
Solr – potężna platforma wyszukiwania
Opublikowany: 2022-11-18Solr to potężna platforma wyszukiwania, która umożliwia bardzo szybkie przeszukiwanie dużych ilości danych. Jest zbudowany na bazie biblioteki wyszukiwania Apache Lucene i zapewnia interfejs API podobny do REST, ułatwiający integrację z aplikacją. Jedną z kluczowych cech Solr jest jego skalowalność – z łatwością radzi sobie z miliardami dokumentów i zapytań. Solr jest często opisywany jako baza danych NoSQL, ponieważ nie korzysta z tradycyjnego modelu relacyjnej bazy danych. Należy jednak zauważyć, że Solr nie jest tradycyjną bazą danych i nie powinien być używany jako baza danych. Jest przeznaczony do indeksowania i wyszukiwania, a nie do przechowywania danych. Jeśli potrzebujesz przechowywać dane, powinieneś użyć bazy danych NoSQL, takiej jak MongoDB lub Cassandra.
Dzięki Elasticsearch jako jedynemu projektowi open source, który może konkurować z Solr, Solr jest jedną z dwóch najpopularniejszych wyszukiwarek open source na świecie. NoSQL oznacza Not Only SQL, co oznacza, że używa języków zapytań innych niż tradycyjny SQL i nie tylko bazy danych. Pomimo doskonałej funkcji wyszukiwania pełnotekstowego, Solr może być niezwykle przydatny w bazie danych NoSQL. Dane dotyczące kondycji zostały wyodrębnione bezpośrednio z HBase za pośrednictwem starszych aplikacji Explorys i Worklist. Solr dał Worklist trzy podstawowe funkcje: był niezwykle łatwy w użyciu, a funkcje były bardzo intuicyjne. Proces filtrowania i sortowania jest bardzo wydajny. Ponieważ filtrowanie Solr opiera się na identyfikatorach dokumentów i buforowaniu, może niemal natychmiast obliczyć liczbę dokumentów spełniających kryteria filtrowania.
Solr to doskonałe rozwiązanie bazodanowe NoSQL, często łączone z innymi usługami big data. Natychmiast przekazaliśmy informacje zwrotne naszym użytkownikom, którzy pracowali nad dodawaniem i konfiguracją filtrów, wysyłając parametrrows=0 do Solr. Bardzo ważne jest, aby rozważyć coś więcej niż tylko utrzymanie schematu Solr , aby stworzyć wyszukiwarkę, która jest dobra pod względem trafności.
Czy możesz używać Solr jako bazy danych?
Tak, możesz używać Solr jako bazy danych. Jest to potężna wyszukiwarka, której można używać do indeksowania i wyszukiwania danych. Może być używany do przechowywania danych w ustrukturyzowanym formacie i szybkiego ich odzyskiwania.
Czy używanie indeksu wyszukiwania jako bazy danych jest złe? W moim przypadku miałem podobny pomysł na przechowywanie kilku podstawowych elementów danych w Solr. Proces aktualizacji Solr zmienił jednak moje zdanie i muszę przyznać, że się co do tego myliłem. Jeśli zaktualizowałeś 2 główne wersje, ale nie dokonałeś ponownego indeksowania (na przykład usunięto oryginalne dokumenty, a następnie same pliki indeksu), rdzeń nie jest już rozpoznawany.
Algolia, Elastic Observability, Coveo i Yext to tylko niektóre z popularnych alternatyw dla Apache Solr. Algolia to wyszukiwarka w języku naturalnym, która analizuje i przetwarza zapytania wyszukiwania na podstawie tego, co wiemy o osobie lub temacie w języku naturalnym. Elastic Observability to platforma danych, która zapewnia wgląd w dane i aplikacje w czasie rzeczywistym. Coveo, platforma marketingu w wyszukiwarkach, umożliwia ukierunkowanie i pomiar działań marketingowych w wyszukiwarkach. Korzystając z Yext, możesz kierować i mierzyć kampanie marketingowe w wyszukiwarkach.
Czym są bazy danych Nosql?
