmiar obiektów MongoDB i używać poprawnych indeksów. Już w latach sześćdziesiątych XX wieku niektóre z najwcześniejszych elektronicznych dokumentów medycznych (EMR) wykorzystywały świnkę, bazę danych zorientowaną na dokumenty. MongoDB, która przechowuje do 40% całej dokumentacji szpitalnej, jest uważana za solidną medyczną bazę danych. Istnieją jednak bardzo sprytne metody wykonywania nieobsługiwanych natywnie zapytań geograficznych, które na dłuższą metę są bardzo powolne. Amazon Kinesis przetwarza setki tysięcy plików danych na sekundę z setek tysięcy źródeł. RabbitMQ ułatwia wysyłanie i odbieranie wiadomości z dowolnej aplikacji. Apache ActiveMQ jest szybki, obsługuje szeroką gamę klientów w różnych językach i jest niezawodnym językiem skryptowym. Dane Hadoop są przetwarzane przy użyciu szybkiego i uniwersalnego mechanizmu przetwarzania o nazwie Spark.
Kafka kontra Mongodb
Mongodb to potężna baza danych zorientowana na dokumenty, która ma wiele funkcji, które czynią ją dobrym wyborem dla różnych aplikacji. Kafka to wysokowydajna platforma do przesyłania strumieniowego, której można używać do tworzenia potoków danych w czasie rzeczywistym i aplikacji do przesyłania strumieniowego.
Transfery z MongoDB jako źródła do innych źródeł MongoDB lub innych źródeł MongoDB mogą być płynne dzięki aplikacji Kafka do MongoDB. Z pomocą MongoDB Kafka Connector nauczysz się, jak sprawnie przesyłać dane. Dzięki tej funkcji możesz utworzyć całkowicie nowy potok ETL dla swojej organizacji. Confluent oferuje różnorodne złącza, które działają jako źródło i ujście, umożliwiając użytkownikom przesyłanie danych między nimi. Konektory Debezium MongoDB są jednym z takich mechanizmów łączności, który umożliwia użytkownikom Kafka MongoDB łączenie się z bazą danych MongoDB. Zanim będziesz mógł uruchomić Confluent Kafka, musisz najpierw upewnić się, że działa w twoim systemie. Korzystając z funkcjonalności takich jak KStream, KSQL lub dowolnego innego narzędzia, takiego jak Spark Streaming, możesz analizować dane w Kafce.
Wprowadzanie danych do hurtowni wymaga zarówno ręcznych skryptów, jak i niestandardowego kodu. Platforma potoków danych Hevo bez kodu umożliwia tworzenie prostych systemów potoków danych bez kodowania. Przejrzysta platforma cenowa Hevo pozwala zobaczyć każdy szczegół Twoich wydatków na ELT w czasie rzeczywistym. Okres próbny trwa 14 dni i obejmuje wsparcie 24×7. Szyfrowanie typu end-to-end odbywa się przy użyciu najbardziej rygorystycznych certyfikatów bezpieczeństwa. Hevo może służyć do bezpiecznego przesyłania danych Kafki i MongoDB do 150 różnych źródeł danych (w tym 40 bezpłatnych źródeł).
Czym jest Kafka i Mongodb?
Złącze MongoDB Kafka to złącze zweryfikowane przez Confluent, które przechowuje dane z tematów Kafki jako ujście danych w MongoDB i publikuje zmiany w tych tematach jako źródło danych.
Plusy i minusy używania Kafki jako bazy danych
Która baza danych jest dobra dla Kafki? W zasadzie Kafkę można wykorzystać do stworzenia bazy danych. Rezultatem będzie zbadanie każdego głównego problemu, który nęka systemy zarządzania bazami danych od dziesięcioleci. System zarządzania bazą danych (DBMS) to rodzaj oprogramowania, które organizuje dane i przeszukuje je. Są wymagane w aplikacjach na dużą skalę i do przechowywania danych, do których dostęp musi mieć wielu użytkowników. DBMS dzieli się na dwa typy: relacyjne i nierelacyjne. Model relacyjny to standardowa metoda reprezentacji informacji w relacyjnym DBMS. Są popularne, ponieważ są proste w użyciu i mogą służyć do przechowywania danych zorganizowanych w tabele. System DBMS, który nie obsługuje modeli relacyjnych z użytkownikiem, nie jest tak wydajny, jak ten, który korzysta z innych modeli. Dane są również przechowywane w formatach innych niż tabele w celu wydajniejszego organizowania, takich jak strumienie danych. Model Kafki służy do tworzenia bazy danych, którą można wykorzystać do różnych celów. Przetwarzanie strumieniowe jest sercem Kafki, nowego modelu reprezentacji danych. Systemy zarządzania danymi (DMS) są kluczowym elementem zarządzania danymi. Jednak używanie Kafki jako bazy danych może być czasami trudne. Niektóre z najczęstszych problemów napotykanych przez DBMS to wydajność, skalowalność i niezawodność. George Fraser, dyrektor generalny Fivetran i Arjun Narayan, dyrektor generalny Materialise, są współautorami postu.
