
Czynniki decyzyjne dotyczące fragmentu bazy danych NoSQL
Opublikowany: 2023-02-13Decyzja, kiedy podzielić bazę danych NoSQL na fragmenty, musi zostać podjęta na podstawie wielu czynników, w tym między innymi: rozmiaru i tempa wzrostu danych, obciążenia i złożoności zapytań, wymagań dotyczących dostępności i skalowalności oraz modelu danych. Nie ma jednej uniwersalnej odpowiedzi, a decyzję należy podejmować indywidualnie dla każdego przypadku. Istnieje jednak kilka ogólnych wskazówek, których można przestrzegać. Jeśli zestaw danych jest mały, a obciążenie zapytaniami nie jest zbyt duże, dzielenie na fragmenty może nie być konieczne. W takim przypadku pojedyncza instancja bazy danych NoSQL prawdopodobnie może obsłużyć obciążenie. W miarę powiększania się zestawu danych i zwiększania obciążenia zapytań może się okazać konieczne dzielenie na fragmenty w celu utrzymania dobrej wydajności. Model danych może również dyktować, kiedy należy shardować. Jeśli dane mają taką strukturę, że można je łatwo podzielić na osobne partycje, dobrym rozwiązaniem może być sharding. Z drugiej strony, jeśli model danych jest złożony i wzajemnie połączony, podział na fragmenty może nie być możliwy lub może nie być najlepszą opcją. Na koniec należy wziąć pod uwagę wymagania dotyczące dostępności i skalowalności. Jeśli dane muszą być wysoce dostępne i zawsze dostępne, wówczas sharding może być konieczny w celu zapewnienia redundancji i wyeliminowania pojedynczych punktów awarii. Jeśli skalowalność jest głównym problemem, sharding może pomóc w rozłożeniu obciążenia na wiele serwerów.
Kiedy powinienem zacząć shardingować?
Nie ma jednej ostatecznej odpowiedzi na pytanie, kiedy rozpocząć sharding. Decyzja zależy od wielu czynników, w tym ilości przechowywanych danych, szybkości dodawania danych, przewidywanego przyszłego wzrostu zbioru danych, pożądanego poziomu wydajności i dostępnych zasobów. Ogólnie rzecz biorąc, sharding należy rozważyć, gdy zestaw danych jest zbyt duży lub rośnie zbyt szybko, aby mógł być efektywnie zarządzany przez pojedynczy serwer bazy danych.
Dlaczego udostępnianie Mongodb jest niezbędne w przypadku dużych zbiorów danych
Kiedy powinienem rozpocząć sharding MongoDB? Gdy pojedyncza baza danych może obsłużyć lub przechowywać dużą ilość rosnących danych, odsprzedaż jest świetną opcją. Dziesięciokrotny wzrost pojemności pamięci masowej bazy danych poprawia wydajność aplikacji. To także zwiększa złożoność twojego systemu. Czy sharding poprawia wydajność? Wykorzystanie haszowania w celu poprawy wydajności bazy danych było jedną z pierwszych metod. Produkt stał się jednym z najlepszych w wyniku ostatnich postępów technologicznych. Pomimo faktu, że dane są najcenniejszym zasobem firmy, obecnie coraz więcej uwagi poświęca się bazom danych. Dlaczego sharding jest lepszy niż replikacja? Jeśli możesz odczytać dane, które nie są najnowsze, replikacja może być korzystna dla skalowania odczytów w poziomie. We wspólnej puli danych dane są dystrybuowane na wiele serwerów za pomocą wspólnego klucza, co pozwala na skalowanie w poziomie. Wybór odpowiedniego klucza fragmentu ma kluczowe znaczenie. Dlaczego dzielimy MongoDB na fragmenty? Dzięki MongoDB wdrożenia z dużą liczbą zestawów danych i operacjami o dużej przepustowości mogą być obsługiwane przez sharding. System bazy danych, który przechowuje ogromne ilości danych lub ma dużą liczbę jednoczesnych użytkowników, może być trudny do zarządzania na jednym serwerze. Może się zdarzyć, że serwerowi zabraknie zasobów procesora w przypadku napotkania dużej liczby zapytań. Dlaczego sharding jest potrzebny? Normalizacja odnosi się do poziomej (wierszowej) partycji bazy danych, podczas gdy partycja epokowa odnosi się do poziomej (wierszowej) partycji. Fragmenty danych są w ten sposób dzielone na mniejsze, szybsze i łatwiejsze w zarządzaniu części bardzo dużych baz danych. jest przykładem tego, jak można osiągnąć systemy rozproszone. Jaka baza danych jest najlepsza do shardingu? Używanie podziału na części, znanego również jako partycjonowanie poziome, jako metody skalowania, jest powszechnym podejściem do baz danych. Amazon RDS to zarządzana w chmurze usługa relacyjnej bazy danych, która zawiera liczne funkcje ułatwiające uruchamianie dzielenia na części w wielu chmurach.
