
Korzyści i koszty indeksów w bazach danych NoSQL
Opublikowany: 2023-03-03Ogólnie rzecz biorąc, indeksy powinny być używane w bazach danych Nosql , gdy problemem jest wydajność zapytań. Indeksy mogą przyspieszyć wykonywanie zapytań, umożliwiając bazie danych szybkie zlokalizowanie żądanych danych. Jednak indeksy mogą również spowalniać operacje zapisu i zajmować dodatkową przestrzeń dyskową. W związku z tym ważne jest, aby dokładnie rozważyć, czy korzyści płynące z zastosowania indeksu przewyższają koszty.
Jest to zorientowany na dokumenty system zarządzania bazą danych, który wykorzystuje usługę sieciową RESTful. Jest w stanie przechowywać duże ilości danych w dokumentach o różnej wielkości i strukturze. Jednym z najbardziej krytycznych narzędzi dla administratorów baz danych jest posiadanie indeksów. Celem tego samouczka jest wyjaśnienie, jak działają indeksy, jak je tworzyć i pokazać, w jaki sposób są one używane przez bazę danych. Indeksowe struktury danych to specjalne typy struktur danych, które przechowują tylko część danych zebranych z kolekcji. Ponieważ są one zaimplementowane w taki sposób, że są w stanie szybko i łatwo przemierzać bazę danych, MongoDB doskonale nadaje się do tego celu. W tym przewodniku nauczymy Cię, jak stworzyć przykładową bazę danych i jak ją zaindeksować.
Ten samouczek nauczy Cię, jak utworzyć kolekcję dokumentów z różnymi polami. Góry są tutaj wymienione w dokumentach, które opisują pięć najwyższych szczytów świata. Dane wyjściowe będą zawierały tablicę identyfikatorów dla nowo wstawionych obiektów. Celem tego przewodnika jest wyjaśnienie, w jaki sposób MongoDB używa indeksów do ograniczania przeglądania dokumentów poprzez wyróżnianie szczegółów zapytania w indeksach. Możesz użyć metody createIndex() do utworzenia indeksu w polu wysokości kolekcji pików. Kiedy w tym przykładzie tworzymy indeks z pojedynczym polem, możemy założyć, że dokument zawiera jeden klucz (wysokość w tym przykładzie). Powinieneś spróbować ponownie, używając indeksu, ponieważ powinieneś mieć to samo zapytanie, co wcześniej.
Ponieważ indeks był składnikiem wykonania zapytania, dane wyjściowe będą inne. Drugim krokiem jest stworzenie indeksów, które są unikalne dla rynku. Nie można dodać dwóch dokumentów do kolekcji, jeśli obie wartości _id są takie same. Wynika to z faktu, że baza danych automatycznie utrzymuje indeks pojedynczego pola w polu _id. Jak zobaczysz w tym kroku, wartość danego pola można dostosować dla każdego dokumentu w kolekcji za pomocą indeksów. Czwartym krokiem jest dodanie indeksu do pola osadzonego w bazie danych MongoDB. Gdy zapytanie przekracza pojemność bazy danych, może to znacząco wpłynąć na jej wydajność.
Celem tego kroku jest zademonstrowanie sposobu generowania indeksów jednopolowych dla pól w osadzonych dokumentach. Gdy istnieje nadmierna liczba indeksów, jest bardzo możliwe, że wydajność ucierpi tak samo, jak gdyby było tylko kilka indeksów. MongoDB użyje indeksów w ostatecznej kolejności, ponieważ pole w indeksie jest uwzględnione w ostatecznej kolejności. Innymi słowy, po pobraniu wszystkich dokumentów nie musi ich ponownie sortować. W poprzednim przykładzie indeks został utworzony w formie rosnącej przy użyciu składni *ascents.total: 1 * i zapytania o szczyty górskie posortowane malejąco. Indeks pojedynczego pola może być użyty do zidentyfikowania wszystkich dokumentów, które MongoDB próbuje przeszukać. Gdy indeks jest dostępny tylko dla pierwszej części zapytania, MongoDB najpierw wykona skanowanie kolekcji.
