
Stabilna dyfuzja: samouczki, zasoby i narzędzia
Opublikowany: 2022-09-08- Zasoby i informacje
- Jakie obrazy zostały użyte do trenowania modelu stabilnej dyfuzji?
- Gdzie znaleźć przykłady i podpowiedzi dotyczące stabilnej dyfuzji?
- Czy istnieje oficjalny serwer Discord?
- Narzędzia i oprogramowanie
- Jak uruchomić stabilną dyfuzję w systemie Windows/Linux?
- Jak uruchomić stabilną dyfuzję na komputerze Mac?
- Jak duży jest model stabilnej dyfuzji?
- Poradniki i poradniki
- Konstruktor monitów o stabilną dyfuzję
- Najlepszy przewodnik dla początkujących
- Kroniki Akaszy
- Szybka ściągawka
- Style i środki artystyczne
- Style wizualne i artystyczne
22 sierpnia założyciel Stability.ai Emad Mostaque ogłosił wydanie Stable Diffusion. Ten model sztuki generatywnej AI ma lepsze możliwości niż DALL·E 2 i jest również dostępny jako projekt open source. W ciągu tych tygodni od premiery ludzie porzucili swoje wysiłki i projekty, aby poświęcić Stable Diffusion całą uwagę.
Byłem już bardzo podekscytowany, gdy OpenAI ogłosił DALL·E 2, a także miałem szczęście uzyskać wczesny dostęp. Ale po zabawie ze stabilną dyfuzją przez ostatnie kilka dni mogę powiedzieć, że DALL·E 2 nie zbliża się do tego, co wnosi na stół stabilna dyfuzja.
A fakt, że jest to oprogramowanie typu open source, sprawia, że jest znacznie bardziej dostępny. W ciągu zaledwie dwóch tygodni strony takie jak Lexica zarchiwizowały ponad 10 milionów obrazów generowanych przez sztuczną inteligencję. Spodziewam się również, że programiści będą czynić postępy w integracji Stable Diffusion z najpopularniejszymi narzędziami do projektowania graficznego, takimi jak Figma, Sketch i inne. Możliwość generowania wysokiej jakości sztuki w ruchu jest bezprecedensowa.

Celem tego artykułu jest wymienienie wszystkich interesujących i odpowiednich samouczków, zasobów i narzędzi, które pomogą Ci szybko zaznajomić się ze stabilnym rozpraszaniem. Wierzę, że w nadchodzących miesiącach zobaczymy masowy napływ projektów, które specjalizują się w wydobywaniu jak największego potencjału ze stabilnej dyfuzji. Zrobię co w mojej mocy, aby ten artykuł był odpowiednio aktualizowany.
- Samouczki – ta sekcja skupia się głównie na tematach takich jak „Jak korzystać ze stabilnej dyfuzji?” .
- Zasoby — ta sekcja koncentruje się na zapytaniach, takich jak „Co to jest stabilna dyfuzja?”.
- Narzędzia – ta sekcja opiera się na narzędziach, które umożliwiają korzystanie ze stabilnej dyfuzji.
Więc bez zbędnych ceregieli – zacznijmy od podstaw.
Zasoby i informacje
Jednym z pierwszych pytań, jakie wiele osób ma na temat stabilnej dyfuzji, jest licencja, na której publikowany jest ten model, oraz to, czy wygenerowaną sztukę można swobodnie wykorzystywać w projektach osobistych i komercyjnych.
Licencja, której używa Stable Diffusion, to CreativeML Open RAIL-M i można ją przeczytać w całości w Hugging Face. Krótko mówiąc, „Open Responsible AI Licenses (Open RAIL) to licencje zaprojektowane w celu umożliwienia swobodnego i otwartego dostępu, ponownego wykorzystania i dalszej dystrybucji pochodnych artefaktów AI, o ile zawsze mają zastosowanie ograniczenia dotyczące wykorzystania behawioralnego (w tym do utworów pochodnych).” .
Bardziej szczegółowe wyjaśnienie tej licencji jest dostępne na tej stronie BigScience.
Jakie obrazy zostały użyte do trenowania modelu stabilnej dyfuzji?
