
Bazy danych NoSQL są często używane w aplikacjach Big Data, które wymagają wysokiego stopnia skalowalności i elastyczności
Opublikowany: 2022-11-22Baza danych NoSQL to nierelacyjna baza danych, która nie korzysta z tradycyjnego, opartego na tabelach schematu relacyjnej bazy danych. Bazy danych NoSQL są często używane w aplikacjach Big Data, które wymagają wysokiego stopnia skalowalności i elastyczności. Dane w bazie danych NoSQL są agregowane przy użyciu procesu zwanego shardingiem. Sharding to proces dzielenia danych na mniejsze części, dzięki czemu można je przechowywać na wielu serwerach. Pozwala to na skalowalność poziomą, co oznacza, że baza danych może obsłużyć większy ruch w miarę dodawania kolejnych serwerów.
Język zapytań Restdb.io umożliwia grupowanie i organizowanie zestawów danych. Zapytanie jest przykładem agregacji wykorzystującej standardowe funkcje (na przykład zapytanie z możliwością agregacji). Gdy przesyłana jest agregacja parametrów, jako parametry zapytania lub wskazówki dotyczące zapytania, są one używane. Poniższa tabela przedstawia sposób korzystania z funkcji agregacji i grupowania. Funkcja SUMA wyszukuje wszystkie elementy w kolekcji graczy i zwraca łączną sumę wszystkich wyników w zapytaniu. Prosta baza danych MongoDB , do której można uzyskać dostęp za pośrednictwem usługi internetowej RESTful. Te funkcje są dostępne jako oddzielne funkcje od innych narzędzi do zapytań, a dokumentacja szczegółowo opisuje, jak z nich korzystać.
Ponieważ agregat jest naturalną jednostką replikacji i skalowania, znacznie łatwiej jest uruchamiać te bazy danych w klastrze z agregatami*. W rezultacie może być przydatny w rozwiązywaniu problemu niedopasowania impedancji, takiego jak różnice między modelem relacyjnym a strukturami danych w pamięci.
Operacje agregacji MongoDB przetwarzają rekordy danych/dokumenty w celu zwrócenia wyników. Ta metoda zbiera wartości z różnych dokumentów i grupuje je razem, a następnie wykonuje różne operacje na wynikowych danych w celu wygenerowania obliczonej wartości.
W MongoDB operator potoku $not aggregation wybiera wartość logiczną, która jest następnie zwracana jako wartość przeciwna. Innymi słowy, gdy wartość logiczna ma wartość true, operator $not zwraca wartość false. Gdy wartość logiczna ma wartość false, zwraca wartość true, podobnie jak operator $not.
Czy Nosql ma funkcje agregujące?

Nie ma ostatecznej odpowiedzi na to pytanie, ponieważ termin „NoSQL” obejmuje szeroki zakres technologii baz danych, z których każda ma swoje własne możliwości. Jednak generalnie bazy danych NoSQL nie są tak skoncentrowane na dostarczaniu funkcji agregujących, jak tradycyjne relacyjne bazy danych. Wynika to z faktu, że bazy danych NoSQL są często projektowane tak, aby były bardziej skalowalne i elastyczne, co może odbywać się kosztem niektórych bardziej zaawansowanych funkcji relacyjnych baz danych.
Czym są agregaty w Nosql Wyjaśnij na przykładzie?
W NoSQL agregaty to sposób grupowania danych. Na przykład możesz mieć agregację wszystkich użytkowników w systemie, wszystkich produktów w systemie lub wszystkich zamówień w systemie. Agregaty mogą służyć do zapewnienia szybkiego dostępu do danych, które są często używane razem.
