
Bazy danych NoSQL: duża tabela
Opublikowany: 2023-01-04Bazy danych NoSQL stają się coraz bardziej popularne ze względu na ich elastyczność, skalowalność i wydajność. Baza danych NoSQL nie wymaga predefiniowanego schematu i może przechowywać dane w dowolnym formacie. Dzięki temu idealnie nadaje się do aplikacji, które muszą przechowywać duże ilości danych, które stale się zmieniają. Big table to rodzaj bazy danych NoSQL, która jest przeznaczona do przechowywania dużych ilości danych. Big table jest używany przez wiele dużych organizacji, takich jak Google, Facebook i Amazon. Duża tabela jest wysoce skalowalna i może obsłużyć miliardy wierszy i miliony kolumn. Big table jest również bardzo szybki i może zapewnić dostęp do danych w czasie rzeczywistym.
Firma Google wydała serię ogólnie dostępnych aktualizacji swojej usługi bazodanowej Cloud Bigtable . Dzięki nowym aktualizacjom na węzeł przypada teraz do pięciu razy więcej miejsca na dane. Firma Google dodała również ulepszone funkcje automatycznego skalowania, które umożliwiają automatyczne powiększanie lub zmniejszanie klastra bazy danych w zależności od potrzeb. Nowa metryka wykorzystania procesora i routing grup klastrów zapewniają lepszy wgląd w sposób wykorzystania zasobów aplikacji. Ze względu na oddzielenie mocy obliczeniowej i pamięci masowej każdy rodzaj zasobów można skalować samodzielnie w Bigtable. Użytkownicy mogą teraz łatwo zarządzać wdrożeniami o wysokiej dostępności i usprawniać zarządzanie obciążeniami dzięki nowym funkcjom.
NoSQL jest popularnym wyborem do przechowywania dużych ilości danych. Ten typ bazy danych staje się dziś coraz bardziej popularny wśród firm internetowych. Zwolennicy rozwiązań NoSQL twierdzą, że oferują one prostszą skalowalność i zwiększoną wydajność niż tradycyjne bazy danych.
Bigtable to rodzaj usługi bazy danych NoSQL, z której mogą korzystać zarówno programiści, jak i administratorzy baz danych. BigQuery jest hybrydą, ponieważ wykorzystuje dialekty SQL i opiera się na technologii przetwarzania danych Google, Dremel.
Czy Bigtable Sql czy Nosql?
Nie ma ostatecznej odpowiedzi na to pytanie, ponieważ zależy to od tego, jak zdefiniujesz każdy termin. Jeśli jednak przyjmiemy szeroką definicję SQL jako dowolnej bazy danych korzystającej z ustrukturyzowanego języka zapytań, a NoSQL jako dowolnej bazy danych, która nie korzysta z ustrukturyzowanego języka zapytań, wówczas Bigtable zostanie uznany za bazę danych NoSQL.
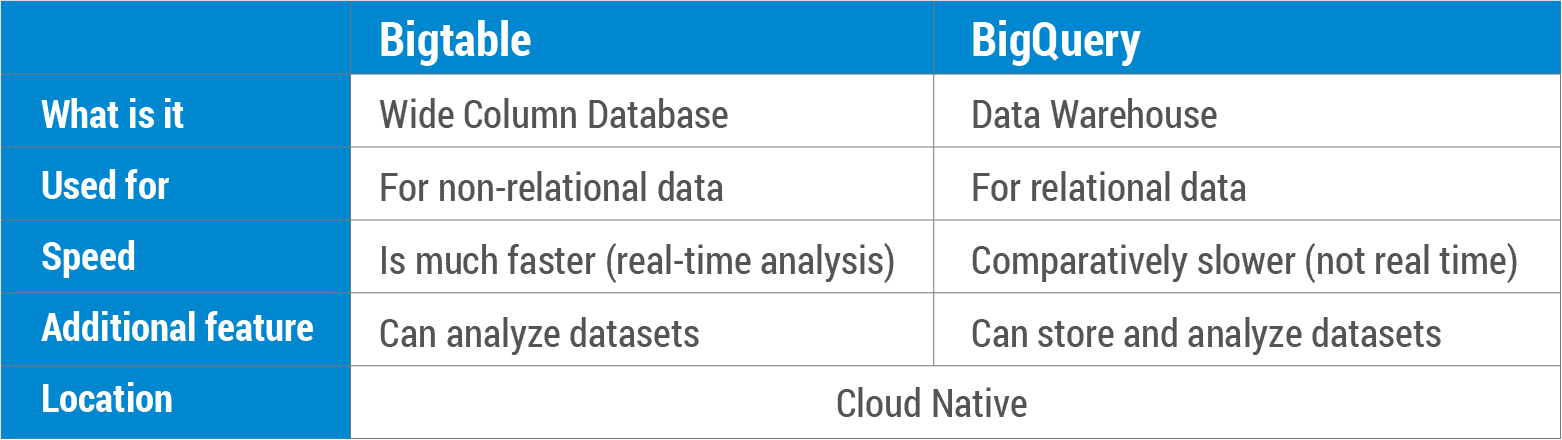
Czym jest porównanie Bigtable i BigQuery? Bigtable to baza danych NoSQL, która pozwala przechowywać dane w bezpieczny i skalowalny sposób. BigQuery to relacyjna hurtownia danych, która przechowuje ogromne ilości danych w bazie danych SQL. Bigtable został zintegrowany z produktami Google, takimi jak Analytics, Finanse, Wyszukiwanie spersonalizowane, Earth i Writely w celu ich codziennej działalności. Bigtable, zmienna baza danych NoSQL , dobrze współpracuje ze scenariuszami OLTP. BigQuery to relacyjna hurtownia danych SQL, której można używać w aplikacjach OLAP. Zarówno Bigtable, jak i BigQuery są natywne dla chmury i oferują wiodące w branży umowy dotyczące poziomu usług. Ponadto oferują automatyczne tworzenie kopii zapasowych (z replikacją), a także nieskończoną skalowalność, automatyczne dzielenie na fragmenty i automatyczne odzyskiwanie po awarii (z replikacją).