Modelowanie AI to sposób na tworzenie i trenowanie algorytmów uczenia maszynowego do określonego celu. W tym przypadku celem generowania obrazów z monitów użytkownika.
Jeśli jesteś ciekawy, jakich obrazów używał Stable Diffusion, Andy Baio i Simon Willison przeprowadzili dokładną analizę ponad 12 milionów obrazów (z łącznej liczby 2,3 miliarda), które zostały użyte do trenowania modelu Stable Diffusion.
Oto niektóre z kluczowych wniosków:
- Zestawy danych, które zostały użyte do trenowania Stable Diffusion, zostały zebrane przez LAION.
- Spośród 12 milionów obrazów, które pobrali, 47% całkowitej wielkości próbki pochodziło ze 100 domen, a Pinterest dał 8,5% całego zbioru danych. Inne najlepsze źródła to WordPress.com, Blogspot, Flickr, DeviantArt i Wikimedia.
- Stabilna dyfuzja nie ogranicza możliwości generowania sztuki na podstawie nazwisk ludzi (czy to celebrytów, czy nie).
Interesujące będzie obserwowanie, jak ten model ewoluuje i czy firmy będą skłonne wnosić swoje media, aby pomóc w rozwoju Stabilnej Dyfuzji.
Gdzie znaleźć przykłady i podpowiedzi dotyczące stabilnej dyfuzji?
Jednym ze sposobów, w jaki stabilna dyfuzja różni się od takich jak DALL·E, jest maksymalne wykorzystanie stabilnej dyfuzji; musisz poznać jego modyfikatory . W szczególności jeden modyfikator nazywa się seed . Za każdym razem, gdy generujesz obraz ze stabilną dyfuzją, temu obrazowi zostanie przypisane ziarno, które można również rozumieć jako ogólną kompozycję tego obrazu. Tak więc, jeśli podobał ci się konkretny obraz i chcesz odtworzyć jego styl (lub przynajmniej tak zbliżony, jak to możliwe), możesz użyć nasion.
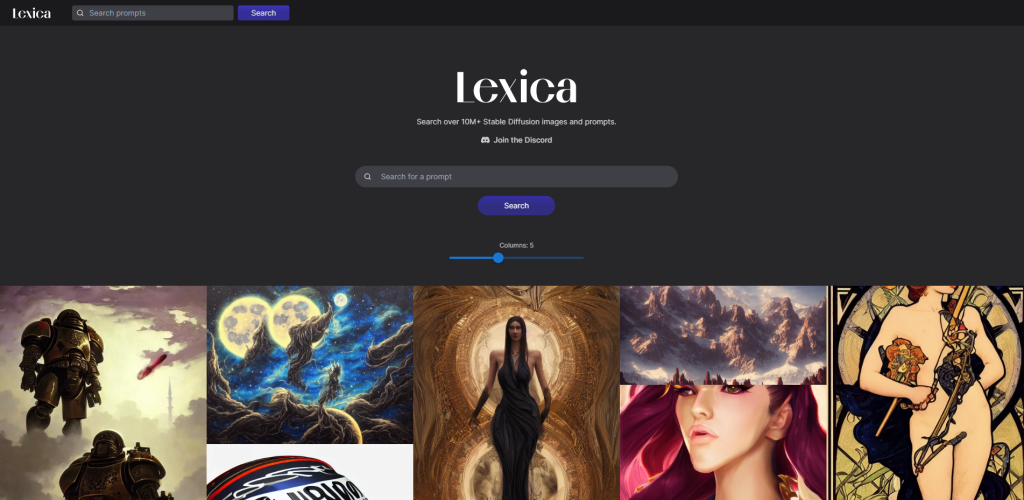
Najlepszą platformą do wyszukiwania przykładów i podpowiedzi używanych do generowania tych obrazów jest Lexica, która archiwizuje ponad 10 milionów przykładowych prac. Każda grafika zawiera pełny monit i numer nasion, którego możesz użyć ponownie.
Czy istnieje oficjalny serwer Discord?
TAk!
Możesz uzyskać do niego dostęp, odwiedzając [https://discord.gg/stablediffusion]; należy zauważyć, że serwer nie obsługuje już generowania obrazów z samego serwera. Ta funkcja była dostępna w ramach programu beta. Jeśli chcesz używać Stable Diffusion z serwera Discord – możesz zajrzeć do projektów takich jak Yet Another SD Discord Bot lub odwiedzić ich serwer Discord, aby go wypróbować.

