
Różne typy klastrów komputerowych
Opublikowany: 2023-02-16W informatyce klaster to grupa niezależnych systemów komputerowych, które współpracują ze sobą w taki sposób, że pod wieloma względami można je postrzegać jako jeden system. Klastry są zwykle wdrażane w celu poprawy wydajności i dostępności w porównaniu z pojedynczym komputerem, a jednocześnie są zwykle znacznie bardziej opłacalne niż pojedyncze komputery o porównywalnej szybkości lub dostępności. Istnieją różne typy klastrów komputerowych, w tym klastry obliczeniowe o wysokiej wydajności, klastry komputerowe wykorzystywane do celów komercyjnych oraz klastry pamięci masowej. W każdym typie klastra systemy składowe współpracują ze sobą, aby wykonać wspólne zadanie lub zadania. Klastry obliczeniowe o wysokiej wydajności (HPC) są wykorzystywane w zastosowaniach naukowych i inżynieryjnych, które wymagają dużej mocy obliczeniowej i/lub przechowywania danych. Klastry te zazwyczaj składają się z grupy komputerów towarowych połączonych szybką siecią lokalną (LAN). Komputery w klastrze HPC zwykle działają z tym samym lub podobnym systemem operacyjnym (OS) i mają takie same lub podobne komponenty sprzętowe. Klastry komercyjne są używane do uruchamiania aplikacji biznesowych, które wymagają wysokiego stopnia dostępności i/lub skalowalności. Klastry te często składają się z serwerów z różnymi systemami operacyjnymi i różnymi komponentami sprzętowymi. W wielu przypadkach serwery w klastrze komercyjnym są również połączone z siecią pamięci masowej (SAN), dzięki czemu mogą uzyskiwać dostęp do wspólnych magazynów danych. Klastry pamięci masowej służą do udostępniania scentralizowanego repozytorium pamięci masowej, do którego dostęp ma grupa komputerów. Klastry pamięci masowej zazwyczaj składają się z grupy serwerów pamięci masowej podłączonych do sieci SAN. Na serwerach w klastrze pamięci masowej zwykle działają różne systemy operacyjne i mają różne komponenty sprzętowe.
Co to jest podzielony na fragmenty klaster mongodb i jaki jest sens łączenia się z nim w MongoDB? Jak połączyć się z jednym lub po prostu połączyć się z hostem lokalnym? Złoty medal przyznawany jest w odznace Noob 7461. Wyprodukowano dziesięć odznak srebrnych i 23 odznaki z brązu. Zreplikowany klaster składa się z dziesięciu serwerów, z których jeden jest przeznaczony dla interfejsu mongos, trzy dla każdego zestawu replik i po jednym dla każdego zestawu replik serwera konfiguracji. W systemie replikacji komponent jest duplikowany, dzięki czemu zawsze istnieje kopia zapasowa, jeśli coś pójdzie nie tak. Wszystkie odłamki muszą być replikami, aby mogły zostać wyprodukowane.
Na przykład klaster mongodb jest powszechnie używany do opisania klastra podzielonego na fragmenty w MongoDB. Podzielony na fragmenty mongodb obsługuje następujące funkcje: Skalowanie odczytów i zapisów z kilku węzłów. Ponieważ każdy węzeł nie obsługuje całego zestawu danych, dane można podzielić tylko na regiony we fragmentu.
Klaster bazy danych , jak sama nazwa wskazuje, jest zbiorem baz danych, które mogą być uruchamiane przez jedną instancję działającego serwera bazy danych. Postgres, co oznacza „domyślną” bazę danych w PostgreSQL, zostanie włączony jako domyślna baza danych do klastra baz danych po jego utworzeniu.
Klaster MongoDB może być również określany jako „zestaw replik” lub „klaster podzielony na fragmenty”. W zestawie replik kilka serwerów przechowuje kopie tych samych danych. Węzły w zestawie replik są zwykle trzy. Gdy aplikacja kliencka wykonuje jakiekolwiek operacje na węźle, wszystkie odczyty i zapisy są wysyłane do tego węzła; jeśli coś pójdzie nie tak, chronią go dwa węzły drugorzędne.
Czy klaster i baza danych to to samo?
