
Bazy danych NoSQL: alternatywa dla tradycyjnych relacyjnych baz danych
Opublikowany: 2023-01-13Bazy danych NoSQL stają się coraz bardziej popularne jako alternatywa dla tradycyjnych relacyjnych baz danych. Baza danych NoSQL nie wymaga stałego schematu i jest łatwa do skalowania. Kolejka jest rodzajem magazynu danych NoSQL. Kolejka to struktura danych, w której dane są przechowywane na zasadzie FIFO (pierwsze weszło, pierwsze wyszło). Kolejka jest często używana do przechowywania danych, które muszą być przetwarzane w kolejności sekwencyjnej, na przykład listy zadań do wykonania. Kolejka jest rodzajem magazynu danych NoSQL, ponieważ nie wymaga stałego schematu. Kolejkę można łatwo skalować wraz ze wzrostem liczby zadań.
Jeśli mam zamiar używać MongoDB lub RavenDB jako kolejki komunikatów , którą wolę? Obiekt wiadomości może zostać wysłany do usługi internetowej za pośrednictwem klienta, a następnie pobrany przez usługę internetową. Usługa, która wykonuje pracę, może następnie wybrać typ komunikatu na podstawie dowolnych kryteriów, które mogą się pojawić. Mogę tworzyć indeksy na podstawie scenariuszy, aby przyspieszyć działanie. Jeśli budujesz tylko kolejkę, powinieneś rozważyć NoSQL do niczego więcej. Najprawdopodobniej będzie to miało większy wpływ na wydajność, niezawodność i efektywność, jeśli podejmiesz decyzję, której implementacji chcesz użyć.
Bazy danych NoSQL (znane również jako SQL) przechowują dane inaczej niż relacyjne bazy danych, oprócz tego, że nie są tabelaryczne. Baza danych NoSQL może występować w wielu różnych typach w zależności od jej modelu danych. Najczęściej używane są typy dokumentów, typy klucz-wartość, typy szerokich kolumn i wykresy.
Datastore to wysoce skalowalna baza danych NoSQL, która obsługuje szeroki zakres aplikacji. W rezultacie Datastore automatycznie zarządza shardingiem i replikacją, umożliwiając korzystanie z wysoce dostępnej i trwałej bazy danych , która automatycznie skaluje się w celu obsługi obciążenia aplikacji.
Który jest magazynem danych Nosql?
Istnieje wiele różnych typów magazynów danych NoSQL, z których każdy ma swoje mocne i słabe strony. Najpopularniejsze magazyny danych NoSQL to MongoDB, Cassandra i HBase.
Oparte na dokumentach bazy danych NoSQL przechowują dane wydajniej niż relacyjne bazy danych. Mają być elastyczne, skalowalne i zdolne do szybkiego reagowania na wymagania biznesowe w zakresie zarządzania danymi. Typy baz danych, które są powszechnie określane jako NoSQL, obejmują czyste bazy danych dokumentów, magazyny klucz-wartość, szerokokolumnowe bazy danych i bazy danych wykresów. Firmy z listy Global 2000 szybko wdrażają bazy danych NoSQL do obsługi aplikacji o znaczeniu krytycznym. Wynika to z pięciu trendów, które stanowią wyzwania techniczne, które utrudniają korzystanie z większości relacyjnych baz danych. Zarządzanie bazami danych jest główną przeszkodą w zwinnym rozwoju, ponieważ brakuje im możliwości obsługi stałego modelu danych, który jest niezbędny do zwinnego programowania. Model aplikacji definiuje model danych w NoSQL.