BigQuery, a nie baza danych NoSQL, tego nie robi.
Jakim typem bazy danych Nosql jest Bigtable?
Cloud Bigtable to baza danych NoSQL, za pomocą której można analizować dane i uruchamiać operacje. Stanowi alternatywę dla HBase, który jest kolumnowym systemem baz danych wykorzystującym HDFS. Aplikacje o przepustowości mniejszej niż 10 MB są odpowiednie dla Cloud Bigtable, która może obsługiwać wysoki poziom przepustowości i skalowalności.
Bazy danych Big Table, jak są znane, są podzbiorem baz danych NoSQL. Bigtable, aplikacja od Google, jest podobna do Kleenex. Bazy danych Bigtable to branżowy standard imitacji i inspiracji. Chociaż artykuł dotyczy głównie Bigtable, dotyczy również innych baz danych NoSQL. Bigtable został zaprojektowany głównie do użytku wewnętrznego przez Google, bez dostępu z zewnątrz. Bigtable został wprowadzony do Google w 2004 roku i od tego czasu jest używany przez ponad 60 aplikacji Google. Implementacja Bigtable wymaga jednego serwera głównego do śledzenia tabletów w klastrze innych serwerów.
Apache Software Foundation przyczyniła się do wielu znakomitych inicjatyw technicznych, szczególnie w dziedzinie baz danych. Accumulo i HBase wykorzystują te same zasady projektowania, co Google Bigtable, ale w formacie, który jest dostępny na rynku. Obecnie Apache HBase obsługuje system przesyłania wiadomości Facebooka i jest ściśle zintegrowany z Hadoopem, umożliwiając przetwarzanie dużych zbiorów danych. Baza danych Hypertable jest oparta na Bigtable, która jest prostą tabelaryczną bazą danych. Hypertable działa w taki sam sposób, jak Hadoop i HFS. Baidu, jedna z największych chińskich wyszukiwarek, jest jednym z głównych sponsorów Hypertable. Do klientów należą serwisy aukcyjne, takie jak eBay, Groupon i Rediff.com, a także sprzedawcy offline, tacy jak Lowe's i TJ Maxx.
Hadoop to platforma oprogramowania typu open source, która umożliwia użytkownikom wydajne przechowywanie i przetwarzanie ogromnych ilości danych. Umożliwia to korzystanie z baz danych NoSQL, które mogą zmniejszyć ilość danych wymaganych do przechowywania na pojedynczych serwerach. Z drugiej strony baza danych NoSQL nie wymaga stałego schematu, ponieważ jest oparta na skalowalności. Z tego powodu są doskonałym wyborem do przechowywania ogromnych ilości danych w sposób rozproszony.
Do jakiego rodzaju magazynu danych Nosql należy Bigtable?
Jedna z niewielu funkcji dostępnych na rynku leków generycznych. Na najbardziej podstawowym poziomie Bigtable to baza danych NoSQL, która obejmuje szeroki zakres kolumn.
Czy baza danych Bigtable jest kolumnowa?
Magazyny z szeroką kolumną, takie jak Bigtable i Apache Cassandra, nie są kolumnami w tradycyjnym znaczeniu tego słowa, ponieważ w ogóle nie używają kolumnowych struktur danych na dwóch poziomach.
Czy Bigtable to nierelacyjna baza danych?
