
Bazy danych NoSQL: wysoka dostępność i skalowalność dzięki replikacji
Opublikowany: 2022-11-19Istnieje wiele różnych typów baz danych NoSQL, z których każdy ma własne możliwości i funkcje. Jednak jedną wspólną cechą wielu baz danych NoSQL jest możliwość replikacji danych na wielu serwerach. Replikacja to proces kopiowania danych z jednego serwera na inny, dzięki czemu dane są dostępne na wielu serwerach. Replikacja może zapewnić zwiększoną dostępność i wydajność, umożliwiając odczyt danych z wielu serwerów. Bazy danych NoSQL zazwyczaj wykorzystują model replikacji master-slave, w którym jeden serwer jest wyznaczony jako master, a wszystkie inne serwery są slave. Serwer główny przechowuje kopię danych i replikuje zmiany na serwerach podrzędnych. Urządzenia podrzędne mogą być używane do odczytu danych, ale wszystkie zapisy muszą przechodzić przez urządzenie nadrzędne. Jedną z zalet replikacji jest to, że może ona pomóc poprawić wydajność poprzez dystrybucję odczytów na wiele serwerów. Replikacja może również poprawić dostępność, udostępniając wiele kopii danych na wypadek awarii jednego serwera. Bazy danych NoSQL zazwyczaj oferują wysoką dostępność i skalowalność dzięki możliwości replikacji danych na wielu serwerach.
Podobnie replikacja danych NoSQL to solidna funkcja, która umożliwia bezproblemowe kopiowanie i przechowywanie danych ustrukturyzowanych, nieustrukturyzowanych i częściowo ustrukturyzowanych, a także zapobieganie utracie danych w przypadku awarii serwera. Dowiedz się więcej o bazach danych NoSQL na tej stronie.
Ma miejsce zarówno replikacja master-slave, jak i slave, a replikacja master-slave wyznacza węzeł jako autorytatywną kopię, która może obsługiwać zarówno zapis, jak i odczyt. Proces replikacji peer-to-peer umożliwia węzłom wzajemny zapis, a każdy węzeł kopiuje dane do następnego.
Replikacja MongoDB odnosi się do tworzenia zestawu replik, który współdzieli wspólny zestaw danych z innymi instancjami MongoDB . Zestaw replik zawiera pewną liczbę węzłów zawierających dane, a węzeł będący arbitrem jest opcjonalny. Istnieje sześć węzłów w środowisku przenoszącym dane, z których jeden element jest wyznaczony jako węzeł główny, a pozostałe elementy są sklasyfikowane jako węzły drugorzędne.
Ogólnie rzecz biorąc, eksperyment lub procedura, która daje więcej niż określoną liczbę wyników, jest sukcesem; w tym przypadku replikacja DNA jest kopiowana lub replikowana. Akt replikowania czegoś jest określany jako replikacja.
Co to jest replikacja danych Nosql?
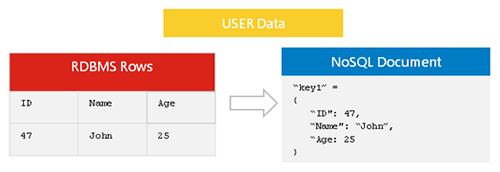
Replikacja danych Nosql to proces kopiowania danych z jednej bazy danych Nosql do drugiej. Można to zrobić z różnych powodów, takich jak utworzenie kopii zapasowej lub dystrybucja danych na wielu serwerach. Replikacja danych Nosql jest generalnie wykonywana asynchronicznie, co oznacza, że kopia danych nie musi być dokładną repliką oryginalnych danych.
Od wielu lat replikacja danych jest niezbędnym elementem infrastruktury danych każdej organizacji. System replikacji danych ochroni Twoje dane, zapewniając wysoką dostępność, tworzenie kopii zapasowych i odzyskiwanie po awarii. Ponadto replikacja pomaga organizacji w poprawie spójności i dokładności danych. Jest to metoda poprawy niezawodności danych poprzez proces replikacji. Replikując dane, możesz mieć pewność, że są one zawsze dostępne, mają kopię zapasową i na wypadek awarii. Replikując dane, może również poprawić ich spójność i dokładność. Podczas projektowania infrastruktury danych niezwykle ważne jest uwzględnienie replikacji danych.
Co to jest dzielenie i replikacja w Nosql?
Jaka jest różnica między dzieleniem na fragmenty a replikacją? Węzeł serwera podstawowego kopiuje dane z węzłów serwera pomocniczego w ramach replikacji danych. W ten sposób możesz zwiększyć dostępność danych i uczynić z nich awaryjną kopię zapasową na wypadek awarii głównego serwera. Zarządza skalowaniem serwerów na powierzchniach poziomych za pomocą klucza shard.

Czy bazy danych Nosql mają nadmiarowość danych?