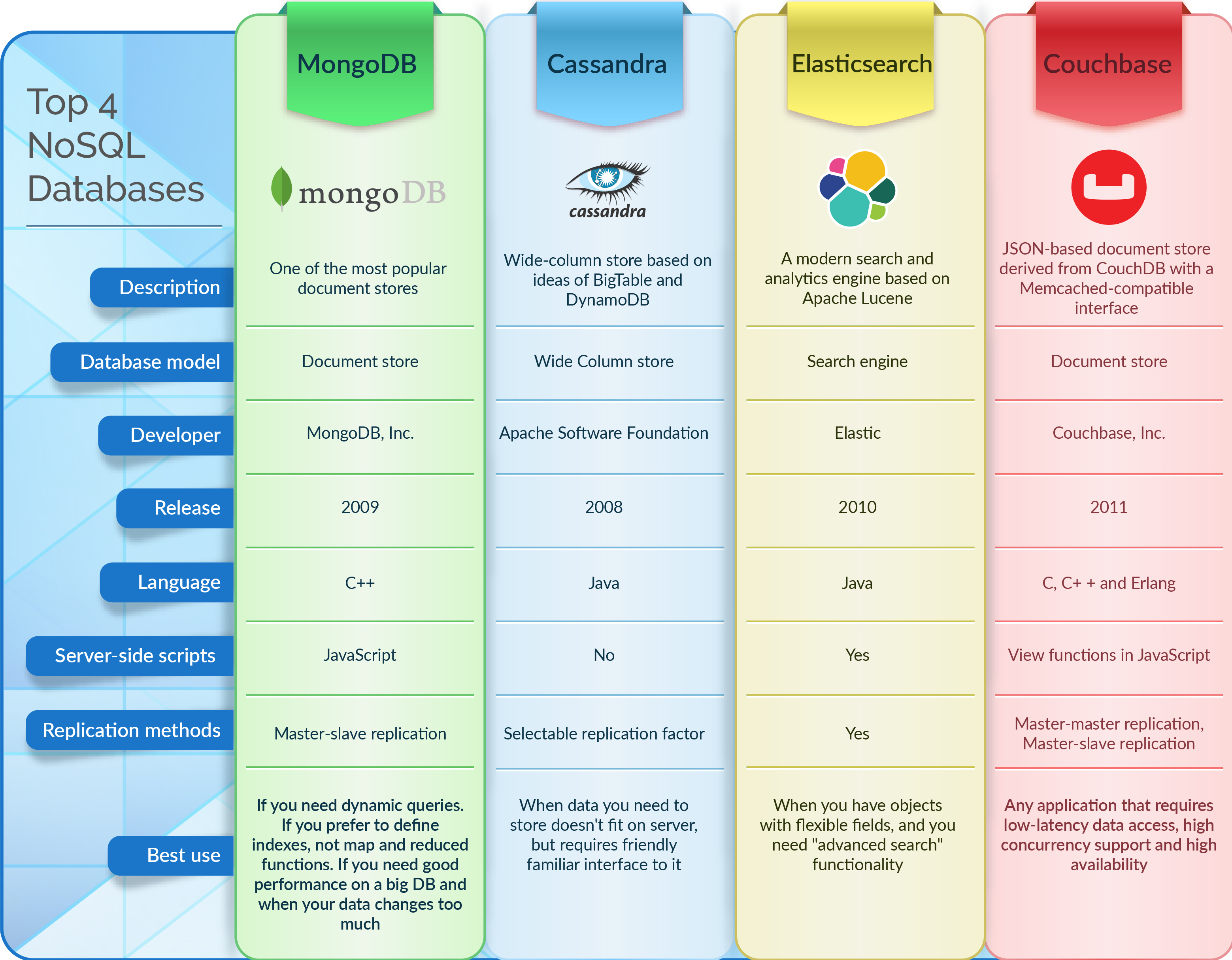
Bazy danych Nosql to bazy danych, które nie wykorzystują tradycyjnego modelu relacyjnej bazy danych. Zamiast tego używają różnych modeli, w tym baz danych klucz-wartość, dokumentów, kolumn i wykresów.
Oparte na dokumentach bazy danych NoSQL przechowują dane w taki sam sposób, jak robią to relacyjne bazy danych. Oprogramowanie do zarządzania danymi jest zbudowane tak, aby było elastyczne, skalowalne i zdolne do szybkiego reagowania na potrzeby nowoczesnych firm. Bazy danych dokumentów , magazyny klucz-wartość, bazy danych z szerokimi kolumnami i bazy danych wykresów to tylko niektóre typy baz danych NoSQL. Większość z 2000 największych przedsiębiorstw na świecie szybko wdraża bazy danych NoSQL do obsługi aplikacji o znaczeniu krytycznym. W tym kontekście pięć trendów stwarza wyzwania techniczne, które są zbyt trudne do rozwiązania dla większości relacyjnych baz danych. Ze względu na stały model danych relacyjne bazy danych są główną przeszkodą w zwinnym rozwoju. Model aplikacji definiuje model danych NoSQL.