Nie ma ostatecznej odpowiedzi na to pytanie, ponieważ zależy to od tego, jak zdefiniujesz „nierelacyjną bazę danych”. Bigtable to magazyn danych zorientowany na kolumny, który niektórzy uważają za rodzaj bazy danych NoSQL. Obsługuje jednak transakcje i indeksowanie, które są zwykle kojarzone z relacyjnymi bazami danych. Tak więc to naprawdę zależy od tego, jak zdefiniujesz nierelacyjną bazę danych.
Instrukcja CREATE EXTERNAL TABLE może służyć do tworzenia tabeli w BigQuery przez określenie tabeli, z której mają być pobierane dane. Opcji uri można użyć do określenia tabeli, z której mają zostać pobrane dane. Schemat tabeli zawiera nazwę tabeli, typ tabeli, nazwy kolumn i typy danych, a także schemat tabeli opcji bigtable_options.
Jeśli używasz MySQL, narzędzie do importowania BigQuery może służyć do automatycznego importowania danych z tabeli MySQL do BigQuery. Nazwa tabeli i rodzina kolumn są wprowadzane do narzędzia, które importuje dane do tabeli BigQuery.
Korzystając z konsoli Google Cloud, musisz ręcznie wprowadzić nazwę tabeli i parametry kwalifikujące rodzinę kolumn. Importowanie danych z różnych źródeł jest możliwe na platformie Google Cloud, w tym MySQL, PostgreSQL, MongoDB i Redis.
Kluczowe cechy Bigtable
Jakie są niektóre funkcje Bigtable?
Szybkość odczytu i zapisu Bigtable, jego ogromna skalowalność i możliwość obsługi dużych ilości danych to tylko niektóre z wielu jego funkcji. Ponadto, ponieważ Bigtable jest bazą danych NoSQL, zapytania SQL nie są obsługiwane. Eliminuje to konieczność wykonywania operacji SQL w oddzielnych bazach danych.
Czy Bigtable to baza danych?
Bigtable nie jest relacyjną bazą danych. Jest to rozproszony system pamięci masowej do zarządzania danymi strukturalnymi, zaprojektowany z myślą o skalowaniu do bardzo dużych rozmiarów: petabajtów danych na tysiącach zwykłych serwerów. Google używa Bigtable do zasilania wielu swoich usług na dużą skalę, takich jak Google Analytics i Google Maps.
Cloud BigTable zapewnia unikalny zestaw funkcji, który umożliwia skalowanie do ponad 100 000 kolumn i miliardów wierszy. Obsługuje przechowywanie około petabajtów i terabajtów danych. W porównaniu do BigTable ma bardzo małe opóźnienia, ale ma też potencjał do przechowywania dużej ilości danych. BigTable może przechowywać uporządkowane dane w kolumnach, co pozwala na obsługę usług internetowych i firmowych danych wyszukiwania w Internecie. Algorytmy kompresji są również wykorzystywane do zwiększania pojemności systemu. BigTable ma wpływowe serwery zaplecza, które oferują lepsze korzyści niż samodzielnie zarządzana instalacja HBase, która jest dołączona do BigTable. Wiersze na BigTable mają tę samą granicę, dlatego są również nazywane blokami.
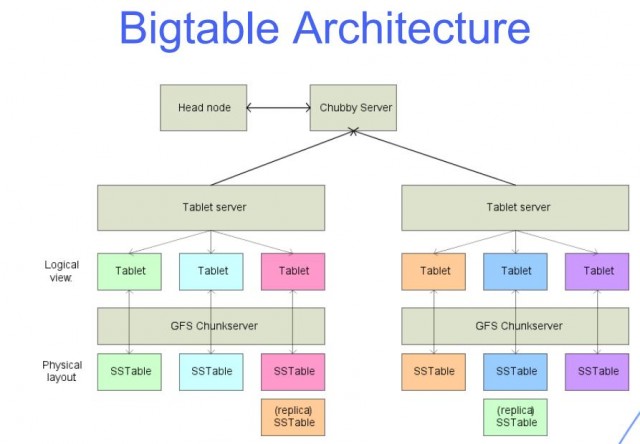
Te urządzenia, zwane „tabletami”, pomagają w zarządzaniu obciążeniem związanym z zapytaniami. Oparty na chmurze system plików Google Colossus służy do przechowywania wszystkich tabletów. Wszystkie operacje zapisu w BigTable są przechowywane we wspólnym dzienniku Colossus, podobnie jak pliki SSTable. Siedem kluczowych funkcji BigTable ma kluczowe znaczenie dla sukcesu firmy. BigTable ma potencjał, aby spersonalizować, przyspieszyć i zautomatyzować Twoje życie na różne sposoby. wiersze i kolumny to dwa wymiary danych w BigTable. Każdy wiersz zawiera unikalny identyfikator lub indeks, do którego można uzyskać dostęp za pomocą klucza pojedynczego wiersza.