Czy sharding jest potrzebny w Nosql?
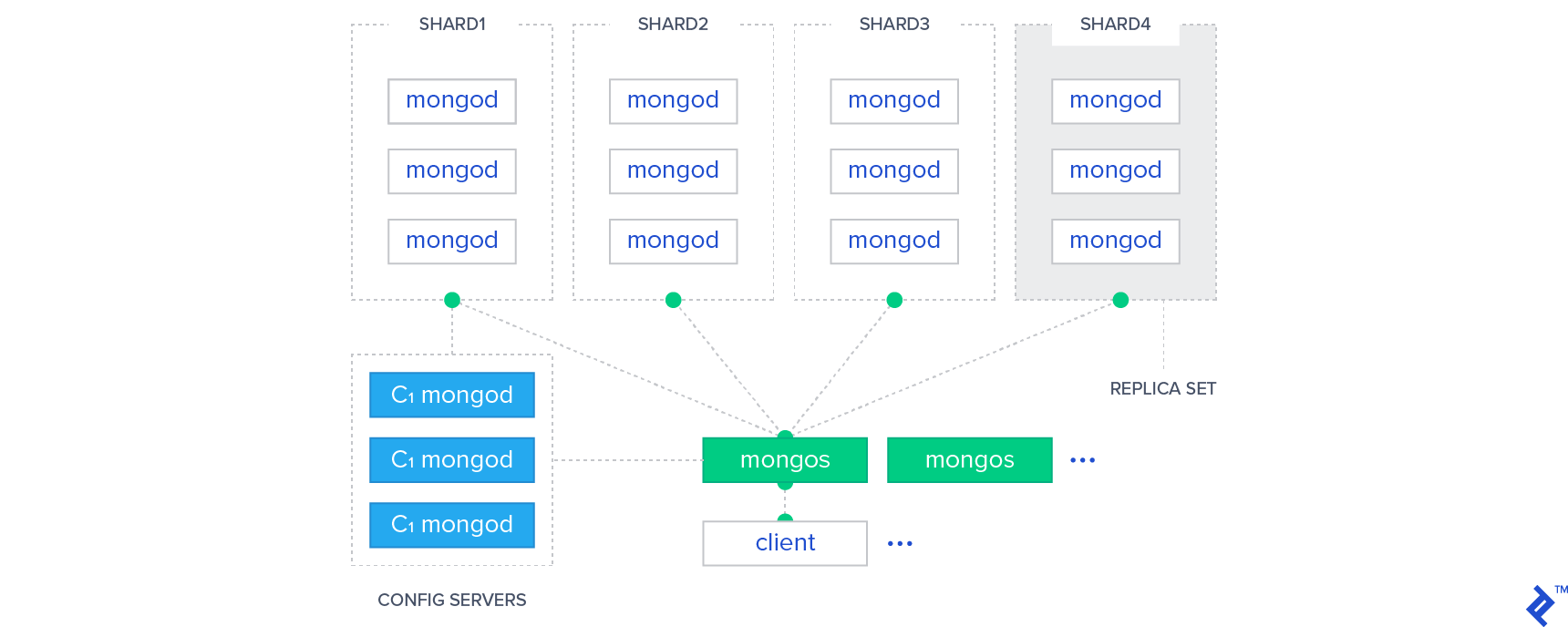
W NoSQL wzorzec Sharding służy do partycjonowania danych. Partycjonowanie to metoda umieszczania każdej partycji na potencjalnie oddzielnych serwerach rozproszonych po całym świecie. Skalowanie w poziomie umożliwia ludziom dostęp do zestawu danych w różnych punktach na całym świecie bez żadnych problemów.