Dane muszą być modelowane w modelu NoSQL niezależnie od ich struktury. Format JSON jest domyślnym formatem przechowywania danych w bazie danych zorientowanej na dokumenty. Ramy ORM można w ten sposób zmniejszać, zmniejszając ogólne koszty tworzenia aplikacji. N1QL (wymawiane nikiel) to język zapytań SQL-to-JSON, który został wydany jako część Couchbase Server 4.0. Narzędzie obsługuje również agregację (GROUP BY), sortowanie (SORT BY), łączenie (LEWY ZEWNĘTRZNY / WEWNĘTRZNY) i wiele innych funkcji. Rozproszona baza danych NoSQL ze skalowalną architekturą, bez pojedynczego punktu awarii i przekonującymi zaletami operacyjnymi to jedna z najbardziej atrakcyjnych funkcji. Ponieważ coraz więcej interakcji z klientami odbywa się online za pośrednictwem aplikacji internetowych i mobilnych, problemem jest dostępność.
Bazy danych NoSQL są łatwe do nauczenia się i używania. Są przeznaczone do przechowywania informacji, pisania i czytania książek. Są również w stanie zarządzać i monitorować klastry o różnej wielkości w dowolnej wielkości. Wbudowana replikacja zawarta w rozproszonej bazie danych NoSQL jest zapewniana przez samą bazę danych – nie jest wymagane żadne dodatkowe oprogramowanie. Ponadto routery sprzętowe zapewniają natychmiastowy i spójny dostęp do krytycznych danych. Podczas gdy administratorzy baz danych badają problem, aplikacje nie muszą czekać, aż baza danych wykryje problem, zanim przeprowadzą własne odzyskiwanie. Technologia NoSQL zyskuje na popularności jako platforma dla dzisiejszych aplikacji internetowych, mobilnych i IoT.
Istnieje wiele powodów, dla których bazy danych NoSQL stają się coraz bardziej popularne. Można je skalować w celu zaspokojenia potrzeb dużych organizacji i można je dostosowywać. Jako przykład rozważmy Ryanair i Marriott jako klientów MongoDB. Organizacje te, oprócz używania MongoDB do zasilania swoich aplikacji mobilnych i systemów rezerwacji, używają go również do zasilania swoich stron internetowych. Firmowy system zarządzania treścią Presto jest również zbudowany z NoSQL. System pomaga w sprawnym zarządzaniu treścią własną firmy.
Przyszłość pracy Przyszłość pracy jest odległa
Która nie jest bazą danych Nosql?
Jaka jest różnica między bazami danych NoSQL i innymi niż NoSQL? Podstawowym produktem firmy jest Microsoft SQL Server, system zarządzania relacyjnymi bazami danych.
Pod koniec 2000 roku bazy danych NoSQL skupiły się na skalowaniu, szybkich wynikach zapytań i ułatwianiu programowania. Bazy danych NoSQL są łatwe do utworzenia, ponieważ mają elastyczny model danych, skalowalny model danych i interfejs użytkownika, który jest prosty w użyciu. Relacyjne bazy danych SQL (Structured Query Language) są zwykle zbudowane ze sztywnych, złożonych i tabelarycznych schematów, a także ze zbyt dużego skalowania pionowego. Wersja 4.0 MongoDB zawierała obsługę wielodokumentowych transakcji ACID, a wersja 4.2 dodała obsługę klastrów podzielonych na fragmenty. Brak modeli danych na liście. W większości baz danych NoSQL zapytania są optymalizowane, a nie duplikowane. Ponadto niektóre nr.
Bazy danych NoSQL obsługują kompresję w celu zmniejszenia rozmiaru pamięci masowej. Na przykład bazy danych wykresów mogą być przydatne do analizowania relacji, ale mogą nie być najwygodniejsze do codziennego pobierania danych. Korzystanie z MongoDB lub innej bazy danych w twoim przypadku użycia zostanie zademonstrowane w białej księdze Gdzie używać MongoDB. Korzystanie z MongoDB Atlas jako punktu wyjścia jest jednym z najprostszych sposobów nauki baz danych NoSQL. Uniwersytet MongoDB oferuje całkowicie bezpłatne szkolenie online, które pomoże Ci w nauce MongoDB.
