
Bazy danych NoSQL: dzielenie i replikacja
Opublikowany: 2022-11-21Bazy danych NoSQL są często używane do przechowywania danych na dużą skalę ze względu na ich zdolność do skalowania w poziomie. Oznacza to, że można je skalować, dodając więcej węzłów do systemu, zamiast aktualizować sprzęt pojedynczego węzła. Jednym ze sposobów osiągnięcia tej skalowalności poziomej jest sharding, czyli proces dystrybucji danych w wielu węzłach. Replikacja to kolejny sposób skalowania baz danych NoSQL, który obejmuje tworzenie kopii danych w wielu węzłach.
Zarówno w przypadku baz danych SQL, jak i NoSQL koncepcja dzielenia bazy danych na fragmenty ma kluczowe znaczenie dla skalowania. Baza danych jest podzielona na kilka fragmentów (odłamków), jak sugeruje nazwa.
Replikacji danych NoSQL można również użyć, aby upewnić się, że nie utracisz danych w przypadku awarii serwera, bezproblemowo kopiując i przechowując ustrukturyzowane, nieustrukturyzowane i częściowo ustrukturyzowane dane. Możesz dowiedzieć się więcej o bazach danych NoSQL, odwiedzając tę stronę.
Relacyjną bazę danych można podzielić na partycje przy użyciu metody Sharding, znanej również jako partycja pozioma. Usługa relacyjnej bazy danych Amazon ( Amazon RDS ) to zarządzana usługa relacyjnej bazy danych, która ułatwia korzystanie z niej w chmurze, oferując różnorodne funkcje.
Metoda replikacji kopiuje dane z wielu serwerów i umieszcza je w miejscu, w którym można je znaleźć. Podczas replikacji tworzone są kopie główne i podrzędne, przy czym kopie główne stają się autorytatywnymi kopiami obsługującymi dane pisane, a kopie podrzędne stają się kopiami asynchronicznymi obsługującymi dane pisane.
Czy Nosql używa Shardingu?
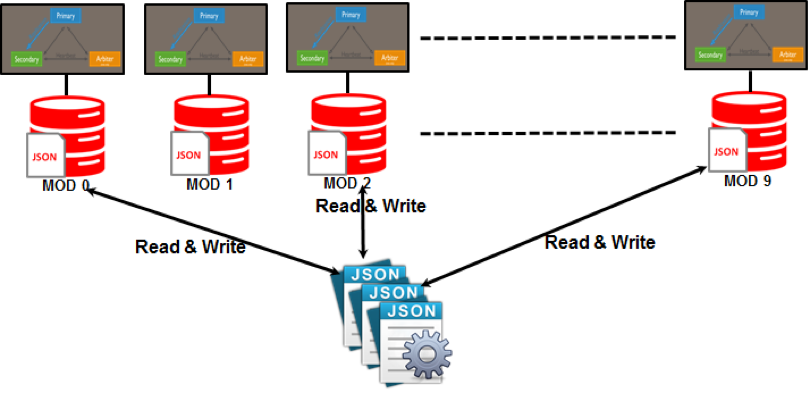
Wzorce partycji, takie jak udostępnianie, są używane w NoSQL. Partycjonowanie to proces przypisywania każdej partycji do serwera, który prawdopodobnie będzie niezależny od reszty sieci. Dzięki takiemu skalowaniu w poziomie możesz zapewnić użytkownikom na całym świecie dostęp do zróżnicowanego zestawu danych przy zachowaniu możliwie najwyższego poziomu wydajności.
Rozwiązaniem jest klaster MySQL. MySQL Cluster to zestaw oprogramowania, które automatycznie dzieli tabele na fragmenty między węzłami i umożliwia poziome skalowanie baz danych na niedrogim sprzęcie w celu obsługi obciążeń wymagających intensywnego odczytu i zapisu przy użyciu języka SQL, a także bezpośrednio za pośrednictwem interfejsów API NoSQL. Klaster MySQL ma potencjał do wykorzystania w znacznie szerszym zakresie niż tylko łańcuchy bloków. Może być również używany do skalowania aplikacji za pomocą klastra MySQL. Powodem tego jest to, że MySQL Cluster jest systemem planowania. W rezultacie możesz skalować swoje aplikacje, decydując, kiedy i jak będą generowane shardy. Jest to główna zaleta, ponieważ nie musisz polegać na przetwarzaniu w chmurze . Wynika to z faktu, że shardy są tworzone w węzłach, w których wykonywane jest obciążenie. W rezultacie możesz kontrolować, ile współbieżności jest wymagane. W rezultacie MySQL Cluster ma bardzo potężny zestaw funkcji. Można go używać do skalowania aplikacji i kontrolowania wymaganej współbieżności.