Kluczową operacją w każdej bazie danych jest agregacja, która pozwala przetwarzać rekordy danych w celu znalezienia odpowiednich wyników. Operacje agregacji używają różnych wyrażeń w celu identyfikacji danych i przedstawienia ich w zrozumiały sposób. Celem tego artykułu jest dokładne zrozumienie metody agregującej, a także używanych w niej wyrażeń. Możemy obliczyć średnie wynagrodzenie pracowników w zbiorze, grupując ich na podstawie oznaczenia, do którego są przypisani w $aggregate. Korzystając z wyrażeń $min i $max, możemy uzyskać minimalną i maksymalną pensję. Wartości tablicowe można zwrócić za pomocą wyrażenia $push w celu obliczenia warunkowych wyników z pogrupowanych danych. Funkcja agregująca MongoDB jest powszechnie używana do uzyskiwania obliczonego wyniku kolekcji poprzez grupowanie zebranych danych. Wyrażenia $first i $last mogą służyć do określenia wartości dowolnego pola w zgrupowanych danych. Operator $last wyświetla datę ważności (występującą na końcu) każdego produktu, jak pokazano w poniższym poleceniu do grupowania danych w odniesieniu do pola Produkt.
Celem zapytań agregujących jest analiza danych w bazach danych zarówno w fazie deweloperskiej, jak i administracyjnej. Są również wykorzystywane w analizie danych i eksploracji danych. Twórca bazy danych lub administrator bazy danych może generować zapytania zbiorcze w celu generowania danych grupy i podgrupy. Zapytanie agregujące to metoda generowania zestawu danych grupy i podgrupy poprzez porównanie wpisów danych z różnych źródeł. Programiści i administratorzy baz danych często używają tego terminu. Jeśli potok zawiera operatora $out, funkcja agregatu() zwraca pusty kursor. Funkcja agregat() agreguje dane kursora wejściowego w tablicy. Możliwe jest użycie funkcji agregat() do obliczenia średniej, mediany i trybu. Podczas obliczania wariancji lub odchylenia standardowego można również użyć funkcji zwanej agregat(). W tym przykładzie do obliczenia wartości minimalnej lub maksymalnej można również użyć funkcji agregat() . Funkcji agregat() można użyć do obliczenia sumy, średniej lub mediany różnych czynników.
Co to jest orientacja agregacji w Nosql?
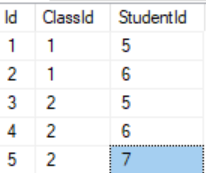
Baza danych NoSQL, taka jak baza danych zorientowana na agregację, nie obsługuje transakcji ACID, ponieważ nie zużywa pamięci ACID. Operacje orientacji agregacji relacyjnej bazy danych różnią się od operacji w nieodtworzonej bazie danych. Baza danych zorientowana na agregaty może być używana do operacji OLAP.
Jakie są korzyści z używania bazy danych zorientowanej na agregację?
Oprócz korzyści, zagregowana baza danych ma inne zalety. Może również ułatwić zarządzanie przechowywaniem danych w klastrach. Ponadto dzięki prostej strukturze ułatwia interakcję z danymi. Wreszcie może mieć negatywny wpływ na transakcje.
W jaki sposób baza danych Nosql przechowuje dane?

Bazy danych Nosql przechowują dane na wiele sposobów, w zależności od typu bazy danych.
Magazyny klucz-wartość, takie jak Redis, przechowują dane jako mapowanie kluczy na wartości. W Redis każdy klucz musi mieć wartość, ale wartością może być ciąg znaków, lista, zestaw lub posortowany zestaw.
Bazy danych dokumentów, takie jak MongoDB, przechowują dane jako dokumenty BSON. BSON jest binarną reprezentacją dokumentów JSON i obsługuje bogatszy zestaw typów danych niż JSON.
Bazy danych zorientowane na kolumny, takie jak Cassandra, przechowują dane w kolumnach, a nie w wierszach. Każda kolumna może mieć inny typ danych, a rodzina kolumn może mieć wiele kolumn.
Bazy danych grafów, takie jak Neo4j, przechowują dane jako węzły i krawędzie. Węzły reprezentują jednostki, a krawędzie reprezentują relacje między jednostkami.
Duże ilości niepowiązanych ze sobą danych można szybko i łatwo przechowywać za pomocą NoSQL. NoSQL nie ma właściwości relacyjnych ze względu na swoją naturę. Od lat 70. najpopularniejszym rodzajem przechowywania danych były relacyjne bazy danych. Według Bena Finkela, trenera CBT, NoSQL ceni szybkość i elastyczność ponad spójność i wydajność. Pomimo swojej wydajności budowanie i utrzymywanie relacyjnych baz danych wymaga znacznych nakładów pracy. Baza danych NoSQL nie musi być zaprojektowana ani zaplanowana, aby mogła zostać wdrożona. W rezultacie programiści mogą znacznie szybciej tworzyć, prototypować i wdrażać aplikacje.