W niektórych przypadkach przypadek może nie być taki sam w przypadku indeksów złożonych. Korzystne może być zdefiniowanie indeksu, który obejmuje wiele pól, aby upewnić się, że nie są wymagane żadne dodatkowe skany. Szóstym krokiem jest opracowanie indeksu wielokluczowego. Ten krok pokazuje, jak MongoDB zachowuje się, gdy pole użyte do wygenerowania indeksu jest polem przechowującym wiele wartości, takim jak tablica. Ponieważ nie ma indeksu dla pola lokalizacji, MongoDB wykonuje pełne skanowanie kolekcji w celu wykonania zapytania. Każdy z tych czterech szczytów rozciąga się na kraj, który jest tablicą wielu wartości, i reprezentują one więcej niż jeden kraj. Każde pole w tablicy jest automatycznie tworzone jako indeks wielokluczowy w MongoDB.
Na przykład dokument z polem lokalizacji zawierającym tablicę [„Chiny, Nepal”] będzie miał dwa oddzielne wpisy indeksu dla tego samego dokumentu: jeden dla Chin i jeden dla Nepalu. MongoDB może efektywnie wykorzystywać swój indeks, nawet jeśli zapytanie żąda w ten sposób tylko częściowego dopasowania do jego zawartości. Indeksy MongoDB mogą zmniejszyć ilość danych, które należy przeanalizować podczas wykonywania zapytania, dzięki zastosowaniu specjalnych struktur danych. W samouczku omówiono podzbiór funkcji indeksowania MongoDB, aby poprawić wydajność zapytań w obciążonych bazach danych. Dowiedz się więcej o indeksowaniu MongoDB z oficjalnej dokumentacji MongoDB .
indeksy, oprócz przeszukiwania wierszy w tabeli bazy danych przy każdym dostępie do tabeli, mogą służyć do szybkiego lokalizowania danych. Tworzenie indeksów przy użyciu jednej lub kilku kolumn tabeli bazy danych jest proste, co pozwala na szybkie i wydajne losowe wyszukiwanie oraz dostęp do uporządkowanych rekordów.
System NoSQL przechowuje indeksy wyszukiwania na dwa sposoby: indeksy na miejscu przechowywane w bazie danych NoSQL oraz poprzez zdalną usługę wyszukiwania. Systemy NoSQL zwykle przechowują swoje indeksy i dane w tym samym węźle. Niektóre systemy NoSQL wykorzystują zewnętrzne usługi wyszukiwania do wyszukiwania pełnotekstowego.
W przypadku używania indeksów jako warunku filtrowania w klauzuli WHERE zapytania nie zaleca się używania indeksów w kolumnach, które zwracają duży odsetek wierszy danych. Gdybyś miał wpis dla słów „the” lub „and” w indeksie książki, nie byłbyś w stanie ich znaleźć. Tabele indeksowane mogą być używane do regularnego uruchamiania wsadów dużych zadań aktualizacji wsadowych.
Ponieważ indeksy w MongoDB nie wymagają skanowania kolekcji, co zwykle obejmuje skanowanie każdego dokumentu w kolekcji w celu znalezienia dopasowania do zapytania, nie musisz wykonywać skanowania kolekcji. Używając odpowiednich indeksów, będziesz mógł efektywniej wyszukiwać, ponieważ liczba dokumentów jest od początku ograniczona.
Kiedy powinniśmy używać indeksów baz danych?
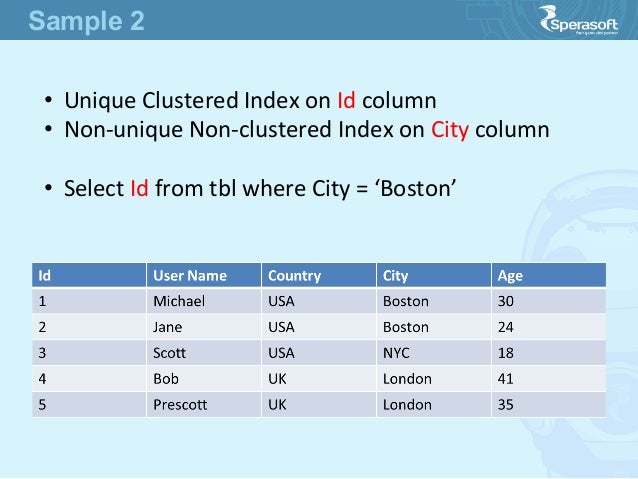
Co to jest indeks i dlaczego jest używany? Szybkość i łatwość użycia indeksu danych ułatwiają pobieranie danych z baz danych. Ta metoda przyspiesza wybieranie zapytań i klauzul WHERE. Chociaż poprawiło to wydajność INSERT, zmniejszyło również wydajność UPDATE.