Istnieją jednak pewne wady baz danych NoSQL. Bazy danych NoSQL, oprócz tego, że są wolne od ACID, nie mają takich samych właściwości jak relacyjne bazy danych. Transakcje w Twojej aplikacji mogą powodować problemy, jeśli Twój system na nich polega. Ponadto bazy danych NoSQL zwykle nie zapewniają takiego samego poziomu elastyczności w czasie wykonywania, jak bazy danych SQL. Należy unikać korzystania z baz danych NoSQL, jeśli aplikacja musi dynamicznie zmieniać swoje modele danych.
Która z poniższych nie jest bazą danych?
Ponieważ wszystkie zapytania, raporty i tabele są powiązane z bazami danych, relacje nie są obiektami bazy danych; są związane z matematyką.
Czy Mongodb jest bazą danych Nosql?
Program do zarządzania bazą danych MongoDB NoSQL jest open source i jest darmowy. Język NoSQL jest alternatywą dla tradycyjnych relacyjnych baz danych. Bazy danych NoSQL doskonale nadają się do dystrybucji danych na dużą skalę. Informacje zorientowane na dokumenty mogą być zarządzane, przechowywane lub pobierane za pomocą MongoDB, które jest narzędziem do zarządzania dokumentami.
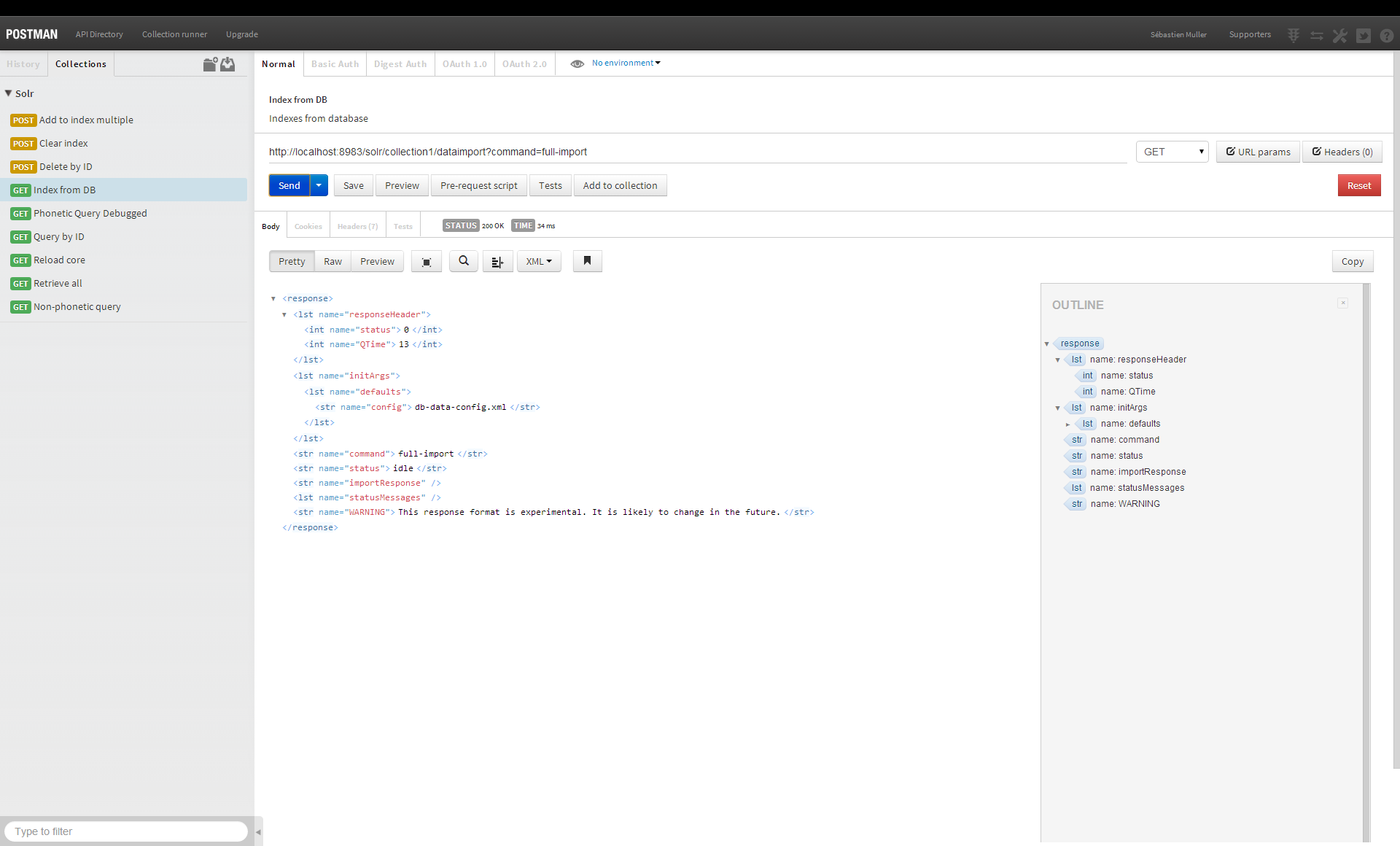
Jak Solr przechowuje dane
Apache Solr indeksuje dane w lokalnym systemie plików, jak sama nazwa wskazuje. Dzięki HDFS (Hadoop Distributed File System) użytkownicy mogą cieszyć się wieloma korzyściami, w tym wielkoskalową i rozproszoną pamięcią masową z funkcjami redundancji i przełączania awaryjnego. Apache Solr zawiera wsparcie dla HDFS.