Można ich również używać w tandemie z programowaniem zwinnym. Ponieważ bazy danych NoSQL mogą przechowywać szeroki zakres typów danych, nie wymagają ponownej normalizacji. Uruchomienie bazy danych NoSQL wymaga większej mocy obliczeniowej niż relacyjnej bazy danych. Możliwe jest uruchamianie baz danych NoSQL na Raspberry Pi, ale trudniej jest też obsłużyć obciążenie serwera WWW. Wykres różni się od pary klucz:wartość lub dokumentu tym, że zawiera informacje, a nie słowa. Model węzła składa się z dwóch komponentów: modelu krawędziowego i modelu grafowego. Węzły przechowują informacje o obiekcie, którym może być dowolny obiekt (osoba, miejsce, rzecz, pomysł itp.) na różne sposoby. Krawędzie są odpowiedzialne za relacje między węzłami. Model danych z szerokimi kolumnami jest podobny do relacyjnej bazy danych, z tą różnicą, że zawiera wiersze i kolumny.
Bazy danych Nosql: wprowadzenie
Zamiast używać kolumn i wierszy w relacyjnych bazach danych, bazy danych NoSQL używają dokumentów JSON do przechowywania danych. Klasyfikujemy je nie tylko jako SQL, ale także wykorzystując w ten sposób różnorodne elastyczne modele danych. Bazy danych dokumentów, magazyny klucz-wartość, bazy danych o dużych kolumnach i bazy danych wykresów to przykłady baz danych NoSQL. Podczas korzystania z bazy danych NoSQL rekord księgi może być przechowywany jako dokument JSON. Każda książka zawiera unikalne informacje o pozycji, numerze ISBN, tytule książki, numerze wydania, nazwisku autora i identyfikatorze autora w jednym dokumencie. Ten model wykorzystuje zoptymalizowane formaty danych, które można łatwo opracować i skalować w pionie. Baza danych NoSQL może służyć do przechowywania danych wszystkich typów, w tym danych ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych. Najlepiej nadają się do przechowywania danych nieustrukturyzowanych i częściowo ustrukturyzowanych (JSON, XML itd.) (żadne pole nie jest znane).

W jaki sposób agregaty wchodzą w interakcję z modelami baz danych Nosql?
Agregaty współdziałają z modelami baz danych nosql, zapewniając sposób przechowywania i pobierania danych w bazie danych nosql. Agregaty umożliwiają przechowywanie danych w bazie danych nosql przy użyciu magazynu klucz-wartość. Agregaty umożliwiają pobieranie danych z bazy danych nosql przy użyciu języka zapytań.
Wykorzystanie Aggregate Data Models w NoSQL Database pozwala na łatwe tworzenie zagnieżdżonych rekordów i złożonych rekordów. Bazy danych NoSQL wyróżniają się elastycznością, skalowalnością i możliwością szybkiego reagowania na potrzeby nowoczesnych przedsiębiorstw w różnych obszarach. Dzięki Hevo możesz zmniejszyć przepustowość inżynieryjną, replikując dane w kilka minut i łatwo. Kolekcja obiektów, które są umieszczone razem jako jednostka, nazywana jest kolekcją. Płytkie modele NoSQL są zazwyczaj podzielone na cztery typy: zagregowane modele danych, zagregowane modele danych i zagregowane modele danych. Klucz lub identyfikator jest zawarty w modelu danych klucz-wartość, który może służyć do uzyskiwania dostępu lub pobierania danych o agregatach odpowiadających kluczowi. Model danych dokumentu może być wykorzystany do określenia składników agregatów.