Modelowanie danych w NoSQL nie jest statyczne. Format JSON jest domyślnym formatem przechowywania danych w bazie danych zorientowanej na dokumenty. Eliminuje to potrzebę stosowania frameworków ORM i usprawnia proces programowania. N1QL (wymawiane nikiel), potężny język zapytań, który rozszerza SQL do formatu JSON, został udostępniony jako część Couchbase Server 4.0. Ponadto zawiera obsługę standardowych instrukcji SELECT / FROM / WHERE, a także agregację (GROUP BY), sortowanie (SORT BY), łączenie (LEFT OUTER / INNER) i inne. Ze względu na skalowalną architekturę i brak pojedynczego punktu awarii, rozproszone bazy danych NoSQL mają istotne zalety operacyjne. Dostępność staje się poważnym problemem, ponieważ coraz więcej klientów wchodzi w interakcje z firmami online i za pośrednictwem aplikacji mobilnych.
Bazy danych NoSQL są proste w instalacji, konfiguracji i skalowaniu. Dzięki rozproszonym odczytom, zapisom i przechowywaniu zostały zaprojektowane tak, aby czytanie, pisanie i przechowywanie było proste. Mogą działać w szerokim zakresie skal, w tym zarządzać i monitorować klastry o różnej wielkości. Nie ma potrzeby opracowywania oprogramowania do replikacji między centrami danych; rozproszona baza danych NoSQL obejmuje wbudowaną replikację między centrami danych. Ponadto umożliwia aplikacjom samodzielne przełączanie awaryjne zamiast czekania, aż baza danych wykryje problem i przeprowadzi proces odzyskiwania oparty na bazie danych. Bazy danych NoSQL są coraz częściej wykorzystywane w aplikacjach internetowych, mobilnych i IoT ze względu na łatwość obsługi i integracji.
Przechowywanie tabel to doskonałe rozwiązanie dla danych, które nie są przechowywane w relacyjnej bazie danych. Magazyn tabel umożliwia przechowywanie danych w kontenerze, który jest wystarczająco elastyczny, aby dostosować się do rozwoju aplikacji. System przechowywania tabel może być używany do przechowywania danych, które są trudne do przechowywania w modelu relacyjnym, takich jak dane wideo lub obrazy.
Bazy danych Nosql platformy Azure: Documentdb, Graph i Keyvalue
Trzy typy baz danych NoSQL na platformie Azure to Azure DocumentDB, Azure Graph i Azure KeyValue. Dzięki Azure DocumentDB nie ma potrzeby zarządzania plikami danych na serwerze ani pobierania ich z archiwów; jest bezserwerowy, klucz-wartość i może obsłużyć do miliona żądań na sekundę. Jest to baza danych wykresów, której można używać do wykonywania zapytań i zarządzania danymi w wielu warstwach w aplikacji. Azure Graph to baza danych wykresów, której można używać do wykonywania zapytań i zarządzania danymi w wielu warstwach w aplikacji. Umożliwia organizowanie i filtrowanie danych na sortowanych i filtrowanych listach usługi Azure KeyValue.
Czy kolejka jest bazą danych?
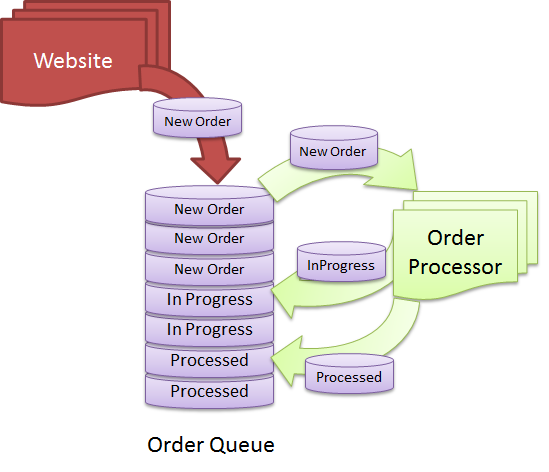
Nie ma ostatecznej odpowiedzi na to pytanie, ponieważ zależy to od tego, jak zdefiniujesz bazę danych. Ogólnie rzecz biorąc, baza danych to zbiór danych zorganizowanych w określony sposób, aby można było uzyskać do nich dostęp i aktualizować je w razie potrzeby. Kolejka to struktura danych, która umożliwia przechowywanie i pobieranie danych w określonej kolejności. Jeśli więc uznasz kolejkę za zbiór danych, można ją uznać za bazę danych. Jeśli jednak uznasz, że baza danych jest tylko zbiorem danych, do których można uzyskać dostęp i które można aktualizować, kolejka nie będzie uważana za bazę danych.