Narzędzia i oprogramowanie
Jeśli widziałeś lub urzekła Cię sztuka stworzona za pomocą Stable Diffusion, być może zastanawiasz się, czy możesz ją wypróbować samodzielnie. Odpowiedź brzmi: tak, a istnieje wiele sposobów na wypróbowanie Stable Diffusion za darmo, w tym robienie tego z przeglądarki lub komputera.
Oficjalnym sposobem na to jest skorzystanie z platformy DreamStudio.
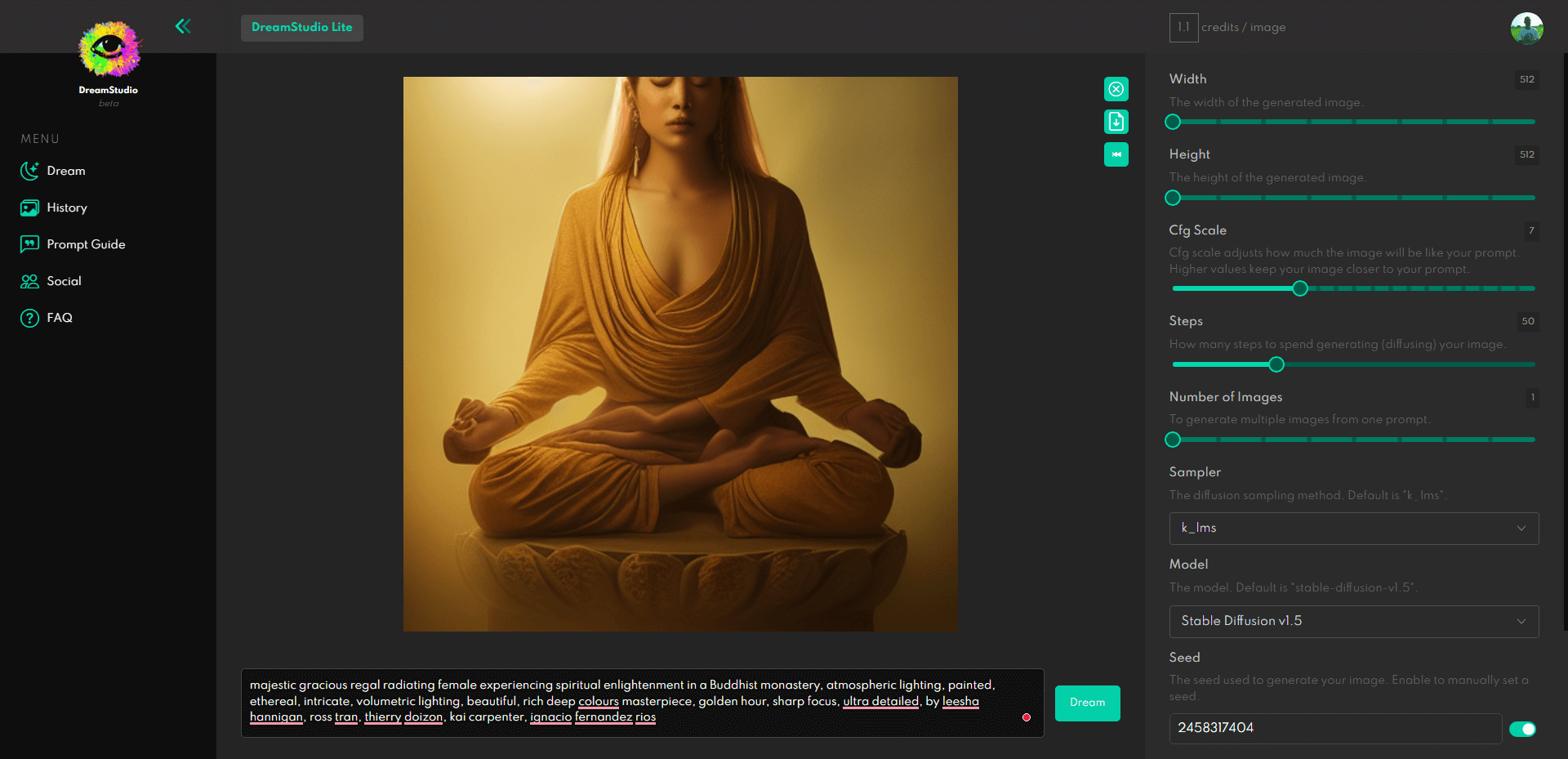
Każdy może zarejestrować się za darmo, a nowe konta otrzymują bezpłatne 200 darmowych tokenów. Te tokeny wystarczą na 200 generacji, o ile nie zwiększysz złożoności i nie zmienisz wysokości i szerokości poza domyślne ustawienie 512×512. Ale jeśli zwiększysz złożoność, prawdopodobnie szybko zabraknie tokenów.
