
MapReduce: model programowania dla dużych zbiorów danych
Opublikowany: 2023-01-08MapReduce to model programowania i powiązana z nim implementacja do przetwarzania i generowania dużych zbiorów danych za pomocą równoległego, rozproszonego algorytmu w klastrze.
Zmieniamy sposób, w jaki pracujemy z ogromnymi ilościami danych, korzystając z nowych technologii. Hurtownie danych, takie jak Hadoop, NoSQL i Spark, to jedni z najbardziej znanych graczy w tej dziedzinie. Administratorzy baz danych i inżynierowie/programiści infrastruktury należą do nowej rasy profesjonalistów, którzy specjalizują się w zarządzaniu systemami o wysokim poziomie zaawansowania. Zamiast bazy danych, Hadoop jest ekosystemem oprogramowania, który umożliwia przetwarzanie równoległe w postaci ogromnych plików. Technologia ta przyniosła znaczne korzyści w zakresie obsługi ogromnych potrzeb przetwarzania dużych zbiorów danych. W przypadku dużych transakcji danych przeciętny klaster Hadoop może potrzebować tylko trzech minut na przetworzenie dużej transakcji, która zwykle zajęłaby 20 godzin w scentralizowanym systemie relacyjnej bazy danych.
Klaster mapreduce to klaster z równoległym algorytmem i modelem programowania, który przetwarza i generuje duże zbiory danych w taki sam sposób, jak normalny klaster.
Ekosystem Apache Hadoop został zaprojektowany do obsługi przetwarzania rozproszonego i zapewnia niezawodne, skalowalne i gotowe do użycia środowisko. Moduł MapReduce tego projektu to model programowania używany do przetwarzania ogromnych zbiorów danych, które znajdują się w Hadoop (rozproszony system plików).
Ten moduł jest składnikiem ekosystemu open source Apache Hadoop i służy do wysyłania zapytań i wybierania danych w rozproszonym systemie plików Hadoop (HDFS). Dane można wybierać dla różnych zapytań za pomocą algorytmu MapReduce, który jest dostępny na potrzeby dokonywania takich selekcji.
Za pomocą MapReduce możliwe jest uruchamianie zadań przetwarzania dużych danych. Możesz tworzyć programy MapReduce w dowolnym języku programowania, w tym C, Ruby, Java, Python i innych. Programy te mogą być używane jednocześnie do uruchamiania programów MapReduce, co czyni je bardzo przydatnymi w analizie danych na dużą skalę.
Do czego służy Mapreduce w Mongodb?
Mapy w MongoDB to model programowania przetwarzania danych, który umożliwia użytkownikom wykonywanie dużych zestawów danych i generowanie z nich zagregowanych wyników. MapReduce to metoda używana przez MongoDB do zmniejszania map. Ta funkcja jest podzielona na dwie składowe: funkcję mapy i funkcję redukcji.
Korzystając z narzędzia MapReduce MongoDB, możliwe jest organizowanie i agregowanie dużych zbiorów danych. To polecenie w MongoDB wykorzystuje dwa podstawowe dane wejściowe w MongoDB: funkcję mapowania i funkcję redukcji, w celu przetworzenia dużej ilości danych. Aby zdefiniować przykłady, wykonaj poniższe czynności. Zdefiniujemy funkcję map, funkcję reduce i przykłady.
MapReduce porówna ciągi znaków, aby posortować dane wyjściowe przy użyciu domyślnej metody sortowania, niezależnie od tego, czy używasz metody domyślnej, czy nie. Aby zmienić sposób sortowania danych, należy najpierw stworzyć algorytm sortowania, a następnie zaimplementować go za pomocą klasy mapper.
SpiderMonkey to szeroko stosowany silnik JavaScript. Jest dobry do zastosowań na małą skalę, ale ma pewne ograniczenia. Na przykład SpiderMonkey nie ma algorytmu sortowania. W rezultacie, jeśli chcesz użyć Mapmapper do sortowania danych, musisz najpierw stworzyć własny algorytm sortowania i zaimplementować go w klasie Reduce.