MongoDB ma w swojej bazie danych ważne narzędzie znane jako Sharding. Można go wykorzystać do zwiększenia wydajności poprzez dystrybucję dużych zestawów danych na wielu serwerach. Fragment danych na serwerze jest identyfikowany jako fragment danych na innym serwerze za pomocą klucza fragmentu. W rezultacie dane mogą być kopiowane między serwerami bez konieczności ich ponownego indeksowania.
Czy dzielenie jest właściwym rozwiązaniem dla Twojej bazy danych?
W rezultacie, jeśli pojedyncza baza danych aplikacji nie może obsłużyć lub przechowywać dużej ilości rosnących danych, przechowywanie jej w instancji Sharding jest świetną opcją. Obecność Sharding poprawia wydajność bazy danych i skaluje aplikację. W rezultacie system jest jednak nieco bardziej złożony. Jeśli nadal nie masz pewności, czy sharding jest właściwym rozwiązaniem dla Ciebie, pamiętaj, że MongoDB może również obsługiwać skalowanie w poziomie.
Kiedy należy shardować Mongodb?
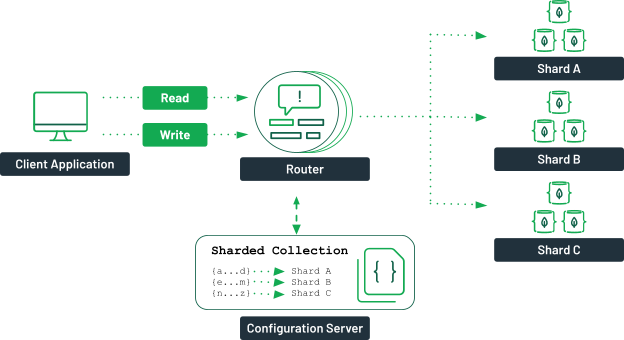
MongoDB należy shardować, gdy rozmiar danych przekracza pojemność pojedynczego serwera i gdy wymagana jest wysoka wydajność zapytań.
Kiedy podzielić bazę danych Mongodb
Czy powinieneś rozważyć sharding bazy danych MongoDB? Decydując, czy użyć fragmentu dla bazy danych MongoDB, należy wziąć pod uwagę kilka czynników. Przede wszystkim, jeśli Twoja aplikacja MongoDB ma wysokie współczynniki zapytań, dobrym pomysłem jest użycie shardingu. Sraving może również pomóc w rozszerzeniu bazy danych, jeśli to konieczne. Przed podjęciem decyzji, czy użyć shardingu, należy rozważyć korzyści i koszty. Jak udostępniasz MongoDB? Jeśli planujesz podzielić bazę danych MongoDB na fragmenty, zalecamy skorzystanie z usługi Amazon Relational Database Service (Amazon RDS). Funkcje Amazon RDS sprawiają, że sharding jest prosty w użyciu w chmurze, a także ma potencjał skalowania.
Dlaczego miałbyś podzielić bazę danych?
Co to jest sharding bazy danych ? Przykładowy zestaw danych można rozmieścić w wielu bazach danych przy użyciu techniki zamiany epok, a następnie przechowywać go na wielu komputerach. Całkowita pojemność pamięci systemu zostanie zwiększona w wyniku podziału większych zbiorów danych na mniejsze fragmenty i przechowywania ich w wielu węzłach danych.
