
Replikacja master-slave vs multi-master w bazach danych NoSQL
Opublikowany: 2023-01-13Istnieje wiele różnych typów replikacji obsługiwanych przez bazy danych NoSQL. Najpopularniejszym rodzajem replikacji jest replikacja Master- Slave . W tego typu replikacji istnieje jeden serwer główny, który zawiera wszystkie dane. Następnie serwery podrzędne replikują dane z serwera głównego. Ten typ replikacji jest bardzo prosty i łatwy w konfiguracji. Jest również bardzo wydajny i zapewnia dobre osiągi. Innym typem replikacji obsługiwanym przez bazy danych NoSQL jest replikacja Multi-Master. W tego typu replikacji istnieje wiele serwerów głównych. każdy serwer główny ma kopię danych. Następnie serwery podrzędne replikują dane ze wszystkich serwerów głównych. Ten typ replikacji jest bardziej złożony w konfiguracji, ale zapewnia lepszą wydajność i jest bardziej odporny na awarie.
Oprócz replikacji danych NoSQL zapewnia solidną funkcję, która umożliwia kopiowanie i przechowywanie ustrukturyzowanych, nieustrukturyzowanych i częściowo ustrukturyzowanych danych w przypadku awarii serwera. Dowiedz się, jak krok po kroku korzystać z baz danych NoSQL.
Replikacja danych: Ponieważ dane są replikowane z jednego serwera na inny, każdy bit danych można znaleźć na wielu serwerach. Proces replikacji dzieli się na dwa etapy: replikacja typu master-slave i replikacja typu slave-aware. Replikacja typu master-slave przypisuje jednemu węzłowi uprawnienia do obsługi zapisu, podczas gdy replikacja typu slave-aware umożliwia urządzeniom podrzędnym odczytywanie i synchronizację z urządzeniem głównym.
MySQL obejmuje jednokierunkową replikację asynchroniczną , w której jeden serwer działa jako źródło, a drugi jako replika.
Współczynnik replikacji (RF), jak sama nazwa wskazuje, to liczba węzłów, w których replikowane są dane (wiersze i partycje). Wiele węzłów (RF=N) jest połączonych w celu przesyłania danych. RF wynoszący jeden wskazuje, że w klastrze jest tylko jedna kopia wiersza i nie ma możliwości odzyskania danych, jeśli węzeł ulegnie awarii lub zostanie naruszony.
Co to jest dzielenie i replikacja w Nosql?
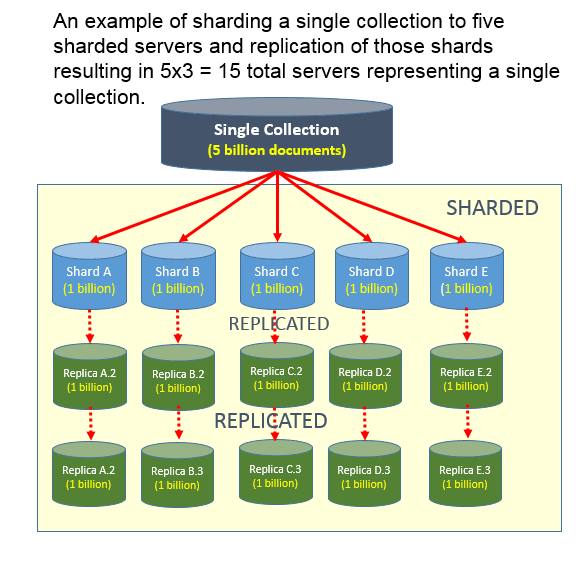
Jaka jest różnica między dzieleniem na fragmenty a replikacją? Replikacja danych ma miejsce, gdy główny węzeł serwera i dodatkowy węzeł serwera wymieniają dane. Jako kopia zapasowa na wypadek awarii serwera podstawowego może pomóc w zwiększeniu dostępności danych. Możliwość skalowania w poziomie między serwerami opiera się na użyciu klucza fragmentu.
