
Bazy danych NoSQL: internetowe bazy danych dla dużego ruchu i dużych zbiorów danych
Opublikowany: 2022-11-18Bazy danych Nosql to internetowe bazy danych, które mogą obsłużyć duży ruch i duże zbiory danych. Zostały zaprojektowane tak, aby były skalowalne i mogły obsługiwać duże obciążenia. Bazę danych nosql można skalować w poziomie, dodając do systemu więcej serwerów. Dzięki temu system może obsłużyć większy ruch i przechowywać więcej danych.
Wzrost zapotrzebowania na złożone aplikacje wymaga większej elastyczności. Równie ważne jest wybranie magazynów danych, które można łatwo skalować i wydajnie działać. Najważniejszym problemem jest to, czy bazy danych „ASL” czy „NoSQL” są lepsze do uruchamiania aplikacji. Bazy danych SQL są używane od dłuższego czasu, ale wiadomo, że bazy danych NoSQL są łatwiejsze do skalowania. W przypadku baz danych NoSQL założeniem jest, że sharding powinien być wykonywany we wszystkich operacjach. Węzeł można zidentyfikować za pomocą funkcji kwalifikującej, której oczekuje się od każdej operacji na danych w bazie danych. Ponieważ dane są przechowywane na wielu komputerach, obsługa operacji na danych nawet na najbardziej podstawowych komputerach jest bardzo wydajna.
Dzięki tej funkcji proste maszyny towarowe mogą służyć do skalowania sklepów NoSQL. NoSQL zakłada, że użytkownik może zaplanować i ustrukturyzować dane tak, aby były one pobierane tylko z tego samego węzła w danym momencie dla dowolnej operacji. Ponadto można przeprowadzić denormalizację danych w węzłach (wstępnie przygotowane dane do uruchomienia). Jest miejsce na połączenia NoSQL, ale nie oczekuj, że będą bogate w SQL lub zoptymalizowane. W praktyce zakłada się, że dane zawsze będą spójne z aplikacjami NoSQL. Istnieje wiele systemów NoSQL, które zapewniają przełączniki modyfikujące spójność w czasie, jeśli spójność jest ważna. Celem każdej decyzji dotyczącej architektury, podobnie jak celem oceny przypadku użycia, jest wybór odpowiedniego magazynu danych.
Poziomą pulę zasobów można rozszerzyć, dodając do niej więcej maszyn, podczas gdy pulę skalowaną w pionie można rozszerzyć, dodając do niej więcej maszyn.
Bazy danych SQL i bazy danych NoSQL używają skalowania pionowego ze względu na sposób przechowywania danych (powiązane tabele a niepowiązane kolekcje), podczas gdy bazy danych NoSQL używają skalowania poziomego, ponieważ nie używają powiązanych tabel.
Typ skalowania obsługiwany przez NoSQL jest poziomy.
Aby skalować w poziomie, MongoDB wykorzystuje wbudowany mechanizm, który umożliwia przenoszenie danych między wieloma serwerami. Ten proces jest określany jako sharding i można go wykonać, naciskając przycisk przełączania na stronie konfiguracji interfejsu użytkownika Atlas. Poza tym proces można również zakończyć bez przestojów.
Jak działa skalowanie w poziomie w Nosql?