Jak uruchomić stabilną dyfuzję w systemie Windows/Linux?
Obecnie najpopularniejszym rozwiązaniem do lokalnego uruchamiania Stable Diffusion jest repozytorium Stable Diffusion Web UI dostępne na GitHub. Oparte na graficznym interfejsie użytkownika Gradio jest to tak blisko, jak to tylko możliwe do interfejsu DreamStudio i możesz pożegnać się z wszelkimi ograniczeniami.
Jakie są wymagania PC dla Stable Diffusion?
– 4 GB (preferowane więcej) GPU VRAM (tylko oficjalne wsparcie dla Nvidii!)
– Użytkownicy AMD sprawdzają tutaj
Pamiętaj, aby korzystać z repozytorium Web UI; musisz sam pobrać model z Hugging Face. Upewnij się, że przeczytałeś instrukcję instalacji (Windows), aby poprawnie ją skonfigurować. W przypadku systemu Linux zapoznaj się z tym przewodnikiem. Możesz też uruchomić go i uruchomić w Google Colab – przewodnik tutaj.
Czy są jakieś alternatywy dla SD w systemie Windows lub Linux?
Interfejs Stable Diffusion zyskuje na popularności (instalacja 1 kliknięciem dla systemów Windows i Linux).
Jak uruchomić stabilną dyfuzję na komputerze Mac?
Charlie Holtz wydał CHARL-E, instalatora jednym kliknięciem dla użytkowników komputerów Mac (M1 i M2).
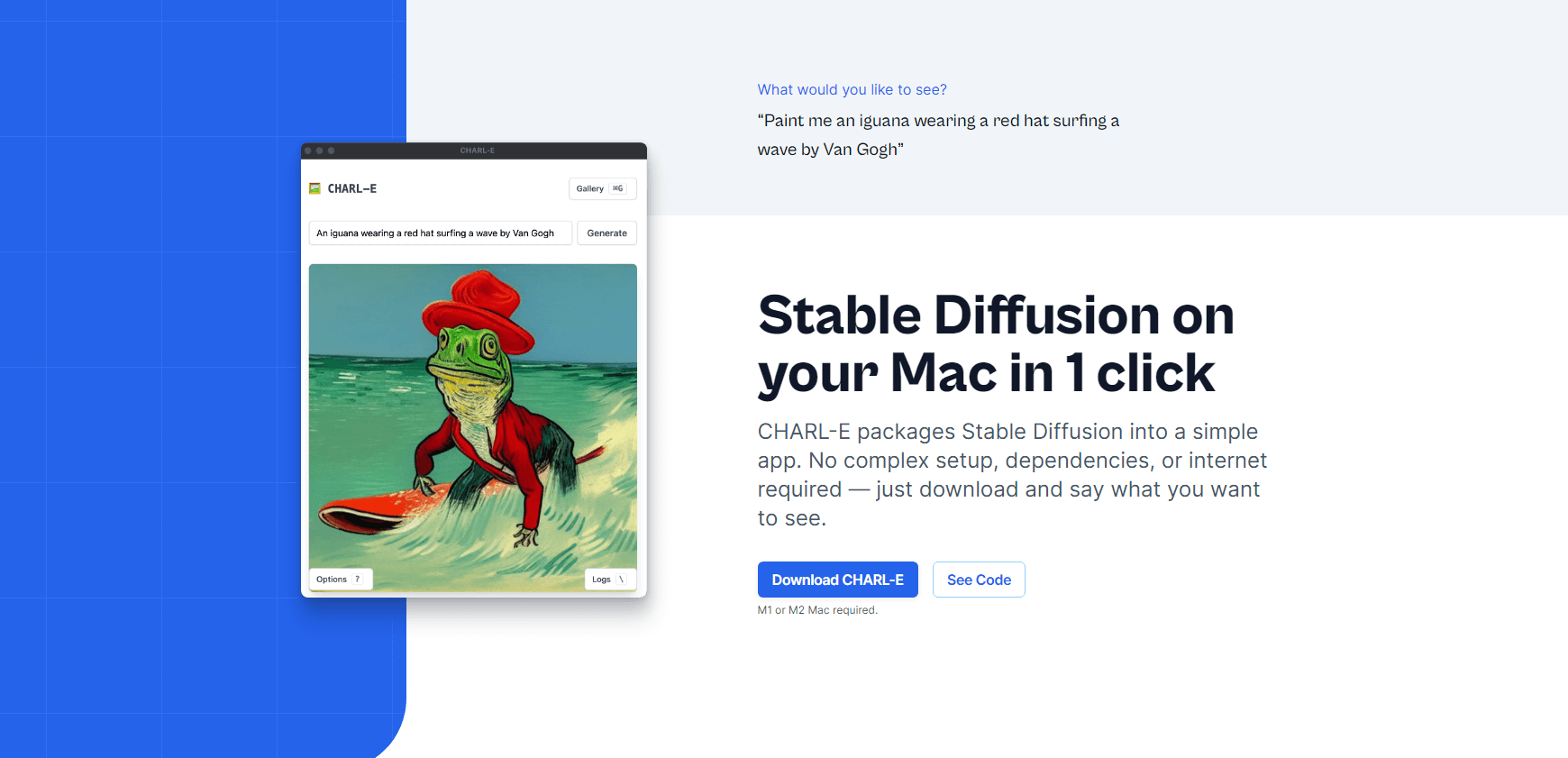
Cechy:
- Automatycznie pobierz wszystkie wymagane wagi.
- Możesz ustawić numer nasion i próbkowanie DDIM.
- Wygenerowane obrazy są zapisywane w galerii.
Jako alternatywę należy rozważyć również pszczołę dyfuzyjną.
Jak duży jest model stabilnej dyfuzji?