Indeks tabeli bazy danych zawiera kopię jednej lub więcej kolumn (lub kolumn). Podobnie, każdy skopiowany wiersz jest połączony z oryginalnym wierszem w kolumnie tabeli w indeksie, a ten link jest również obecny w każdym skopiowanym wierszu. Kiedy baza danych wykonuje więcej operacji odczytu niż operacji zapisu, indeksy są najbardziej przydatne. Prawie na pewno nie będziesz potrzebować indeksu dla działań, które piszesz, a nie czytasz w kolumnie tabeli. Możliwe jest utworzenie indeksu dla wielu kolumn w bazie danych, ale kolejność kolumn jest bardzo ważna. Użytkownicy będą mogli wyszukiwać filmy po nazwisku reżysera i zobaczyć, które filmy były wyświetlane w porządku chronologicznym, wprowadzając nową funkcję. Gdybyśmy utworzyli indeks z datą wydania jako pierwszą, nie mielibyśmy możliwości sprawdzenia, czy każde wydanie zawiera wiele identyfikatorów reżyserów powiązanych z indeksem. Reżyserzy zostaną teraz poproszeni o dokładniejsze wyszukiwanie wraz z datami wydania dla każdego zestawu reżyserskiego. Indeksy baz danych wyróżniają się zrównoważonymi drzewami lub B-drzewami.
Podzbiór wierszy w tabeli można pobrać za pomocą indeksu, co skutkuje szybszym skanowaniem tabeli. W zależności od względnej szybkości skanowania tabeli i klastra wierszy powiązanych z kluczem indeksu, wiersze pobierane przez indeks będą się różnić.
Jeśli chodzi o tabele z szerokim zakresem wartości, indeksy mogą być niezwykle przydatne w skracaniu czasu potrzebnego na ich przeszukiwanie.
Czy Nosql używa indeksów?
Używając technik indeksowania dla baz danych NoSQL, indeksowanie I Indexed Structures to proces parowania klucza z lokalizacją rekordu danych. Bazy danych NoSQL mogą być indeksami na różne sposoby. W tej sekcji pokrótce opisano niektóre z bardziej powszechnych metod indeksacji, takie jak indeksy B-Tree, T-Tree i O2-Tree.
Mongodb: potężna baza danych zorientowana na dokumenty
Baza danych MongoDB to zorientowana na dokumenty baza danych, która wykorzystuje indeksy wielokluczowe do indeksowania zawartości tablic. W takim przypadku zapytania mogą wykorzystywać dopasowywanie elementów lub elementów tablicy w celu określenia, czy dokument zawiera tablice. Oprócz indeksów podstawowych MongoDB obsługuje indeksy wtórne, których można użyć do zapytania o atrybuty inne niż podstawowe.
Gdzie należy stosować indeksy?
Indeksy powinny być stosowane w bazach danych w celu przyspieszenia procesu wyszukiwania danych. Indeksy mogą służyć do poprawy wydajności zapytań SQL.
Zawiera listę nazwisk, tematów i innych tematów, które zostały powiązane z lokalizacjami, w których zostały znalezione. Systemy te mogą być również wykorzystywane w internetowych bazach danych do organizowania i kategoryzowania danych. W tym artykule omówiono tworzenie i obsługę indeksów, podobnie jak podstawy indeksów. W wersji roboczej indeksu uwzględnisz swoje główne tematy, a także wszelkie alternatywne. Podkategorie powinny być tworzone tylko wtedy, gdy są interesujące dla autora i odnoszą się do tematu książki. Jeśli piszesz do publikacji branżowej, być może będziesz musiał użyć alternatywnego lub slangowego terminu dla niektórych słów. Rozpoczynając słowo indeksowe, użyj rzeczownika.