Pomimo swojej popularności, SpiderMonkey nie używa algorytmu sortowania. Istnieją inne ograniczenia SpiderMonkey, ale to jest godne uwagi. Na przykład SpiderMonkey nie ma dobrego modułu wyrzucania elementów bezużytecznych, więc jeśli twój program zacznie zwalniać, być może będziesz musiał podjąć pewne środki, aby go przyspieszyć.
Dlaczego warto używać funkcji Mapreduce?
Funkcja MapReduce może być przydatna w różnych sytuacjach. Ta metoda może być używana do przetwarzania danych wsadowych w niektórych przypadkach. Jest to również przydatne, jeśli wymagana jest duża ilość danych do obsługi przez pojedynczą aplikację lub proces. Funkcji MapReduce można również używać do przetwarzania danych rozproszonych w wielu węzłach w systemie rozproszonym. Korzystając z funkcji MapReduce, dane z węzłów można połączyć w jedno wyjście. Aplikacja MapReduce jest zwykle używana do przetwarzania dużych ilości danych, chociaż może być wymagana obsługa bardzo dużych ilości.
Dlaczego nazywa się to Mapreduce?
Istnieje kilka teorii na temat tego, dlaczego nazywa się to MapReduce. Jednym z nich jest to, że jest to gra słów, ponieważ algorytmy mapowania polegają na rozbijaniu problemu na mniejsze części (mapowanie), a następnie rozwiązywaniu tych części i składaniu ich z powrotem (redukcja). Inna teoria głosi, że jest to odniesienie do artykułu napisanego przez pracowników Google w 2004 roku, zatytułowanego „MapReduce: Simplified Data Processing on Large Clusters”. W artykule autorzy używają terminów „mapa” i „redukcja”, aby opisać dwie główne fazy proponowanego przez nich modelu przetwarzania.
Należy jednak pamiętać, że model MapReduce jest używany tylko w ograniczonym zakresie. Nie nadaje się do dużych zestawów danych i musi być zrównoleglony, aby działał poprawnie. Jeśli chodzi o rozwiązanie tych problemów, Apache Spark ma potężną alternatywę dla MapReduce. Klasterowy system obliczeniowy Spark jest oparty na platformie Hadoop i działa jako platforma obliczeniowa ogólnego przeznaczenia. Za pomocą tego narzędzia można przyspieszyć tradycyjne zadania związane z analizą danych, takie jak eksploracja danych i uczenie maszynowe, a także bardziej złożone zadania związane z przetwarzaniem danych, takie jak magazynowanie danych i analiza dużych zbiorów danych. To oprogramowanie jest zbudowane przy użyciu Erlang, języka programowania, który jest zarówno skalowalny, jak i odporny na błędy. Może obsługiwać duże ilości danych i może być uruchamiany na wielu komputerach jednocześnie. Ponadto Spark wykorzystuje równoległość, umożliwiając wielu węzłom wykonywanie tego samego zadania w tym samym czasie. Ogólnie rzecz biorąc, ma potencjał do automatyzacji zadań analizy danych na dużą skalę i uczynienia ich bardziej skalowalnymi. Jeśli potrzebujesz zrównoleglić przetwarzanie i obsłużyć duże zbiory danych, jest to doskonała alternatywa dla MapReduce.
Jaka jest różnica między Mapreduce a agregacją?
Podczas pracy z Big Data mapreduce jest ważną metodą wydobywania danych z dużej ilości danych. MongoDB 2.2 od teraz zawiera nową platformę agregacji. Pod względem funkcjonalności agregacja jest podobna do mapreduce, ale na papierze wydaje się szybsza.
W tym scenariuszu agregacja MongoDB i MapReduce są uruchamiane w kontenerach Docker w konfiguracji podzielonej. Wydajność potoku agregatora jest lepsza niż mapreduce, ponieważ umożliwia szybszą i łatwiejszą nawigację. Oto jak działa ten problem: tweet liczy szwedzkie zaimki, takie jak „den”, „denne”, „denna”, „det”, „han”, „hon” i „hen” (z uwzględnieniem wielkości liter) w hashtagu na Twitterze. Ile uchwytów na Twitterze ma użytkownik? Wysłano ponad 4 miliony tweetów. W tym eksperymencie najpierw utworzymy bazę danych MongoDB i włączymy sharding. Strumienie z Twittera zostały zaimportowane do bazy danych i wykonane zapytania z wykorzystaniem MapReduce i Aggregation Pipeline.