Jak wspomniałem powyżej, musisz pobrać model Stable Diffusion, a link znajdziesz tutaj. Będziesz musiał utworzyć konto na Hugging Face, a następnie zaakceptować warunki licencji modelu, zanim będziesz mógł przeglądać i pobierać jego pliki.
Jedno z pytań, jakie ludzie zadają, brzmi: „Jak to możliwe, że model ma tylko 4 GB, mimo że został wykonany z ponad 2 miliardów obrazów?” .
A najlepsza odpowiedź na to pytanie pochodzi od użytkownika Hacker News, juliendorra ⟶
To interesująca część: wszystkie wygenerowane obrazy pochodzą z modelu mniejszego niż 4 GB (wytrenowane wagi sieci neuronowej).
W pewnym sensie setki miliardów możliwych obrazów są przechowywane w modelu (każdy wektor w wielowymiarowej przestrzeni ukrytej) i na żądanie przekształcane w piksele (napędzane przez model języka, który wie, jak zamienić słowa w wektor w tej przestrzeni )
Ponieważ jest to deterministyczne (biorąc pod uwagę dokładnie te same parametry żądania, w tym losowe ziarno, otrzymujesz dokładnie ten sam obraz) jest to również forma kompresji (lub przynajmniej dekodowania kodowania): mógłbym wysłać ci parametry dla 1 miliona obrazów, które byś był w stanie odtworzyć po Twojej stronie, tak jak stosunkowo mały plik tekstowy.
Poradniki i poradniki
Ta sekcja jest w całości poświęcona samouczkom i przewodnikom, które pomogą Ci wydobyć jak najwięcej soku z monitów o stabilnej dyfuzji. Jak powiedziałem, zrobię co w mojej mocy, aby to aktualizować, ponieważ dostępnych będzie więcej przewodników i lepsze zrozumienie modelu.