Baza danych trwałości Kafki
Bazy danych trwałości Kafka zapewniają sposób przechowywania danych w klastrze Kafka w wysoce dostępny i skalowalny sposób. Domyślnie kafka będzie używać bazy danych w pamięci do przechowywania danych, ale nie jest to odpowiednie dla wdrożeń produkcyjnych. Baza danych trwałości Kafka może służyć do zapewnienia bardziej niezawodnej opcji przechowywania danych Kafka.
LinkedIn stworzył open-source Apache kaffef w 2011 roku. Platforma ta umożliwia przesyłanie danych w czasie rzeczywistym przy bardzo małych opóźnieniach i przepustowości. W większości przypadków dane można importować i eksportować przez Kafka Connect z systemów zewnętrznych. Nowe rozwiązania mogą pomóc w rozwiązaniu problemów, takich jak nieefektywna wydajność pamięci masowej i niepełne wykorzystanie dysków. Pomimo wyzwań związanych z architekturą, lokalny flash jest doskonałym wyborem dla systemów Kafka. Ponieważ dostęp do każdego tematu w Kakfa można uzyskać tylko na jednym dysku, nastąpi wzrost niepełnego wykorzystania. Synchronizacja może być również trudna, co powoduje problemy z kosztami i wydajnością.
Gdy dysk SSD ulegnie awarii, dane z niego muszą zostać całkowicie odbudowane. Ta czasochłonna procedura zmniejsza wydajność klastra. Kafka najlepiej nadaje się do pamięci masowej opartej na NVMe/TCP, ponieważ spłaszcza kompromis między niezawodnością a wydajnością.
Kafka to fantastyczny system przesyłania wiadomości, ale nie jest to idealne rozwiązanie do przechowywania danych
Kafka to doskonały system przesyłania wiadomości, którego można używać do przechowywania danych. Jedną z opcji retencji Kafki jest czas retencji -1, który odnosi się do retencji przez całe życie. Jednak niezawodność Kafki znacznie odbiega od niezawodności tradycyjnej bazy danych. Należy zauważyć, że Kafka przechowuje dane na dysku, sumę kontrolną i replikuje w celu zapewnienia odporności na uszkodzenia, więc gromadzenie większej ilości przechowywanych danych nie spowalnia go. Kafki można używać do wysyłania i odbierania wiadomości, ale nie jest to najlepszy wybór do przechowywania danych.
Czym jest Kafka
Kafka to szybki, skalowalny, trwały i odporny na błędy system przesyłania wiadomości typu „publikuj-subskrybuj”. Kafka jest wykorzystywana w produkcji przez firmy takie jak LinkedIn, Twitter, Netflix czy Airbnb.
Kafka ma prosty i bezpośredni projekt. Jest to system rozproszony, który działa na klastrze maszyn i może być skalowany poziomo. Kafka została zaprojektowana do obsługi wysokiej przepustowości i małych opóźnień.
Kafka służy do tworzenia potoków danych i aplikacji przesyłanych strumieniowo w czasie rzeczywistym. Może służyć do przetwarzania i agregowania danych w czasie rzeczywistym. Kafka może być również używana do przetwarzania zdarzeń, rejestrowania i audytowania.
LinkedIn uruchomił Kafkę w 2011 roku, aby obsługiwać źródła danych w czasie rzeczywistym. Kafka jest obecnie używana przez ponad 80% osób z listy Fortune 100. Kafka Streams API to zaawansowana, lekka biblioteka zaprojektowana w celu umożliwienia przetwarzania w locie. Oprócz popularnych rozproszonych baz danych, Kafka zawiera abstrakcję rozproszonego dziennika zatwierdzeń. W przeciwieństwie do kolejek przesyłania komunikatów, Kafka jest wysoce elastycznym, odpornym na błędy systemem rozproszonym o wysokiej skalowalności. Na przykład można go wykorzystać do zarządzania dopasowywaniem pasażerów i kierowców w Uber lub dostarczania analiz w czasie rzeczywistym w British Gas. Wiele mikrousług opiera się na Kafce. Natywna dla chmury, kompletna iw pełni zarządzana usługa Confluent jest lepsza niż Kafka. Confluent ułatwia tworzenie zupełnie nowej kategorii nowoczesnych, sterowanych zdarzeniami aplikacji, łącząc dane historyczne i dane w czasie rzeczywistym w jedno ujednolicone źródło prawdy.
Z pomocą Kinesis możesz obsługiwać szeroki zakres strumieni danych, co czyni go potężną i wszechstronną platformą do przetwarzania strumieni. Jest to popularna platforma ze względu na swoją szybkość, prostotę i kompatybilność z szeroką gamą urządzeń. Ze względu na swoją niezawodność jest to jedna z najpopularniejszych platform streamingowych. Może obsługiwać duże ilości danych bez żadnych problemów ze względu na swoją trwałość. Ponadto, ponieważ jest to dobrze znana platforma, która jest szeroko używana i obsługiwana, łatwo jest znaleźć partnera lub integratora, który pomoże Ci zacząć z nią korzystać. Jeśli szukasz platformy do przesyłania strumieniowego, która jest zarówno potężna, jak i niezawodna, Kinesis to doskonały wybór.
