
Bazy danych NoSQL i niejednolite dane
Opublikowany: 2023-03-03Non Uniform Data in NoSQL to dane, które nie są zgodne ze schematem bazy danych. Może się to zdarzyć, gdy dane nie są poprawnie sformułowane, gdy nie są znormalizowane lub gdy nie są poprawne zgodnie z regułami bazy danych. Niejednolite dane w NoSQL mogą powodować problemy z wydajnością bazy danych, a także mogą powodować utratę danych.
Co to jest nierelacyjna baza danych Nosql?
Nierelacyjna baza danych to taka, która nie opiera się na schemacie tabelarycznym występującym w standardowej bazie danych. Z drugiej strony nierelacyjne bazy danych wykorzystują model przechowywania dostosowany do konkretnych potrzeb typu przechowywanych danych.
Oprogramowanie bazodanowe zaprojektowane dla chmury zapewnia korzyści, takie jak większa skalowalność, wydajność i elastyczność modelu danych niż tradycyjne relacyjne bazy danych . Technologie bazodanowe, takie jak NoSQL, zostały stworzone, aby były niezwykle elastyczne i proste w użyciu, a także niespecyficzne dla podejścia opartego na tabelach. Wszystkie typy danych, ustrukturyzowane i nieustrukturyzowane, można łatwo obsługiwać i skalować w celu ich przechowywania w opłacalny sposób. Jeśli chodzi o budowanie systemów personalizujących doświadczenie klienta, najpopularniejszym wyborem są bazy danych NoSQL. Jedną z podstawowych różnic między bazą danych NoSQL a relacyjną bazą danych jest jej skalowalność. Oprócz baz danych NoSQL masz możliwość wyboru takiej, która najlepiej odpowiada Twoim danym i celom. Baza danych wykresów to magazyn danych, który używa metafory grafu do łączenia relacji między danymi.
Wielomodelowe bazy danych zyskują na popularności zarówno na rynkach NoSQL, jak i RDBMS. Bazy danych NoSQL są zaprojektowane do obsługi zdecentralizowanych systemów, które są przeznaczone dla aplikacji w chmurze. Baza danych NoSQL w większości przypadków zapewnia następujące korzyści w porównaniu z innymi systemami zarządzania bazami danych: Nie wymaga predefiniowanego schematu. Możesz zmieniać typy i pola danych w locie. Kiedy używane są bazy danych NoSQL, zapewniają one stałą dostępność danych poprzez replikację ich kopii na wielu serwerach. Służy do replikacji bazy danych NoSQL na dwa sposoby: podstawowy/pomocniczy i peer-to-peer. Interfejsy API dla każdego modelu danych NoSQL, takie jak modele klucz-wartość, dokumenty, modele tabelaryczne i wykresy, są własne.
RDBMS są przeznaczone do odczytu, zapisu i dystrybucji danych, podczas gdy bazy danych NoSQL są przeznaczone do odczytu, zapisu i dystrybucji danych. Na przykład MongoDB obsługuje zapisy i odczyty we wszystkich węzłach w klastrze NoSQL, takim jak Cassandra. Wiele zasad NoSQL, takich jak architektura systemów rozproszonych i SQL, jest obecnie używanych w bazach danych newSQL.
Bazy danych NoSQL można również skalować w pionie, aby pomieścić większą liczbę użytkowników. Mechanizmy replikacji i tolerancji błędów to dwa kluczowe sposoby osiągnięcia skalowalności. W rezultacie dane mogą być przechowywane na wielu serwerach w celu zmniejszenia prawdopodobieństwa wystąpienia awarii.
Baza danych NoSQL jest również bardzo poszukiwana. Mają niski wskaźnik awaryjności i mogą wytrzymać duże obciążenia. Ze względu na niskie opóźnienia i przepustowość stanowią doskonały wybór dla aplikacji o wysokich wymaganiach dotyczących przepustowości.
Korzyści z nierelacyjnych baz danych
Jakie są korzyści z niestosowania systemów relacyjnych baz danych?
Korzystanie z nierelacyjnej bazy danych ma wiele zalet zamiast relacyjnej bazy danych. Nierelacyjna baza danych to najlepszy wybór do szybkiego tworzenia aplikacji. Przechowywanie w nich danych jest wygodniejsze, ponieważ często działają szybciej i mają większą prędkość. Są jednak bardziej elastyczne i szybkie w obsłudze, więc można nimi zarządzać bez trudności.
Jaki jest typ danych w Nosql?