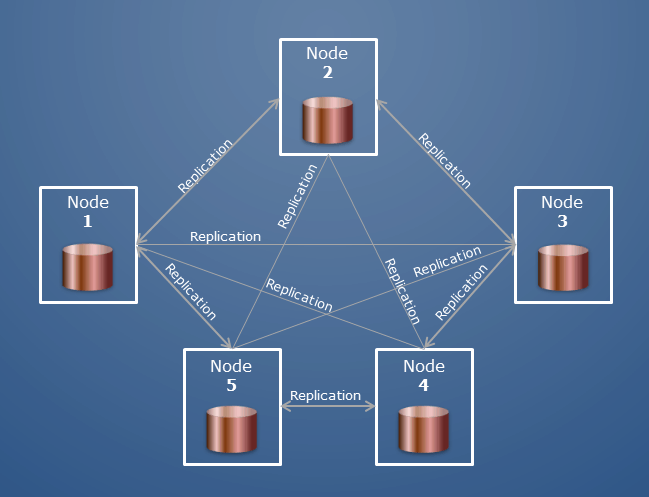
Istnieje wiele klastrów hostów, które tworzą klaster. Hosty podzielonego na fragmenty klastra są sklasyfikowane według różnych ról. Baza danych jest zbiorem kolekcji; w Oracle byłby to odpowiednik bazy danych i aschema.
Klaster bazy danych to zbiór serwerów lub instancji, które łączą jedną bazę danych z inną. Klastrowanie baz danych jest wykorzystywane przez serwery z różnych powodów, z których głównymi są nadmiarowość danych, równoważenie obciążenia, wysoka dostępność oraz monitorowanie i automatyzacja. W rezultacie, jeśli komputer ulegnie awarii, wszystkie nasze dane będą dostępne dla innych, co daje nam przewagę w postaci redundancji danych. Dzięki klastrowaniu istnieje możliwość zautomatyzowania wielu procesów bazy danych, a także tworzenia reguł identyfikujących potencjalne problemy. W architekturze klastrowej wszystkie żądania są kierowane do wielu komputerów, z których każdy jest w stanie obsłużyć żądanie i wygenerować je dla użytkownika. Klaster przełączania awaryjnego lub wysokiej dostępności replikuje serwery i rekonfiguruje sprzęt, aby zapewnić dostępność usług. Tego typu klastry są opłacalne dla użytkowników komputerów, którzy całkowicie polegają na swoich systemach. Celem klastrów o wysokiej wydajności jest zwiększenie przepustowości sieci przy jednoczesnej poprawie wydajności.
W systemie rozproszonym Hadoop węzły działają jako centra przechowywania i przetwarzania danych. Podstawowa różnica między klastrem a serwerem polega na tym, że klaster wykorzystuje wiele węzłów, które komunikują się ze sobą w celu wykonania zestawu operacji. Klaster zawiera pewną liczbę węzłów, które wykonają zestaw operacji. Rozproszony system Hadoop może obsłużyć do 10 000 baz danych. Podobne wyniki zapytania można uzyskać, gdy dane z wielu tabel w tej samej bazie danych są łączone w zapytanie z wielu baz danych w tym samym klastrze.
Korzyści z klastra
Korzystając z klastra, możesz łatwo zarządzać wieloma bazami danych, zapewniając jednolite przechowywanie tabel i kolumn we wszystkich z nich. Poprawia to wydajność i integralność danych, a tym samym sprawia, że system jest bardziej wydajny.
Gdzie jest nazwa klastra w Mongodb?