Bazy danych SQL umożliwiają podzielenie zbioru danych na tabele, a następnie utworzenie partycji dla każdej tabeli. Baza danych NoSQL , taka jak MongoDB, nie zawiera tabel, lecz zbiór dokumentów. Polecenie mongo shard służy do dzielenia kolekcji MongoDB na fragmenty. Możesz rozłożyć obciążenie na wiele serwerów w jednym środowisku shardingu, co skutkuje lepszą wydajnością. Jest to szczególnie prawdziwe w przypadku dużych zbiorów danych. Co więcej, sharding może pomóc w zarządzaniu i zabezpieczaniu dużych zbiorów danych, zapewniając integralność danych. Oprócz skalowania danych, Sharding jest fantastycznym narzędziem do efektywnego zarządzania nimi. Ten wzorzec jest szeroko stosowany w bazach danych NoSQL ze względu na łatwość implementacji i szerokie wsparcie.
Dlaczego dzielenie jest lepsze dla zapisu danych
Ogólnie rzecz biorąc, replikacja pozwala na poziome skalowanie odczytów, ale nie pozwala na skalowanie danych na wielu serwerach za pomocą jednego klucza, podczas gdy sharding tak.
Jakie typy danych są obsługiwane przez Nosql?
Bazy danych NoSQL są coraz bardziej popularne, ponieważ obsługują szeroki zakres typów danych. Obejmuje to zarówno tradycyjne typy danych, takie jak liczby i łańcuchy, jak i nowsze typy danych, takie jak JSON i XML. Bazy danych NoSQL obsługują również szeroką gamę języków programowania, co czyni je dobrym wyborem dla firm używających wielu języków.
W bazie danych NoSQL istnieją cztery typy: pary klucz-wartość, kolumny, wykresy i dokumenty. Każda kategoria ma swój własny zestaw cech i ograniczeń. Baza danych MongoDB jest popularną bazą danych NoSQL . Jest to baza danych par klucz-wartość, która przechowuje obie pary. Ta aplikacja jest prosta w użyciu, skalowalna i szybka. CouchDB koncentruje się na bazach danych zorientowanych na dokumenty. Ta aplikacja jest prosta w użyciu i wystarczająco elastyczna, aby pomieścić wielu użytkowników. Baza danych CouchBase jest zorientowana na kolumny i koncentruje się na transakcjach. Baza danych Cassandry jest oparta na architekturze zorientowanej na kolumny. System pamięci masowej HBase to skalowalne, rozproszone i petabajtowe rozwiązanie pamięci masowej dla dużych zestawów danych. Jest to rozproszona baza danych pamięci, która działa na Redis. Wykorzystując Riak jako magazyn danych, możesz zbudować wysokowydajny system typu open source. Neo4J, jako baza danych wykresów, jest zbudowana na platformie Java.
Dlaczego Nosql to najlepszy wybór dla firm, które muszą szybko się skalować
Dla firm, które muszą szybko skalować, NoSQL jest dobrym wyborem, ponieważ ma bardziej elastyczną architekturę i może być skalowany w poziomie. Ponadto bazy danych NoSQL nie są tak wrażliwe na zmiany schematu jak tradycyjne relacyjne bazy danych.
Replikacja danych Nosql jest
Replikacja danych Nosql to proces kopiowania danych z bazy danych Nosql do innej bazy danych Nosql. Odbywa się to w celu zapewnienia bezpieczeństwa danych i zapewnienia, że są one zawsze dostępne w przypadku awarii.
Nosql vs. Rdbms: co jest lepsze pod względem wydajności?
Istnieje coraz więcej badań, które pokazują, że bazy danych NoSQL, takie jak MongoDB, przewyższają tradycyjne RDBMS. Technologia umożliwia dzielenie i replikację danych, dzięki czemu idealnie nadaje się do zastosowań wymagających dużej przepustowości i szybkiego dostępu do danych. Chociaż dane mogą być czasami replikowane, nie zawsze jest to możliwe.
Replikacja master-slave w Nosql
Replikacja master-slave to typ replikacji, w którym dane są kopiowane z serwera głównego („głównego”) na jeden lub więcej serwerów pomocniczych („podrzędnych”). Serwery podrzędne mogą być używane do operacji odczytu, ale wszystkie operacje zapisu muszą być wysyłane do serwera głównego. Ten typ replikacji jest często stosowany w bazach danych Nosql, ponieważ może zapewnić wysoką dostępność i skalowalność. Na przykład, jeśli serwer główny ulegnie awarii, urządzenia podrzędne mogą nadal służyć do obsługi żądań odczytu. A jeśli potrzebna jest większa pojemność odczytu, można dodać dodatkowe serwery podrzędne.