Każda kolumna w rodzinie ma kolumnę kwalifikującą. Użycie jednostek kwalifikujących kolumny, takich jak klucze wierszy, pomaga w identyfikacji kolumn. Jeśli chodzi o bazy danych, BigTable jest znany jako rzadki. Każda z wersji BigTable ze znacznikiem czasu jest reprezentowana przez komórkę, która jest jednym z wymiarów w strukturze mapy 3D. Ta potężna baza danych, którą można spersonalizować i dostosować do szybkości, może być używana do zasilania witryn i aplikacji mobilnych. Jeśli cofniesz się myślami do przeszłości, możesz dowiedzieć się, które interakcje przyniosły najlepsze rezultaty. Pomoże Ci to wdrożyć więcej analiz danych i doprowadzi do lepszej obsługi klienta.
Google Cloud Bigtable, baza danych NoSQL typu open source, jest zintegrowana z chmurą Google. Fakt, że jest kompatybilny z tak wieloma istniejącymi ekosystemami Big Data i Hadoop, oznacza, że może być używany do danych nieustrukturyzowanych lub danych wymagających małych opóźnień.
Bigtable: doskonały wybór do aplikacji intensywnie korzystających z danych
Bigtable, usługa bazy danych NoSQL, jest używana do dużych obciążeń analitycznych i operacyjnych. W rezultacie jest to doskonały wybór dla aplikacji intensywnie korzystających z danych i działających w czasie rzeczywistym. Ponadto, ponieważ jest zorientowany na kolumny, idealnie nadaje się do przechowywania danych w trzech wymiarach.
Bigtable kontra Mongodb
Istnieje kilka kluczowych różnic między Bigtable i MongoDB. Po pierwsze, Bigtable to baza danych zorientowana na kolumny, podczas gdy MongoDB to baza danych zorientowana na dokumenty. Oznacza to, że w Bigtable dane są przechowywane w kolumnach, podczas gdy w MongoDB dane są przechowywane w dokumentach. Po drugie, Bigtable nie obsługuje indeksów wtórnych, podczas gdy MongoDB tak. Oznacza to, że jeśli chcesz zapytać o dane w Bigtable, musisz znać konkretną kolumnę, którą chcesz zapytać. W MongoDB możesz wysyłać zapytania do dowolnego pola w dokumencie. Wreszcie, Bigtable został zaprojektowany do skalowania w poziomie, podczas gdy MongoDB został zaprojektowany do skalowania w pionie. Oznacza to, że w Bigtable możesz dodać więcej maszyn do klastra, aby zwiększyć pojemność, podczas gdy w MongoDB możesz dodać więcej pamięci RAM i procesora do swojego serwera, aby zwiększyć pojemność.
Google Cloud Bigtable: nie tylko dla dużych zbiorów danych
Bigtable to wciąż element infrastruktury Google, który powstał w 2007 roku. Chociaż Cloud Bigtable jest idealny do przechowywania dużych ilości danych z niskimi opóźnieniami, nie jest idealny do danych, które nie wymagają częstego dostępu. Na przykład Cloud Bigtable nie pasowałby do jeziora danych.
Baza danych Bigtable
Baza danych bigtable to baza danych wykorzystująca strukturę danych bigtable . Bigtable to rozproszony system przechowywania danych strukturalnych, który można skalować do bardzo dużych rozmiarów.
Duża tabela to taka, która ma wiele wierszy i kolumn i jest zazwyczaj słabo zapełniona. Bigtable jest idealny do dużych zbiorów danych ze względu na niskie opóźnienia i dużą gęstość. To źródło danych jest idealne dla operacji MapReduce, ponieważ obsługuje wysoką przepustowość odczytu i zapisu przy małych opóźnieniach i jest idealne dla dużych zestawów danych. Dane tabeli Bigtable są dzielone na bloki ciągłych wierszy, z których każdy jest określany jako tablet, aby zmniejszyć obciążenie zapytaniami. Format SSTable służy do przechowywania tabletów Google w Colossus, firmowym systemie plików. Każdy tablet jest połączony z określonym węzłem w instancji Bigtable, który jest również nazywany węzłem. Dodanie węzłów do klastra może zwiększyć zdolność klastra do obsługi wielu jednoczesnych żądań.