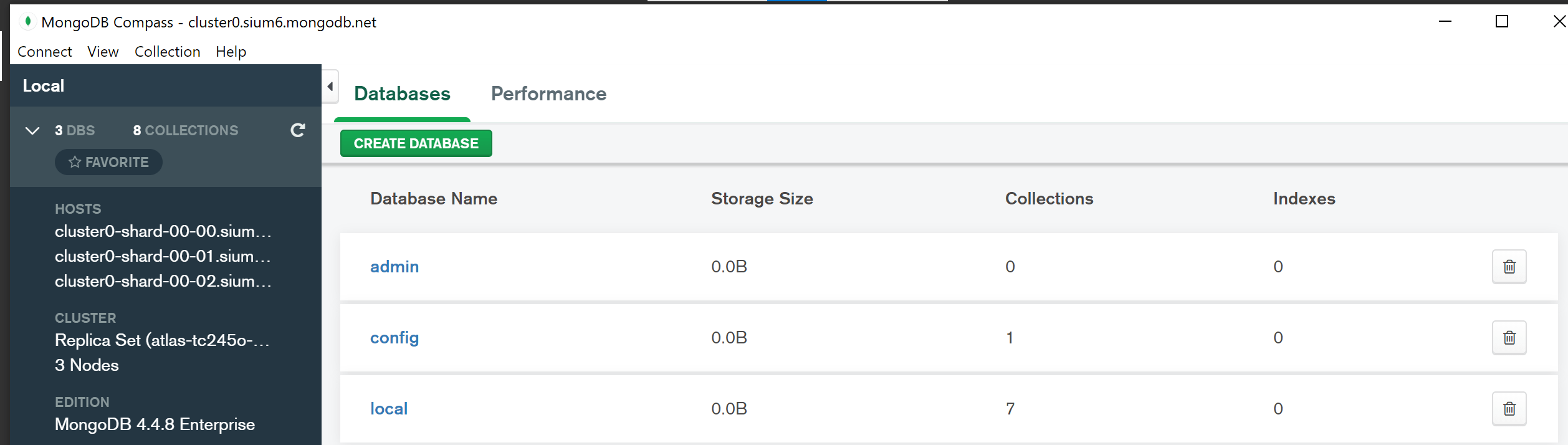
Nie ma ustalonej odpowiedzi na to pytanie, ponieważ nazwę klastra można znaleźć w różnych miejscach w zależności od typu używanego klastra MongoDB. Na przykład w zestawie replik nazwa klastra jest zwykle przechowywana w kolekcji local.system.replset, podczas gdy w klastrze podzielonym na fragmenty zwykle znajduje się w kolekcji config.shards.
MongoDB Atlas to oferta MongoDB-as-a-Service NoSQL Database-as-a-Service, która jest dostępna w chmurach publicznych Microsoft Azure, Google Cloud Platform i Amazon Web Services. Możesz stworzyć działający klaster MongoDB w ciągu kilku minut za pomocą swojej ulubionej przeglądarki internetowej, klikając link, aby go skonfigurować. Nie ma potrzeby instalowania oprogramowania na stacji roboczej, aby połączyć się z Internetem za jej pośrednictwem, a do tego celu można użyć interfejsu sieciowego. Kiedy zestawy replik MongoDB są używane w połączeniu z wieloma serwerami MongoDB, zapewniona jest nadmiarowość danych i wysoka dostępność. Klaster MongoDB ma dodatkową pojemność operacji odczytu, dzięki czemu może kierować klientów do dodatkowych serwerów. Podczas replikacji jeden lub więcej członków zestawu replik jest replikowanych asynchronicznie z węzła głównego do drugorzędnych, dzięki czemu zestaw replik może działać pomimo potencjalnych awarii jego członków. W MongoDB możesz wykonywać dodatkowe operacje odczytu i zapisu oprócz standardowych poleceń wejścia i wyjścia.
W większości przypadków węzeł podstawowy jest źródłem wszystkich operacji odczytu, ale można skonfigurować kierowanie do węzłów pomocniczych. Ryzyko potencjalnie nieaktualnych danych jest większe, gdy najbliższy węzeł jest węzłem pomocniczym. Aby zapis mógł pomyślnie rozprzestrzenić się w klastrze, musisz uwzględnić opcje zapisywania danych w zestawie replik MongoDB. W ramach tego procesu do wstawiania należy dodać właściwość dotyczącą zapisu. Po otrzymaniu żądania zapisu klaster jest proszony o potwierdzenie, że powiodło się w ogromnej większości węzłów przenoszących dane. Konfiguracja podzielonego na fragmenty klastra umożliwia skonfigurowanie go również jako zestawu replik. Zestaw replik zawiera zarówno podstawowe, jak i wtórne procesy mongod. Jeśli master zawiedzie, zaleca się, aby łączna liczba tych procesów była nieparzysta, aby zapewnić wykonanie większości z nich.