Kiedy jest właściwy czas na użycie bazy danych w systemie opartym na kolejkach? Niezwykle ważne jest utrzymanie uporządkowanej, zorganizowanej kolejki, aby wszystkie żądania były przetwarzane tak szybko, jak to możliwe. Istnieje kolejka komunikatów zaprojektowana do obsługi tego typu sytuacji, ułatwiająca usuwanie z kolejki lub umieszczanie wiadomości w kolejce. Wyobraź sobie, że masz w swojej bazie danych setki żądań utworzenia pliku PDF w dowolnym momencie. Pożądana jest możliwość ciągłego przetwarzania większej liczby żądań na sekundę. Nie ma potrzeby podłączania większej liczby pracowników (procesów obsługujących żądania), ponieważ rozwiązanie można skalować. Aby otrzymać wniosek, pracownik będzie musiał podać dodatkową informację.
Kolejki komunikatów nie wymagają od użytkownika wykonywania żadnych transakcji w celu zapewnienia przechowywania i przetwarzania komunikatów. Zamiast ręcznego sondowania komunikatów z bazy danych, kolejki komunikatów są wypychane w czasie rzeczywistym. Jeśli zabraknie Ci mocy procesora podczas łączenia się ze zbyt wieloma połączeniami lub wykonywania innych zadań wymagających dużej mocy procesora, możesz użyć większej mocy procesora do zasilania serwera kolejki komunikatów. W przypadkach, gdy wymagana jest duża liczba komunikatów asynchronicznych, zdecydowanie zaleca się użycie kolejki komunikatów. Jeśli robotnik zginie podczas wykonywania zadania, należy go przetrzymać w kolejce do czasu rozpatrzenia żądania. Po odebraniu i przetworzeniu komunikatu pracownik wysyła potwierdzenie z powrotem do kolejki komunikatów, aby powiadomić go o postępie.
Kolejka to struktura danych, która może przechowywać kolekcję elementów w logicznej kolejności. Pozycje umieszczone w kolejce są przetwarzane jak najszybciej po dodaniu do kolejki. Kolejka może być przydatna, gdy chcesz przetwarzać elementy w określonej kolejności. Instrukcja SELECT to metoda, której można użyć do zmiany zawartości kolejki. Instrukcja SELECT to metoda, która umożliwia wybranie elementów z kolejki i wysłanie ich do innej lokalizacji, jeśli sobie tego życzysz. Instrukcja SELECT służy również do wysyłania elementów z innej lokalizacji do odpowiedniej kolejki , a także do wstawiania ich do kolejki. Instrukcja INSERT, UPDATE, DELETE lub TRUNCATE nie może próbować kierować kolejki. Jeśli musisz przetwarzać elementy w określonej kolejności, przydatna jest kolejka; nie należy jednak modyfikować pozycji w kolejce.

Znaczenie systemów kolejek w systemach baz danych
Baza danych z mechanizmami kolejkowania to doskonałe uzupełnienie każdego data center. Posiadanie funkcjonalności DBMS dla systemów kolejek ma kluczowe znaczenie, ponieważ mogą one być wykorzystywane do różnych celów. Integrując funkcje kolejek ze standardowym systemem baz danych , inne aplikacje mogą uzyskać do nich większy dostęp. Dzięki tej aktualizacji systemy kolejek są potężniejsze i bardziej wszechstronne, a ich użyteczność i potencjał są zwiększone.
Czy Mongodb ma kolejkę?
