
Skalowanie bazy danych NoSQL: porady i wskazówki
Opublikowany: 2022-11-18Bazy danych NoSQL stają się coraz bardziej popularne, ponieważ ilość danych generowanych przez firmy wciąż rośnie wykładniczo. Jednak wiele organizacji niechętnie przechodzi na NoSQL, ponieważ obawiają się, że skalowanie będzie trudniejsze. Skalowanie bazy danych NoSQL w rzeczywistości nie różni się zbytnio od skalowania relacyjnej bazy danych. Główna różnica polega na tym, że bazy danych NoSQL są zaprojektowane tak, aby były skalowalne w poziomie, co oznacza, że można je skalować, dodając więcej węzłów do systemu. Kontrastuje to z relacyjnymi bazami danych , które są skalowalne w pionie, co oznacza, że można je skalować tylko poprzez dodanie większej liczby zasobów do pojedynczego serwera. Podczas skalowania bazy danych NoSQL należy pamiętać o kilku rzeczach: 1. Upewnij się, że dane są równomiernie rozmieszczone we wszystkich węzłach. 2. Dodawaj węzły stopniowo, aby uniknąć przeciążenia systemu. 3. Uważnie monitoruj wydajność systemu, aby zidentyfikować wszelkie wąskie gardła. 4. Regularnie dostrajaj system, aby zapewnić optymalną wydajność. Biorąc pod uwagę te wskazówki, skalowanie bazy danych NoSQL nie powinno być trudniejsze niż skalowanie relacyjnej bazy danych.
Istnieje wiele metod i zasad skalowania bazy danych, w zależności od jej typu. Skalowanie baz danych NoSQL i sql jest zależne od koncepcji dzielenia bazy danych. Korzyści wynikające z możliwości przechowywania większej ilości danych narastają, gdy serwery są dystrybuowane, ale dziedziczymy również problemy związane z dystrybucją. Monolityczna baza danych nie obsługuje automatycznego dzielenia na fragmenty, a inżynierowie musieliby ręcznie pisać logikę, aby sobie z tym poradzić. Aby rozwiązać ten problem, przed usługą zapytań i bazą danych można zainstalować serwer proxy, taki jak moduł równoważenia obciążenia. Możemy uzyskać szybsze zapytania, gdy shard jest duży, ponieważ ten serwer proxy może być ponownie użyty. Ze względu na brak świadomości użytkowników końcowych skalowanie baz danych NoSQL jest w dużej mierze niewidoczne.
Każdy fragment jest unikalny, w przeciwieństwie do architektury master-slave. Jeśli we fragmentu głównym pojawią się zapytania dotyczące odczytu, do fragmentów podrzędnych zostanie wysłane żądanie. Na poziomie centrum danych możemy replikować bazę danych, aby mieć pewność, że mamy kopię zapasową. Węzeł to węzeł, który może komunikować się i wymieniać informacje z innymi węzłami. Każdy węzeł komunikuje się z ustaloną liczbą innych węzłów za pośrednictwem protokołu. Ponieważ wszystkie węzły są równe w Cassandrze, węzeł może replikować swoje dane z jednego do drugiego bez obawy o utratę jakichkolwiek danych. Protokół plotek jest jednym z wielu sposobów, w jaki węzły mogą udostępniać informacje.
Rozproszona baza danych może mieć szereg zalet oprócz uzyskiwania dodatkowych właściwości. Kluczowym elementem zapewnienia dostępności jest replikacja danych. Kiedy używasz replikacji asynchronicznej dla swojej bazy danych, początkowo nie zawsze będzie ona całkowicie spójna, ale z czasem będzie coraz bardziej spójna. Bazy danych SQL są używane w aplikacjach finansowych, które wymagają dużej precyzji danych, podczas gdy bazy danych NoSQL są używane w mniej istotnych aplikacjach, takich jak liczenie wyświetleń.
Skalowanie pionowe odnosi się do procesu stopniowego zwiększania obciążenia obliczeniowego za pomocą modernizacji sprzętu. Przejście na architekturę rozproszoną i dodanie większej liczby komputerów w celu rozwiązania naszego problemu wiąże się ze skalowaniem w poziomie, znanym również jako skalowanie poziome lub skalowanie w poziomie.