Klastry MongoDB , jak sama nazwa wskazuje, to klastry węzłów, które współpracują ze sobą w celu przechowywania danych i zarządzania nimi. Tworząc klaster MongoDB, określasz, ile węzłów ma zawierać i do czego muszą być skonfigurowane. Możesz połączyć swoją aplikację z klastrem MongoDB za pomocą Node po jego utworzeniu. MongoDB Compass można traktować jako sterownik dla biblioteki MongoDB JS lub sterownik PyMongo dla MongoDB. Główną zaletą połączenia aplikacji z klastrem jest to, że może ona odczytywać i zapisywać w nim dane. Dzięki MongoDB Compass możesz eksplorować, modyfikować i wizualizować swoje dane na różne sposoby. Przykład tego, jak możesz przeglądać swoje dane, można znaleźć w siatce, która pozwala obserwować, jak dane zmieniają się w czasie i kto dystrybuuje dane w twoim klastrze.
Gdzie jest klaster w Atlasie Mongodb?
Nie ma jednej ostatecznej odpowiedzi na to pytanie, ponieważ lokalizacja klastra w Atlasie MongoDB może się różnić w zależności od wielu czynników, w tym regionu geograficznego, w którym się znajduje, oraz specyficznych potrzeb aplikacji, którą obsługuje. Jednak generalnie klaster w Atlasie MongoDB można znaleźć w sekcji „Klastry” konsoli MongoDB Atlas.

Klaster może być zestawem replik lub zestawem podzielonym na fragmenty. Całkowita liczba węzłów każdego projektu jest ograniczona określonym ograniczeniem opartym na ich zakresie funkcji w różnych regionach. Każdy projekt Atlas może wdrożyć do 25 baz danych. W przypadku jakichkolwiek pytań dotyczących limitu wdrożenia bazy danych skontaktuj się z administratorami baz danych. TLS w wersji 1.2 to domyślna wersja TLS dla klastrów utworzonych po 1 lipca 2020 r.
Co to jest klaster w Mongodb
W MongoDB klaster to grupa serwerów baz danych, które przechowują kopie tych samych danych. Każdy serwer w klastrze jest nazywany węzłem. Klaster może mieć jeden lub więcej węzłów.
Do czego służy klastrowanie baz danych? Proces łączenia wielu serwerów lub instancji z pojedynczą bazą danych nazywany jest połączeniem SQL. W MongoDB klaster jest zestawem replik lub klastrem podzielonym na fragmenty, w zależności od typu MongoDB. W kolejnych akapitach omówię bardziej szczegółowo poszczególne aspekty tych klastrów. Ze względu na równoważenie obciążenia i liczbę maszyn MongoDB ma wysoki poziom dostępności. Klaster może służyć do automatyzacji wielu procesów bazodanowych, umożliwiając jednocześnie tworzenie reguł ostrzegających o potencjalnych problemach. Bazę danych MongoDB można podzielić na dwa typy: zestawy replik i klastry shardingu.
Dane są przechowywane na wielu komputerach w Shard. Na tym opiera się metoda zapewniania skalowalności danych przez MongoDB. Zmniejsza to ilość czasu potrzebnego do zarządzania dużymi ilościami danych. Ze względu na ilość danych dostarczanych przez repliki aplikacje rozproszone również mogą z nich korzystać.
Problemy z wydajnością i konflikty danych mogą wystąpić, jeśli w tym samym klastrze wdrożono wiele projektów Atlas. Firma Atlas zaleca używanie tylko jednego bezpłatnego klastra na projekt Atlas. Dobre narzędzie do grupowania danych jest wymagane w szerokim zakresie aplikacji do analizy danych i eksploracji danych. Aby uniknąć potencjalnych problemów z wydajnością i konfliktów danych w projektach Atlas, firma Atlas zaleca używanie tylko jednego wolnego klastra na projekt.
Architektura klastra Mongodb
Klaster MongoDB to grupa serwerów MongoDB, które współpracują ze sobą w celu przechowywania danych. Każdy serwer w klastrze jest nazywany węzłem. Klaster może mieć dowolną liczbę węzłów. Klaster składa się z zestawu replik, czyli grupy węzłów, z których każdy ma kopię Twoich danych. Zestaw replik ma co najmniej trzy węzły, więc jeśli jeden węzeł ulegnie awarii, Twoje dane będą nadal dostępne.