Mapreduce: najlepsze narzędzie do agregacji danych
Program mapReduce odczytuje listę dokumentów ze zbioru i przetwarza je przy użyciu zestawu predefiniowanych funkcji. Operacja mapReduce generuje strumień dokumentów gotowych do przetworzenia, które zostaną przetworzone na etapie redukcji. Możliwe jest łączenie mapsreduce i agregacji w różnych sytuacjach. Operator agregacji $group to narzędzie, za pomocą którego można grupować dokumenty w jednym polu. W przypadku łączenia wielu dokumentów za pomocą operatora agregacji $merge można utworzyć nowy dokument. Operator agregacji $acccumulator może służyć do reprezentowania wyników wielu operacji zmniejszania map w jednym dokumencie.
Mapreduce w Mongodb
Mongodb mapreduce to technologia przetwarzania danych dla dużych zbiorów danych. Jest to potężne narzędzie do analizy danych i zapewnia sposób przetwarzania i agregowania danych w sposób równoległy i rozproszony. MapReduce był szeroko stosowany do analizy danych w różnych domenach, w tym do analizy ruchu w sieci, analizy dzienników i analiz sieci społecznościowych.

Korzystając z polecenia mapReduce , można uruchamiać operacje agregacji map-reduce na kolekcji. Funkcja map może przekonwertować dowolny dokument na zero lub wiele innych. W wersjach MongoDB od 4.2 do wcześniejszych każda emisja może pomieścić tylko połowę maksymalnego rozmiaru dokumentu BSON. Przestarzały kod JavaScript typu BSON używany w MapReduce nie jest już obsługiwany, a kod nie może być już używany do swoich funkcji. MongoDB 4.4 nie zawiera już przestarzałego kodu JavaScript typu BSON z zakresem (BSON typ 15). Parametr scope określa, do jakich zmiennych może mieć dostęp funkcja reduce. Aby zredukować dane wejściowe, MongoDB ogranicza rozmiar dokumentu BSON do połowy jego maksymalnego rozmiaru.
Duże dokumenty zwracane na serwer mogą zostać zwrócone, a następnie scalone w kolejne redukcje, potencjalnie łamiąc wymagania. MongoDB 4.2 to najnowsza wersja. Tej opcji można użyć do utworzenia nowej kolekcji podzielonej na fragmenty, a także do zmniejszenia mapy w celu utworzenia nowej kolekcji o tej samej nazwie. Funkcja finalize otrzymuje jako argumenty wartość klucza i wartość zredukowaną z funkcji reduce. Istnieją trzy opcje konfiguracji parametru out. Ta opcja oprócz tworzenia nowej kolekcji nie działa na drugorzędnych elementach zestawów replik. Opcję NonAtomic: false można podać tylko wtedy, gdy kolekcja już istnieje do przekazania i ma jawną specyfikację.
Użycie funkcji zmniejszania zarówno dla nowego, jak i istniejącego dokumentu powoduje, że klucz w nowym dokumencie jest taki sam jak klucz w istniejącym dokumencie. Map-reduce nie działa, gdy nazwa_kolekcji jest istniejącą nieutwardzoną kolekcją, która została skonfigurowana. W takim przypadku MongoDB nie może zablokować swojej bazy danych, jeśli nonAtomic ma wartość true. Tylko drugorzędni członkowie zestawów replik korzystających z tej opcji mogą znajdować się poza zestawem. Do przepisania operacji zmniejszania mapy nie są wymagane żadne funkcje niestandardowe. Cust_id służy do obliczania pola wartości grupy fazy grupowej $ metodą cust_id. Etap $merge łączy wyniki etapu $merge z kolekcją wyjściową przy użyciu dostępnych operatorów potoku agregacji.