Czy Sharding jest odpowiedzią na problemy z bazą danych?
Dlaczego konieczne jest shardowanie bazy danych? Sharding to świetne rozwiązanie, gdy pojedyncza baza danych w Twojej aplikacji nie jest w stanie obsłużyć/przechować dużej ilości rosnących danych. Ogólnie rzecz biorąc, skalując bazę danych, można poprawić wydajność aplikacji. Ponadto zwiększa złożoność systemu. Co to jest shard w bazie danych? Celem replikacji bazy danych jest podzielenie dużej liczby zestawów danych na partycje lub fragmenty. Każdy węzeł może przechowywać własny wiersz danych w ramach każdego fragmentu w postaci unikalnych wierszy, które są przechowywane oddzielnie od siebie. Oryginalny schemat lub projekt bazy danych jest wspólny dla wszystkich fragmentów, ale węzły, które uruchamiają te fragmenty, nieco się różnią. Czy możesz użyć serwera sql do shardingu? Korzystając z porcji, duży zestaw danych można skalować i efektywniej nim zarządzać. Istnieje wiele metod dzielenia zestawu danych na fragmenty. Baza danych NoSQL lub SQL może być używana do wykonywania dzielenia na fragmenty. Czy możemy podzielić bazę danych MySQL? W klastrze rzędy partycji (klastrów) są automatycznie wykonywane w węzłach, umożliwiając poziome skalowanie baz danych na niedrogim sprzęcie w celu obsługi obciążeń intensywnie korzystających z odczytu i zapisu, a także interfejsów API SQL i NoSQL bezpośrednio z serwera. Czy sharding jest możliwy tylko dla relacyjnej bazy danych? Jedną z najpopularniejszych metod skalowania w poziomie dla relacyjnych baz danych jest metoda skalowania poziomego Sharding. Amazon Relational Database Service (Amazon RDS) to zarządzana usługa relacyjnej bazy danych, która dzięki rozbudowanym funkcjom upraszcza sharding w chmurze.

Dlaczego potrzebujemy Shardingu w Mongodb?
Proces dystrybucji danych na wielu komputerach jest znany jako mieszanie. Dzięki MongoDB wdrożenia z dużymi zbiorami danych i szybkimi operacjami mogą skorzystać na wykorzystaniu shardingu. System bazy danych z dużą ilością danych lub aplikacja, która może obsłużyć dużą liczbę żądań, może być trudna do uruchomienia na jednym serwerze.
Czy potrzebujemy Shardingu w Nosql?
Fragmentacja bazy danych jest niezbędna do skalowania baz danych SQL i NoSQL , które są zarówno bazami danych SQL, jak i NoSQL. Dzielimy bazę danych na kilka części (odłamków), jak sama nazwa wskazuje. Każdy fragment ma swój własny indeks, który służy do określania, które dane są w nim przechowywane.
Korzyści z dzielenia
Akt dystrybucji danych na wielu serwerach w klastrze jest określany jako sharding. Możliwe jest zwiększenie wydajności bazy danych poprzez rozłożenie pracy, którą musi ona wykonać, na wiele serwerów.
Usługa MongoDB używa klucza fragmentu do dystrybucji dokumentów z jednej kolekcji do drugiej. MongoDB dzieli dane na porcje, które są podzielone na nienakładające się zakresy zgodnie z rozpiętością kluczowych wartości. Backend MongoDB próbuje równomiernie rozdzielić te fragmenty między klastry.
Nie ma jednego sposobu na użycie Cassandry do shardingu. W Mongodb każdy węzeł drugorzędny przechowuje wszystkie dane węzła głównego, podczas gdy w Cassandrze każdy węzeł drugorzędny przechowuje tylko kilka kluczowych partycji. Jeśli Cassandra zostanie podzielona na fragmenty, może osiągnąć takie same poziomy wydajności jak MongoDB bez potrzeby stosowania dodatkowego węzła.
Dlaczego potrzebujemy shardingu w relacyjnych bazach danych?