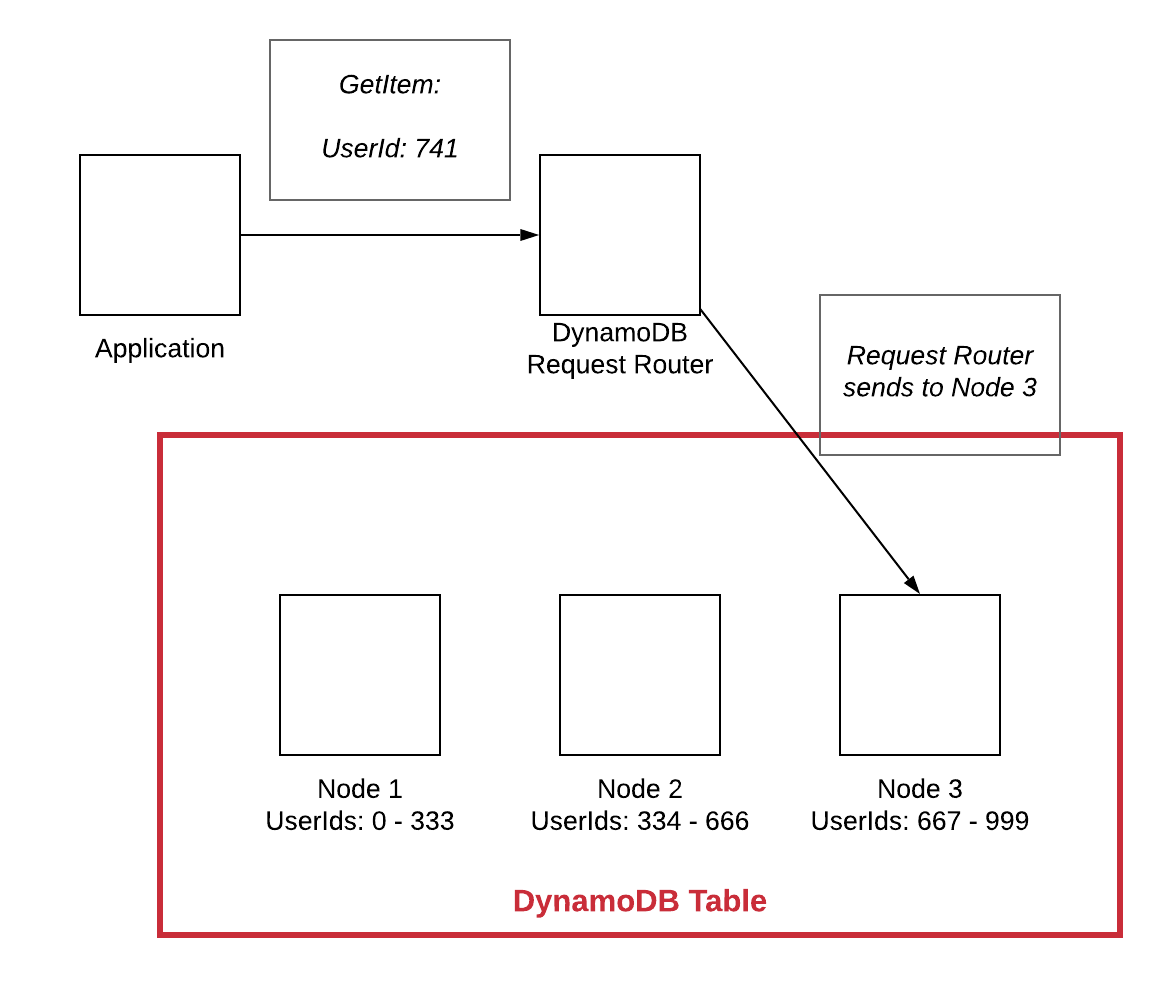
Skalowanie poziome w bazie danych NoSQL oznacza, że bazę danych można skalować, dodając więcej maszyn do systemu, zamiast zwiększać szybkość lub wydajność pojedynczej maszyny. Dzięki temu system może obsłużyć większy ruch i dane bez problemów z wydajnością.
Skalowanie poziome ma wiele zalet: możesz łatwo dodać więcej serwerów, aby obsłużyć zwiększony ruch, i nie musisz się martwić o jednoczesne ładowanie wierszy z wielu serwerów. W rezultacie bazy danych NoSQL stanowią doskonały wybór dla firm, które chcą przechowywać dane na żądanie, jednocześnie oszczędzając pieniądze na przechowywaniu danych .
Bazy danych Nosql lepiej radzą sobie z dużymi zbiorami danych
Ze względu na ograniczenia relacyjnych baz danych nie mogą one obsługiwać dużych zbiorów danych. Bazy danych NoSQL, takie jak MongoDB, przechowują dane w samodzielnym formacie dokumentu, umożliwiając dystrybucję danych w wielu węzłach. Dzięki tej funkcji baza danych jest w stanie szybko i łatwo obsłużyć duże zbiory danych.
Jak Mongodb może skalować się w poziomie?