Architektura zestawów replik jest ważnym czynnikiem wpływającym na pojemność i możliwości MongoDB. Klastry MongoDB są zazwyczaj dystrybuowane w trzech replikach węzłów. Odzyskiwanie bazy danych po awarii musi być stale stabilne, zwłaszcza w następstwie. Jednym z najlepszych sposobów wdrożenia klastra podzielonego na fragmenty jest użycie strategii replikacji. Dane zawarte w Shard Keys muszą być dystrybuowane w ten sam sposób. Należy skalować bazę danych w poziomie i zmniejszyć liczbę operacji, które można wykonać na pojedynczej instancji. W przypadku niewielkiej liczby fragmentów operacje odczytu i zapisu mogą stać się powolne ze względu na fakt, że liczba fragmentów ogranicza liczbę operacji.
Każdy element danych w Shard składa się z podzbioru tego elementu w oparciu o określony zestaw kryteriów. Często minimalna liczba fragmentów wymaganych do osiągnięcia znaczenia dzielenia na fragmenty wynosi dwa. Zapytań scatter-gather należy używać tylko wtedy, gdy można ich używać jednocześnie na wszystkich fragmentach. Przy wyborze klastra bardzo ważne jest, aby mieć co najmniej siedmiu członków z prawem głosu, aby proces wyborów był jak najprostszy. Jeśli masz tylko siedmiu lub mniej członków z prawem głosu, ale taką samą liczbę członków, należy skorzystać z arbitra. Arbitrzy nie przechowują kopii danych, co powoduje zmniejszenie zasobów potrzebnych do przetworzenia danych. Podczas konfigurowania elementów zestawu replik lub elementów klastra podzielonych na fragmenty preferowane jest używanie logicznej nazwy hosta DNS zamiast adresu IP. Ponieważ niektóre połączenia zestawów replik grupy sterowników są oparte na nazwach zestawów replik, nazwy te powinny być używane oddzielnie dla zestawów. Geograficzna dystrybucja węzłów zestawu replik jest idealna do rozwiązania problemu redundancji i zapewnienia odporności na awarie w przypadku braku jednego z centrów danych.
Nazwa klastra Mongodb
Klaster MongoDB to grupa serwerów MongoDB, które współpracują ze sobą w celu zapewnienia wysokiej dostępności i skalowalności. Klaster zazwyczaj ma serwer główny, który działa jako serwer główny, oraz jeden lub więcej serwerów pomocniczych, które działają jako serwery podrzędne. Serwer główny zawiera dane, a serwery pomocnicze kopiują dane z serwera głównego.
Programy baz danych zorientowane na dokumenty są tworzone do przechowywania dużych ilości danych za pomocą wieloplatformowego programu MongoDB. MongoDB, program bazy danych NoSQL, został sklasyfikowany jako taki, ponieważ wykorzystuje dokumenty w stylu JSON z opcjonalnymi schematami. Możesz poprawić wydajność, instalując bazę danych w tym samym centrum danych, co inne zasoby DigitalOcean. W regionie znajduje się co najmniej jedno centrum danych, a każde z nich ma własną sieć VPC. Można wybrać typ maszyny, liczbę i rozmiar węzłów bazy danych. Innymi słowy, do klastra można dodać maksymalnie dwa węzły rezerwowe. Dodaj nazwę projektu, uzupełnij go i użyj dowolnych tagów, których chcesz użyć podczas jego tworzenia. Tworzenie klastra może potrwać do pięciu minut.
Moc klastra Atlas Mongodb
MongoDB Atlas Cluster to rozwiązanie bazodanowe NoSQL jako usługi w chmurze publicznej, które działa w MongoDB. Jest to solidna, skalowalna platforma danych, która umożliwia szybkie tworzenie i wdrażanie aplikacji. Korzystając z MongoDB Atlas Cluster, możesz bezpiecznie łączyć się z MongoDB z dowolnego miejsca na świecie.
