
Architektury baz danych NoSQL: podejście zorientowane na kolumny
Opublikowany: 2022-12-14Istnieje wiele różnych architektur, które można zastosować podczas pracy z bazami danych NoSQL , ale najczęstszą z nich jest podejście zorientowane na kolumny. To podejście jest często używane, ponieważ pozwala na bardziej elastyczny schemat, który może być pomocny podczas pracy z dużymi ilościami danych. Ponadto takie podejście może również pomóc poprawić wydajność, umożliwiając lepszą kompresję danych.
Ruch NoSQL rozwinął się w ostatnich latach wraz z modelami przechowywania i wyszukiwania danych. Nie jest konieczne tworzenie tabeli i przechowywanie danych w wielu wierszach klucza obcego. W NoSQL dane są przechowywane w formacie klucz-wartość. Baza danych NoSQL to taka, która przechowuje duże ilości danych w czasie rzeczywistym. W bazie danych NoSQL funkcja skrótu jest używana na najwyższym poziomie, gdzie wykonuje dobrze znany algorytm, który pobiera dane wejściowe o zmiennej długości i generuje dane wyjściowe o stałej długości. Kiedy ten klucz jest ponownie mieszany, aparat bazy danych pobiera parę wartości odpowiadającą kluczowi wykrytemu w bazie danych (jeśli klucz istnieje). Zasadniczo istnieją trzy typy baz danych NoSQL: deklaratywne, semantyczne i grafowe. Istnieją również magazyny klucz-wartość, magazyny dokumentów, wykresy i magazyny kolumnowe.
W architekturze hybrydowej do stworzenia modelu hybrydowego wykorzystywane są różne modele baz danych . Jeśli używasz architektury hybrydowej, możesz pracować z SQL i NoSQL w jednym systemie.
Z jakiej architektury korzysta Nosql?
Właściwość jest jedną z wielu funkcji baz danych NoSQL. W przeciwieństwie do ACID, który jest zbiorem właściwości, jest to zbiór zasad i wytycznych. Podstawowa dostępność BA, stan S-miękki i spójność E-parzystości są wskaźnikami spójności E-parzystości. W przeciwieństwie do ustrukturyzowanej bazy danych , która przechowuje dane w określonym formacie, dane w bazie danych NoSQL są przechowywane w formacie klucz-wartość.
Administratorzy zmieniają pojemność baz danych RDBMS i baz danych NoSQL na różne sposoby. Jedynym sposobem na zwiększenie wydajności systemu relacyjnego jest dodanie drogiego sprzętu, szybszych procesorów i większej ilości pamięci RAM. Komponent sieciowy z zaawansowanymi funkcjami. węzły, które można łatwo dodawać i usuwać zgodnie z zapotrzebowaniem, zapewniają „elastyczną” pojemność w klastrach NoSQL. Aplikacje o dużej objętości i małych opóźnieniach mogą korzystać z bazy danych NoSQL, która wykorzystuje architekturę masterless. Baza danych NoSQL różni się od relacyjnej bazy danych tym, że zachęca do tworzenia aplikacji po raz pierwszy. Ta metoda replikacji danych jest stosowana w tych bazach danych, w których wszystkie węzły są replikowane w tym samym czasie.
Bazy danych NoSQL wykorzystują wiele „kształtów” obiektów danych, co oznacza, że mogą współistnieć i zwiększać odporność danych, ale mogą też popełniać więcej błędów. Modele danych mogą być ustrukturyzowane deklaratywnie w relacyjnej bazie danych, w przeciwieństwie do deklaratywnych modeli ustrukturyzowanych w schemacie. To podejście jest często odrzucane przez NoSQL, który daje programistom większą moc i często jest bardziej zdecentralizowany w kontroli struktur danych.
Baza danych NoSQL LinkedIn sprawia, że doskonale pasuje do platformy sieci. Dane na LinkedIn stale się zmieniają i zmieniają, co czyni go doskonałym wyborem dla firmy, która chce nawiązać kontakty. Ponieważ LinkedIn korzysta z bazy danych NoSQL, oszczędza znaczną ilość czasu i zasobów, ponieważ nie musi odbudowywać bazy danych za każdym razem, gdy następuje zmiana. Użytkownicy mogą być na bieżąco z najnowszymi trendami i połączeniami, reagując na witrynę.
Czym jest architektura bazy danych Nosql?