MongoDB może skalować się w poziomie za pomocą shardingu. Sharding to proces dzielenia danych na wiele serwerów. Każdy serwer ma własną część zestawu danych, a dane są równomiernie rozłożone na serwerach. Po wysłaniu żądania serwer MongoDB określi, który serwer ma żądane dane i pobierze je z tego serwera. Ten proces umożliwia MongoDB skalowanie w poziomie i obsługę dużych ilości danych.
Jeśli chodzi o skalowanie infrastruktury, wiele firm ma trudności. Platforma bazy danych MongoDB jako usługa obsługuje szeroki zakres opcji skalowania i jest wbudowana w jej zaplecze. Technika skalowania w poziomie jest znana jako sharding (ponieważ jest preferowana). Termin „skalowanie warstwowe” odnosi się do zdolności pojedynczego serwera lub klastra do skalowania w górę. Jest to metoda skalowania poziomego, która obejmuje dystrybucję danych w wielu węzłach. Platforma MongoDB Atlas automatycznie konfiguruje shard key, co nadal zależy od nas. Oczywiste jest, że zestawy replik i sharding są podobne, ale zestawy danych nie są takie same.
Ponadto mogą powodować problemy z dużą liczbą transakcji zapisu dla aplikacji. Atlas MongoDB obsługuje również skalowanie w poziomie i w pionie. Wdrożenie podzielonego na fragmenty klastra umożliwia skalowanie w poziomie. Krótko mówiąc, skalowanie pionowe jest tak proste, jak skonfigurowanie warstwy klastra. W przypadku całkowitego wyłączenia klastra można go wstrzymać, aby utrzymać klaster na poziomie 0, efektywnie skalując cały klaster do 0 z wyjątkiem pamięci masowej.
MongoDB to doskonała baza danych NoSQL, podobnie jak nowoczesna aplikacja, która musi skalować się w poziomie, aby obsługiwać duże zbiory danych. MongoDB ma prosty interfejs API, który ułatwia programistom dostęp do danych i manipulowanie nimi, a przechowywanie bez schematów ułatwia przechowywanie i pobieranie danych. Ponadto, ponieważ MongoDB obsługuje replikację, dane można łatwo replikować na wielu serwerach, zapewniając ich dostępność do wykorzystania w przyszłości.
Skalowalność Mongodb
MongoDB to jeden z najbardziej elastycznych języków programowania. W bazach danych zorientowanych na dokumenty, takich jak MongoDB, dane są przechowywane w dokumentach podobnych do JSON. Proces MongoDB skaluje się poziomo za pomocą shardingu. Srave to technika dystrybucji danych, która wykorzystuje wiele kolekcji i maszyn do dystrybucji danych w bazach danych i maszynach.
Czy Sql Db jest skalowalny w poziomie?
W przypadku skalowania poziomego bazy danych są dodawane lub usuwane w celu wykonania określonego zadania, takiego jak zwiększenie lub zmniejszenie ogólnej pojemności lub wydajności. Skalowanie poziome jest zwykle realizowane przez łączenie danych z wielu baz danych o identycznej strukturze, a następnie rozdzielanie ich w osobne tabele.
Każda baza danych każdego dnia musi być skalowana, aby obsłużyć ilość generowanych danych. Skalowanie dzieli się na dwa typy: pionowe i poziome. Pamięć serwera 2 TB wystarcza na przechowywanie większej ilości danych. Kupuje duży serwer za bardzo wysoką cenę. Dodanie większej liczby maszyn do serwera jest określane jako skalowanie poziome. Jego celem jest podzielenie zestawu danych na wiele serwerów lub fragmentów. Bezsensowne byłoby posiadanie jednego punktu prawdy opartego na denormalizacji. Takie podejście ma jedną wadę: jeśli master nie zaktualizuje replik podrzędnych podczas wykonywania zapisu, master nie zaktualizuje replik podrzędnych.