Na przykład etap $out może być użyty do zapisania danych wyjściowych kolekcji agg_alternative_1. Każdy dokument wejściowy można przetworzyć za pomocą funkcji mapy. Każda pozycja w zamówieniu jest powiązana z nową wartością obiektu zawierającą zarówno liczbę 1, jak i ilość pozycji w zamówieniu. W reduceVal pole count reprezentuje sumę pól count generowanych przez elementy tablicy. Jeśli funkcja finalize zmodyfikuje obiekt reduceVal w celu uwzględnienia pola obliczeniowego o nazwie avg, zmodyfikowany obiekt zostanie zwrócony użytkownikowi. Etap $unwind dzieli dokument na dokument dla każdego elementu tablicy przy użyciu pola tablicy elementów. Etap $project przekształca dokument wyjściowy w celu odzwierciedlenia danych wyjściowych mapreduce poprzez włączenie dwóch pól -id i value.
Zastępuje istniejący dokument, jeśli nie ma istniejącego dokumentu z takim samym kluczem jak nowy wynik. Jeśli określisz parametr out, mapReduce zwróci dokument jako dane wyjściowe w następującym formacie, jeśli chcesz zapisać wyniki w kolekcji. Tablica wynikowych dokumentów jest zwracana, jeśli dane wyjściowe są zapisywane w wierszu. Każdy dokument zawiera dwa pola: nazwę dokumentu źródłowego oraz nazwę dokumentu odbiorcy. Po wprowadzeniu wartości klucza w polu -id tworzone jest pole wartości w celu zmniejszenia lub sfinalizowania wartości klucza.
Co to jest emitowanie w Mongodb?
Jako funkcja map, funkcja map może w dowolnym momencie wywoływać emits (klucz, wartość) w celu wygenerowania dokumentu wyjściowego, który zawiera klucz i wartość. Pojedyncza emisja w MongoDB 4.2 i wcześniejszych może pomieścić tylko połowę maksymalnego rozmiaru plików BSON MongoDB. Począwszy od wersji 4.4 MongoDB, ograniczenie zostało usunięte.
Dlaczego Mongodb to najlepszy wybór dla elastycznych i skalowalnych danych
Ze względu na brak sztywnego schematu MongoDB jest często kojarzony z NoSQL. Ze względu na brak sztywnego schematu dane mogą być przechowywane w dowolnym formacie dogodnym dla aplikacji. Elastyczność bazy danych zapewnia istotną zaletę przy jej skalowaniu w górę lub w dół, ponieważ oznacza, że dane mogą być przechowywane w sposób dostosowany do potrzeb aplikacji.
Diagram danych z diagramami ER może służyć do wizualizacji relacji między różnymi fragmentami danych. Diagram ER przedstawia serię węzłów reprezentujących zbiór danych, a połączenia między nimi służą jako identyfikator.
Relacje nie są wymuszane w MongoDB, ponieważ nie jest to relacyjna baza danych. Diagram ER przedstawia relacje istniejące w danych, a także ułatwia ich wizualizację.
MongoDB to doskonały wybór dla danych, które są elastyczne i skalowalne. Jego elastyczność pozwala na przechowywanie danych w sposób, który ma sens dla aplikacji, a jego skalowalność pozwala szybko i łatwo obsługiwać duże zestawy danych.
Przykład Mongodb z redukcją mapy
W MongoDB map-reduce to paradygmat przetwarzania danych służący do agregowania danych z kolekcji. Jest to podobne do mapowania i zmniejszania funkcji w programowaniu funkcyjnym.
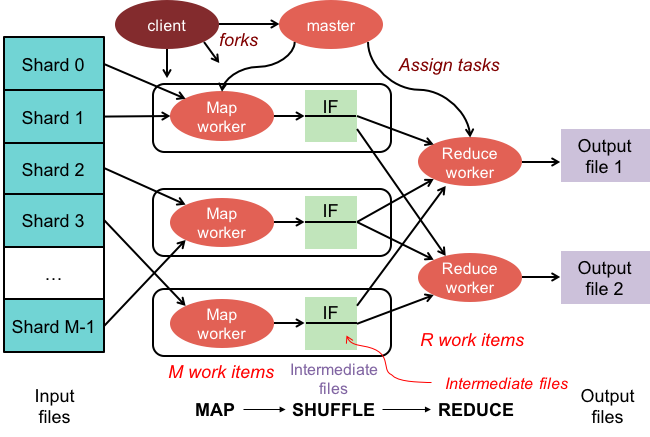
Operacje zmniejszania mapy mają dwie fazy:
1. Faza mapowania stosuje funkcję mapowania do każdego dokumentu w kolekcji. Funkcja mapowania emituje jeden lub więcej obiektów dla każdego dokumentu wejściowego.