Konstruktor monitów o stabilną dyfuzję
Poniżej znajdują się dodatkowe przewodniki po stylu, ale jeśli chodzi o wizualne budowanie podpowiedzi – narzędzie promptoMANIA jest prawdopodobnie najlepszym z dostępnych.
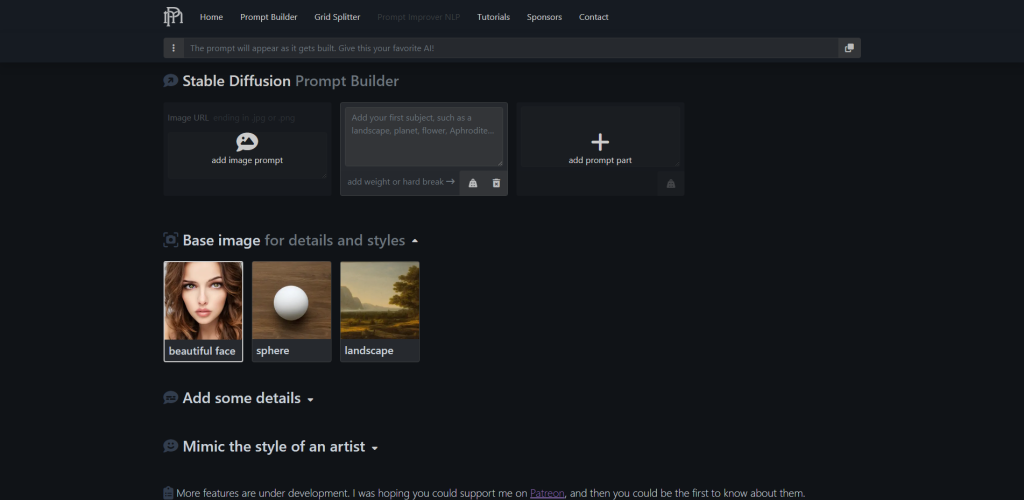
Możesz zacząć od dodania opisu obrazu, który próbujesz utworzyć, a następnie możesz przewinąć w dół, aby rozpocząć dodawanie szczegółów i naśladować style różnych artystów. Do wyboru są setki opcji, każda z wizualnym podglądem.
Po zakończeniu budowania ciągu możesz go skopiować, a następnie wkleić do dowolnego narzędzia, którego używasz do generowania obrazów stabilnej dyfuzji.
Najlepszy przewodnik dla początkujących
Arman Chaudhry opublikował kompaktową prezentację Dokumentów Google na temat podstaw SD.
Ten przewodnik obejmuje wszystkie modyfikatory obsługiwane przez SD, ale także zaleca najlepsze praktyki dotyczące ustawień szerokości/wysokości oraz typowe błędy, których należy unikać.
Kroniki Akaszy
Jeśli szukasz głębokiego nurkowania (lub potrzebujesz referencji do badań) – repozytorium SD Akashic Records ma zdumiewającą ilość zasobów do nauki.
Znajdziesz tu wszystko, od użycia słów kluczowych, przez szybką optymalizację, po przewodniki po stylu. Istnieją również wzmianki o kilku narzędziach, poza tymi, które zostały już wymienione w tym artykule.
Szybka ściągawka
Jeśli szukasz inspiracji do zastosowania niestandardowych stylów i efektów do swoich podpowiedzi, zapoznaj się z tym wpisem na blogu Moritza. Obejmuje szybkie dodawanie pojęć, takich jak grafika 2D i 3D, szczegóły, oświetlenie, kolory i środowiska.
Style i środki artystyczne
Sprawdź ten plik Dokumentów Google, aby znaleźć ponad 100 różnych stylów i mediów, których możesz użyć podczas generowania obrazu SD. Dokument opiera się na pojedynczym monicie, a wspomniany monit został wygenerowany w setkach różnych stylów, dzięki czemu możesz powielić ten sam styl w swoich monitach.
Style wizualne i artystyczne
Sprawdź ten plik modifiers.json w serwisie GitHub, aby uzyskać dodatkowe style i rekomendacje wykonawców. To ponad 200 różnych modyfikatorów, które możesz zastosować do swoich podpowiedzi.