Większość wpisów w indeksie nie zawiera słów pisanych wielką literą. Będziesz musiał napisać to kursywą, jeśli odwołujesz się do publikacji. Niektórzy wydawcy zatrudniają profesjonalnych indeksatorów, którzy zapewniają, że każda strona w ich witrynie jest zgodna z licznikiem stron indeksu. Będziesz musiał upewnić się, że pisownia twoich nazwisk lub tytułów jest spójna i poprawna, jeśli używasz ich w pierwszej kolejności. Cytując badacza o nazwisku John Grey, nie będziesz w stanie dopasować swojej autokorekty do jego nazwiska w indeksie.
Indeksując zapewniasz szybki i łatwy dostęp do potrzebnych informacji. Możesz generować raporty w swoim systemie, które pomogą Ci w podejmowaniu lepszych decyzji dotyczących Twojej firmy.
Dlaczego powinniśmy używać indeksowania w Mongodb?
Istnieje kilka powodów, dla których warto używać indeksowania w MongoDB:
1. Indeksowanie może poprawić wydajność zapytań, zwłaszcza jeśli chodzi o konkretne wartości, a nie o wyszukiwanie pełnotekstowe.
2. Indeksowanie może pomóc w egzekwowaniu ograniczeń unikatowości danych, co może być przydatne, jeśli budujesz system, który opiera się na integralności danych.
3. Indeksowanie może również pomóc zoptymalizować wykorzystanie przestrzeni dyskowej, ponieważ indeksowanie umożliwia przechowywanie tylko tych danych, które są potrzebne do pobrania wyników.
Według MongoDB nadmierne indeksy mogą również negatywnie wpływać na wydajność. W tym artykule przeprowadzę kilka prostych eksperymentów i przedstawię kilka znalezionych heurystyk, które pomogą Ci określić, kiedy i ile indeksów jest wymaganych. Do wygenerowania wyników przedstawionych w tym artykule wykorzystano eksperyment N=1. Nie użyłbym niczego innego do zbudowania mojej aplikacji, ponieważ MongoDB działa znakomicie. Generujemy 50 milionów dolarów przychodów rocznie, używając jednego klastra MongoDB do małych obciążeń w chmurze, dzięki dobrej strategii indeksowania. Posiadanie kilku wzorców projektowych i ostrożność przy znanych powolnych operacjach może ułatwić obsługę kolekcji składających się z dziesiątek milionów dokumentów.

Indeksowanie w Sql Vs Nosql
Istnieje kilka kluczowych różnic między indeksowaniem w bazach danych SQL i NoSQL. Po pierwsze, bazy danych SQL zwykle używają indeksów B-drzewa, podczas gdy bazy danych NoSQL często używają indeksów mieszania . Po drugie, bazy danych SQL zazwyczaj indeksują wszystkie kolumny w tabeli, podczas gdy bazy danych NoSQL zazwyczaj indeksują tylko kolumny, których dotyczy zapytanie. Wreszcie, bazy danych SQL zwykle wymagają aktualizacji indeksu, gdy dane w tabeli są aktualizowane, podczas gdy bazy danych NoSQL często aktualizują indeks automatycznie.
W tym poście omówię różnice między bazami danych SQL i NoSQL oraz omówię ich wydajność. Ponadto przedstawię listę przypadków użycia, w których jeden jest lepszy od drugiego. Wszystkie bazy danych mają własny język zapytań lub podejście do zapytań o dane, w zależności od bazy danych. W porównaniu z bazami danych SQL bazy danych NoSQL są bardziej wydajne w wykonywaniu operacji zapisu na sekundę. Ponieważ dane są nieustrukturyzowane i niezweryfikowane przed wprowadzeniem do bazy danych, istnieje możliwość wstawienia lub zapisania zniekształconych lub błędnych danych. Odnosząc się do baz danych NoSQL, baza danych „bez schematu” nie wymaga stałego schematu do wprowadzania i pobierania danych. W sytuacjach, gdy wymaganych jest wiele operacji odczytu na sekundę, bazy danych SQL mogą być skutecznym wyborem.