Wiele platform NoSQL przechowuje duże ilości złożonych agregatów, a także danych wielowymiarowych przy użyciu modeli danych zagregowanych. Dzięki zautomatyzowanej platformie Hevo No Code możesz wzbogacić swoje modelowanie danych, korzystając z jej błyskawicznego potoku danych. Hevo jest dostępne do bezpłatnej wersji demonstracyjnej. Możesz otrzymać bezpłatną wersję próbną Hevo i wypróbować ją przez 14 dni. Bazę danych NoSQL można ustrukturyzować przy użyciu zagregowanych modeli danych. O ile nam wiadomo, nie ma formatu, którego można użyć do narysowania granic agregatów. Dane są przetwarzane tylko w razie potrzeby, w oparciu o Twoje wymagania. Dzięki Hevo Data, rozwiązaniu typu Data Pipeline bez kodu, możesz łatwo przesyłać dane ze 100 różnych źródeł do wybranej hurtowni danych.
Znaczenie modelowania danych w hurtowniach danych
Aby skutecznie przechowywać i analizować dane, niezwykle ważne jest posiadanie modelu danych, który jest dostosowany do wydajności i skali. Baza danych NoSQL, taka jak MongoDB, zawiera różnorodne modele danych, w tym modele klucz-wartość, dokumenty i wykresy, z których wszystkie są zoptymalizowane pod kątem wydajności i skali. Te modele danych są mniej podatne na niestabilność, co pozwala na większą elastyczność i skalowalność w hurtowniach danych na dużą skalę. Aby modelowanie danych funkcjonowało prawidłowo, wymagana jest agregacja danych . Jest to proces, w którym dane są gromadzone i prezentowane w podsumowanym formacie do analizy statystycznej i osiągnięcia celów biznesowych. Hurtownia danych musi wykorzystywać agregację danych, ponieważ pozwala na analizę dużych ilości surowych danych. Wykorzystując modele danych zoptymalizowane pod kątem agregacji danych, hurtownie danych mogą pomóc w lepszym podejmowaniu decyzji w oparciu o ogromną ilość gromadzonych informacji.
Agregacja Nosql
Agregacja NoSQL to proces zbierania i łączenia danych z wielu baz danych NoSQL . Można to zrobić z różnych powodów, takich jak uzyskanie pełniejszego widoku danych, połączenie danych z wielu źródeł lub ułatwienie wykonywania zapytań i analizowania danych.
Operacje agregacji MongoDB przetwarzają i zwracają rekordy/dokumenty danych. System zbiera wartości z różnych dokumentów i grupuje je razem, a następnie wykonuje różne operacje na tych zgrupowanych danych, takie jak suma, średnia, minimum, maksimum i tak dalej. Potok agregacji MongoDB można podzielić na trzy części: etapy, wyrażenia i akumulatory. Suma $ reprezentuje całkowitą sumę wszystkich dokumentów w następujących grupach, a akumulator $max reprezentuje maksymalną liczbę dokumentów w każdej grupie w odpowiednim wieku. W naszej kolekcji mamy dużą liczbę tematów, co oznacza, że nie będziemy się nad nimi rozwodzić. W analizie danych redukcja mapy służy do agregowania wyników dla dużej ilości danych. Ma dwie podstawowe funkcje.
Jedna z map to metoda porządkująca pogrupowane dane, a druga to metoda wykonująca operację. Można go użyć do określenia, które dokumenty mają różne wartości, zliczając liczbę dokumentów lub korzystając z funkcji wyszukiwania. Metoda count() i metoda estymowanaDocumentCount() służą do uzyskiwania dostępu do wspólnego procesu agregacji.
Czy Cassandra jest dobra do agregacji?
Ponieważ Cassandra nie ma struktury agregacji , nie będziesz w stanie jej znaleźć. Aby agregować dane, administratorzy muszą korzystać z narzędzi innych firm, takich jak Hadoop i Spark. Z drugiej strony struktura agregacji MongoDB jest wbudowana. Może uruchamiać potok ETL w celu agregowania przechowywanych danych i zwracania wyników.
Trzy szybkie bazy danych
Baza danych Cassandra może przetwarzać wiele jednoczesnych zapisów oprócz obsługi dużych ilości danych. MongoDB to bardzo szybka baza danych, która może obsługiwać tylko jeden zapisywalny węzeł podstawowy na zestaw replik. Pamięć Redisa jest ogromna i pozwala na przechowywanie dużych ilości danych.
Co to jest agregacja danych?