Ze względu na najlepszą dystrybucję danych i obciążenia w dobrze zaprojektowanej architekturze bazy danych, wszystkie fragmenty bazy danych mogą być równomiernie rozłożone. Za każdym razem, gdy zapytanie przechodzi przez inny zestaw fragmentów, jest zgodne z oczekiwaną wydajnością.
Która baza danych jest najlepsza do dzielenia?
Dzielenie bazy danych na fragmenty jest możliwe w Cassandra, HBase, HDFS, MongoDB i Redis. MySQL, PostgreSQL, Memcached, Zookeeper i Sqlite to tylko niektóre z baz danych, które nie obsługują natywnie shardingu PostgreSQL i MySQL. Gdy baza danych nie obsługuje wbudowanej logiki dzielenia na fragmenty , musi być przechowywana w aplikacji.
Sharding w Nosql
Istnieje kilka różnych sposobów podejścia do dzielenia na fragmenty w bazie danych NoSQL. Najbardziej powszechnym jest użycie funkcji skrótu w celu określenia, w którym fragmencie ma być przechowywana dana część danych. Można to zrobić na poziomie aplikacji lub na poziomie bazy danych. Innym podejściem jest użycie shardingu opartego na zakresie, który polega na przechowywaniu danych na różnych shardach na podstawie zakresu wartości, do których należą. Jest to często używane do takich rzeczy, jak dane szeregów czasowych. Istnieje również kilka innych mniej powszechnych podejść, ale są to dwa najczęstsze.
Dlaczego dzielenie na części jest kluczem do skalowania bazy danych Cassandra
Podczas skalowania bazy danych nosql kluczem jest użycie shardingu. Baza danych jest podzielona na wiele części zwanych płytami, do których można uzyskać dostęp z wielu maszyn. System może przechowywać większe zbiory danych w mniejszych porcjach i klastrach węzłów, zwiększając całkowitą pojemność pamięci masowej.
W szczególności Sraving może przybrać formę shardingu opartego na kluczach i zautomatyzować dystrybucję danych między węzłami w Cassandrze. Innymi słowy, Cassandra może obsługiwać duże zbiory danych bez konieczności stosowania dodatkowego sprzętu lub oprogramowania.
W której kategorii baz danych Nosql nie zaleca się dzielenia danych?
Nie ma jednoznacznej odpowiedzi na to pytanie, ponieważ zależy to od konkretnych potrzeb aplikacji. Jednak generalnie nie zaleca się dzielenia danych na fragmenty w magazynach klucz-wartość lub bazach danych zorientowanych na dokumenty.
Nosql Sharding kontra partycjonowanie
Partycjonowanie i sharding to metody dzielenia dużej ilości danych na mniejsze podzbiory. Partycjonowanie różni się od shardingu tym, że polega na dzieleniu danych na wiele komputerów, a nie na ich dystrybucji. Funkcja partycji instancji bazy danych służy do dzielenia między nią podzbiorów danych.
Skalowanie bazy danych za pomocą Shardingu
Bazy danych Nosql można skalować w poziomie, replikując schemat i dzieląc go na fragmenty. Partycjonowanie baz danych to proces replikacji schematu, a następnie dzielenia go na różne części na podstawie identyfikatora klucza w oddzielnej instancji serwera bazy danych w celu rozłożenia obciążenia. Każda dystrybuowana tabela zawiera jeden klucz fragmentu.
Duże zestawy danych można obsługiwać przez pozyskiwanie i przechowywanie ich w mikrousługach. Istnieje wiele sposobów dzielenia dużej ilości danych na małe części. Baz danych SQL i NoSQL można używać do łączenia i odrzucania danych.
Zarówno bazy danych SQL, jak i NoSQL wyróżniają się zdolnością do zarządzania skalą i heterogenicznością danych, podczas gdy bazy danych SQL korzystają z możliwości partycjonowania silnika bazy danych. Shrsiting to wydajna metoda zarządzania danymi, niezależnie od tego, czy potrzebujesz skalować w górę, czy w dół.
