
Baza danych NoSQL: Impala
Opublikowany: 2023-03-03NoSQL to termin używany do opisania bazy danych, która nie korzysta z tradycyjnej, relacyjnej struktury bazy danych. Zamiast tego bazy danych NoSQL są często projektowane w celu zapewnienia prostszego, bardziej skalowalnego rozwiązania.
Impala to baza danych NoSQL, która została zaprojektowana w celu zapewnienia szybkiego, skalowalnego rozwiązania do zarządzania dużymi zbiorami danych. Impala jest oparta na modelu danych Google Bigtable i używa kolumnowego formatu przechowywania. Impala jest dostępny jako projekt open source i jest wspierany przez Cloudera.
Apache Impala to silnik zapytań SQL typu open source, który jest instalowany w klastrze Hadoop i wykonuje masowe przetwarzanie równoległe (MPP) danych przechowywanych w systemie. Pierwotnie opracowany w 2012 roku projekt open source jest znany jako „Microsoft Formula 1”.
Platforma Impala umożliwia użytkownikom wykonywanie zapytań SQL o niskim opóźnieniu do danych Hadoop przechowywanych w HDFS i Apache HBase bez konieczności przenoszenia lub przekształcania danych.
Czy Impala Sql jest oparta?
Impala to oparty na SQL silnik zapytań, który działa na Apache Hadoop. Pozwala użytkownikom na wysyłanie zapytań do danych przechowywanych w HDFS i HBase przy użyciu SQL. Impala zapewnia wysoką wydajność i małe opóźnienia w porównaniu z innymi silnikami zapytań Hadoop, takimi jak Hive i Pig.
Analityczna baza danych MPP firmy Impala zapewnia najkrótszy czas uzyskiwania wglądu w branży. Jest zintegrowany z CDH i można uzyskać do niego dostęp za pośrednictwem Cloudera Enterprise. Bazy danych MPP dla Apache Hadoop, takie jak Impala, używają systemu plików HDFS, aby zapewnić szybszy czas uzyskiwania wglądu.
Impala to baza danych
Jest to baza danych, w którą wierzę.
Czy Impala jest narzędziem ETL?
Impala nie jest narzędziem ETL, jest to silnik zapytań SQL, którego można używać do wykonywania zapytań SQL po oczyszczeniu danych w procesie.
Do czego służy Apache Impala?
Korzystając z zapytań podobnych do SQL, możemy odczytywać dane z różnych źródeł za pomocą Impala. Apache Impala radzi sobie lepiej niż Hive i inne silniki SQL, jeśli chodzi o dostęp do danych przechowywanych w rozproszonym systemie plików Hadoop . Używamy Impala do przechowywania danych w Hadoop HBase, HDFS i Amazon S3.
19 firm, które używają Apache Impala w swoich stosach technologicznych
Apache Impala to popularny silnik przetwarzania danych dla różnych dużych firm. Według raportów 19 firm technologicznych, w tym Stripe, Agoda i Expedia.com, używa Apache Impala. Platforma Impala jest elastyczna i wydajna, zdolna do szybkiej i efektywnej obsługi dużych zbiorów danych. Powszechne użycie tego narzędzia pokazuje, jak bardzo jest ono przydatne i przydatne w przetwarzaniu danych.
Jakie są różnice między Sql Hive a Impalą?
Celem Hive jest obsługa długotrwałych zapytań, które wymagają wielu przekształceń i sprzężeń. Ze względu na małe opóźnienia i możliwość obsługi mniejszych zapytań silnik przetwarzania zapytań Impala jest idealny do obliczeń interaktywnych. Spark obsługuje zarówno zapytania krótko-, jak i długoterminowe, a także zapytania krótko- i długoterminowe.
Hive lepiej nadaje się do długotrwałych zadań wsadowych
Głównym celem narzędzi nie jest przetwarzanie partii. Hive lepiej nadaje się do długoterminowej pracy wsadowej niż Impulsa, która może obsługiwać mniejsze zestawy danych.
Czy Impala jest bazą danych
Impala to baza danych przechowująca dane w formacie kolumnowym. Został zaprojektowany tak, aby był skalowalny i zapewniał wysoką wydajność dla dużych zestawów danych.