W przeciwieństwie do wielu innych wyszukiwarek, Solr może generować natychmiastowe wyniki, ponieważ przeszukuje indeks, a nie bezpośrednio tekst. Skanując indeks z tyłu książki, można go użyć do wyszukania stron powiązanych ze słowem kluczowym. Ten indeks jest przechowywany w katalogu danych jako indeks w katalogu zwanym katalogiem danych. Wyszukiwarka Solr jest obsługiwana przez Lucene, pełnotekstową wyszukiwarkę typu open source. Relacja między Solr i Lucene jest podobna do relacji między samochodem a jego silnikiem. Szczegółowo omówimy różnice między Lucene i Solr w tym artykule.

Jak korzystać z zapisanych pól w Sol
Format pola dokumentu jest używany w Solr. Dokument może zawierać jakąś formę pola, które jest po prostu zbiorem danych. Gdy szukasz dokumentu za pomocą Solr, wyniki będą zawierać dopasowania dla wszystkich pól w dokumencie, który jest indeksowany.
Zapisane pole to pole, którego nie trzeba przeszukiwać, ale które nadal musi być wyświetlane podczas wyszukiwania. W Solr są to pola składowane. Solr indeksuje wszystkie przechowywane pola w wyniku algorytmu indeksowania, więc gdy szukasz dokumentu, Solr zwraca wyniki, które obejmują wszystkie przechowywane pola.
Przechowywanie pól ma wiele zalet. Jeśli chcesz wyświetlić tytuł dokumentu na liście wyników, może być konieczne zapisanie tytułu jako pliku. Jeśli chcesz mieć możliwość znalezienia wszystkich dokumentów, które kiedykolwiek przeszukiwałeś, używając tego samego identyfikatora, możesz śledzić identyfikator dokumentu za pomocą wielu wyszukiwań.
Wyniki wyszukiwania można również wyświetlać, przechowując pola. Tytuł dokumentu może pojawić się na liście wyników, jeśli jest opatrzony etykietą. Możesz także chcieć wyświetlić identyfikator dokumentu, aby można go było łatwo znaleźć, przeszukując wiele witryn dla dokumentu.
Możliwości Solr obejmują możliwość indeksowania danych, jak również ich przechowywania. Aby zindeksować dokument, Solr musi najpierw stworzyć bazę danych wszystkich pól w nim zawartych, a następnie zostaną zapisane informacje o pozycji każdego pola. Możesz wyszukiwać i wyświetlać wyniki z tego typu informacji.
Oprócz potężnych możliwości wyszukiwania, Solr umożliwia korzystanie z potężnych aplikacji do wyszukiwania dokumentów. Dane udostępniane użytkownikom na podstawie ich zapytań są oparte na ich zapytaniach.
Samouczek bazy danych Solr
Baza danych solr to rodzaj bazy danych, która wykorzystuje oprogramowanie solr do indeksowania i wyszukiwania danych. Jest to potężne narzędzie, za pomocą którego można bardzo szybko indeksować i przeszukiwać duże ilości danych.