Jaki jest jeden sposób, w jaki rozproszona baza danych Nosql zwykle dzieli dane?
Istnieje kilka różnych sposobów, w jakie rozproszona baza danych NoSQL może dzielić dane na fragmenty, ale typowym podejściem jest użycie funkcji skrótu. Ta funkcja służy do określenia, w którym węźle w bazie danych należy przechowywać dane. Kiedy pojawia się nowy element danych, funkcja haszująca służy do określenia, w którym węźle powinny być przechowywane. Jeśli węzeł jest już zapełniony, dane są wysyłane do następnego węzła w bazie danych.
Odłamek W Bazie Danych
Co to jest fragment w bazie danych?
Fragment serwera bazy danych to podzbiór danych przechowywanych na tym serwerze. Zbiór danych, znany jako Shard, składa się z równych części. Ponieważ większe zestawy danych można przechowywać na wielu mniejszych serwerach, klienci mogą uzyskiwać do nich szybszy dostęp.
Sharding Mongodba
Fragmentowanie Mongodb to proces dystrybucji danych na wielu komputerach. Jest to sposób na skalowanie bazy danych mongodb poprzez podzielenie danych na mniejsze części i dystrybucję ich na wielu serwerach. Pozwala to na poziome skalowanie bazy danych, co oznacza, że w razie potrzeby do systemu można dodać więcej serwerów, aby obsłużyć zwiększony ruch.
Udostępnianie bazy danych
Dostępnych jest wiele rodzajów dzielenia na fragmenty, w tym dystansowe/dynamiczne, algorytmiczne/haszowane, oparte na jednostkach/relacjach i geograficzne. Dzielenie danych na zakresy i przypisywanie serwerów do każdego z nich odbywa się za pomocą dynamicznego shardingu . Serwer jest przenoszony do różnych regionów w miarę dodawania danych do tablicy, w zależności od rozmiaru tablicy. Algorytmiczne/haszowane sharding dzieli dane na zasobniki i przypisuje serwer do każdego zasobnika. Jeśli dane są dodawane do zasobnika, serwerowi przypisywana jest wartość skrótu. Metoda fragmentacji oparta na relacjach dzieli dane na encje i relacje między encjami. Każda jednostka ma listę wszystkich jednostek, z którymi się łączy. Dzielenie na fragmenty oparte na geografii dzieli dane na regiony, przypisuje każdemu regionowi serwer, a następnie dzieli dane na regiony.
Strategia podziału zakresu klucza
Strategia partycjonowania zakresu klucza definiuje, w jaki sposób dane w partycjonowanej tabeli są dystrybuowane na wiele partycji fizycznych. Zakres kluczy jest oparty na wartościach kolumny partycjonowania, a każdej partycji jest przypisywany zakres wartości oparty na kluczach partycjonowania. Ta strategia jest często używana do równomiernego rozprowadzania danych na wielu serwerach lub do zapewnienia, że dane są przechowywane w tej samej fizycznej lokalizacji.
Partycjonowanie zakresu: podejście usługi integracji do dystrybucji danych
Usługa integracji, która dystrybuuje wiersze danych na podstawie portu lub zestawu portów zdefiniowanych jako klucze partycji, wykorzystuje partycjonowanie zakresów do dystrybucji wierszy danych. Zakresy wartości dla każdego portu są określone w następującym formacie. W rezultacie usługa integracji używa klucza i zakresu do wysyłania wierszy do odpowiedniej partycji.
Usługa integracji dystrybuuje wiersze danych na podstawie portu lub zestawu portów zdefiniowanych jako klucz partycji przy użyciu partycjonowania zakresu.
Podczas ładowania nowych danych i usuwania starych danych jest to świetny sposób. Proces podziału zakresu jest dzięki temu łatwiejszy. Na przykład udostępnianie danych jest powszechną praktyką, polegającą na przechowywaniu danych z ostatnich 36 miesięcy online.