W początkowej wersji Impala obsługiwane są następujące typy danych w kolumnach podstawowych: STRING, VARCHAR, VARCHar2, INT i FLOAT zamiast liczb, a żaden typ BLOB nie jest obsługiwany. Impala SQL-92 zawiera pewne ulepszenia standardów standardów SQL, ale nie zawiera ich wszystkich. Gdy dane są zbyt duże, aby można je było produkować, przetwarzać i analizować na jednym serwerze, Impala działa lepiej niż inne hurtownie danych i zapewnia większą skalowalność. Nie ma potrzeby usuwania oryginalnej lokalizacji plików danych podczas ładowania Impala, ponieważ jest lekki. Pierwszym krokiem w zdobywaniu wiedzy na temat testowania wydajności, skalowalności i konfiguracji klastrów wielowęzłowych jest zazwyczaj zebranie ogromnych ilości danych. Cloudera Impala jest zoptymalizowana pod kątem ładowania danych i odczytu zbiorczego w dużych zestawach danych, dzięki czemu możesz zrobić więcej za mniej. Wielomegabajtowy rozmiar bloku HDFS pozwala Impala przetwarzać ogromne ilości danych równolegle na wielu serwerach sieciowych.
Zamiast planować znormalizowane indeksy oraz czas i wysiłek potrzebny do ich stworzenia, zrobisz to w Impala. Silnik zapytań Impala może obsłużyć duże ilości danych pochodzących z hurtowni danych. Analizuje klaster i rozdziela zadania między węzły w celu zmniejszenia ilości zużywanych zasobów. Partycjonowanie hurtowni danych to znana koncepcja w Impala. Partycjonowanie zmniejsza liczbę operacji we/wy dysku i zwiększa skalowalność zapytań w Impala. Pliki danych są wymagane, ponieważ nie będziesz mieć dostępu do żadnych wbudowanych tabel w Impala. INSERT jest jedną z dostępnych opcji.
Aby zbudować dwa stoliki z zabawkami, użyj instrukcji wartości. Jeśli korzystasz z oprogramowania zorientowanego na przetwarzanie wsadowe, możesz spróbować. Możesz włączyć technologię SQL-on-hadoop do swojej konfiguracji Apache Hive. Tabele Hive w Impala nie są ładowane ani konwertowane w czasochłonny sposób.
Impala: potężne narzędzie do zarządzania danymi dla Hadoop
Składnia SQL jest znana użytkownikom Impala, którzy mogą wyszukiwać dane przechowywane w HDFS i Apache HBase. W ten sposób Hadoop i Impulsa mogą być używane zamiast tradycyjnych relacyjnych baz danych . Ponadto dzięki swoim funkcjom jest potężnym narzędziem do zarządzania danymi. Co więcej, jego możliwości w przypadku dużych zestawów danych są imponujące i radzi sobie z nimi z dużą łatwością.
Impala w Big Data
Impala to silnik zapytań MPP SQL o otwartym kodzie źródłowym, który działa na Apache Hadoop. Zapewnia szybkie, interaktywne zapytania SQL dotyczące danych przechowywanych w HDFS i HBase. Impala ma na celu poprawę wydajności Apache Hadoop poprzez zapewnienie szybkiego, interaktywnego interfejsu SQL dla danych przechowywanych w HDFS i HBase.

