
Pig: Platforma wysokiego poziomu dla Apache Hadoop
Opublikowany: 2023-02-22Pig to wysokopoziomowa platforma do tworzenia programów działających na Apache Hadoop. Termin „Pig” odnosi się do warstwy infrastruktury platformy, na którą składa się środowisko kompilatora i wykonania oraz zestaw operatorów wysokiego poziomu. Warstwa infrastruktury Pig zapewnia zestaw narzędzi dla programistów do tworzenia, utrzymywania i wykonywania ich programów Pig. Pig to projekt typu open source, który jest częścią ekosystemu Apache Hadoop . Model programowania Pig opiera się na przepływie danych, co ułatwia pisanie programów przetwarzających duże ilości danych. Programy świń składają się z serii operatorów, które są wykonywane w skierowanym grafie acyklicznym. Pig to doskonały wybór do przetwarzania dużych ilości danych, ponieważ jest skalowalny, wydajny i łatwy w użyciu.
Jako rozwiązanie NoSQL potrzebujesz konkretnych, predefiniowanych sposobów analizowania i uzyskiwania dostępu do danych. SQL (UNION, INTERSECT itp.) to popularne wyrażenie zapytania, które nie jest często używane w świecie dużych zbiorów danych. Ponieważ Hive jest zoptymalizowany pod kątem przetwarzania wsadowego i dużych zbiorów danych, najlepiej jest dotykać każdego wiersza. Hive wydaje na operacje znacznie mniej czasu i pieniędzy niż Hadoop, co ma tę zaletę, że jest skalowalne. Nawet małe zapytania w systemach deweloperskich mogą być O RZĘDY wielkości wolniejsze niż podobne zapytania w RDBMS. Hive nie buforuje wyników zapytań. Ponowne przesyłanie powtarzającego się zapytania jest powszechną praktyką w MapReduce.
Istnieją dwa typy Hive: 1) Hive nie jest bazą danych; jest to raczej silnik zapytań, który obsługuje części SQL specyficzne dla danych zapytań b) Hive to baza danych z obsługą SQL c) Hive to baza danych specyficzna dla SQL. Hive to oparty na SQL system hurtowni danych dla Hadoop, który obejmuje między innymi Pig i Python; Hive służy do przechowywania danych Hadoop .
Czy świnia jest sql?
Nie ma dobrej ani złej odpowiedzi na to pytanie, ponieważ zależy to od osobistej opinii. Niektórzy ludzie mogą wierzyć, że świnia to sql, podczas gdy inni mogą nie. Ostatecznie to od osoby zależy, czy świnia jest sql.
Dziś Apache Hive i Pig to dwa terminy, które szybko stają się synonimami big data. Dzięki tym narzędziom programiści i analitycy danych mogą zredukować złożoność MapReduce przy jednoczesnym zachowaniu wysokiego poziomu integralności danych. Hive to infrastruktura magazynu danych, znana również jako narzędzie ETL (wyodrębnianie, ładowanie i transformacja). Apache Hive, Pig i SQL to trzy popularne narzędzia do analizy danych i zarządzania nimi. Musisz być świadomy, która platforma będzie najlepsza dla Twoich potrzeb i jak często powinieneś z niej korzystać. Przyjrzyjmy się trzem różnym sposobom używania Hive, Pig i SQL w kontekście tych trzech technologii. SQL nadal króluje w zarządzaniu i analizie dużych zbiorów danych, pomimo dominacji Apache Hive i Apache Pig. Ponieważ każdy pełni określoną funkcję, jego wymagania są dostosowane do biznesu. Apache Pig jest oparty na skryptach i wymaga specjalnej wiedzy, podczas gdy Apache Hive jest jedynym rozwiązaniem bazodanowym natywnym dla programisty.
Świnia to wszechstronne zwierzę o dużej elastyczności. Na przykład Pig może przetwarzać pliki dziennika zawierające dane JSON lub XML, umożliwiając odczyt danych. Możliwe jest również przechowywanie danych z serwisów internetowych w Pig.