Co to jest dzielenie i replikacja w Nosql?
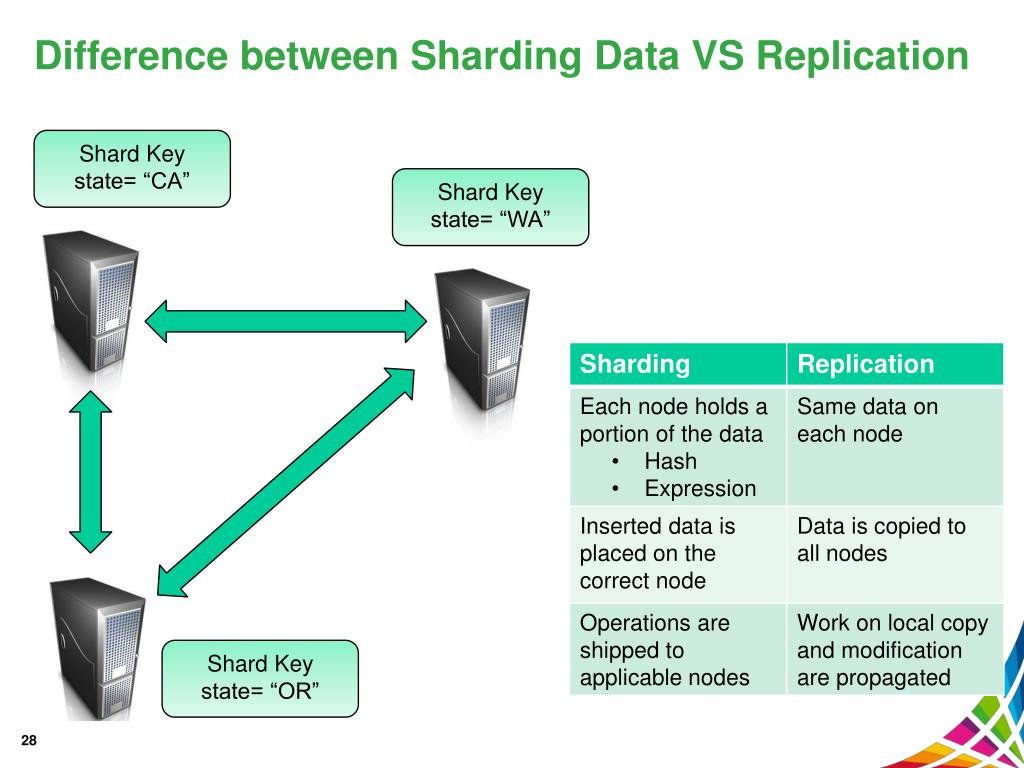
Jaka jest różnica między replikacją a shardingiem? Replikacja danych to czynność przesyłania danych z głównego węzła serwera do drugorzędnych węzłów serwera . Jako kopia zapasowa na wypadek awarii serwera podstawowego może pomóc w zapewnieniu dostępności danych. Ta funkcja może służyć do skalowania serwerów w poziomie przy użyciu klucza fragmentu.
Zalety dzielenia
Gdy masz do czynienia z danymi, które muszą zostać podzielone na partycje, ale brakuje im zasobów do ich replikacji, odstępy mogą być korzystne w różnych sytuacjach. Gdy zachodzi potrzeba skalowania odczytów, przydatna jest replikacja, ale zapisy danych mogą być obsługiwane wydajniej dzięki fragmentowaniu. Wybór niewłaściwego klucza odłamka może mieć negatywny wpływ na wydajność systemu.
Czy Mongodb używa Shardingu?