Gdy istnieje znaczna ilość danych, a nadmiarowość danych może być tolerowana, baza danych NoSQL najlepiej nadaje się do określonych typów aplikacji i selektywnych przypadków użycia.
Czy Nosql można podzielić?
Partycjonowanie według wzorca mikrousług jest używane w środowiskach NoSQL. Wzorzec polega na podziale każdej partycji na wiele serwerów, które mogą, ale nie muszą, znajdować się w tej samej lokalizacji na całym świecie. To skalowanie w poziomie działa dobrze dla osób z całego świata, które chcą uzyskać dostęp do różnych części zestawu danych i osiągnąć wysoką wydajność.
Co to jest replikacja w bazie danych?
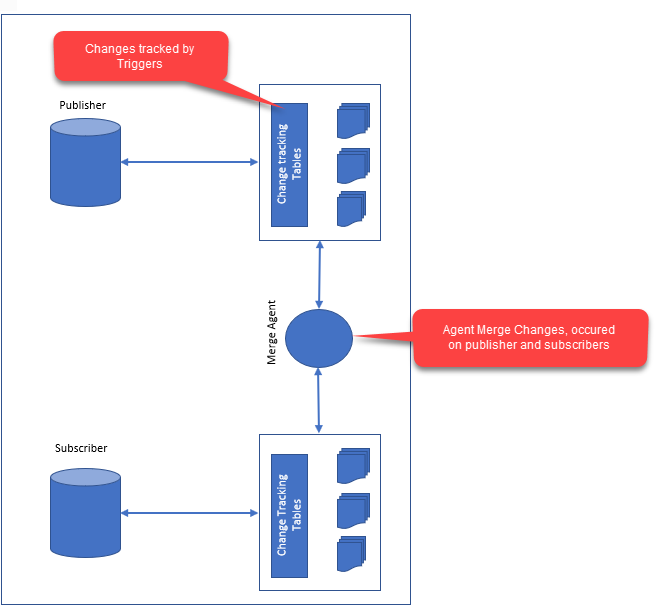
Replikacja w bazie danych to proces kopiowania danych ze źródłowej bazy danych do docelowej bazy danych. Dwie bazy danych mogą znajdować się na tym samym serwerze lub na różnych serwerach. Replikacja może służyć do tworzenia kopii zapasowych danych, dystrybucji danych na wiele serwerów lub umożliwiania wielu użytkownikom dostępu do danych.
Integralność danych i wydajność to dziś krytyczne aspekty replikacji danych . Przepisywanie danych może być tak proste, jak wysłanie ich do subskrybenta, lub tak skomplikowane, jak przeprowadzenie wielu eksperymentów jednocześnie. Najpowszechniejszą formą replikacji jest replikacja migawki. W przypadku dużej ilości danych lub gdy abonent jest zdalny, wysyła do niego cały zestaw danych. Jest to bardziej zaawansowana forma replikacji niż replikacja transakcyjna. W niektórych przypadkach wysyła modyfikacje danych tylko do abonenta lub danych, co może być korzystne w małych lub lokalnych plikach. Jest to bardziej złożona technika replikacji. Elementy można modyfikować zarówno po stronie wydawcy, jak i subskrybenta, co może być przydatne w sytuacjach, gdy dane są duże lub wydawca i subskrybent są odlegli. Replikacja heterogenicznych danych jest zatem możliwa w celu uzyskania dostępu do różnych produktów bazodanowych. Jest to szczególnie przydatne w przypadku danych, które są duże i mają wiele typów maszyn, takich jak wydawcy i subskrybenci.
Co oznacza replikacja w Mongodb?
Replikacja MongoDB to metoda replikacji zestawu danych wielu serwerów MongoDB. Można to osiągnąć za pomocą zestawu replik. Zestaw replik to zbiór instancji MongoDB, które obsługują ten sam zestaw danych MongoDB i są powiązane z tym samym procesem.
Podczas tworzenia zestawu replik węzeł główny jest wybierany automatycznie. Gdy stanie się dostępny, węzeł dodatkowy będzie węzłem podstawowym z najwyższym oznaczeniem zestawu replik. Zestaw replikacji MongoDB określa role węzła podstawowego i wtórnego, a jeśli oba węzły są dostępne, MongoDB automatycznie konfiguruje węzeł podstawowy. Jest to zbiór instancji MongoDB, które są identyczne pod względem zbioru danych i procesu. Administratorzy baz danych mogą oferować nadmiarowość danych poprzez replikację danych. Dane są powszechnie dostępne. Zestaw replik to zbiór węzłów MongoDB zorganizowanych w grupy do replikacji. Zestaw replikacji musi mieć co najmniej trzy węzły MongoDB: jeden z trzech węzłów jest uważany za węzły podstawowe odpowiedzialne za odbieranie wszystkich operacji zapisu. Gdy tworzony jest pierwszy zestaw replik, węzeł podstawowy jest wybierany automatycznie.