Kafka: system przesyłania wiadomości, który zastępuje bazy danych
Przepływy danych w czasie rzeczywistym można dostosowywać do zmieniającego się środowiska danych za pomocą Kafki, systemu przesyłania wiadomości do tworzenia potoków danych i aplikacji przesyłanych strumieniowo w czasie rzeczywistym. Duże zbiory danych są przetwarzane za pośrednictwem strumieni zdarzeń w czasie rzeczywistym przy użyciu Kafki, która jest napisana w Scali i Javie. Połączenie Kafki można rozszerzyć z jednego punktu do drugiego, a także można go używać do przesyłania danych między źródłami. Platforma do strumieniowego przesyłania wydarzeń ma na celu zapewnianie strumieniowego przesyłania wydarzeń na żywo. Porównywanie baz danych z rozwiązaniami do przesyłania wiadomości, takimi jak Kafka, jest niesprawiedliwe. Dzięki funkcjom Kafki bazy danych nie są już potrzebne.
Kafka nie jest bazą danych
Kafka nie jest bazą danych, ale często jest używana w połączeniu z bazą danych. Jest to broker komunikatów, którego można używać do przesyłania komunikatów między różnymi komponentami systemu. Jest często używany do oddzielania różnych części systemu, aby mogły skalować się niezależnie.
Można zastąpić Apache Kafkę bazą danych, ale nie rób tego dla wygody. Odcinek Top Gear, w którym każdy z bohaterów dostał po 10 000 dolarów za zakup używanego włoskiego supersamochodu z silnikiem umieszczonym centralnie, przypomniał mi stary odcinek Top Gear, w którym każdy z bohaterów otrzymał po 10 000 dolarów. W 2011 roku LinkedIn wypuścił Kafkę, a ten odcinek został wyemitowany w tym samym roku. Pozwala na wykonywanie minimum trwałej wymiany wiadomości bez inwestowania we w pełni funkcjonalną platformę do przesyłania wiadomości. Podstawową przesłanką jest to, że istnieje podstawowa zasada. Utwórz tabelę (lub zasobnik, kolekcję, indeks, cokolwiek) dla każdego zdarzenia, które zostało zarejestrowane podczas procesu produkcyjnego. Regularnie sonduj bazę danych z instancji konsumenta, aktualizując stan konsumenta podczas jego przetwarzania.
Aby model działał prawidłowo, producenci i konsumenci powinni móc pracować równolegle. Rozważ użycie książki Kafki jako przewodnika i przechowywanie zapisów w nieskończoność, zamiast po prostu je czytać. Z drugiej strony rozłączne grupy konsumentów można wdrożyć poprzez powielanie rekordów przy wstawianiu, a następnie usuwanie rekordów po zużyciu. Kafka stosuje trwałe przesunięcia, aby umożliwić zdefiniowane przez użytkownika wachlowanie danych i obsługę wielu rozłącznych konsumentów. Aby zrezygnować z tej funkcjonalności, należy opracować usługę od podstaw. Wdrożenie koncepcji czyszczenia opartego na czasie nie jest trudne, ale konieczne jest przyjęcie logiki padlinożerców. Na Kafce istnieje szczegółowa kontrola nad wszystkimi aktorami (konsumentami, producentami i administratorami).
Może przetwarzać miliony rekordów na sekundę na serwerach towarowych i w chmurze bez żadnych problemów. Kafka jest zoptymalizowana pod kątem wysokiego poziomu przepustowości zarówno po stronie producenta, jak i konsumenta, w sensie niefunkcjonalnym. Używając Kafki, jest to rozproszony dziennik tylko do dołączania, który nie ma sobie równych w tej dziedzinie. W przeciwieństwie do tradycyjnych brokerów wiadomości, które usuwają wiadomości na etapie konsumpcji, Kafka nie czyści wiadomości po ich zużyciu. Przepustowość i opóźnienia bazy danych prawie na pewno będą wymagały znacznej poprawy poprzez zastosowanie specjalistycznego sprzętu i wysoce skoncentrowanego dostrajania wydajności. Rezygnacja z brokera może być atrakcyjna na pierwszy rzut oka. Korzystając z platformy wydarzeń strumieniowych, takiej jak Kafka, czerpiesz korzyści z ogromnego wysiłku inżynierów włożonego w jej budowę.
Aby mieć pewność, że jakiekolwiek rozwiązanie, które zdecydujesz się wdrożyć dzisiaj, będzie mogło być utrzymywane, musisz mieć pewność, że będzie ono utrzymywane w wysokim standardzie. Większość funkcji w magazynie zdarzeń można zaimplementować tylko za pomocą bazy danych. Nie ma jednego uniwersalnego sklepu z wydarzeniami; w większości przypadków każdy nietrywialny magazyn zdarzeń jest prawie na pewno implementacją na zamówienie, wspieraną przez jedną lub więcej gotowych baz danych. Możesz używać baz danych w dziedzinie organizowania danych w celu wydajnego wyszukiwania, ale powinieneś unikać ich używania do dystrybucji danych w czasie (prawie) rzeczywistym.