Replikacja to akt wymiany danych między węzłami w klastrze. Replikując dane, można zwiększyć dostępność i odzyskiwanie serwera. Ponadto replikację można wykorzystać do rozłożenia obciążenia na wiele klastrów węzłów. Organizacja może poziomo podzielić swoje dane na mniejsze porcje i rozmieścić te porcje w wielu węzłach. Partycjonowanie poziome poprawia wydajność. Oprócz domyślnych klastrów MongoDB istnieje kilka różnych typów klastrów MongoDB. Ogólnie klaster z jednym węzłem jest najprostszym typem klastra i dobrze nadaje się do testowania i programowania. Klaster z dwoma węzłami jest najbardziej powszechnym typem klastra i nadaje się do zastosowań o średniej i dużej skali. Popularny jest również klaster z trzema węzłami, który nadaje się do zastosowań na dużą skalę. Na przykład w klastrze z dwoma węzłami dane są dzielone na dwa oddzielne fragmenty w każdym węźle. W takim przypadku każdy węzeł ma kopię danych. Gdy obciążenie jednego węzła rośnie, drugi węzeł może być w stanie obsłużyć obciążenie. Klaster z równoważeniem obciążenia jest jednym z najpopularniejszych typów klastrów. Klaster z trzema węzłami składa się z trzech oddzielnych centrów danych, z których każde zawiera trzy oddzielne fragmenty. Jeśli obciążenie jednego węzła wzrośnie, pozostałe dwa węzły mogą przejąć kontrolę. Zrównoważony klaster jest jednym z tych klastrów. Baza danych MongoDB to nowoczesna baza danych oparta na dokumentach z możliwością skalowania poziomego: replikacją i partycjonowaniem poziomym (lub shardingiem). Proces poziomego skalowania bazy danych polega na dodawaniu większej liczby instancji lub węzłów w celu obsługi zwiększonego zapotrzebowania. Gdy potrzebujesz większej pojemności, po prostu dodaj więcej serwerów do klastra. Ponadto serwery są zwykle mniejsze i tańsze niż te używane do komputerów stacjonarnych. Jest to proces kopiowania danych pomiędzy węzłami w klastrze. Partycjonowanie danych w poziomie dzieli je na mniejsze fragmenty i rozdziela je na wiele węzłów w systemie rozproszonym. Istnieje kilka typów klastrów MongoDB, z których każdy ma odrębny zestaw funkcji. Powszechne są również klastry z trzema węzłami, chociaż nie są one tak efektywne jak klastry z czterema węzłami.

Skalowanie w poziomie z relacyjną bazą danych
Tradycyjna baza danych SQL zazwyczaj nie może być skalowana w poziomie, ponieważ musi pomieścić więcej serwerów, ale nadal możemy dodawać repliki innych maszyn. Dziennik zapisu z wyprzedzeniem służy do propagowania wszystkich operacji zapisu z serwera głównego na inne komputery. Ze względu na elastyczność składni zapytań relacyjne bazy danych nie mogą być skalowane w poziomie. Aby upewnić się, że żadne fragmenty danych nie zostaną pobrane, dopóki nie wykonasz zapytania, SQL umożliwia dodanie tak wielu warunków i filtrów do danych, że baza danych nie jest w stanie przewidzieć, które części zostaną pobrane. W rezultacie baza danych może działać wolno, gdy próbuje przetworzyć duże ilości danych. Ponieważ relacyjne bazy danych mogą być skalowane w poziomie, mogą pomóc pokryć obszary, w których Spark jest zwykle mniej efektywny, czy to działając jako nośnik pamięci dla przesyłania strumieniowego Spark, czy obliczeń wsadowych. Platforma Cloud SQL nie obsługuje natywnie tych konfiguracji, ale można je zaimplementować za pomocą narzędzi branżowych, takich jak ProxySQL. Jednak podstawowa koncepcja Cloud SQL nie jest przeznaczona do tego typu scenariuszy.
Dlaczego Nosql jest skalowalny w poziomie
Bazy danych NoSQL można skalować w poziomie lub w pionie, w zależności od ich wymagań. Możesz poradzić sobie z sytuacjami o dużym natężeniu ruchu, dzieląc bazę danych NoSQL na fragmenty, dodając więcej serwerów do procesu. Bazy danych NoSQL są preferowanym wyborem w przypadku dużych i często zmieniających się zbiorów danych, ponieważ można je skalować w poziomie, a nie w pionie.