Typy danych mapy, krotki i typy danych worka mogą być używane zamiennie. Są w stanie obsłużyć dane z dowolnego źródła.
Czy świnia jest narzędziem Etl?
Nie ma ostatecznej odpowiedzi na to pytanie, ponieważ zależy to od tego, jak zdefiniujesz narzędzie ETL. Mówiąc ogólnie, narzędzie ETL to aplikacja, która pomaga wyodrębnić dane z jednego lub kilku źródeł, przekształcić je w format zgodny z systemem docelowym i załadować je do tego systemu. Niektórzy powiedzieliby, że świnia jest narzędziem ETL, ponieważ może wykonywać wszystkie te funkcje. Inni mogą argumentować, że świnia nie jest narzędziem ETL, ponieważ nie jest specjalnie zaprojektowana do transformacji danych. Ostatecznie odpowiedź na to pytanie zależy od Twojej własnej definicji narzędzia ETL.

Jak można wykorzystać świnię do przetwarzania Etl?
Aplikację Pig można opisać jako model transakcji ETL, który opisuje, w jaki sposób proces wyodrębnia dane z obiektu i przekształca je w magazyn danych w oparciu o zestaw reguł. Użytkownicy definiują funkcje zdefiniowane przez użytkownika (UDF) świni w celu pozyskiwania danych z plików, strumieni i innych źródeł.
Co to jest narzędzie świni?
Platforma lub narzędzie znane jako Pig przetwarza duże zbiory danych. Ta biblioteka zawiera wysoki poziom abstrakcji do przetwarzania danych w procesie MapReduce. Pig Latin to język skryptowy wysokiego poziomu, który jest używany w procesie kodowania do opracowywania kodów analizy danych.
Jaka jest różnica między świnią a sql?
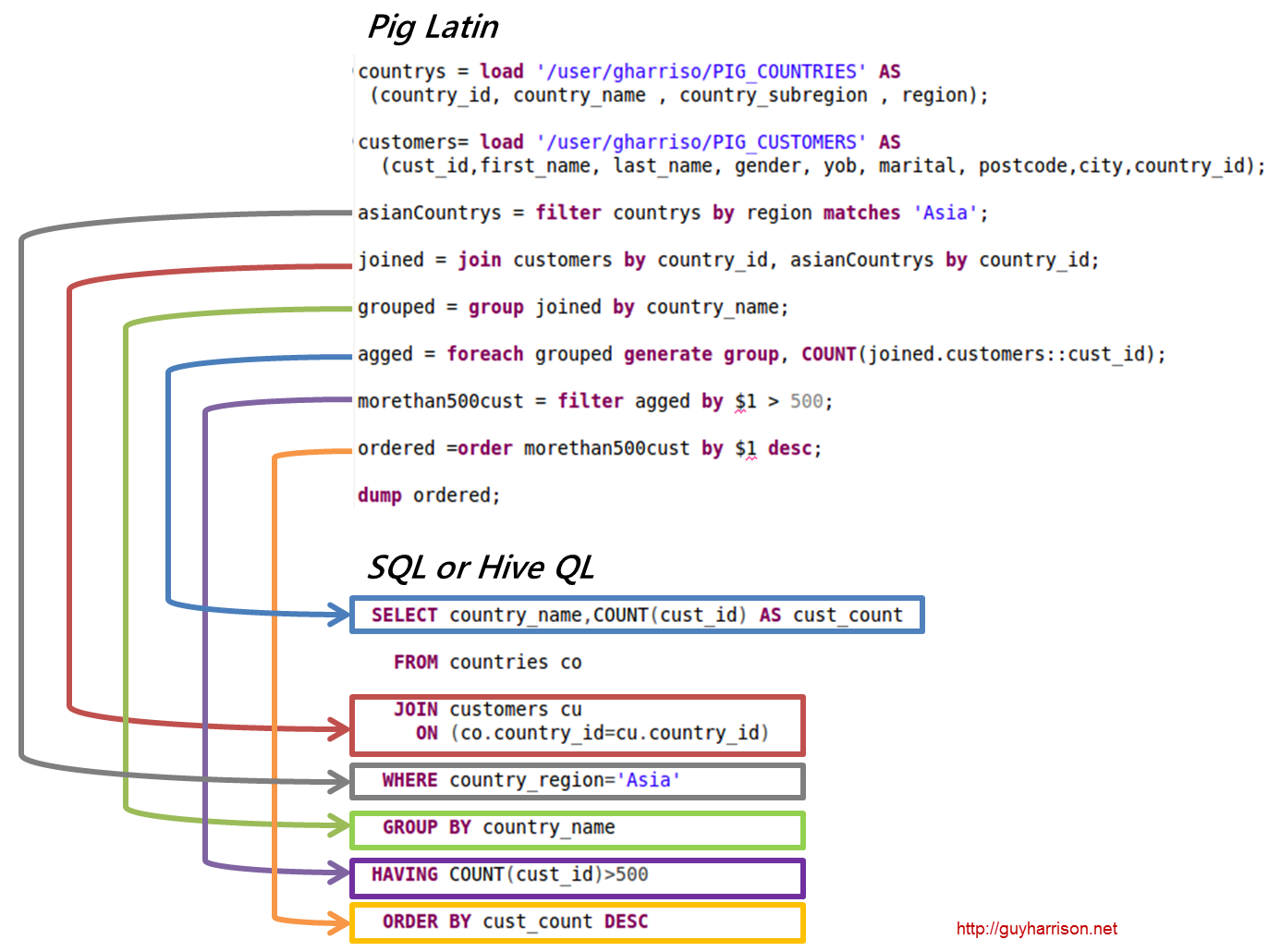
SQL Pig Latin i Apache Pig to języki proceduralne. SQL jest językiem skryptowym o charakterze deklaratywnym. To, czy używany jest schemat, zależy wyłącznie od Apache Pig. Dane mogą być przechowywane bez potrzeby stosowania schematu (typy wartości są przechowywane w $, $ itd.).
Czy świnia jest częścią Hadoop?