Ponieważ ten samouczek został zweryfikowany z Solr 8, może działać również ze starszymi wersjami. Pole id jest już predefiniowane w każdym Lucene i Solr, więc trzeba zrozumieć, jakie typy pól może poprawnie indeksować. Pola dynamiczne można tworzyć w locie, bez konieczności wstępnego definiowania, co pozwala na ich zmianę w dowolnym momencie. Biblioteka Lucene , której Solr używa do wyszukiwania pełnotekstowego, wykorzystuje migawki z określonego punktu w czasie, które muszą być regularnie odświeżane, aby zapytania były przedstawiane nowym szczegółom. Solr, w przeciwieństwie do niezależnego formatu danych JSON lub XML, jest niezależny od formatu danych.
Jak korzystać z wyszukiwarki Solr w Javie
Klient Java jest wymagany do połączenia z serwerem Solr, więc użyj pliku org.apache.solr.client.solrjimpl. Klasa korzystająca z protokołu HttpSolrServer nosi nazwę HttpSolrServer. Ta klasa wykorzystuje Java Socket do komunikacji z serwerem Solr. Podczas tworzenia aplikacji serwerowej Solr należy najpierw załadować odpowiednie klasy. Na przykład w Javie dostęp do funkcji wyszukiwania Solr można uzyskać za pomocą pliku org.apache.solr.client.solrj.impl. Klasa org.apache.solr.client.solrj.request jest komponentem klasy SolrServer. Ta klasa tworzy klasę RequestHandler. Ta potężna wyszukiwarka pozwala łatwo znaleźć potrzebne informacje. Aby uzyskać dostęp do serwera Solr, użyj klienta Java.
Solr kontra Lucene
Jeśli chodzi o projekty Apache Solr i Lucene, składają się one z tych samych komponentów. Z drugiej strony Apache Solr to samodzielny serwer, choć z wieloma zaawansowanymi funkcjami. Z drugiej strony Apache Lucene to rozwiązanie oparte na bibliotece Java, które indeksuje (przechowuje) i przeszukuje dane.
Ze względu na swoją pamięć podręczną Solr ma przewagę w polu danych statycznych, co może ułatwić pobieranie wyników. Dane szeregów czasowych są często przetwarzane przez Elasticsearch, który oprócz danych szeregów czasowych wykorzystuje swoje filtry i możliwości grupowania.
Solr kontra Elasticsearch
Nie ma jednoznacznej odpowiedzi na to pytanie, ponieważ zależy to od indywidualnych potrzeb i preferencji. Jednak niektóre kluczowe różnice między Solr i Elasticsearch obejmują:
-Solr opiera się na tradycyjnym modelu relacyjnej bazy danych, podczas gdy Elasticsearch wykorzystuje podejście zorientowane na dokumenty.
-Solr jest zwykle szybszy do indeksowania i wyszukiwania dużych zbiorów danych, podczas gdy Elasticsearch jest ogólnie bardziej skalowalny.
-Solr obsługuje bardziej zaawansowane funkcje zapytań, takie jak łączenia i obiekty zagnieżdżone, podczas gdy Elasticsearch ma prostszą składnię zapytań.
Istnieje duża społeczność współtwórców obu technologii i dostępna jest pomoc ekspertów. Elasticsearch był wcześniej znany jako Apache 2.0 i był open source. Od 2021 r., wraz z wydaniem wersji 7.11, Elasticsearch będzie dostępny bezpłatnie w ramach licencji publicznej po stronie serwera. Jest przeznaczony do wyszukiwania tekstu na poziomie przedsiębiorstwa, które wymaga wyszukiwania informacji i/lub analizy. Wyszukiwanie pełnotekstowe jest również możliwe w Elasticsearch i można czytać bogate dokumenty, takie jak PDF i Word. Elasticsearch wymaga więcej pamięci sterty niż Solr (1 GB vs 512 MB), ale te ustawienia domyślne można zmienić. Platforma Elasticsearch umożliwia większą automatyzację, łącząc ponowne równoważenie klastrów z czyszczeniem danych, co zwykle nie wymaga użycia rąk.
Sharding to metoda dystrybucji danych na wielu serwerach obsługiwana przez Solr i Elastic. Zarówno Solr, jak i ElasticSearch to popularne bazy danych wyszukiwarek z dużymi, zaangażowanymi społecznościami i podobnymi możliwościami. Elasticsearch jest bardziej przyjazny dla użytkownika niż Solr, łatwiejszy do skalowania i ma lepsze możliwości analityczne i zapytania. Biblioteka Apache Tika, z której mogą korzystać obie bazy danych, pozwala na przeszukiwanie całego tekstu i czytanie bogatych dokumentów.