Każdy wiersz zawiera kombinację rodziny kolumn, identyfikatora kolumny i znacznika czasu, czyli zasadniczo tablicę wpisów kluczy/wartości. W większości przypadków Bigtable konwertuje wszystkie dane na surowe ciągi bajtów. Ponieważ Bigtable przechowuje mutacje sekwencyjnie i kompaktuje je tylko raz na kilka miesięcy, mutacje zajmują więcej miejsca, gdy są zamieniane na wiersz. Bigtable kompresuje dane za pomocą inteligentnego algorytmu i wykorzystuje technologię kompresji. Ponieważ delecje są wyspecjalizowanym rodzajem mutacji, w krótkim okresie wymagają dodatkowej przestrzeni dyskowej. Opatentowane przez Google metody przechowywania pozwalają wytrzymać próbę czasu dla danych wykraczających poza zakres standardowej trójdrożnej replikacji HDFS. Użytkownicy mogą uzyskiwać dostęp do Twoich tabel Bigtable, korzystając z ról przypisanych im przez Twój projekt Google Cloud oraz Zarządzanie tożsamością i dostępem (IAM). Większość danych Google Cloud jest szyfrowana w stanie spoczynku przy użyciu tych samych systemów zarządzania kluczami o zaostrzonych zabezpieczeniach, których używamy w przypadku naszych zaszyfrowanych danych. Kopii zapasowej można użyć do zapisania kopii schematu i danych tabeli, a także do późniejszego przywrócenia kopii zapasowej do nowej tabeli.
Bigtable to dobrze zaprojektowany, rozproszony system pamięci masowej, który może pomieścić do petabajtów danych. Ponieważ jest prosty w użyciu, jest doskonałym wyborem do przechowywania danych na dużą skalę .

Potęga Bigtable w chmurze
Baza danych Cloud Bigtable może pomieścić dziesiątki tysięcy wierszy i kolumn i jest dostępna z dowolnego miejsca na świecie. W rezultacie doskonale nadaje się do przechowywania danych na dużą skalę. Cloud Bigtable jest teraz dostępny w Google Cloud od 6 maja 2015 r. Od tego czasu obsłużono ponad 10 EXAbajtów danych i ponad 5 miliardów żądań przetwarzanych na sekundę. Dzięki temu Cloud Bigtable jest nadal w użyciu i jest cennym narzędziem do przechowywania danych.
Bigtable kontra Cassandra
Każdy węzeł jest wybierany do operacji odczytu i zapisu przy użyciu własnej metody. W Cassandrze identyfikowany jest klucz partycji, podczas gdy w Bigtable używany jest klucz wiersza. Zasady równoważenia obciążenia Cassandry są najpierw sprawdzane przez klienta.
Dystrybuowane są systemy baz danych, takie jak Bigtable i Cassandra. Tworzą wielowymiarowe magazyny klucz-wartość, które mogą przetwarzać dziesiątki tysięcy zapytań na sekundę (QPS). Celem tego dokumentu jest wyjaśnienie różnic i podobieństw między dwoma systemami baz danych. Bigtable zawiera wiele głównych funkcji opisanych w Bigtable. W artykule opisano rozproszony system przechowywania danych strukturalnych. Kiedy Bigtable identyfikuje przypisanie zakresu wymagane dla zbioru danych, zakresy danych dla węzła przetwarzającego są łatwe do zmiany, ponieważ warstwa przechowywania jest oddzielona od warstwy przetwarzania. Ponadto Bigtable umożliwia asynchroniczną replikację między rozproszonymi geograficznie klastrami w topologiach do czterech.
Tolerancję błędów zapewnia Cassandra, która jest skorelowana z poziomem spójności. Korzystając z konfigurowalnej strategii topologii replikacji danych, można zdefiniować replikację geograficzną. W większości topologii centrów danych z wieloma centrami danych ustawieniem domyślnym jest KWORUM (lub LOCAL_QUORUM). Aby ustawienie poziomu zostało uznane za pomyślne, wymagana jest większość odpowiedzi węzła repliki na węzeł koordynujący. Repliki danych w Cassandrze można udoskonalić pod względem odporności na uszkodzenia, wykorzystując konfiguracje data center i rack. Topologia określa, które węzły są wymagane do zagwarantowania spójności podczas operacji odczytu i zapisu. Instancja Bigtable może mieć jeden lub więcej klastrów albo kolekcję maksymalnie czterech zreplikowanych klastrów.
Bigtable i Cassandra działają jako magazyny szerokokolumnowe NoSQL. Klucz wiersza określa kolejność, w jakiej globalne sortowanie danych tabeli jest wyświetlane w Bigtable. W Bigtable węzły służą do równoważenia odpowiedzialności za kluczowe zakresy, które potocznie nazywane są tabletami. Usługa Bigtable nie wymusza typów danych kolumn wysyłanych przez klienta. Rodzina kolumn Bigtable wybiera, które kolumny w tabeli powinny być przechowywane i pobierane z jednej do drugiej. Każda tabela musi mieć co najmniej jedną rodzinę kolumn, ale tabele często mają ich więcej (maksymalna liczba kolumn w tabeli to 100). Klucz wiersza znajduje się w jednej komórce, a nazwa kolumny w drugiej.