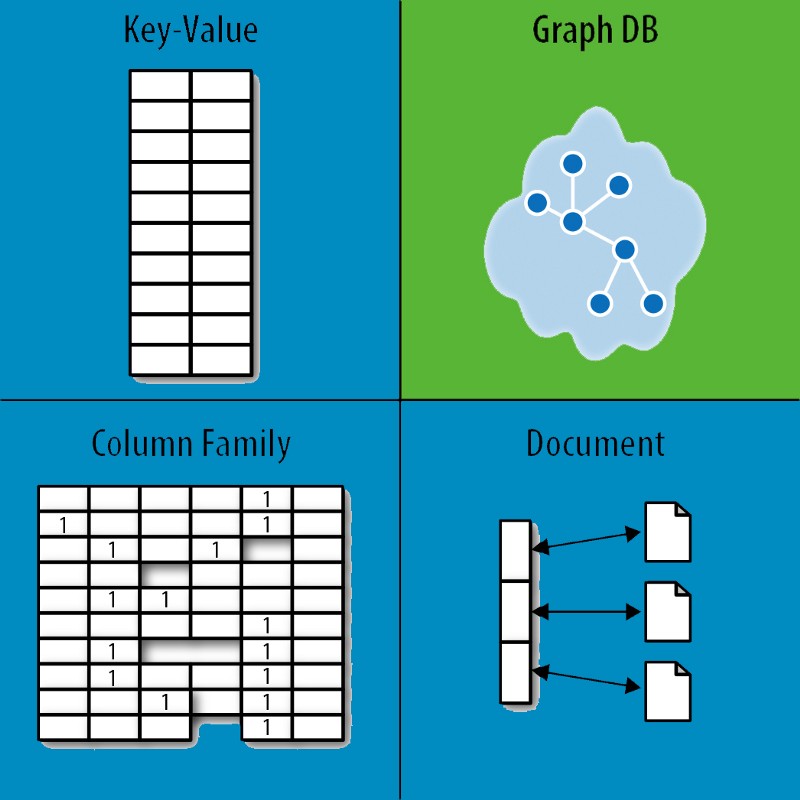
System NoSQL jest definiowany jako dowolna alternatywa dla tradycyjnej bazy danych SQL. Bazy danych SQL i bazy danych NoSQL to bardzo różne bazy danych. Stworzyli swój model danych w inny sposób niż tradycyjne modele tabel wierszowo-kolumnowych stosowane w systemach zarządzania relacyjnymi bazami danych (RDBMS).
Baza danych NoSQL składa się z czterech typów: magazyny klucz-wartość, magazyny dokumentów, bazy danych zorientowane na kolumny i bazy danych grafów . Relacyjna baza danych nie może rozwiązać problemu żadnym rozwiązaniem. Na przykład OrientDB to baza danych, która łączy typy NoSQL i wielomodelowe. Istnieje wiele typów jednostek i opcji łączenia tabel dla relacyjnej bazy danych na dużą skalę. Wszystkie podmioty (osoby) są reprezentowane w wierszu rozłożonym na wiele kolumn. Kolumny są przechowywane oddzielnie w bazie danych kolumn, co ułatwia ich wyszukiwanie, gdy w grę wchodzi tylko kilka kolumn. Indeks kreśli wiersze i kolumny do danych, podczas gdy baza danych kolumn kreśli wiersze i kolumny do danych.
Magazyn klucz-wartość, w przeciwieństwie do bazy danych NoSQL, jest najmniej złożony. Mogą przechowywać codzienne dokumenty w sposób, który ułatwia ich wyszukiwanie i obliczanie, a także przechowują dokumenty w takiej postaci, w jakiej są. Normalizacja nie jest ważna dla magazynów dokumentów, o ile dane mają prawidłową strukturę. Celem graficznych baz danych jest ułatwienie śledzenia relacji między podmiotami. Grafowe bazy danych składają się z dwóch głównych komponentów: danych i struktury. Podmiot jako całość. Krawędź jest właściwością dwóch elementów, które są reprezentowane przez linie. Magazyny dokumentów i magazyny klucz-wartość są zgodne z BASE, podczas gdy bazy danych wykresów, takie jak Neo4j, twierdzą, że podtrzymują ACID.
Elastyczne przechowywanie danych dzięki Json
Ponieważ dokumenty JSON są elastyczne i proste w użyciu, są popularnym typem danych w bazach danych NoSQL. JSON to typ przechowywania danych podobny do arkusza kalkulacyjnego, z tą różnicą, że jest przechowywany w wierszach i kolumnach, a nie w wierszach i kolumnach. Jest to idealne rozwiązanie do przechowywania danych częściowo ustrukturyzowanych, które nie wymagają określonej procedury porządkowania.
Czy Nosql to dane nieustrukturyzowane czy częściowo ustrukturyzowane?