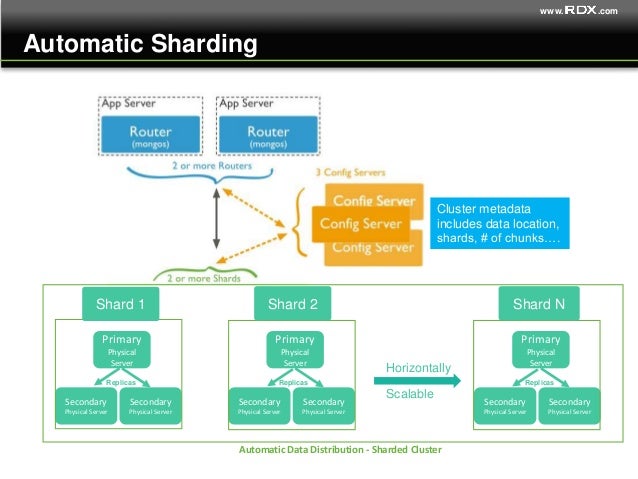
Bazy danych NoSQL wyróżniają się odejściem od serwerów opartych na SQL. Logika sprawdzania poprawności, kontroli dostępu, mapowania indeksowanych danych, które można przeszukiwać, korelacji między powiązanymi danymi, rozwiązywania konfliktów, utrzymywania ograniczeń integralności i wyzwalania procedur została usunięta z warstwy bazy danych .
W przypadku baz NoSQL najlepiej iść również ze zmianą architektury aplikacji. Podejście NoSQL, w przeciwieństwie do serwerów opartych na SQL, kładzie nacisk na prostotę. W tym artykule omówimy bardziej szczegółowo zarządzanie danymi i zaproponujemy warstwę zarządzania danymi, która łączy bazy danych NoSQL i różne aspekty zarządzania danymi. Hierarchiczna zagnieżdżona struktura w jednostkach danych jest jedną z najczęściej używanych funkcji baz danych NoSQL. Zagnieżdżona struktura danych elegancko działa w sytuacjach, w których zawsze można uzyskać dostęp do struktury potomnej/podstruktury z poziomu dokumentu nadrzędnego. W niektórych przypadkach struktury zagnieżdżone mogą pomóc w wyeliminowaniu niepotrzebnych relacji dwukierunkowych. W rzeczywistości relacje są nadal bardzo ważne w niektórych rzeczywistych zastosowaniach.
Relacje między tradycyjnymi systemami RDBMS a innymi bazami danych zostały dokładnie poznane. Jak modelujemy relacje i bazy danych NoSQL? Różne podejścia można podsumować w następujący sposób. Aby zapobiec duplikowaniu danych, zaleca się stosowanie strategii normalizacji. Denormalizowanie danych może również poprawić wydajność zapytań. Jeśli podejścia NoSQL próbują unieważnić filary zarządzania danymi ustanowione przez Edgara Codda, zmierzają w złym kierunku. Zamiast korzystać z interfejsu API wielokrotnego użytku w celu uzyskania dostępu do bazy danych, podejście to koncentruje się na implementacji bazy danych.
Zarządzanie spójnością danych staje się ważnym elementem magazynu NoSQL, ponieważ wymaga gromadzenia danych i zarządzania nimi. Interfejs API BerkeleyDB to interfejs API bazy danych dokumentów typu klucz-wartość wzorowany na indeksowanym interfejsie API bazy danych dokumentów typu klucz-wartość. Według niedawnego raportu W3C, w bazach danych NoSQL, do których dostęp uzyskuje się za pośrednictwem przeglądarki, lepiej jest używać indeksów programistycznych niż indeksów opartych na zapytaniach. Nie oznacza to jednak, że można usunąć ograniczenia dotyczące ważności i integralności danych. Przeniesienie walidacji z warstwy przechowywania danych do warstwy zarządzania danymi zmniejsza zapotrzebowanie na pamięć masową. Ogólnie rzecz biorąc, bardziej swobodny system replikacji oparty na spójności można zaimplementować na każdym systemie przechowywania bazy danych w oparciu o bardziej rygorystyczną semantykę transakcyjną. Replikacja niestandardowa i egzekwowanie spójności mogą być niezwykle przydatne w aplikacjach, w których niektóre aktualizacje mogą być bardziej stabilne, a inne mogą być bardziej swobodne.
Rozwiązywanie konfliktów w oparciu o rozwiązywanie konfliktów w stylu Multi-Version Concurency Control (MVCC), takie jak w CouchDB, może być naiwne. Persevere 2.0 może służyć do definiowania modelu danych i łączenia produktów z ich producentami. W pełni wdrożyliśmy model MVC. W rezultacie uważam, że ten typ warstwy interfejsu użytkownika powinien zostać zrekapitalizowany jako mVC, co kładzie nacisk na problemy związane z modelowaniem danych w logice interfejsu użytkownika.
Bazy danych NoSQL są doskonałymi kandydatami na magazyny danych, które wymagają wysokiej wydajności i skalowalności. Mogą obsługiwać wiele danych i są proste w użyciu. Bazy danych NoSQL, oprócz tego, że są wyjątkowo niezawodne i zdolne do obsługi dużego ruchu, są również niezwykle elastyczne.