Wykorzystanie Apache Solr
Ponieważ może indeksować i przeszukiwać dokumenty i załączniki wiadomości e-mail, a także indeksować i przeszukiwać wiele witryn internetowych, jest popularnym narzędziem do wyszukiwania witryn internetowych i przedsiębiorstw.
Jest to platforma wyszukiwania typu open source, która służy do tworzenia aplikacji do wyszukiwania. Bazuje na popularnej wyszukiwarce pełnotekstowej Lucene . Solr to natywna dla chmury, wysoce elastyczna platforma, która jest gotowa do operacji korporacyjnych. Równoległe zapytania zostały włączone w najnowszej wersji Solr, Solr 6.0, która została wydana w 2016 roku. Platforma Solr umożliwia nam skalowanie, dystrybucję i zarządzanie indeksami dla aplikacji o dużej skali (Big Data). Pracując z Solr, nie musisz być programistą ze znajomością języka Java. Zamiast Lucene zapewnia bardzo prostą i łatwą w użyciu usługę tworzenia pola wyszukiwania, które zawiera autouzupełnianie.
Wiele zalet Apache Sol
Wyszukiwarka Apache Solr jest popularną wyszukiwarką zarówno wśród małych, jak i dużych organizacji. To oprogramowanie jest bardzo wszechstronne, dzięki czemu może być używane w różnych sytuacjach, w tym do analizy i wyszukiwania danych. Solr to usługa oferująca możliwości wyszukiwania korporacyjnego, co czyni ją idealnym wyborem do zarządzania dużymi ilościami danych.
Przydatne rozwiązanie bazy danych Nosql
Obecnie dostępnych jest wiele przydatnych rozwiązań baz danych NoSQL . Bazy danych NoSQL są często bardziej skalowalne i wydajniejsze niż tradycyjne relacyjne bazy danych. Są też zwykle bardziej elastyczne, co pozwala na łatwiejsze modelowanie danych i ewolucję schematów. Niektóre popularne bazy danych NoSQL to MongoDB, Cassandra i HBase.
Bazy danych NoSQL nie będą już używane przez programistów w przyszłości. Przyszłość jest tutaj, gdzie te bazy danych będą powszechnym narzędziem do zasilania popularnych aplikacji. Możesz nie wiedzieć, że niektóre popularne aplikacje działają na bazach danych NoSQL i dlaczego NoSQL jest idealny do tych aplikacji. W 1996 roku Forbes jako pierwsza publikacja biznesowa uruchomiła stronę internetową. Forbes przenosi swoją usługę do MongoDB Atlas, aby zaspokoić potrzeby 140 milionów użytkowników online. Ze względu na wpływ pandemii COVID-19 publikacja przeniosła się do infrastruktury chmurowej i poradziła sobie z trudnymi czasami. BangDB został wybrany przez Accenture jako baza danych NoSQL dla aplikacji do oceniania leadów.
Facebook Messenger działa na bazie danych Cassandra NoSQL bez pojedynczego punktu awarii, co pozwala na skalowanie operacji na wielu platformach. Bigtable to składnik Gmaila, który wspomaga Google Bigtable, firmę internetową obsługującą różne transakcje Gmaila. Baza danych Espresso zapewnia normalne działanie wszystkich aplikacji LinkedIn. Pobierz bezpłatnie BangDB, aby sprawdzić, czy jest to odpowiednie narzędzie dla Ciebie.
Korzyści z baz danych Nosql
Wiele baz danych NoSQL może służyć do przechowywania i modelowania danych ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych w jednej bazie danych, co czyni je idealnymi do przechowywania i modelowania struktur danych i semantyki. Mogą działać lepiej i być bardziej stabilne niż tradycyjne relacyjne bazy danych, a także mogą być łatwiejsze do wdrożenia dla programistów. Wraz z rosnącą popularnością baz danych NoSQL, ich popularność prawdopodobnie będzie nadal rosła.
Mongodb »
MongoDB to potężny system baz danych zorientowany na dokumenty. Posiada funkcję wyszukiwania opartą na indeksie, która sprawia, że wyszukiwanie danych jest szybkie i łatwe. MongoDB oferuje również funkcję skalowalności, umożliwiającą obsługę danych na dużą skalę.