Aplikacja Pig Hadoop to język programowania wysokiego poziomu, którego można używać do analizowania ogromnych zbiorów danych. Projekt Pig Hadoop firmy Yahoo! był jednym z pierwszych projektów Hadoop . Ogólnie rzecz biorąc, podczas uruchamiania Hadoop wykonuje znaczną ilość pracy związanej z administrowaniem danymi.
W dziedzinie analizy dużych danych Pig Hadoop jest językiem programowania wysokiego poziomu. Aby analizować dane za pomocą Apache Pig, musimy najpierw napisać skrypty używając Pig Latin. skrypty, które zostaną przekształcone w zadania MapReduce . Osiąga się to dzięki wykorzystaniu Pig Engine, rozszerzenia Apache Pig. Wykonując poniższe czynności, możesz zainstalować Apache Pig w systemie Linux/CentOS/Windows (przez VM lub Cloudera). Pierwszym krokiem jest pobranie i instalacja Apache Pig. Drugim krokiem jest zmiana zmiennych środowiskowych Apache Pig za pomocą pliku bashrc.
W kroku 3 określ wersję świni . Ten plik można zapisać w innym katalogu po przeniesieniu. Piątym krokiem jest uruchomienie Grunt Shell (skrypt używany do uruchamiania Pig Latin) poprzez kliknięcie polecenia Pig.
Dlaczego Pig Latin to najlepszy język skryptowy wysokiego poziomu do analizy danych
Kod analizy danych Pig Latin jest napisany w języku skryptowym wysokiego poziomu. Jest to język podobny do SQL, który ma na celu równoległe przetwarzanie przepływów danych.
Przykład świni Apache
Pig to wysokopoziomowa platforma do tworzenia programów działających na Apache Hadoop. Język tej platformy nazywa się Pig Latin. Pig może wykonywać swoje zadania Hadoop w MapReduce, Tez lub Spark. Pig Latin wyodrębnia programowanie z idiomu Java MapReduce do notacji, która ułatwia programowanie MapReduce. Na przykład poniższa instrukcja Pig Latin jest odpowiednikiem powyższego kodu Java MapReduce: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); ZRZUT A;