Wyzwania związane z replikacją master-slave
Utrzymywanie danych we wszystkich węzłach podrzędnych w modelu replikacji master-slave może być trudne. Jeśli jeden z węzłów podrzędnych ulegnie awarii, dane w tym węźle podrzędnym zostaną utracone.
Który model replikacji obsługuje operacje odczytu i zapisu bazy danych we wszystkich węzłach?
Model replikacji obsługujący operacje odczytu i zapisu bazy danych we wszystkich węzłach to model replikacji Master -Master. Ten model pozwala każdemu węzłowi działać jako master, co oznacza, że każdy węzeł może odczytywać i zapisywać w bazie danych. Jest to korzystne dla organizacji, które muszą mieć wysoką dostępność i nadmiarowość, ponieważ wszystkie węzły mogą nadal działać, nawet jeśli jeden węzeł ulegnie awarii.

Który model aplikacji obsługuje operacje odczytu i zapisu bazy danych we wszystkich notatkach?
RDBMS zwykle wykorzystują model schematu przy zapisie, w którym struktura danych jest definiowana z wyprzedzeniem, a wszystkie operacje odczytu i zapisu są zależne od tej struktury.
Zmiany i aktualizacje bazy danych mogą wystąpić w trybie odczytu i zapisu
Zmiany i aktualizacje mogą zachodzić w trybie odczytu/zapisu, gdy baza danych jest otwarta w trybie odczytu/zapisu, który jest kontrolowany przez OpenReadWrite() lub OpenWrite. DatabaseReader to klasa, której można używać do odczytywania i zapisywania danych w bazie danych. Dane można zapisywać w bazie danych przy użyciu obiektu DatabaseWriter.
Który typ bazy danych obsługuje węzły połączone relacjami?
Relacje można przechowywać i uzyskiwać do nich dostęp w bazach danych grafów przy użyciu ustrukturyzowanych relacji. Relacje są najcenniejszymi aspektami grafowych baz danych, ponieważ są jednymi z najcenniejszych obywateli. Węzły są używane w bazach danych grafów do przechowywania jednostek danych, a krawędzie służą do łączenia jednostek.
Mongodb i Node.js: idealne połączenie do pracy z wykresami w JavaScript
Jeśli chcesz używać wykresów w JavaScript, powinieneś użyć MongoDB. MongoDB to najpopularniejsza baza danych NoSQL, a Node.js to także popularny język programowania JavaScript.
Jak działa replikacja nierelacyjnej bazy danych?
W instancji Peer-to-Peer NoSQL Data Replication dane są replikowane z jednej bazy danych do drugiej w oparciu o koncepcję, zgodnie z którą każda kopia musi aktualizować własną kopię. Może to działać tylko wtedy, gdy każda kopia schematu przechowuje ten sam typ danych w tym samym formacie. Innym krytycznym aspektem tej metody replikacji danych jest przywracanie bazy danych.
Różne typy replikacji
*br *Replikacja pamięci masowej *br Jest to rodzaj replikacji, który przechowuje zmiany danych w spójny sposób. Źródłowy serwer repliki tworzy migawkę bazy danych z aktualnymi informacjami o stanie po jej utworzeniu. Następnie migawka jest wysyłana do docelowego serwera repliki. Po utworzeniu migawki docelowy serwer replik tworzy nową kopię bazy danych. Odwoływanie się do replikacji transakcyjnej w danych Transakcje są przechowywane w danych, które często się zmieniają i mogą być replikowane przy użyciu replikacji transakcyjnej. Transakcja jest grupowana razem i replikowana w jednej partii. Zmiany w danych są replikowane w procesie znanym jako replikacja. Replikację peer-to-peer można przeprowadzić za pomocą serwerów. Replikacja danych typu „peer-to-peer” to typ replikacji danych przeznaczony do replikowania danych, które nie są często zmieniane. W replikacji danych peer-to-peer klaster węzłów replikuje dane. Każdy węzeł w klastrze ma swój własny model danych. Węzły klastra nie znają się nawzajem.
Replikacja bazy danych dokumentów Nosql
Bazy danych dokumentów Nosql zostały zaprojektowane w celu zapewnienia wysokiej dostępności i skalowalności poprzez replikację danych na wielu serwerach. Dzięki temu baza danych może działać nawet w przypadku awarii jednego lub kilku serwerów.