Cassandra i Bigtable używają różnych metod wyboru węzła przetwarzania zarówno dla operacji odczytu, jak i zapisu. W Cassandrze rozróżniany jest klucz partycji, natomiast w Bigtable używany jest klucz wiersza. Tworząc zasady dotyczące wielu klastrów, zasady równoważenia obciążenia uwzględniające centra danych zapewniają korzyści wynikające z przełączania awaryjnego. Obie bazy danych zostały zoptymalizowane pod kątem szybkiego zapisu i wykorzystują do tego podobny proces. Obie bazy danych przechowują dane w plikach SSTable, które są niezmiennymi plikami. W Cassandrze należy skontaktować się z kilkoma replikami, zanim koordynator poinformuje klienta, że pisanie zostało zakończone. Ponieważ każdy klucz wiersza w Bigtable jest przypisany tylko do jednego węzła, wymagana jest odpowiedź z tego węzła, aby potwierdzić, że zapis się powiódł.
W wyniku fuzji SSTable obie bazy danych mogą wykluczać komórki. Podczas zwracania danych do Cassandry klauzula WHERE w zapytaniu CQL ogranicza liczbę wierszy. Podczas korzystania z Bigtable należy konsultować się tylko z węzłem odpowiedzialnym za zakres kluczy. Wyniki odczytu węzła można ograniczyć na różne sposoby. Podczas fazy zagęszczania Bigtable i Cassandra przechowują dane w SSTables, które są regularnie scalane. Bigtable nie ogranicza liczby wersji znaczników czasu dla każdej komórki, ale inne rozmiary wierszy mogą. Replikacja zapewniona przez Colossus gwarantuje wysoką trwałość danych.
Interfejs wiersza poleceń Bigtable, a także biblioteki klienckie dla różnych popularnych języków programowania uzupełniają możliwości Cassandry. Każdy węzeł Bigtable musi obsługiwać serię SSTables zawierających dane przechowywane w tych tabelach. Nie musisz już obliczać replik pamięci masowej w Bigtable tak, jak w przypadku Cassandry, podczas określania rozmiaru klastra. Instancje Bigtable zazwyczaj przechowują dane na dyskach półprzewodnikowych (SSD) lub dyskach twardych (HDD). W przeciwieństwie do Cassandry, która opiera się na teorii, że nie ma utraty gęstości pamięci, aby osiągnąć odporność na uszkodzenia, obciążenie pracą nie traci gęstości. Łatwo jest skalować instancję Bigtable w górę lub w dół zgodnie z potrzebami, aby spełnić wymagania dotyczące obciążenia przy minimalnym wysiłku i przestojach. Instancja może mieć tylko cztery klastry, ale można je zgrupować w dowolnym obsługiwanym regionie chmury na planecie.
Aby utworzyć metrykę dla pernodu QPS, Google zaleca wykorzystanie wydajności Bigtable z reprezentatywnymi danymi i zapytaniami. Bigtable zawiera zarządzane komponenty do typowych funkcji administracyjnych Cassandry. Tabela, która jest częścią klastra, jest tworzona jako odtwarzalna kopia tabeli w kopii zapasowej bigtable. Cena kopii zapasowej jest niższa niż Cloud Storage lub nie zużywa zasobów węzła. Inną opcją jest użycie zarządzanego eksportu danych do Cloud Storage w celu utworzenia kopii zapasowej Bigtable. Bigtable z łatwością zarządza typowymi zadaniami konserwacji wewnętrznej Cassandry, takimi jak instalowanie poprawek systemu operacyjnego, odzyskiwanie węzłów, naprawa węzłów, monitorowanie upakowania pamięci masowej i rotacja certyfikatów SSL. Pulpity nawigacyjne są gotowe do śledzenia wskaźników przepustowości i wykorzystania na poziomie instancji, klastra i tabeli na stronie konsoli Bigtable Google Cloud. Możesz użyć pulpitu nawigacyjnego monitorowania, aby przeprowadzić zaawansowane dostrajanie wydajności.
SQL jest używany w Bigtable, podobnie jak dostęp do danych za pomocą klucza wiersza w bazie danych NoSQL. Węzły są rozmieszczone w całej sieci, a plotki służą do utrzymania spójności sieci. Dzięki temu systemowi zwiększa się pojemność przechowywania danych i utrzymuje się dostępność bez pojedynczego punktu awarii.