Jak stworzyć klaster w Mongodb
Wykonaj następujące kroki, aby utworzyć klaster w MongoDB:
1. Wybierz topologię wdrożenia.
2. Wybierz typ zestawu replik, który chcesz wdrożyć.
3. Wybierz liczbę zestawów replik, które chcesz wdrożyć.
4. Skonfiguruj zestawy replik.
5. Połącz się z routerem mongos.
6. Skonfiguruj klucz fragmentu.
7. Dodaje elementy do klastra.
8. Sprawdź, czy klaster działa.
MongoDB Atlas to bezpłatna warstwa MongoDB, która jest w pełni zarządzaną usługą bazy danych w chmurze MongoDB. Usługa jest przeznaczona dla obciążeń korporacyjnych, a także globalnych klastrów . Nie musisz tworzyć konta w Amazon Web Services (AWS), Google Cloud Platform lub Microsoft Azure. Poprosi o utworzenie konta administratora w celu uzyskania dostępu do usługi. Aby uzyskać dostęp do usługi, klaster musi być połączony z adresem IP. Domyślne ustawienia bezpieczeństwa MongoDB Atlas zapobiegają wszelkim zewnętrznym połączeniom. Twoje hasło nie powinno zawierać znaków specjalnych, a jedynie znaki alfanumeryczne, aby ułatwić połączenie ze Studio 3T. Podczas tworzenia ciągu połączenia dla MongoDB należy zakodować znaki specjalne. W kroku 1 wybierz Java z listy rozwijanej STEROWNIK, a następnie z listy rozwijanej WERSJA. Jeśli wybierzesz sterownik i wersję, usługa automatycznie zaktualizuje parametry połączenia w kroku 2.
Klastrowanie Mongodb: świetna opcja zapewniająca wysoką przepustowość
Korzystając z klastrowania MongoDB , możesz spełnić wysokie wymagania dotyczące przepustowości, dostępności i przepustowości dla dużych środowisk. Klastry MongoDB można skonfigurować tak, aby obsługiwały szeroki zakres typów zestawów replik MongoDB, od prostych konfiguracji z jednym węzłem po wysoce dostępne konfiguracje z wieloma węzłami.
Samouczek klastra Mongodb
Klaster MongoDB to grupa serwerów MongoDB, które współpracują ze sobą w celu przechowywania danych. Klaster MongoDB może być tak mały, jak pojedynczy serwer lub tak duży, jak setki serwerów. Tworząc klaster MongoDB, określasz liczbę serwerów (węzłów), które chcesz mieć w klastrze. Każdy węzeł w klastrze MongoDB przechowuje podzbiór Twoich danych. Klastry MongoDB są zaprojektowane tak, aby były skalowalne i zapewniały wysoką dostępność. W dowolnym momencie możesz dodać węzły do klastra, aby zwiększyć jego pojemność lub zastąpić uszkodzony węzeł. Gdy usuniesz węzeł z klastra, inne węzły redystrybuują dane z usuniętego węzła, tak aby dane były nadal równomiernie rozmieszczone w klastrze.
Łatwy przewodnik Hevo po klastrowaniu MongoDB to pierwszy krok. Gdy baza danych jest zbyt mała lub zbyt wolna, aby uruchomić system, działalność organizacji jest kontynuowana. MongoDB ma wiele zaawansowanych funkcji zaprojektowanych dla chmury, takich jak sharding i replikacja. MongoDB umożliwia przechowywanie wielu kopii tych samych danych, dzięki czemu są one niezwykle dostępne. W przypadku awarii jednego serwera dane z drugiego można odzyskać natychmiast. Dzięki Hevo Data możesz zautomatyzować, uprościć i wzbogacić proces replikacji danych. Replikacja danych jest prosta i bezbolesna w użyciu, gdy masz dostęp do naszej 14-dniowej bezpłatnej wersji próbnej.
Aby skonfigurować klastry MongoDB, musisz najpierw zainstalować wszystkie trzy niezbędne komponenty. Dzięki zautomatyzowanej platformie Hevo bez kodu możesz śledzić wszystko, co musisz zrobić, aby zapewnić płynną replikację danych. Aby zapewnić maksymalną dostępność, musi być dostępnych wiele serwerów konfiguracyjnych lub routerów. Kiedy router określa, w którym fragmencie znajdują się dane, wysyła żądania do odpowiedniego klastra. W procesie tworzenia klastrów MongoDB wymagane będą następujące kroki, aby dodać do nich shardy. W konfiguracji klastrowej port 27018 jest używany jako domyślny dla serwerów fragmentu. Oznacza to, że jest to serwer shard, a nie serwer konfiguracji.