Kolejka to zbiór dokumentów, które są wstawiane do bazy danych MongoDB w porządku rosnącym na podstawie danych tworzenia dokumentu lub rankingu dokumentów na podstawie danego priorytetu.
Jeśli już używasz MongoDB, możesz użyć tej metody do tworzenia kolejek z ładnym interfejsem API. Jeśli masz sterownik MongoDB v3 lub starszą bazę danych, zalecana jest opcja mongodb- [email protected] . Ten pakiet jest sklasyfikowany jako kompletny i stabilny. Pomimo jego powszechnego zastosowania, dzieje się z nim bardzo niewiele nowych rzeczy. Daj nam znać, jeśli masz jakiekolwiek problemy lub używasz go nieprawidłowo. Każda utworzona przez Ciebie kolejka będzie osobną kolejką. Można utworzyć kolekcję MongoDB o nazwie resize-image-queue lub notify-owner-queue, z których można korzystać w obu przypadkach.
Jeśli nie otrzymasz wiadomości w ciągu 30 sekund po jej otrzymaniu, zostanie ona umieszczona z powrotem w kolejce, aby można było ją odzyskać. Przeszukaj swoją martwą kolejkę, aby sprawdzić, czy nie znaleziono żadnych martwych wiadomości. Kiedy zwracamy wszystkie komunikaty z oryginalnej kolejki do martwej kolejki when.get(), ładunkiem martwej kolejki jest komunikat. Jeśli przedmiot zostanie usunięty z kolejki, ale nie zostanie zatwierdzony, zostanie przeniesiony do tej martwej kolejki przy następnej próbie opuszczenia. Jeśli przedmiot zostanie usunięty z kolejki, ale nie zostanie zatwierdzony, zostanie przeniesiony do tej martwej kolejki przy następnej próbie opuszczenia. Kolejkę można nadal przeglądać, wysyłając wiadomość ping, aby powiedzieć, że żyjesz i przetwarzasz żądanie. Czas widoczności przekazywany podczas operacji ping jest również określany przez metodę // czas widoczności (w tym przypadku ta kolejka widziała %d komunikatów %d komunikatów %d liczy; ); // kolejka.ping(msg.ack, (err, id) = Liczba wiadomości, które znajdowały się w kolejce przez ostatnie 24 godziny, jak również wiadomości bieżące.
Możemy obliczyć liczbę otrzymanych nowych wiadomości, które nie zostały jeszcze aktywowane. Get.total() powinno być możliwe, jeśli dodasz up.size() +.inFlight() +.done() ale będzie to tylko przybliżone, ponieważ te dwie operacje są używane do obliczenia sumy. Czasami pory roku są bardzo różne. Użyj opcji setInterval, aby regularnie czyścić system. Console.log('Przetworzone wiadomości zostały usunięte z kolejki')*).
Kolejka Mongodba
Kolejki MongoDB (lub kolejki komunikatów) zapewniają mechanizm przechowywania komunikatów w uporządkowany sposób, pierwszy na wejściu, pierwszy na wyjściu. Wiadomości można wstawiać do kolejki w dowolnym momencie i będą one przetwarzane w kolejności ich otrzymania. To sprawia, że kolejki MongoDB są idealne do przetwarzania zadań, które muszą być wykonywane w określonej kolejności lub do zadań, które mogą być przetwarzane asynchronicznie.
Misją FloQast jest umożliwienie zespołom produktowym przyspieszenia i automatyzacji rozwoju innowacyjnych produktów. Tradycyjnie AWS SQS służył jako nasza usługa kolejki komunikatów . Spowodowało to problemy z utrzymaniem wykonalności i powielaniem. Zamiast tego wybraliśmy MongoDB jako naszą kolejkę wiadomości. W AWS Lambda możesz łatwo dodawać wiadomości do dowolnej kolejki. Eliminuje konieczność aktualizacji istniejących usług w celu korzystania z oddzielnej Lambdy. Po uzyskaniu dostępu do kolejki usługa wykorzystuje atomową metodę findAndModify MongoDB, aby pobrać pierwszy element i wywołać Lambda na podstawie instrukcji programisty.