Z drugiej strony Bigtable jest bardziej skalowalny i zapewnia wyższy poziom dostępności niż Cassandra. Bigtable jest również bardziej przyjazny dla użytkownika niż inne języki programowania, co czyni go doskonałym wyborem dla zestawów danych o mniejszej liczbie zasobów.
Czy Google nadal używa Bigtable?
Google Analytics, indeksowanie stron internetowych, MapReduce i wiele innych aplikacji Google, takich jak Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code hosting, wykorzystują go do generowania i modyfikowania danych przechowywanych w Bigtable, Google Maps , Książki Google, Moje wyszukiwanie
Czy Google używa Cassandry?
Topologia DataStax Astra Cassandra as a Service została wdrożona w Google Cloud przy użyciu systemu operacyjnego TensorFlow, a także przy użyciu systemu operacyjnego Apache Cassandra w trzech strefach Google Cloud.
Czy Bigtable to to samo co Hbase?
Znacznik czasu Bigtable jest przechowywany w mikrosekundach, podczas gdy znacznik czasu HBase jest przechowywany w milisekundach. To rozróżnienie może być przydatne podczas korzystania z biblioteki klienta HBase dla Bigtable i przeglądania odwróconych znaczników czasu.
Do czego służy Bigtable?
Baza danych Bigtable NoSQL to szerokokolumnowa baza danych, która idealnie nadaje się do użycia w bazie danych NoSQL. System jest zoptymalizowany pod kątem małych opóźnień, dużej liczby odczytów i zapisów oraz wysokiej wydajności na dużą skalę. Korzystanie z przypadków tabel jest zwykle ograniczone do określonej skali lub przepływności, która wymaga dużych opóźnień, takich jak Internet rzeczy (IoT), AdTech, FinTech i tak dalej.
Bigtable kontra BigQuery
Istnieje kilka kluczowych różnic między bigtable i bigquery. Bigtable zaprojektowano jako skalowalną, zorientowaną na kolumny bazę danych, podczas gdy bigquery zaprojektowano jako skalowalną, relacyjną bazę danych. Bigtable nie obsługuje SQL, podczas gdy bigquery tak. Bigtable nie jest tak szeroko stosowany jak bigquery, ale ma pewne zalety w stosunku do bigquery, takie jak możliwość skalowania do większej liczby kolumn i wierszy.
Na przestrzeni lat Google poczynił znaczne postępy w przechowywaniu ogromnych ilości danych w chmurze. Bigtable to petabajtowa, w pełni zarządzana usługa bazy danych NoSQL, oparta na obiektowej administracji bazą danych (OOPA). BigQuery jest zbudowany przy użyciu Bigtable i Google Cloud Platform, a także systemu bazy danych Google Dremel. Istnieją trzy główne różnice między BigQuery i Bigtable. Rozwiązanie Big Data as a Service (BaaS) to rozwiązanie oferowane przez Google Cloud BigQuery. BigQuery jest używany przez produkty Google, takie jak Analytics, Finanse, Wyszukiwanie spersonalizowane, Earth, Orkut i Writely. Gdy używane jest błyskawiczne przetwarzanie danych BigQuery, 35 miliardów wierszy można przetworzyć w ciągu kilku sekund.
Baza danych NoSQL jest akronimem usługi bazy danych; innymi słowy, nie jest to relacyjna baza danych. Kolumny klawiszy mogą mieć wiele rozmiarów, a paski klawiszy można przewijać w poziomie. Pojedyncze elementy danych o większej pojemności wynoszącej 10 megabajtów mogą obniżać wydajność. Jeśli potrzebujesz kompleksowego rozwiązania do przechowywania obiektów bez struktury (na przykład plików wideo), przechowywanie w chmurze będzie prawdopodobnie lepszą opcją. To doskonały wybór w przypadku zapytań wymagających skanowania tabeli lub przeglądania dużej bazy danych w jednym ujęciu. Przesłany obiekt nie może zmienić się w BigQuery przez cały okres jego istnienia, a jego dane są zawsze niezmienne. Tabele w bigtable przechowują skalowalne dane , które zostały posortowane na posortowane mapy kluczy/wartości według klucza, wiersza i znacznika czasu.
Dzięki Integrate.io możesz zautomatyzować proces ETL i integracji danych, aby połączyć swoje źródła danych i hurtownie danych w chmurze. Platforma integracyjna obejmuje ponad 100 gotowych integracji, w tym BigQuery, oraz interfejs typu „przeciągnij i upuść”, który sprawia, że zarządzanie procesami integracji jest łatwiejsze niż kiedykolwiek. Skontaktuj się z naszym zespołem ekspertów ds. danych, aby omówić swoją sytuację lub rozpocząć 14-dniowy pilotaż platformy Integrate.