Jest to szczególnie przydatne w przypadku usług rejestrowania dzienników, które muszą przechowywać duże ilości danych. Te bazy danych mają silniki indeksów nowej generacji, które mogą być bardziej wydajne i mniej niezawodne niż tradycyjne bazy danych. Bazy danych NoSQL są zarówno wydajne, jak i popularne, ale bazy danych SQL mają wiele zalet. Wszystko sprowadza się do potrzeb i potencjału Twojej organizacji. Jeśli chcesz technologii sprawdzonej w boju i dużej wiedzy branżowej, skorzystaj z tradycyjnej bazy danych. Z drugiej strony NoSQL jest najlepszym narzędziem do jak najszybszego przechowywania ogromnych ilości nieustrukturyzowanych danych.
Indeks Nosql
Baza danych NoSQL to nierelacyjna baza danych, która nie korzysta z tradycyjnej struktury relacyjnej bazy danych opartej na tabelach. Bazy danych NoSQL są często używane w przypadku dużych zbiorów danych i aplikacji internetowych działających w czasie rzeczywistym.
Indeks pomocniczy zawiera tablicę atrybutów, które nie są zawarte w tabeli nadrzędnej indeksu. Dostępne są oddzielne partycje i sortowanie tabel; w przeciwieństwie do tabeli bazowej, to oprogramowanie może służyć do sortowania i partycjonowania danych. Indeks wtórny, jak mogliśmy założyć, nie składa się z tabeli podzielonej według klucza partycji. Tabela jest przechowywana w tym samym węźle co tabela nadrzędna. Dodatkowe indeksy można zdefiniować przy użyciu tabeli partycji w bazach danych NoSQL typu klucz-wartość. W tym samym węźle co tabela podstawowa indeks drugorzędny jest strukturą danych. Łatwo było zaimplementować indeks pomocniczy w sekcji dotyczącej implementacji bazy danych w pamięci. Ten eksperyment pokazał, jak zaimplementować dwie strategie indeksowania (kopiowanie i pobieranie).
Indeksowanie Mongodb
Indeksowanie MongoDB to proces, który tworzy struktury danych w celu optymalizacji wydajności zapytań. Indeksy wspierają sprawne wykonywanie zapytań w MongoDB. Bez indeksów MongoDB musi skanować każdy dokument w kolekcji, co może być kosztowne i powolne.
Indeks to rodzaj specjalnej struktury danych, która przechowuje część danych kolekcji w łatwo dostępnym formacie. Wpisy indeksu w ten sposób są uporządkowane w taki sposób, aby zarówno ich dopasowania równości, jak i operacje zapytań oparte na zakresie były wydajne. MongoDB indeksuje dokumenty w dowolnym polu lub podpolu, które znajduje się w kolekcji i może być zdefiniowane na poziomie kolekcji. Indeksy MongoDB umożliwiają wyszukiwanie danych i wykonywanie zapytań w oparciu o typ danych i wymagane zapytanie. W indeksie złożonym istnieje znacząca różnica między kolejnością, w jakiej wymienione są pola, a kolejnością, w jakiej się pojawiają. MongoDB indeksuje dane przechowywane w tablicach przy użyciu indeksów wielokluczowych. MongoDB udostępnia dwa rodzaje indeksów do zarządzania danymi współrzędnych w systemach geosynchronicznych: 2dsphere i 2dsphere.
Zamiast rzadkiego indeksu wersja MongoDB 5.3 umożliwia utworzenie indeksu klastrowego. Ukryte indeksy nie są widoczne w narzędziu do planowania zapytań i nie można ich używać do obsługi zapytania. Ukryty indeks można ukryć w planerze, aby użytkownicy mogli zobaczyć, jak spadek indeksu może wpłynąć na wartość indeksu bez faktycznego porzucania go. W MongoDB użytkownicy mogą określić, które reguły mają zastosowanie do ciągów porównawczych, takich jak wielkość liter i znaki diakrytyczne. Jeśli operacja określa inne sortowanie, operacja nie może wykonywać porównań ciągów w polach indeksowanych przy użyciu indeksu z sortowaniem. Samouczek Analiza wydajności zapytania zawiera przykład statystyki zapytania wykonanego z indeksem i bez niego. MongoDB wykorzystuje indeksy, aby pomóc w wypełnianiu zapytań za pomocą ich przecięcia.