Baza danych NoSQL jest zazwyczaj odpowiednia do przetwarzania danych częściowo ustrukturyzowanych, danych w pełni nieustrukturyzowanych, dokumentów, wykresów lub schematów dynamicznych. Podczas gdy tradycyjne systemy RDBMS radzą sobie z wysoce ustrukturyzowanymi danymi, bazy danych NoSQL zwykle radzą sobie z częściowo lub w pełni ustrukturyzowanymi poziomami.
Istnieje wiele różnych typów danych, począwszy od arkuszy kalkulacyjnych, poprzez tekst, wideo, a skończywszy na plikach audio. Dane strukturalne to rodzaj danych, które zostały wstępnie zdefiniowane, aby można je było przechowywać w pamięci masowej w określony sposób. Ponieważ nie zawierają predefiniowanego modelu danych, dane nieustrukturyzowane nie są przechowywane w relacyjnej bazie danych. Termin dane nieustrukturyzowane odnosi się do danych nieustrukturyzowanych, które nie mają struktury, ale zawierają metadane, które umożliwiają użytkownikom identyfikację częściowej lub hierarchicznej struktury. Naukowcy i inżynierowie korzystający z uczenia maszynowego lub sztucznej inteligencji wydobywają znaczenie z tego typu danych za pomocą technik, które są zarówno wydajne, jak i głębokie. Plik danych częściowo ustrukturyzowanych zawiera wiadomości e-mail i inne dokumenty, które są w tym samym formacie, ale zawierają metadane, które umożliwiają użytkownikom dostęp do informacji na określonym poziomie. W tym artykule przyjrzymy się kilku przykładom z rzeczywistego świata dla każdego typu danych i omówimy ich podstawowe zastosowania w nowoczesnych organizacjach.

Dane strukturalne są zwykle przechowywane w bazie danych, a hurtownie danych są również uwzględniane. Ponieważ brakuje im zdefiniowanego schematu, którego należy przestrzegać dla danego atrybutu, dane nieustrukturyzowane są przechowywane w bazie danych Data Lakes lub w nierelacyjnej bazie danych. Nowoczesne bazy danych NoSQL, takie jak MongoDB, służą do przechowywania częściowo ustrukturyzowanych danych (ze strukturą lub hierarchią).
Ten typ bazy danych zapewnia takie korzyści, jak szybszy rozwój i bardziej elastyczny model danych, co czyni go popularnym wyborem. MongoDB, wiodące rozwiązanie NoSQL , jest szczególnie dobre w archiwizowaniu nieustrukturyzowanych danych. W rezultacie model danych dokumentu przechowuje wszystkie powiązane dane w jednym dokumencie, który jest znacznie bardziej elastyczny niż sztywny model relacyjnej bazy danych. W rezultacie MongoDB jest doskonałym wyborem dla danych nieustrukturyzowanych i częściowo ustrukturyzowanych.
Wiele zalet częściowo ustrukturyzowanych danych
Dane częściowo ustrukturyzowane, jak sama nazwa wskazuje, nie pasują do żadnej z następujących kategorii: struktura, ilość lub skład. Te dwa rodzaje danych można uznać za mieszane i dopasowane. Typy częściowo ustrukturyzowanych danych, które można przechowywać, to JSON, XML i tekst.
Bazy danych Nosql
Baza danych NoSQL zapewnia mechanizm przechowywania i wyszukiwania danych, który wykorzystuje luźniejsze modele spójności niż tradycyjne relacyjne bazy danych. Bazy danych NoSQL są często bardziej skalowalne i zapewniają lepszą wydajność.
W przeciwieństwie do tradycyjnych baz danych , bazy NoSQL są bardziej elastyczne. Bazy danych NoSQL przechowują dane w tej samej strukturze danych, co inne typy baz danych, takie jak dokumenty. Nierelacyjna baza danych może być używana do zarządzania dużymi i zazwyczaj nieustrukturyzowanymi zbiorami danych ze względu na niski poziom relacyjności. Systemy bazodanowe NoSQL nie wymagają łączenia tabel. Bazy danych NoSQL umożliwiają przechowywanie szerokiej gamy struktur danych, dzięki czemu są przydatne w analizie danych, sieciach społecznościowych i aplikacjach mobilnych. Każdy typ bazy danych ma kilka zalet, ale NoSQL i relacyjne bazy danych są używane w dużych ilościach przez firmy. Bazy danych dokumentów zawierają dane w postaci dokumentów, które są ze sobą synchronizowane, gdy są używane w aplikacjach.