NoSQL może obsługiwać skalowanie w oparciu o metody poziome.
MongoDB jako baza danych NoSQL jest skalowalna, ponieważ jej dane nie są przechowywane w relacyjnych bazach danych. Dane są przechowywane jako dokumenty podobne do JSON, które są łatwo dostępne za pośrednictwem żądania HTTP. Za pomocą tej metody można przeprowadzić dystrybucję dokumentów w poziomie w wielu węzłach.
Jak skalujesz bazę danych Nosql?
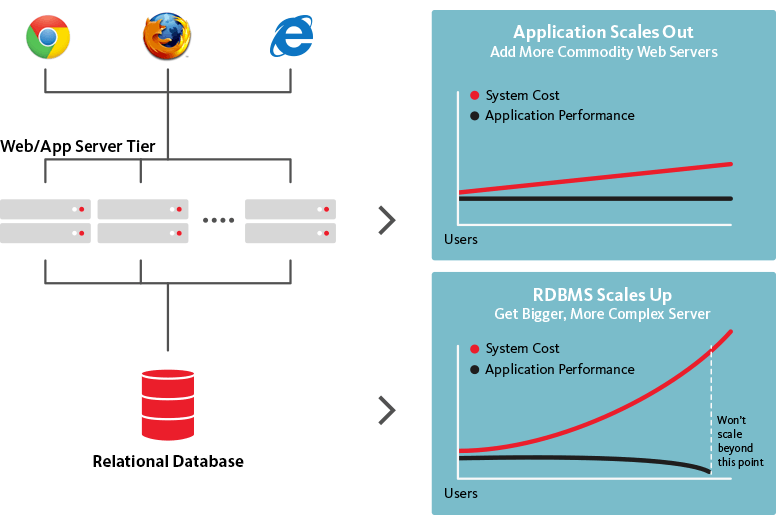
Z drugiej strony bazy danych NoSQL są skalowalne poziomo, co oznacza, że mogą obsłużyć zwiększony ruch w razie potrzeby, po prostu dodając więcej serwerów do bazy danych. Ponieważ bazy danych NoSQL można przekształcić w znacznie większe i potężniejsze struktury, jest to logiczny wybór w przypadku dużych zbiorów danych i stale rozwijających się baz danych.
Aby ten samouczek działał, musisz mieć działające środowisko Node.js. W tym poście rozpakuję pliki DynamoDB do folderu o nazwie nodejs-dynamodb-sample. Aby uzyskać szczegółową wersję tego, przejdź do mojej strony GitHub: https://www.gofundme.com/adamfowleruk/nodesurvey.html. Przykładowa aplikacja może wyszukiwać i pobierać informacje o filmach z DynamoDB. Będziemy przechowywać dane w S3 w Amazon Web Services i uzyskiwać dostęp do DynamoDB za pośrednictwem usługi Amazon Identity and Access Management (IAM). Aby korzystać z usługi Amazon In-App Analytics, musisz najpierw zarejestrować się i utworzyć konto. Zanotuj rok i tytuł każdego filmu, który chcesz POST/filmy.
Możesz wprowadzić pole z kluczem, aby znaleźć filmy z określonego roku. Następnie możesz zaprojektować własną aplikację od podstaw. Możesz używać swoich tabel, dopóki ich nie skończysz, ale powinieneś je usunąć, gdy zostaną użyte. Odwiedź konsolę DynamoDB w Amazon Web Services, aby zobaczyć, ile miejsca wykorzystałeś do tej pory. Zakładka „Filmy” umożliwia przeglądanie pozycji w tabeli i metryk z Twojej aplikacji, a także szacowanego miesięcznego kosztu na karcie Pojemność. Ten kod można znaleźć na mojej stronie GitHub: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
MongoDB, Apache HBase i Cassandra to trzy bazy danych NoSQL, które idealnie nadają się do skalowania w poziomie. Ponieważ ich struktury danych są bardziej poziome, ułatwia to dodawanie kolejnych serwerów do systemu, jednocześnie eliminując konieczność ich zmiany. Co więcej, te bazy danych są stosunkowo nowe, więc wciąż są rozwijane i udoskonalane, co oznacza, że prawdopodobnie z czasem będą udoskonalane.