Analiza wysokiego poziomu polega na podsumowaniu dużej liczby punktów danych w ustrukturyzowanym formacie. Proces ten obejmuje gromadzenie danych z wielu zalecanych baz danych i organizowanie ich w prostsze, łatwiejsze w użyciu medium, zwykle przy użyciu odniesień sumy, średniej, średniej lub mediany.
Różne typy danych zagregowanych
Kruszywo grube to br>. Istnieją wartości br. W ten sposób podsumowuje się wartość danej pozycji.
Jest to wartość pieniężna.
Maksymalna wartość przypisana przez Rezerwę Federalną USA to**br>. Zawartość materiału jest gruba. Jest obliczany jako średnia wszystkich wartości.
Liczba wartości *br** jest używana do obliczenia liczby. Suma wartości jest reprezentowana przez SUMĘ sumy.
Innymi słowy, wartością jest *br>. MAX OF wartości br> jest równe wartościom w nawiasach. Media odnoszą się do wartości takimi, jakie są.
STDEV to wartość przypisana do wartości.
Baza danych Nosql do obsługi ciężkich zapytań zbiorczych
Bazy danych NoSQL są często używane w przypadku dużych zagregowanych obciążeń związanych z zapytaniami, ponieważ można je skalować w poziomie i zapewniać wysoką dostępność. Bazy danych NoSQL można również dostosować do określonych obciążeń, co może zwiększyć ich wydajność w porównaniu z tradycyjnymi relacyjnymi bazami danych.
Jak wybrać bazę danych Google w chmurze? Jaki typ danych wybrać? Jeśli szyfrujesz dane w stanie spoczynku w DynamoDB, musisz wygenerować unikalny, sekwencyjny identyfikator dla każdej wartości przechowywanej w Redis. Jak utworzyć magazyn danych dla nowej aplikacji e-commerce? Która baza danych jest używana do analizy magazynu kluczowych wartości? Jak wybrać bazę danych NoSQL? Jaka jest najlepsza baza danych magazynu kolumn z wbudowanymi typami danych?
Przegląd Nosql
Systemy NoSQL są zaprojektowane tak, aby zapewnić mechanizm przechowywania i wyszukiwania danych, który jest modelowany w sposób inny niż relacje tabelaryczne stosowane w relacyjnych bazach danych. Takie systemy są czasami nazywane „nie tylko SQL”, aby podkreślić, że mogą obsługiwać języki zapytań podobne do SQL. Bazy danych NoSQL są coraz częściej wykorzystywane w aplikacjach big data, aplikacjach internetowych czasu rzeczywistego, systemach zarządzania treścią i aplikacjach wywiadu operacyjnego.
Koncepcja relacyjnej bazy danych powstała w wyniku artykułu EFCodda z 1970 r. Relacyjny model danych dla dużych współdzielonych banków danych. Jest to sieć komputerów i komponentów oprogramowania, które komunikują się ze sobą. Kiedy komputery wchodzą ze sobą w interakcję i dzielą się zasobami, osiągają wspólny cel. Rozproszony system obliczeniowy ma większą moc obliczeniową i jest szybszy niż inne systemy, co czyni go bardziej wydajnym. Systemy zarządzania nierelacyjnymi bazami danych, znane również jako NoSQL, różnią się pod pewnymi względami od tradycyjnych systemów relacyjnych baz danych. Możliwość skalowania magazynów danych w systemie NoSQL sprawia, że jest to znacznie szybsze. Carlo Strozzi wymyślił koncepcję NoSQL w 1998 roku.
Infrastruktura bazy danych to termin używany do opisania nierelacyjnej, rozproszonej i niezgodnej bazy danych, która nie jest zgodna z czterema podstawowymi cechami tradycyjnych relacyjnych baz danych: niepodzielnością, spójnością, izolacją i trwałością. Twierdzenie CAP stwierdza, że istnieją trzy warunki wstępne projektowania aplikacji dla architektur rozproszonych. Zgodnie z twierdzeniem CAP rozproszony system komputerowy nie może jednocześnie gwarantować wszystkich trzech poniższych właściwości. Ogólnie bazy danych NoSQL dzielą się na cztery typy. Krawędzie lub łuki to uporządkowany zestaw uporządkowanych par w strukturze danych grafu.