Powinien być w stanie obsłużyć bardzo duże bazy danych , z bardzo wysokimi wskaźnikami żądań, przy bardzo małych opóźnieniach. Skalowalność i dostępność to kluczowe wymagania dla witryn o dużym natężeniu ruchu, takich jak eBay, Amazon, Twitter i Facebook. Gdy masz możliwość jednoczesnego uruchamiania wielu instancji na serwerze, skalowanie w poziomie jest idealne.
Ze względu na swoją skalowalność i elastyczność bazy danych NoSQL zyskują na popularności w porównaniu z bazami SQL. Ponadto działają lepiej w porównaniu z bazami danych opartymi na tabelach dla danych nieustrukturyzowanych, które mogą być trudne do przetwarzania i przechowywania.
Jak skalować bazę danych Nosql
Nie ma jednej uniwersalnej odpowiedzi na to pytanie, ponieważ najlepszy sposób skalowania bazy danych NoSQL zależy od konkretnych potrzeb aplikacji i przechowywanych danych. Jednak niektóre wskazówki dotyczące skalowania bazy danych NoSQL obejmują dodawanie większej liczby węzłów do klastra w celu zwiększenia pojemności i wydajności, używanie fragmentacji do dystrybucji danych w wielu węzłach oraz replikowanie danych do wielu węzłów w celu zapewnienia wysokiej dostępności.
Kilka ważnych punktów zostało omówionych, gdy Rahim Yaseen z Couchbase przeprowadza nas przez nie. Organizacje starają się zarządzać, przechowywać i zarabiać na swoich ogromnych ilościach danych. Jedną z ważnych decyzji dotyczących bazy danych jest to, czy skalować w poziomie. Rejestracja jest dystrybuowana do stanowisk odprawy w trybie ręcznego shardingu. Osiąga się to dzięki dobrze zdefiniowanemu, z góry zdefiniowanemu schematowi. W ramach autoshardingu musiałbyś przejść do każdej kabiny, aby dowiedzieć się, kto zameldował się z nazwiskiem zaczynającym się na S. Bazy danych dokumentów mają wzorce dostępu, które wymagają od użytkowników przejścia do innego dokumentu za pomocą określonego klucza i dostępu do danych za pomocą jednego klucz. Wraz ze wzrostem rozmiaru rozproszonego zestawu danych indeksowanie go i wykonywanie zapytań staje się coraz trudniejsze.
Nie ma sensu używać techniki map-reduce, ponieważ każdy węzeł w zapytaniu musi w nim uczestniczyć. Wraz ze wzrostem ilości danych skalowanie modelu RDBMS staje się coraz mniej wykonalne. W przypadku dużego zestawu danych awaria architektury skalowania może być bardzo dużym punktem awarii. Internet jest przykładem ultraskalowego klastra bez współdzielenia.
Bazy danych Nosql: przyszłość skalowalności
Ponieważ dane są przesyłane między wieloma maszynami w bazach danych Nosql, są one niezwykle skalowalne. Dzięki temu zamiast kupować drogie maszyny wymagające specjalistycznego sprzętu, możemy w prosty sposób dołożyć moc procesora. Ponadto bazy danych Nosql mogą przechowywać dużą ilość danych bez ograniczeń, co czyni go bardzo wszechstronnym systemem zarządzania danymi.
Czy bazę danych Sql można skalować w poziomie
Tak, bazy danych SQL można skalować w poziomie. Oznacza to, że mogą być rozłożone na wielu serwerach, z których każdy obsługuje część wszystkich danych. Pozwala to na większą skalowalność niż mógłby zapewnić pojedynczy serwer.
Dlaczego bazy danych SQL nie są skalowalne w poziomie?
Ze względu na elastyczność składni zapytań niemożliwe jest skalowanie w poziomie w relacyjnej bazie danych . Dzięki SQL możesz dodać do swoich danych dowolną liczbę warunków i filtrów, które uniemożliwiają systemowi bazy danych rozpoznanie, które fragmenty zostaną zwrócone, dopóki zapytanie nie zostanie zakończone.
Dlaczego Sql skaluje się w pionie?
Celem skalowania pionowego jest zwiększenie zużycia energii i pojemności pamięci RAM istniejących systemów, zasadniczo zwiększając dostępne zasoby. Skalowanie w pionie jest nie tylko łatwiejsze, ale także tańsze. Problem również nie wymaga długoterminowej naprawy.