Dlaczego skalowanie Nosql jest łatwe?
Nosql jest łatwy do skalowania, ponieważ został zaprojektowany tak, aby był skalowalny w poziomie. Oznacza to, że można go skalować, dodając więcej węzłów do klastra nosql . Nosql jest również łatwy do skalowania, ponieważ może obsługiwać duże ilości danych i dużą liczbę zapytań na sekundę.
Aplikacje do prawidłowego działania wymagają wysokiego poziomu skalowalności. Równie ważny jest wybór magazynów danych z prostym i wydajnym interfejsem użytkownika. Głównym punktem spornym jest to, czy użycie bazy danych „ASL” czy „Nosql” jest lepsze. Bazy danych NoSQL, w przeciwieństwie do baz SQL, są popularne, ponieważ są proste w budowie. Zatrzymanie wszystkich operacji w bazie danych NoSQL jest z natury zależne od dzielenia na fragmenty. Ogólnie rzecz biorąc, każda operacja na danych wymaga użycia operatora kwalifikującego, którego można użyć do identyfikacji węzła z danymi. Dane są przechowywane na wielu komputerach, co bardzo ułatwia wykonywanie operacji na danych nawet na najmniejszych komputerach.

W rezultacie sklepy NoSQL można skalować, aby korzystać ze stosunkowo prostej maszyny towarowej. Zakłada się, że użytkownicy zaplanują i ustrukturyzują dane w taki sposób, aby można je było pobrać za jednym razem z tego samego węzła w celu wykonania określonej operacji na bazie NoSQL. Denormalizowanie danych w ten sposób może również sugerować, że węzeł jest gotowy do uruchamiania wstępnie przygotowanych danych. Złączenia w NoSQL są możliwe, ale nie są tak solidne jak złączenia SQL. W praktycznym świecie NoSQL projektanci aplikacji wierzą, że w końcu nastąpi spójność danych. Oprócz udostępniania przełączników do dostosowywania spójności w różnych systemach NoSQL, wiele systemów NoSQL zapewnia procedury, dzięki którym spójność wydaje się bardziej widoczna. Ważną częścią każdej decyzji dotyczącej architektury jest ocena przypadku użycia i wybór odpowiedniego magazynu danych na podstawie tego przypadku.
Czy wszystkie bazy danych Nosql są skalowalne?
W wyniku ery Internetu i przetwarzania w chmurze, bazy danych NoSQL zostały stworzone, aby ułatwić wdrażanie architektury skalowalnej w poziomie. skalowalność jest osiągana poprzez połączenie przechowywania danych z pracą wymaganą do ich przetwarzania na dużej liczbie komputerów w architekturze skalowalnej w poziomie.
System powinien być w stanie obsłużyć bardzo duże bazy danych przy bardzo małych opóźnieniach, a jednocześnie obsługiwać bardzo wysokie stawki żądań. Jeśli chodzi o strony internetowe o dużej objętości, takie jak eBay, Amazon, Twitter i Facebook, kluczowe znaczenie mają skalowalność i wysoka dostępność . Możesz uruchomić wiele instancji serwera jednocześnie ze skalowaniem poziomym.
Baza danych MongoDB jest skalowalna zarówno w poziomie, jak iw pionie, zarówno pod względem skali, jak i liczby użytkowników. W MongoDB możesz skalować swój klaster w pionie lub poziomie, dodając więcej zasobów i dzieląc dane na mniejsze części. W rezultacie MongoDB jest popularnym wyborem dla aplikacji i magazynów danych na dużą skalę .
Najlepsze bazy danych Nosql do szybkiego skalowania i dużej ilości danych
Inne bazy danych NoSQL można skalować w celu spełnienia określonych potrzeb, tak jak w przypadku innych baz danych. Na przykład MongoDB jest popularnym językiem programowania, ponieważ można go szybko skalować i obsługiwać wiele danych. Magazyny danych oparte na Redis są szeroko stosowane ze względu na ich możliwości i szybkość w pamięci.