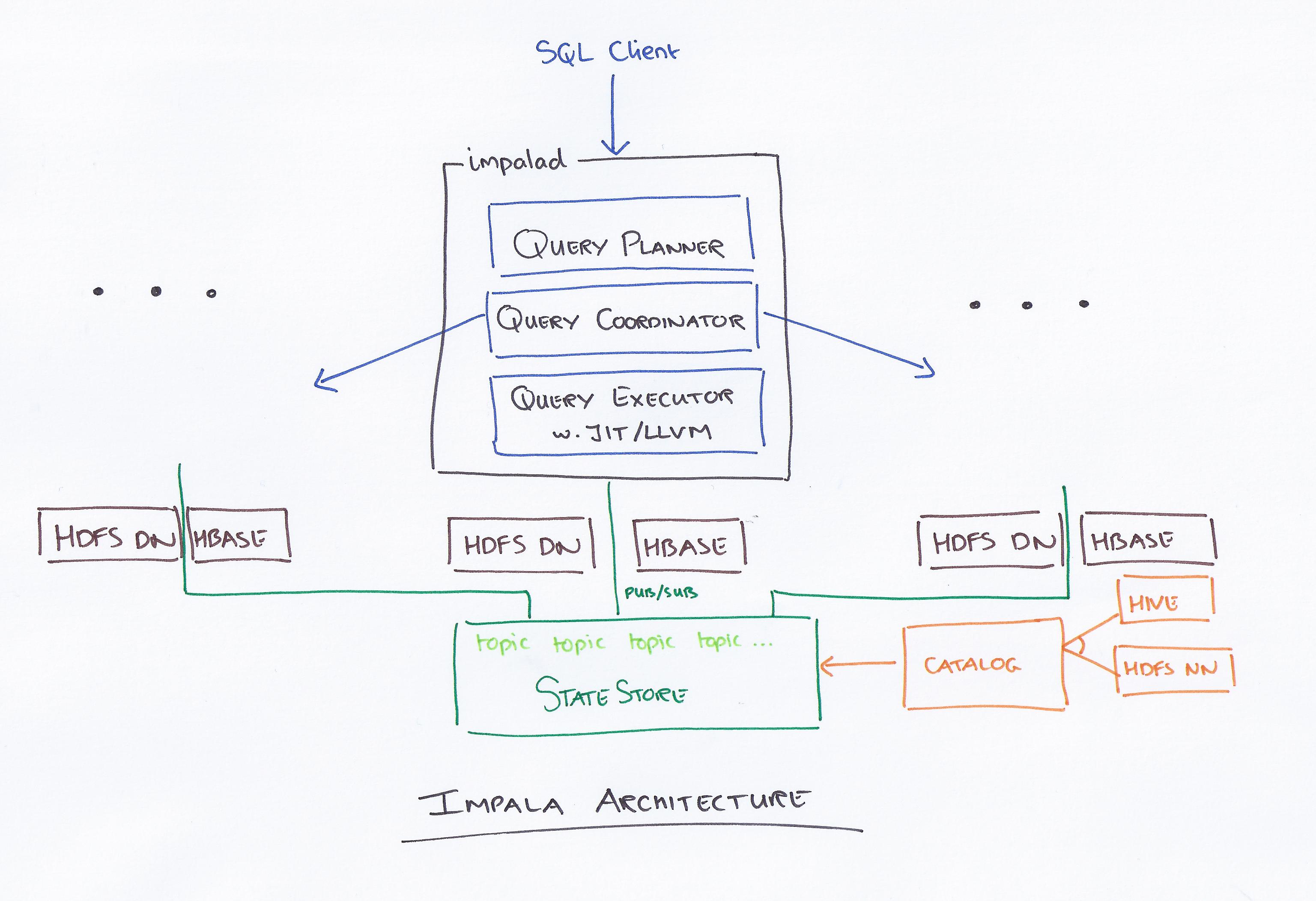
Impala, kierowana przez Clouderę, to nowy system zapytań. Hadoop ma HDFS i HBase, więc może wyszukiwać przechowywane tam duże zbiory danych na poziomie PB. Technologia ta bazuje na gałęzi i pamięci obliczeniowej, a także uwzględnia hurtownię danych i zapewnia przetwarzanie wsadowe w czasie rzeczywistym oraz wielokrotne przetwarzanie współbieżne. Klient wysyła żądanie zapytania do węzła w sieci impalad, gdzie zwracany jest identyfikator zapytania dla kolejnych operacji klienta. Podczas pierwszego etapu procesu tworzenia analizatora generowany jest autonomiczny plan wykonania (plan pojedynczej maszyny, rozproszony plan wykonania), a także wykonywany jest SQL, taki jak zmiany kolejności łączenia, wypychanie predykatów i tak dalej. Wszystkie węzły przechowują kopię najnowszych metadanych, aby upewnić się, że nie wypadniesz z pętli. Przed użyciem Hadoop, Hive lub Impurbia należy najpierw zainstalować niezbędne oprogramowanie do przetwarzania danych.
Plik konfiguracyjny Impala można zmienić. Każdy węzeł dokonuje zmiany konfiguracji w Impala. Wszystkie węzły są odpowiedzialne za połączenie pakietu sterowników MySQL z bazą danych. Węzły zmieniają ścieżkę Java Bigtop.
Porównanie Hive i Impala
Istnieje również kilka drobnych różnic, oprócz tych trzech głównych. W Hive istnieje podzbiór HiveQL, podczas gdy w Implicit istnieje podzbiór HiveQL. Hive i Impala są używane odpowiednio do hurtowni danych i interaktywnych zapytań. Hive, w przeciwieństwie do Impala, nie jest przeznaczony do obliczeń interaktywnych.
Co to jest Impala w Hadoop
Impala to silnik zapytań SQL o otwartym kodzie źródłowym dla danych przechowywanych w klastrze Hadoop. Jest przeznaczony do dostarczania szybkich, interaktywnych zapytań SQL dotyczących danych przechowywanych w HDFS, HBase lub dowolnym innym źródle danych Hadoop .
Impala wykorzystuje szeroką gamę znanych komponentów Hadoop . INSERT może zapisywać tylko dane typu, który Impala może odczytać, podczas gdy SELECT może odczytywać dane typu, który Impala może odczytać. W przypadku korzystania z formatu pliku Avro, RCFile lub SequenceFile dane są ładowane do programu Hive. Oprócz statystyk tabel i kolumn można używać statystyk tabel i statystyk kolumn. Wszystkie instrukcje DDL i DML są automatycznie aktualizowane przy użyciu demona katalogu w Impala 1.2 i nowszych, jeśli są wysyłane przez demona katalogu. Metoda INVALIDATE METADATA zwraca metadane dla wszystkich tabel w magazynie metadanych, do których uzyskano dostęp. Pliki danych są przechowywane w katalogach dla nowej tabeli i są odczytywane niezależnie od nazwy pliku, gdy Impala jest uruchomiona.