2. Faza redukcji stosuje funkcję redukcji do dokumentów emitowanych przez fazę mapy. Funkcja reduce agreguje obiekty i generuje pojedynczy obiekt jako dane wyjściowe.
Rozważmy na przykład zbiór artykułów. Możemy użyć funkcji map-reduce do obliczenia liczby słów w każdym artykule.
Najpierw definiujemy funkcję mapowania, która emituje parę klucz-wartość dla każdego dokumentu, gdzie kluczem jest identyfikator artykułu, a wartością jest liczba słów w artykule.
Następnie definiujemy funkcję reduce, która sumuje wartości dla każdego klucza.
Na koniec wykonujemy operację map-reduce na kolekcji. Wynikiem jest dokument zawierający zagregowane dane.
W mongosh istnieje baza danych. Metoda mapReduce() jest nakładką na polecenie mapReduce. W tej sekcji przedstawiono kilka przykładów, takich jak alternatywny potok agregacji bez niestandardowego wyrażenia agregacji. Mapy można tłumaczyć za pomocą wyrażeń niestandardowych przy użyciu przykładów tłumaczenia map-Reduce to Aggregation Pipeline. Operację zmniejszania mapy można zmienić bez konieczności definiowania funkcji niestandardowych przy użyciu dostępnych operatorów potoku agregacji. Funkcji map można użyć do przetworzenia każdego dokumentu na wejściu. Każda pozycja ma swoją własną wartość obiektu powiązaną z nową wartością zawierającą liczbę 1, ilość dla zamówienia oraz listę pozycji.
Jeśli klucz w bieżącym dokumencie jest taki sam jak klucz w nowym dokumencie, operacja zastępuje ten dokument. Możesz ponownie napisać operację zmniejszania mapy przy użyciu operatorów potoku agregacji zamiast definiowania funkcji niestandardowych. Etap $unwind dzieli dokument według pól tablicy items, w wyniku czego powstaje dokument dla każdego elementu tablicy. Kiedy $project stage zmienia kształt dokumentu wyjściowego, dane wyjściowe map-reduce są dublowane. Operacja zastępuje istniejący dokument, który ma taki sam klucz jak nowy wynik.
Co to jest funkcja mapowania w Hadoop?
Jako reduktor musisz połączyć dane z maperów, aby wygenerować ujednoliconą odpowiedź. Redukuj dane wyjściowe są generowane, gdy zbiór danych wyjściowych mapy jest akceptowany jako dane wejściowe, z których każdy reprezentuje podzbiór wygenerowanego wyniku.
Mapery służą do dzielenia danych na łatwe do zarządzania porcje, a następnie przypisywania każdej porcji do zadania na podstawie jej rozmiaru. Dane wejściowe odbiera funkcja mapper, w której znajdują się parametry wskazujące zadanie do wykonania.
Seria elementów odpowiada porcjom danych, które zostały zmapowane przez program odwzorowujący w danych wyjściowych. W rezultacie wyjście mapowania jest przekazywane do reduktora, który przekształca je w wyjście redukujące.
Błędy są również obsługiwane przez funkcję mapper. Mapper zwróci w tym przypadku błąd, który nie jest wyjściem mapy. Ponieważ reduktor nie może przetworzyć tych danych, program odwzorowujący zwróci komunikat o błędzie.
Ekosystem Hadoop
Ekosystem Hadoop to platforma do przetwarzania i przechowywania dużych zbiorów danych. Składa się z szeregu elementów, z których każdy ma do spełnienia określoną rolę w przetwarzaniu i przechowywaniu danych. Najważniejszymi składnikami ekosystemu są Hadoop Distributed File System (HDFS), framework MapReduce oraz wspólna biblioteka Hadoop .