Klawisze indeksu podlegają pewnym ograniczeniom w określonych przypadkach. Podczas tworzenia indeksu wydajność aplikacji może być niższa. Sterownik może używać NumberLong(1) zamiast 1 jako specyfikacji indeksu . W rezultacie otrzymany indeks nie ulega zmianie.
Czy powinieneś używać indeksów w Mongodb?
Jakie są zalety i wady używania indeksów w MongoDB?
Dzięki indeksowaniu MongoDB może szybciej przeszukiwać dane, poprawiając wydajność zapytań. indeksy mogą również pomóc zapewnić spójność danych w wielu fragmentach i węzłach. Z drugiej strony indeksy mogą również zwiększać złożoność i koszt zapytań, dlatego należy ich używać ostrożnie, jeśli nie ma takiej potrzeby.
Indeks złożony Mongodb a pojedynczy indeks
Indeksy złożone nie indeksują tylko jednego pola dokumentu; indeksują wiele pól w porządku rosnącym lub malejącym i sortują dane z wielu pól po wprowadzeniu pola.
Indeksowanie MongoDB może pomóc w lepszym wykorzystaniu zapytań. Termin indeks złożony odnosi się do indeksów z wieloma odniesieniami do pojedynczego pola. W MongoDB pojedyncze zahaszowane pole indeksu może służyć do reprezentowania indeksu złożonego. Dzięki temu zapytania takie jak db.collection.sort (producent:1, cena:-1) mogą być uruchamiane wydajniej dzięki stworzonemu przez nas indeksowi. W indeksie MongoDB sort() jest dostarczane przez MongoDB. Dopasowanie wyrażenia sortowania MongoDB (przedrostek dopasowania) można uzyskać z indeksu zawierającego uporządkowane rekordy, co oznacza, że MongoDB może uzyskać dopasowania wyrażenia sortowania (prefiks dopasowania) z dowolnego indeksu zawierającego uporządkowane rekordy. Jeśli MongoDB nie jest w stanie wygenerować porządku sortowania przy użyciu indeksu, wykonuje blokującą operację sortowania.
Co to jest pojedynczy indeks w Mongodb?
MongoDB indeksuje dokumenty na podstawie pola, w którym są przechowywane, a także innych pól w kolekcji. Wszystkie kolekcje mogą mieć indeks w polu -id, a aplikacje i użytkownicy mogą dodawać dodatkowe indeksy w celu obsługi ważnych zapytań i operacji. Wykresy indeksowe są ułożone w porządku rosnącym lub malejącym na jednym polu dokumentu.
Dlaczego indeksowanie jest ważne
Proces tworzenia indeksu dokumentu lub zestawu dokumentów w celu przyspieszenia i ułatwienia wyszukiwania informacji jest znany jako konstrukcja indeksu . Indeksowanie jest przydatne z dwóch powodów. Pierwszą zaletą indeksów jest to, że mogą one pomóc w szybszym znalezieniu określonej informacji w dużym dokumencie. Na przykład, jeśli szukasz określonych artykułów w gazecie, indeks będzie w stanie powiedzieć, jaki był tytuł artykułu. Jedną z zalet indeksów jest ułatwienie dostępu do informacji zawartych w dokumencie osobom niepełnosprawnym. Na przykład indeks giełdowy może być wykorzystany do znalezienia informacji o konkretnej firmie na podstawie jej symbolu giełdowego, umożliwiając to osobom niewidomym.
Jaka jest inna opcja indeksowania w Mongodb?
MongoDB indeksuje zawartość w tablicach w MongoDB przy użyciu indeksów wielokluczowych. MongoDB tworzy osobne wpisy indeksu dla każdego elementu tablicy, jeśli indeksuje pole z wartością tablicy. W tych indeksach wielokluczowych zapytania mogą wybierać dokumenty z tablicami, dopasowując elementy lub części tablicy do ich indeksów wielokluczowych.