Co to jest bez schematu Dlaczego Nosql podąża za architekturą bez schematu?
Schemat to schemat lub plan używany do konstruowania bazy danych. Schemat może zawierać reguły określające, jakie dane są dozwolone w bazie danych, a także sposób organizacji danych.
Często mówi się, że bazy danych NoSQL działają w architekturze „bezschematycznej”. Oznacza to, że nie wymuszają określonego schematu na danych, które są w nich przechowywane. Można to postrzegać jako główną zaletę, ponieważ pozwala na znacznie większą elastyczność w sposobie przechowywania i wyszukiwania danych.

W ostatnim czasie w branży IT spopularyzował się termin bazy danych „bez schematów”. Zamiast oddawać bezschematowe bazy danych w ręce programistów, nadszedł czas, aby wprowadzić je na otwarty rynek. Gdy dane są przechowywane w bazie danych bez schematu, są przechowywane jako para klucz/wartość (znana również jako KV) lub dokument JSON. Bezschematowa baza danych, w przeciwieństwie do wiersza w relacyjnej bazie danych, może mieć możliwość całkowitej zmiany stanu wiersza konta. Wszystko, co jest wymagane do określenia sposobu grupowania jednostek, to pojedynczy atrybut jednostki. Większość tego działania jest całkowicie wyeliminowana z baz danych bez schematów. To poważny cios dla przedsiębiorstwa, którego przetrwanie w dużej mierze zależy od jego danych.
Aby sprostać opóźnieniom, należy zakupić najnowocześniejszy sprzęt, który wiąże się z wysokimi kosztami kapitałowymi i operacyjnymi. Błąd ręcznego wdrożenia może spowodować kilkudniowe lub miesięczne opóźnienia. Dzięki elastycznemu modelowi przechowywania danych bazy danych NoSQL ograniczają złożone migracje i synchronizację zmian. Możesz zdefiniować widok danych, zamiast walczyć o niego w bezschematowej bazie danych. Baza danych bez schematu nie wymaga rozwijania ani wdrażania złożonej/własnej infrastruktury, jak również dużych nakładów kapitałowych lub operacyjnych. Za naciśnięciem jednego przycisku małą instancję można przeskalować do niemal dowolnego rozmiaru.
Ta wolność może cię zarówno wyzwolić, jak i rzucić wyzwanie. Możliwość zmiany danych bez obawy o uszkodzenie aplikacji może być wyzwalająca. Znalezienie schematu, który jest zarówno elastyczny, jak i wydajny, a także ustrukturyzowanie danych w najlepszy możliwy sposób, może być trudne. Bezschematowa baza danych, w przeciwieństwie do tradycyjnego RDBMS , ma swój własny zestaw wyzwań i może zapewnić znaczną elastyczność i wydajność w porównaniu z tradycyjnymi RDBMS.
Która z poniższych jest najprostszą architekturą Nosql?
Istnieje wiele różnych typów architektur NoSQL, z których każda ma swoje zalety i wady. Najprostszą architekturą NoSQL jest magazyn klucz-wartość, który jest bardzo podstawowym typem bazy danych NoSQL. Magazyny klucz-wartość są bardzo szybkie i skalowalne, ale nie są zbyt elastyczne i nie obsługują złożonych zapytań.
Baza danych NoSQL może przechowywać dane, a nie relacyjna baza danych. Są zbudowane tak, aby były elastyczne, skalowalne i zdolne do szybkiego reagowania na nowoczesne wymagania w zakresie zarządzania danymi biznesowymi. Termin NoSQL odnosi się do szerokiej gamy typów baz danych, w tym czystych baz danych dokumentów, magazynów klucz-wartość, szerokokolumnowych baz danych i grafowych baz danych. Wraz z rozwojem globalnych firm 2000, bazy danych NoSQL zyskują na popularności jako sposób zasilania aplikacji o znaczeniu krytycznym. Istnieje pięć głównych trendów, które utrudniają korzystanie z relacyjnych baz danych ze względu na związane z nimi wyzwania techniczne. Ze względu na swój stały model danych, relacyjne bazy danych nie wspierają dobrze programowania zwinnego. W przypadku korzystania z NoSQL model danych jest definiowany przez model aplikacji.
Modelowanie danych nie jest zdefiniowane w NoSQL w tradycyjnym tego słowa znaczeniu. Dane są przechowywane w formacie JSON jako część zorientowanej na dokumenty bazy danych. Ramy ORM nie są już potrzebne, a proces programowania jest usprawniony. N1QL (wymawiane nikiel), potężny język zapytań, który rozszerza SQL do formatu JSON, został wprowadzony w Couchbase Server 4.0. Obsługuje również tablice (GROUP BY), sortowanie (SORT BY), łączenia (LEFT OUTER / INNER) i inne więcej niż tylko instrukcje SELECT / FROM / WHERE. Korzyści z rozproszonych baz danych NoSQL są liczne, w tym wykorzystanie architektury skalowalnej w poziomie i brak pojedynczego punktu awarii. Zdolność do zapewnienia szybkiej i wydajnej obsługi staje się coraz ważniejsza, ponieważ coraz więcej zleceń klientów jest obsługiwanych online za pośrednictwem aplikacji mobilnych i internetowych.