Co to jest strumień zmian w Mongodb?
W czasie rzeczywistym twórcy aplikacji mogą obserwować zmiany w danych bez obawy, że śledzą swój oplog lub będą musieli radzić sobie ze złożonością i zagrożeniami związanymi ze złożonymi strukturami danych. Strumień zmian może być używany przez aplikację do subskrybowania wszystkich zmian danych w dowolnym zbiorze, bazie danych lub wdrożeniu i natychmiastowego reagowania na nie.
Użyj wyzwalaczy, aby zautomatyzować operacje na bazie danych
Używając mechanizmów wyzwalających, możesz zautomatyzować operacje na bazie danych i zwiększyć wydajność systemu. Gdy dokument jest dodawany, aktualizowany lub usuwany z połączonego klastra MongoDB Atlas, wyzwalacze mogą obsługiwać logikę po stronie serwera. Dzięki temu będziesz w stanie zapewnić płynne działanie systemu i zautomatyzować operacje na bazie danych.
Baza danych dokumentów Nosql
Baza danych NoSQL, zwana także nierelacyjną bazą danych, to baza danych, która nie wykorzystuje tradycyjnej struktury relacyjnej bazy danych opartej na tabelach. Bazy danych NoSQL są często używane w przypadku dużych zbiorów danych i aplikacji internetowych działających w czasie rzeczywistym.
Baza danych zorientowana na dokumenty to nowoczesny sposób przechowywania danych w formacie JSON zamiast tradycyjnych kolumn i wierszy. Te częściowo ustrukturyzowane dane można wykorzystać do rozwiązywania trudnych problemów, które w innym przypadku wymagałyby RDBMS. Magazyny dokumentów to naturalne i elastyczne rozwiązanie, z którego mogą korzystać programiści, którzy chcą szybciej pracować ze zwinnym oprogramowaniem. Możesz wysyłać zapytania na różne sposoby dzięki ekspresyjnemu językowi zapytań i wszechstronnym możliwościom indeksowania. Relacyjna baza danych ma zestaw gwarancji, które znasz podczas uruchamiania transakcji ACID. Posiadanie systemów rozproszonych umożliwia skalowanie i ochronę danych w bardziej wydajny i elastyczny sposób. Każdy dokument jest dystrybuowany na wielu serwerach w niezależnej jednostce, co zmniejsza potrzebę lokalizacji danych.
Bazy danych dokumentów są intuicyjne i proste w obsłudze, a ich szybkość transmisji danych jest większa niż w przypadku relacyjnych baz danych. Jakość danych będzie niższa, a tabele sztywne. Ponieważ nie można wykonać natywnego skalowania w poziomie, jeśli chcesz podzielić tradycyjną relacyjną bazę danych na partycje, musisz zapłacić za drogie systemy skalowania. W bazach danych zorientowanych na dokumenty można wybierać spośród szerokiej gamy typów dokumentów; jednak pola znajdujące się w każdym sklepie mogą być opcjonalne. Każdy dokument ma taką samą strukturę, ale różnią się jego polami. Każdy dokument ma swój unikalny identyfikator, którego można używać do dodawania, zmieniania, usuwania i wyszukiwania informacji. Zazwyczaj uważa się, że kodowanie dokumentów to proces przekształcania danych (lub informacji) w kapsułki w standardowy format.
Struktura bazy danych zorientowana na dokumenty jest mniej sztywna, a przez to mniej podatna na niespójność. W przypadku zapytania o informacje bezpośrednio z dokumentu, a nie z kolumn w bazie danych, dane są przechowywane bardziej bezpośrednio w dokumencie. Dane można dodawać do magazynu dokumentów za pomocą pojedynczego pola, które zawiera pola informacyjne dotyczące danych.