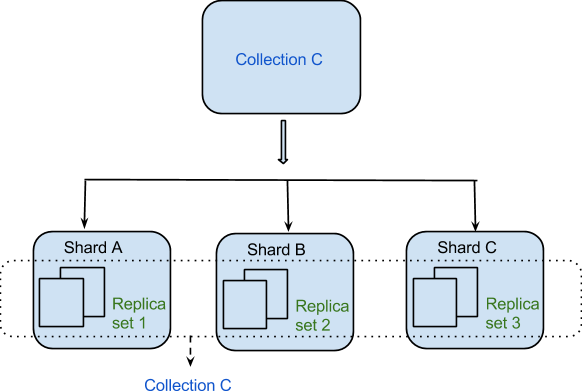
Dane są dystrybuowane między maszynami w sposób rozproszony dzięki Shardingowi. MongoDB wykorzystuje sharding do obsługi wdrożeń na dużą skalę, które wymagają wysokiego poziomu przepustowości. Zbudowanie pojedynczego serwera dla systemu bazy danych z dużą liczbą zestawów danych lub aplikacji o dużej przepustowości może być trudne.
Najbardziej powszechną strategią rozwiązywania problemów z zasięgiem jest podejście w najbardziej ogólnym sensie. Węzeł główny klastra ma z góry określoną liczbę fragmentów, które można podzielić na podstawie ich odległości od centrum danych klastra. Węzeł podstawowy jest nazywany węzłem głównym, ponieważ jest pierwszym węzłem tworzonym w zbiorze danych. Inny typ fragmentu jest nazywany fragmentem wtórnym. Możliwa jest zarówno transakcja dystansowa, jak i transakcja mieszająca. Wartość klucza skrótu określonego fragmentu określa, ile danych może wygenerować. Identyfikator jest tworzony przez klucz skrótu dla każdej części danych w transakcji. Istnieje wiele zalet i wad każdej strategii. Łatwiej jest zaimplementować dzielenie zakresu, gdy zestaw danych jest mały, w przeciwieństwie do dużego zestawu, i jest bardziej wydajny, gdy jest mały. Gdy zestaw danych jest duży, haszowanie jest bardziej wydajne. Reputacja MongoDB w zakresie szybkości wynika z faktu, że obsługuje on delegowanie danych do innych usług MongoDB. Fragmenty zestawu danych mogą być dystrybuowane między wieloma serwerami w MongoDB, aby poprawić szybkość przetwarzania danych. MongoDB oprócz shardingu obsługuje wiele opcji replikacji. W rezultacie replikacja umożliwia dystrybucję zestawu danych na wielu serwerach w celu zachowania spójności. Replikacja danych jest konieczna, jeśli chcesz mieć pewność, że informacje są zawsze dokładne i aktualne. Ponadto rozproszone klastry w MongoDB mogą być przydatne do poprawy wydajności. Sraving to technika przesyłania dużych ilości danych z jednego serwera na drugi w taki sam sposób, jak replikacja. Klucz fragmentu to element danych, który można skopiować (lub „fragmenty”) z jednego serwera na inny. Dwie podstawowe metody dystrybucji danych w klastrach podzielonych na fragmenty w MongoDB to oparte na zakresie i rozproszone. Haszowanie można wykonać za pomocą zaszyfrowanego serwera. Dzieląc rzeczy, możesz osiągnąć więcej niż jedną rzecz.

Czy powinieneś podzielić swój Mongodb?
Nie jest pewne, czy sharding poprawia wydajność w niektórych przypadkach, ale wykazano, że w niektórych przypadkach zwiększa wydajność. Ponadto w rezultacie sharding wprowadza własny zestaw wyzwań, takich jak zapewnienie niezawodnych kopii zapasowych i przywracania. Zanim zdecydujesz się na strategię shardingu , powinieneś pomyśleć o jej zaletach i wadach.