Bazy danych NoSQL są dostępne w różnych rozmiarach, są łatwe w instalacji i można je skonfigurować w celu spełnienia określonych wymagań. Zostały zaprojektowane tak, aby umożliwić ruch odczytów, zapisów i przechowywania. Mogą zarządzać i monitorować klastry różnej wielkości, a także prowadzić operacje w każdej skali. Nie musisz instalować żadnego oprogramowania, aby uruchomić bazę danych NoSQL: jest to tak proste, jak przechowywanie danych w rozproszonej bazie danych NoSQL. Ponadto użycie routerów sprzętowych umożliwia natychmiastową awarię, eliminując konieczność oczekiwania na wykrycie problemu przez bazę danych i przeprowadzenie niezależnego procesu odzyskiwania. Struktury danych oparte na NoSQL stają się coraz bardziej popularne jako część dzisiejszych aplikacji internetowych, mobilnych i Internetu rzeczy (IoT).
Architektura baz danych NoSQL oparta jest na kolumnach. Oznacza to, że dane są przechowywane w wierszach i kolumnach, jak w zwykłej bazie danych . W przeciwieństwie do zwykłej bazy danych, bazy danych NoSQL są zaprojektowane tak, aby zapewnić wydajność, a nie spójność. Ponieważ są przeznaczone do obsługi dużej ilości danych, nie są ograniczone możliwością szybkiego reagowania na zmiany. Nie ma znaczenia, jakiego typu dane zawiera baza danych NoSQL: można jej używać do przechowywania danych na dużą skalę. Jest to również dobra opcja dla firm, które muszą reagować na szybkie zmiany. Mogą szybko i łatwo wyszukiwać dane, ponieważ bazy danych NoSQL są oparte na kolumnach. Ze względu na szybki dostęp do konkretnych informacji, rozwiązania te są doskonałym wyborem dla firm poszukujących szybkich odpowiedzi. Jest to również dobry pomysł dla firm, które potrzebują dużych ilości danych do korzystania z baz NoSQL. W rezultacie są doskonałą opcją dla firm, które wymagają dodatkowych serwerów. Bazy danych NoSQL można łatwo rozszerzyć za pomocą struktur danych opartych na kolumnach. W rezultacie dodanie większej ilości danych do baz danych nie musi obniżać wydajności przedsiębiorstw. Baza danych NoSQL to dobry wybór dla firm, które muszą przechowywać dużą ilość danych.
Nosql Wprowadzenie
Nosql to baza danych przechowująca dane w formacie innym niż tradycyjny format relacyjny . Chociaż bazy danych nosql mogą przybierać różne formy, wszystkie mają wspólną cechę, jaką jest skalowalność i łatwość użycia.
Relacyjna baza danych jest wynikiem artykułu EFCodda z 1970 roku zatytułowanego A relacyjny model danych dla dużych współdzielonych banków danych. System rozproszony to taki, który wykorzystuje wiele komputerów i komponentów oprogramowania komunikujących się ze sobą za pośrednictwem sieci komputerowej. Aby system mógł osiągnąć wspólny cel, komputery muszą ze sobą współdziałać i dzielić się zasobami. Rozproszony system obliczeniowy ma większą moc obliczeniową niż inne typy systemów ze względu na dużą szybkość obliczeniową. W przeciwieństwie do tradycyjnych relacyjnych baz danych , bazy danych NoSQL nie wymagają użycia języka SQL ani innych podobnych algorytmów. Gdy używany jest system NoSQL, może on przechowywać dane znacznie szybciej, ponieważ wykorzystuje skalowanie w poziomie. Carlo Strozzi ukuł termin NoSQL w 1998 roku jako pomysł na biznes.
Tradycyjne bazy danych mają cztery oczywiste cechy wspólne: są relacyjne, są rozproszone, są nierelacyjne i nie są zgodne z atomowością, spójnością, izolacją ani trwałością. Zgodnie z Twierdzeniem CAP istnieją trzy podstawowe wymagania, które muszą być spełnione przy tworzeniu aplikacji dla systemów rozproszonych. Zgodnie z twierdzeniem CAP, rozproszone systemy komputerowe nie mogą zagwarantować, że wszystkie te trzy właściwości występują jednocześnie. Bazy danych NoSQL są podzielone na cztery kategorie (z których najpowszechniejsze to kategorie). Krawędź lub łuk to skończony (lub zmienny) zestaw uporządkowanych par w strukturach danych grafu.