Skalowanie pionowe Nosql
Bazy danych Nosql są skalowalne w poziomie, co oznacza, że mogą obsłużyć zwiększony ruch poprzez dodanie większej liczby węzłów do systemu. Kontrastuje to ze skalowaniem pionowym, w którym system jest skalowany poprzez dodawanie większej liczby zasobów do pojedynczego węzła.
Każda baza danych musi być skalowana, aby obsłużyć wolumen danych generowanych każdego dnia. Termin „skalowanie” dzieli się na dwa rodzaje: pionowe i poziome. Jeśli chcesz przechowywać więcej danych, powinieneś zainwestować w serwer o pojemności 2 TB. Pojedynczy serwer staje się coraz droższy i większy. Proces dodawania maszyn do serwera skutkuje skalowaniem poziomym. W takim przypadku dane są dzielone na zestaw i dystrybuowane na wielu serwerach lub fragmentach. Ponieważ jest zgodny z modelem denormalizacji, nie ma potrzeby stosowania jednego punktu prawdy. Takie podejście może nie skutkować aktualizacją informacji, gdy urządzenie nadrzędne nie wykona zapisu, ponieważ nie aktualizuje informacji w replikach podrzędnych, gdy urządzenie nadrzędne nie wykona zapisu.
Co to jest skalowanie pionowe w Sql?
Celem podejścia do skalowania pionowego jest zwiększenie wydajności pojedynczej maszyny poprzez zwiększenie zasobów tego samego serwera logicznego. Istniejące oprogramowanie musi zostać zaktualizowane o zasoby, takie jak pamięć, pamięć masowa i moc obliczeniowa, aby działać jak najlepiej.
Jak skalować bazę danych w poziomie
Co to jest skalowanie poziome i jak działa? Metoda skalowania poziomego to taka, która wymaga dodania dodatkowych węzłów w celu uwzględnienia obciążenia. Jest to niezwykle trudne w przypadku relacyjnych baz danych ze względu na trudność w dystrybucji powiązanych danych między węzłami.
Oprócz dodawania kolejnych wystąpień w celu współdzielenia obciążenia, skalowanie w poziomie (lub skalowanie w poziomie) pociąga za sobą zwiększenie liczby wystąpień aplikacji lub usługi. Natomiast skalowanie w pionie wymaga dodania do instancji większej ilości zasobów, takich jak moc procesora i pamięć. Ze względu na bazowe protokoły HTTP, większość aplikacji internetowych i interfejsy API można je łatwo skalować niezależnie od siebie. Niektóre bazy danych umożliwiają teraz synchronizację i udostępnianie zapisanych danych między wieloma instancjami. Jeśli ruch jest kierowany w ten sposób, więcej zasobów jest przeznaczanych na najczęściej żądane elementy. Chociaż odwrotne serwery proxy są powszechnie używane do obsługi żądań HTTP, bazy danych nie zawsze są do tego używane. Większość baz danych można przekazywać za pomocą oprogramowania takiego jak nginx lub HAproxy, z których oba można wykonać na poziomie TCP.
Jeśli twój serwer proxy może zrozumieć, jak działają połączenia na poziomie protokołu, może określić, czy odczytana replika nie jest zsynchronizowana lub nie może zareagować, nawet jeśli połączenie sieciowe jest aktywne. Trasę można dostosować w zależności od obciążenia repliki oraz ilości połączeń. Istnieje kilka serwerów proxy, które mogą pełnić różne funkcje. Poczyniono pewne postępy w zakresie trwałych woluminów i oświadczeń, ale istnieją również nieodłączne trudności, jeśli nie wybierzesz bazy danych, która ceni każdą instancję jednakowo. Ponieważ kontenery są przenoszone w klastrze, ponowne uruchomienie jednej z replik do odczytu powinno wystarczyć. Jeśli tak się stanie z główną bazą danych , raczej nie będziesz zachwycony.