Ogólnie rzecz biorąc, Apache Hive dobrze sprawdza się jako platforma do przechowywania danych, podczas gdy Impala lepiej nadaje się do przetwarzania równoległego. Hive jest odporny na awarie, podczas gdy Impulsa nie.
Apache Impala
Apache Impala to szybki, interaktywny silnik zapytań SQL dla Apache Hadoop. Umożliwia użytkownikom wysyłanie zapytań SQL o niskim opóźnieniu do danych przechowywanych w HDFS i Apache HBase bez konieczności przenoszenia lub przekształcania danych.
Koncepcja architektury Impala umożliwia obsługę interaktywnych zapytań przy użyciu HDFS wydajniej niż jakikolwiek inny silnik zapytań. Hive jest znacznie wolniejszy ze względu na operacje we/wy dysku, ale Apache jest znacznie szybszy, ponieważ to zupełnie inny silnik. Nie ma rozróżnienia między Impulsa i Presto, ponieważ Impulsa wykorzystuje znacznie szybszą technologię, a Presto wykorzystuje podobną architekturę. Jeśli chodzi o pilniki do parkietu, najlepiej radzi sobie Impala. Określ, które dane należy podzielić na partycje na podstawie zapytań analityków. Dzięki Compute Stats Statistics Twoje zapytania będą znacznie łatwiejsze, zwłaszcza jeśli dotyczą więcej niż jednej tabeli (złączenia). Cztery razy w tygodniu mieliśmy awarię serwera katalogu Impala, a nasze zapytania trwały zbyt długo.
Ponadto ilość tworzonych przez nas plików znacznie wpływa na wydajność naszych zapytań. W rezultacie zaczęliśmy zarządzać naszymi partycjami i łączyć je w optymalny rozmiar pliku około 256 MB. Stwierdzono, że każda partycja ma tylko jeden plik (chyba że jego rozmiar jest > 256 MB). Spośród wszystkich typów danych obsługiwanych przez Implicit należy wybrać najbardziej odpowiedni typ kolumny. Aby ograniczyć liczbę równoczesnych zapytań lub pamięć Y dostępną dla użytkownika, użyj kontroli dostępu Impala. Jeśli zapytanie trwa dłużej niż 30 minut, jest uważane za martwe.
Najlepszy silnik dla Big Data: Impala
Silnik Impala to silnik przetwarzania danych Hadoop zaprojektowany specjalnie dla dużych klastrów. Zużywa znacznie mniej energii i zużywa znacznie mniej zasobów niż standardowy silnik MapReduce firmy Hadoop. Implicit wykorzystuje rozproszony system plików HDFS jako podstawowy nośnik danych, opierając się na redundancji HDFS, aby zapobiec awariom sprzętu lub sieci na zasadzie węzeł po węźle. Pliki danych, które reprezentują dane tabeli, są fizycznie reprezentowane przez znane formaty plików HDFS i kodeki kompresji.
Silnik zapytań z przetwarzaniem równoległym
Mechanizm zapytań przetwarzania równoległego to typ aparatu bazy danych, który jest przeznaczony do równoległego przetwarzania zapytań. Można to zrobić za pomocą wielu procesorów, wielu rdzeni lub wielu maszyn. Przetwarzanie równoległe może znacznie poprawić wydajność aparatu zapytań, zwłaszcza w przypadku złożonych zapytań.
Komputer wieloprocesorowy służy do przekształcania złożonych zapytań w plany wykonania, które można wykonywać jednocześnie, co pozwala na przetwarzanie dużych ilości danych jednocześnie. Wysoka wydajność wymaga wydajnego wykonania, takiego jak dobry czas odpowiedzi na zapytanie lub wysoka przepustowość zapytania. Osiąga się to poprzez zastosowanie wydajnych technik wykonywania równoległego i optymalizacji zapytań.
Przetwarzanie równoległe: przyszłość ETL?
Zapytanie wysokiego poziomu można przekształcić w plan wykonania, który może być skutecznie wykonany przez komputer wieloprocesorowy przy użyciu równoległego przetwarzania zapytań. Przetwarzanie równoległe wykorzystuje technikę łączenia danych równoległych i rozproszonych, a także różne techniki wykonania zapewniane przez system równoległej bazy danych . Równoległe przetwarzanie zapytań jest realizowane w ETL poprzez podzielenie zestawu rekordów w każdej tabeli źródłowej przeznaczonej do przesłania na porcje o tej samej wielkości, a następnie wykonanie procesu transformacji danych dla każdej tabeli źródłowej w cyklu, wybierając kolejno dane, porcja po porcji .