Usunięcie indeksu w Mongodb zmniejszy wydajność wyszukiwania
Jedną wadą jest to, że MongoDB będzie zmuszony do ponownej analizy danych w celu znalezienia odpowiednich rekordów, jeśli indeks zostanie usunięty.
Wprowadzenie Mongodb
Mongodb to potężny system baz danych zorientowany na dokumenty. Posiada funkcję wyszukiwania opartą na indeksie, która sprawia, że wyszukiwanie danych jest szybkie i łatwe. Mongodb oferuje również funkcję skalowalności, umożliwiającą obsługę danych na dużą skalę.
MongoDB to wieloplatformowa baza danych NoSQL o otwartym kodzie źródłowym i jest używana przez wiele aplikacji internetowych opartych na węzłach do przechowywania danych. W tym samouczku pokażę, jak zainstalować Mongo i jak używać go do przechowywania i wysyłania zapytań do danych. Dowiesz się, jak wchodzić w interakcje z bazą danych Mongo za pomocą programu node i zbadać niektóre różnice między Mongo a tradycyjnymi relacyjnymi bazami danych. Często zdarza się, że MongoDB jest pobierany i instalowany za pośrednictwem oficjalnych kanałów oprogramowania Linux, ale czasami może to skutkować nieaktualną wersją. Jeśli masz dystrybucję Linuksa inną niż Ubuntu, możesz dowiedzieć się więcej o jej instalowaniu, odwiedzając tę stronę. MongoDB udostępnia również narzędzie o nazwie Compass, które umożliwia łączenie się z bazami danych i zarządzanie nimi za pomocą graficznego interfejsu użytkownika. Dzięki MongoDB nie ma potrzeby posiadania kontroli dostępu.
Jeśli używasz Mongo w środowisku produkcyjnym, powinieneś wprowadzić zmiany w tej funkcji. Akronim CRUD służy do wskazania, że coś zostało utworzone, przeczytane, zaktualizowane lub usunięte. Są to cztery podstawowe operacje na bazie danych, które musisz wykonać, jeśli chcesz zbudować aplikację. Oto kilka kroków, które możesz wykonać, aby odzyskać wszystkie dokumenty użytkownika. Odpowiada to zapytaniu do bazy danych SQL, które odczytuje z kolumny „Od UŻYTKOWNIKÓW”. MongoDB zapewnia wiele sposobów aktualizacji dokumentu, w tym operację tworzenia. Na przykład możesz ustawić wartość rejestracji na 18 lat dla wszystkich użytkowników, którzy nie ukończyli 18 lat.
Nie musisz określać liczby ani typu kolumn podczas korzystania z bazy danych MongoDB, która jest bazą danych bez schematu. Z drugiej strony schemat JSON może być użyty do określenia reguł walidacji naszych danych. Aby komunikować się z serwerem MongoDB, musisz użyć biblioteki po stronie klienta, zwanej sterownikiem. wywołania zwrotne, obietnice lub oczekiwania to wszystkie możliwe metody interakcji z bazą danych. Aby połączyć się z Mongo, musisz podać nazwę i hasło w swoim kodzie. MongoDB ma wbudowany sterownik, ale jest również znany jako sterownik MongoDB. Aby zarządzać danymi w MongoDB, musisz najpierw ustalić schemat. Kształt każdego dokumentu w kolekcji MongoDB jest określany przez mapowanie schematu.
Mongodb: alternatywa Nosql dla relacyjnych baz danych
MongoDB to platforma do zarządzania bazami danych NoSQL typu open source, która zapewnia interfejsy API do zarządzania dużymi zbiorami rozproszonych danych w bezpieczny i wydajny sposób. MongoDB to nierelacyjna baza danych dokumentów, która obsługuje przechowywanie JSON i nierelacyjne struktury dokumentów. Przetwarzanie tradycyjnych relacyjnych baz danych w MongoDB może zająć do pięciu minut. Ponadto MongoDB jest lepszą alternatywą dla relacyjnych baz danych do zarządzania dużymi zbiorami rozproszonych danych.