Sharding w Nosql
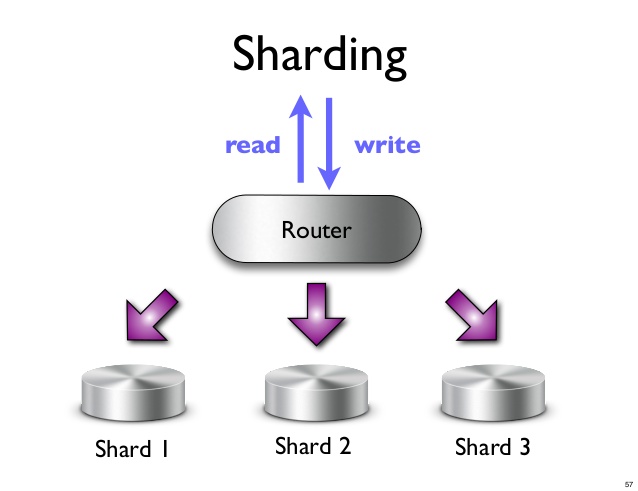
Fragment to pozioma partycja danych w bazie danych lub wyszukiwarce. Każdy fragment jest niezależną instancją bazy danych lub wyszukiwarki. W bazie danych NoSQL zbiór dokumentów można podzielić na fragmenty, z których każdy jest przechowywany na osobnym serwerze.
Sharding vs replikacja
Różnica między replikacją a shardingiem polega na tym, że replikacja polega na powielaniu danych, podczas gdy sharding polega na podziale danych na oddzielne porcje. W tym przypadku podzieliłeś swoją kolekcję na kilka części w oparciu o sharding. Pobranie bazy danych daje obrazy wszystkich zestawów danych.
Korzyści z dzielenia
Dane są dzielone na wiele maszyn w celu zwiększenia liczby jednoczesnych użytkowników i poprawy wydajności. Dane przechowywane są na osobnych partycjach w każdej z maszyn.
Replikacja w Nosql
Istnieje kilka różnych sposobów obsługi replikacji w bazie danych NoSQL. Jednym ze sposobów jest automatyczna replikacja bazy danych na serwer pomocniczy za każdym razem, gdy nastąpi zmiana. Dzięki temu zawsze dostępna jest kopia zapasowa na wypadek awarii serwera podstawowego. Innym sposobem jest regularne ręczne replikowanie danych na serwer pomocniczy. Daje to administratorowi większą kontrolę nad tym, kiedy nastąpi replikacja, ale oznacza również, że istnieje szansa, że serwer zapasowy nie będzie aktualny w przypadku awarii.
Co to jest dzielenie w bazie danych
Sharding to proces poziomego podziału danych w bazie danych. Podczas shardingu baza danych jest dzielona na mniejsze części, zwane shardami. Każdy fragment jest przechowywany na osobnym serwerze. Proces shardingu pomaga poprawić wydajność bazy danych poprzez rozłożenie obciążenia na wiele serwerów.
Pojedynczy fragment danych może zostać zreplikowany w pojedynczej transakcji przy pomocy shardingu. W wyniku podziału zbioru danych na mniejsze części i rozmieszczenia ich na wielu serwerach można zwiększyć ogólną pojemność pamięci masowej systemu. W niektórych przypadkach może to być przydatne, jeśli dane są duże i wymagają wielu serwerów do ich utrzymania. Obce opakowania danych są również używane do odczytywania danych ze zdalnych serwerów, zapewniając jeszcze większą elastyczność przechowywania danych.
Jaka jest różnica między partycjonowaniem a dzieleniem?
Partycjonowanie i dzielenie na fragmenty to dwa podejścia do strukturyzowania dużych kolekcji danych w małe fragmenty. Zarówno sharding, jak i partycjonowanie oznaczają, że dane są rozproszone na wielu komputerach, ale są one różne. Procedura partycjonowania instancji bazy danych obejmuje grupowanie w niej podzbiorów danych.
Która baza danych jest najlepsza do dzielenia?
Dzielenie bazy danych na fragmenty jest obsługiwane przez Cassandra, HBase, HDFS, MongoDB i Redis. Bazy danych, które nie obsługują natywnie PostgreSQL, Memcached, Zookeeper, MySQL i Sqlite, są uważane za bazy danych. Logika Jarryda musi być obecna w aplikacji, jeśli nie ma ona wbudowanej obsługi baz danych.
Czy dzielenie jest możliwe w Sql?
Możliwe jest jednak zaimplementowanie shardingu opartego na zakresie (zasadniczo poziomego) w sposób, który czyni go bardziej przejrzystym dla aplikacji. Typowym sposobem na zrobienie tego w SQL Server jest widok podzielony na partycje, ale nie musi tak być.