Bazy danych dokumentów są często wykorzystywane przez systemy zarządzania treścią oraz profile użytkowników. Informacje są przechowywane w kolumnach w dużych bazach danych, co ułatwia użytkownikom dostęp do określonych kolumn. Na przykład Apache HBase i Apache Cassandra to dwa przykłady tego typu bazy danych. Baza danych grafów zarządza i przechowuje sieć połączeń między elementami grafów. Ponieważ dane są przechowywane w pamięci, a nie na dysku, można uzyskać do nich dostęp szybciej niż w przypadku tradycyjnych dyskowych baz danych. Posiadanie aplikacji opartej na mikrousługach jest korzystne, ponieważ eliminuje potrzebę posiadania jednego, współdzielonego magazynu danych w wielu aplikacjach. W rezultacie IBM może zapewnić szeroką gamę baz danych NoSQL i NoSQL do szerokiego zakresu zastosowań. IBM Data Management Platform for MongoDB Enterprise Advanced jest komponentem pakietu IBM Cloud Pak for Data Suite. Apache CouchDB, PouchDB i inne popularne biblioteki internetowe i mobilne są obsługiwane przez usługę, która jest częścią ekosystemu open source.
Jaki jest najlepszy sposób na utworzenie schematu dla bazy danych NoSQL? Podczas tworzenia schematu dla bazy danych NoSQL natywna struktura bazy danych może służyć jako punkt wyjścia. Ponadto schemat można utworzyć za pomocą edytora schematów.
Bazy danych Nosql: zalety i wady
Bazy danych NoSQL są czasami porównywane do baz danych SQL, z których częściej korzystają firmy. Bazy danych NoSQL są również przydatne w aplikacjach, które przechowują dane w inny sposób niż ten, który obsługuje SQL.
Na przykład bazy danych dokumentów mogą przechowywać dane w formatach JSON lub XML. Podczas przechowywania danych w magazynach klucz-wartość muszą istnieć dwie pary klucz-wartość. Dane są przechowywane w kolumnach o różnej szerokości w magazynach z szerokimi kolumnami, dzięki czemu idealnie nadają się do przechowywania danych, które nie są dobrze zdefiniowane lub wymagają szybkiego dostępu. Dane mogą być przechowywane w bazach danych wykresów w celu reprezentowania relacji między różnymi jednostkami poprzez wyświetlanie wykresów.
Z drugiej strony bazy danych SQL nie są tak wydajne jak bazy danych NoSQL. Ponadto bazy danych SQL są znacznie droższe i mogą obsłużyć tylko ograniczoną liczbę transakcji. W rezultacie dane nieustrukturyzowane, które często trudno jest przechowywać w relacyjnej bazie danych, są z większym prawdopodobieństwem przetwarzane przez te systemy.
Istnieje jednak kilka ograniczeń dotyczących baz danych NoSQL. Bazy danych SQL są jasno zdefiniowane i znacznie lepiej przystosowane do transakcji wielowierszowych, podczas gdy te bazy danych mogą nie być tak dobrze dopasowane. Ponadto są trudniejsze do nauczenia się niż bazy danych SQL.
Magazyny danych
Magazyny danych to repozytoria danych, do których komputery mają dostęp. Można je podzielić na dwa główne typy: aktywne magazyny danych, które służą do przechowywania danych, które są aktywnie używane przez aplikacje, oraz pasywne magazyny danych, które służą do przechowywania danych, które nie są aktywnie używane przez aplikacje. Magazyny danych można dalej podzielić na dwa podtypy: relacyjne magazyny danych, które przechowują dane w formacie tabelarycznym, oraz nierelacyjne magazyny danych, które przechowują dane w formacie nietabelarycznym.
Co oznacza magazyn danych?
Magazyn danych to połączenie, które istnieje między dwoma lub więcej magazynami danych, niezależnie od tego, czy dane są przechowywane w bazie danych, czy w jednym lub większej liczbie plików. Magazyn danych lub może być źródłem danych dla procesu lub może być źródłem wyników etapowych danych procesu do magazynu danych.
Znaczenie podstawowej pamięci masowej
Jest to podstawowa pamięć komputera, w której przechowywane są aktualnie używane dane, programy i instrukcje. Dzięki podstawowej pamięci masowej płyty głównej może ona bardzo szybko odczytywać i zapisywać dane. Serwer to komputer, który odbiera i przechowuje dane od wielu klientów w sieci. Jest przechowywany na dysku w celu długoterminowego dostępu do plików. Pamięć masowa może być częścią składową systemu serwerowego lub może być oddzielona od serwera.
Wspólne modele baz danych grafów
Istnieją trzy popularne modele grafowych baz danych: model wykresu właściwości, model ramowy opisu zasobów i model potrójnego sklepu. Model grafu właściwości jest najpopularniejszym modelem i jest używany przez wiele baz danych wykresów, w tym Neo4j. Model ramowy opisu zasobów jest standardowym modelem przechowywania danych w bazie danych grafów i jest używany przez bazy danych, takie jak AllegroGraph. Model potrójnego sklepu to prosty model używany przez wiele grafowych baz danych, w tym Virtuoso.
Mongodb: baza danych wykresów?
MongoDB to baza danych grafów.