Google BigQuery przoduje pod względem funkcji, pomimo faktu, że MySQL jest nadal powszechnie używany. Jest to szczególnie prawdziwe w przypadku funkcji powszechnie używanych w aplikacjach biznesowych, takich jak import i eksport danych, analiza danych i federacja danych. Z drugiej strony MySQL ma tylko 28 funkcji, co oznacza, że może nie być w stanie zaspokoić potrzeb wielu firm. Google BigQuery działa w chmurze, dzięki czemu można uzyskać do niego dostęp z dowolnego miejsca z połączeniem internetowym. Z drugiej strony MySQL działa w architekturze klient-serwer i nie jest dostępny w chmurze.
Jaka jest różnica między BigQuery a Bigtable?
Bigtable to szerokokolumnowa baza danych NoSQL zoptymalizowana pod kątem intensywnego odczytu i zapisu. W przeciwieństwie do BigQuery, który jest korporacyjną hurtownią danych dla dużych ilości relacyjnych danych, Oracle Data Warehouse służy jako usługa deduplikacji.
Czy BigQuery jest zbudowane na Bigtable?
Wkrótce potem pojawił się Bigtable, oparta na chmurze usługa zapytań opracowana we współpracy z Google i Microsoft, oraz system Google Dremel do zapytań ad hoc.
Kiedy powinienem używać Bigtable?
Bigtable jest idealny dla aplikacji, które wymagają dużej przepustowości i skalowalności podczas obsługi danych klucz/wartość, z nie więcej niż 10 MB danych na wartość. Mocne strony Bigtable to wsadowe operacje MapReduce, przetwarzanie strumieniowe/analiza i uczenie maszynowe.
Skalowalna usługa bazy danych Nosql
Skalowalna usługa bazy danych nosql to rodzaj bazy danych, która może obsługiwać dane na dużą skalę. Jest to usługa internetowa, której można używać do przechowywania i zarządzania dużymi ilościami danych. Ten typ bazy danych został zaprojektowany tak, aby był skalowalny, aby mógł obsługiwać dane na dużą skalę.
W tym samouczku założono, że masz działające środowisko Node.js. Stworzyłem folder o nazwie nodejs-dynamodb-sample, w którym można rozpakować pliki DynamoDB. Strona GitHub projektu to https://www.gofundme.com/adamfowleruk/nodesurvey.html. Przykładowa aplikacja używa DynamoDB do wyszukiwania i pobierania danych filmu. Aby przechowywać dane w S3, użyjemy usługi Amazon Identity and Access Management (IAM), a aby uzyskać dostęp do DynamoDB na AWS, użyjemy usługi DynamoDB firmy Amazon. Aby korzystać z usługi iADM firmy Amazon, musisz najpierw zarejestrować się i utworzyć użytkownika. Tytuł filmu i rok można dodać do sekcji POST/filmy w wyszukiwaniu.
Sporządź listę filmów z danego roku, wpisując pole wprowadzane kluczem. Możesz teraz utworzyć własną aplikację, korzystając z tego podstawowego przykładu. Jeśli zamierzasz ponownie używać swoich tabel, powinieneś je usunąć po zakończeniu korzystania z nich, co spowoduje poniesienie kosztów hostingu i obsługi AWS. W AWS przejdź do konsoli DynamoDB i wprowadź ilość używanej przestrzeni dyskowej. Możesz przeglądać elementy w tabeli, klikając „Filmy”, spojrzeć na wskaźniki widoczne w aplikacji i zobaczyć szacunkowe koszty miesięczne, klikając kartę Pojemność. Na mojej stronie GitHub dołączam próbkę kodu w tym ćwiczeniu: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Baza danych Google Cloud Bigtable
Google Cloud Bigtable to szybka, w pełni zarządzana usługa bazy danych NoSQL o wielkości petabajtów, która idealnie nadaje się do dużych obciążeń analitycznych i operacyjnych.
Magazyn danych Google lepiej nadaje się do aplikacji, które wymagają szybkich odpowiedzi na żądania użytkowników.
W bazie danych Google Bigtable nie ma relacyjnej bazy danych. Zapytania SQL, łączenia i transakcje wielowierszowe nie są obsługiwane. W rezultacie, jeśli szukasz standardowej obsługi baz danych, nie możesz tego oczekiwać. Z drugiej strony Bigtable nie zapewnia dużej ilości danych ani analiz. Zoptymalizowany charakter Bigtable wynika częściowo z jego wysokowydajnych możliwości analitycznych i obsługi danych. Z drugiej strony Datastore ma na celu umożliwienie dostarczania aplikacjom danych transakcyjnych o dużej wartości. W rezultacie Datastore lepiej nadaje się do aplikacji wymagających szybkich odpowiedzi na żądania użytkowników.