Duża baza danych Nosql
Nie ma jednoznacznej odpowiedzi na to pytanie, ponieważ zależy to od konkretnych potrzeb użytkownika. Jednak niektóre z najpopularniejszych dużych baz danych nosql to MongoDB, Cassandra i Hadoop. Wszystkie te bazy danych zostały zaprojektowane z myślą o zapewnieniu skalowalności i wysokiej wydajności, dzięki czemu idealnie nadają się do przetwarzania danych na dużą skalę.
Na przykład baza danych NoSQL, taka jak MongoDB, jest idealna do dużych zbiorów danych, ponieważ może szybko i łatwo obsługiwać duże ilości danych. Ponieważ MongoDB jest MongoDB zorientowanym na dokumenty, może obsłużyć ogromne ilości danych. Innymi słowy, MongoDB może obsługiwać dane w różnych formatach, w tym JSON, BSON i JavaScript Object Notation (JSON). Ułatwia również dostęp do danych i ich przechowywanie. Ponadto MongoDB jest skalowalny, co oznacza, że może przetwarzać duże ilości danych.
Która baza danych Nosql jest najlepsza dla Big Data?
Tworzą formaty, których narzędzia analityczne mogą używać do konwertowania danych nieustrukturyzowanych i częściowo ustrukturyzowanych na formaty, które mogą być używane w ich aplikacjach. Wyjątkowe wymagania dotyczące przechowywania dużych zbiorów danych sprawiają, że bazy danych NoSQL (nierelacyjne), takie jak MongoDB, są doskonałym wyborem.
Dlaczego Mongodb to najlepszy wybór do przechowywania dużych zbiorów danych
MongoDB to doskonały wybór do przechowywania i zarządzania dużymi ilościami danych. Operacje CRUD (tworzenie, odczytywanie, aktualizowanie, usuwanie), struktura agregacji, wyszukiwanie tekstu i funkcja Map-Reduce ułatwiają użytkownikom dostęp do danych, manipulowanie nimi i analizowanie.
Czy Big Data to Nosql?
Jeśli Twoje obciążenia związane z danymi są bardziej skoncentrowane na szybkim przetwarzaniu i analizie dużych ilości zróżnicowanych i nieustrukturyzowanych danych, takich jak Big Data, NoSQL jest lepszym wyborem. Bazy danych NoSQL nie mają takich samych ograniczeń dotyczących typów danych jak relacyjne bazy danych.
Dlaczego bazy danych Nosql są przyszłością zarządzania danymi
Baza danych NoSQL staje się coraz bardziej popularna ze względu na znaczną przewagę wydajności nad tradycyjnymi relacyjnymi bazami danych. Jest to aktywator bazy danych NoSQL, który umożliwia niektóre typy baz danych NoSQL, takie jak HBase, umożliwiając dystrybucję danych na tysiącach serwerów bez zmniejszania wydajności. Platforma chmurowa Google (GCP) zapewnia zróżnicowany zestaw usług bazodanowych, które są wyjątkowe pod względem możliwości przetwarzania bardzo dużych, dynamicznych zestawów danych bez potrzeby stosowania schematu.
Czy duże firmy używają Nosql?
Technologia bazodanowa oparta na Cloud Computing, sieci Web, Big Data i Big Users. Oferując NoSQL jako alternatywę dla tradycyjnych RDBMS, NoSQL stał się realną opcją dla wielu popularnych firm internetowych, takich jak LinkedIn, Google, Amazon i Facebook.
Czy Nosql to przyszłość baz danych zaplecza Instagrama?
W tym momencie Instagram wydaje się preferować PostgreSQL jako swoją podstawową bazę danych jako główny backend, choć może się to zmienić. Cassandra, popularna baza danych NoSQL, może, ale nie musi, najlepiej pasować do Instagrama. Cassandra to doskonałe narzędzie do przechowywania dużych ilości danych, ale ma słabe wyniki w zakresie wydajności.
W tej chwili trudno jest przewidzieć, czy Instagram będzie używał baz danych NoSQL jako swojej podstawowej bazy danych zaplecza. PostgreSQL i Cassandra to doskonały wybór, ale nie mogą konkurować z SQL pod względem wydajności.