
Różne sposoby przechowywania danych wykresu na dysku
Opublikowany: 2022-11-22Grafowe bazy danych to rodzaj bazy danych NoSQL, która używa struktur grafowych do zapytań semantycznych z węzłami, krawędziami i właściwościami do reprezentowania i przechowywania danych. Bazy danych wykresów różnią się od innych baz danych NoSQL tym, że przechowują swoje dane w formacie wykresu. Oznacza to, że dane są reprezentowane przez węzły (obiekty) i relacje między tymi węzłami (krawędzie). Pozwala to na znacznie większą elastyczność i łatwiejsze wykonywanie zapytań niż w przypadku tradycyjnych baz danych. Istnieje kilka różnych sposobów, w jakie grafowe bazy danych mogą przechowywać swoje dane na dysku. Najczęstszym jest użycie listy sąsiedztwa. Tutaj każdy węzeł ma listę wszystkich innych węzłów, z którymi jest połączony. Jest to najprostszy sposób przechowywania danych wykresu, ale może być nieefektywny, jeśli wykres jest bardzo duży. Innym sposobem przechowywania danych grafu jest użycie macierzy sąsiedztwa. W tym miejscu używana jest macierz do reprezentowania krawędzi między węzłami. Jest to bardziej wydajne w przypadku większych wykresów, ale może być trudniejsze do zapytania. Ostatnim sposobem przechowywania danych wykresu jest użycie wykresu właściwości. Tutaj każdy węzeł ma zestaw właściwości (atrybutów), a krawędzie między węzłami są definiowane przez te właściwości. Jest to najbardziej elastyczny sposób przechowywania danych wykresu, ale zapytania mogą być trudniejsze. Grafowe bazy danych są potężnym narzędziem do analizy danych i mogą być wykorzystywane do różnych zastosowań. Szczególnie dobrze nadają się do aplikacji wymagających złożonych zapytań lub wymagających elastycznego przechowywania danych.
Jakich metod używają te dokumenty do przechowywania wykresu w systemie plików? Nie jestem pewien, co należy załadować do pamięci i jakich identyfikatorów konkretnie wymagają. Jeśli potrzebne są dalsze badania, wskazanie kluczowych cech, których należy szukać, może pomóc w lepszym zrozumieniu tego.
Jest to technologia służąca do zarządzania dużymi zbiorami danych ustrukturyzowanych, częściowo ustrukturyzowanych lub nieustrukturyzowanych przy użyciu zarówno języka SQL, jak i NoSQL („nie tylko SQL”). Umożliwia organizacjom lepsze zrozumienie ich dużych zbiorów danych i analiz mediów społecznościowych poprzez integrację i analizę danych z różnych źródeł.
Grafowe systemy baz danych zazwyczaj przechowują dane w strukturze podobnej do połączonych list pod względem struktury danych. Przechowywane są w nich bezpośrednie linki do danych, a nie tylko łańcuchy danych.
Używając swojego typu danych jako podstawowego identyfikatora, zdefiniuj system typów dla swojego API i użyj go do wykonywania zapytań przy użyciu języka zapytań GraphQL . Ponieważ GraphQL jest wspierany przez istniejący kod i dane, nie wymaga żadnej specjalnej bazy danych ani silnika pamięci masowej.
Dane wykresu są przechowywane w plikach magazynu, które zawierają informacje o określonej części grafu, takiej jak węzły, relacje, etykiety i właściwości. Jak wspomniano wcześniej, dane są dzielone w ten sposób, aby pomóc w wysoce wydajnym przechodzeniu przez wykresy.
W jaki sposób dane są przechowywane w Graph Nosql?
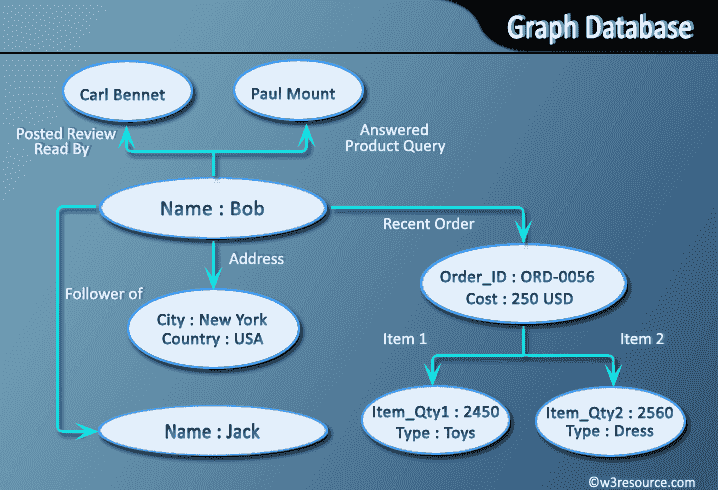
Grafowe bazy danych to rodzaj bazy danych NoSQL, która używa struktur grafowych do zapytań semantycznych z węzłami, krawędziami i właściwościami do reprezentowania i przechowywania danych.
Baza danych wykresów (znana również jako NoSQL lub SQL) to rodzaj bazy danych, w której można przechowywać duże zbiory danych ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych. Pomaga firmom w uzyskiwaniu dostępu, integrowaniu i analizowaniu danych z różnych źródeł, umożliwiając im analizowanie mediów społecznościowych i analiz dużych zbiorów danych. Nie trzeba go ponownie definiować przed dodaniem nowych danych do bazy danych NoSQL, która nie wymaga ponownego definiowania. Standardy W3C używane do reprezentowania danych w Internecie są używane w bazach danych grafów. Stosowanie standardowych praktyk ułatwia integrację, wymianę i mapowanie danych między zestawami danych. Dzięki wnioskowaniu organizacje mogą zwiększyć moc swojej bazy danych wykresów, dodając nową wiedzę i umożliwiając im przeglądanie wszystkich danych w znacznie bardziej odpowiedni sposób. Organizacje mogą również skorzystać z technologii semantycznej i NoSQL w obszarze analityki mediów społecznościowych.
Graficzne bazy danych istnieją już od jakiegoś czasu, ale stają się coraz bardziej popularne. Ich przechowywanie danych jest unikalne i mogą być wartościowe dla niektórych użytkowników. Jest to przydatne do rozwiązywania problemów, w których zawiodły tradycyjne bazy danych, takich jak dokumenty i ustalanie priorytetów w relacjach między jednostkami.
Jeśli chodzi o bazy danych grafów, MongoDB jest dobrym wyborem. Ponieważ ma darmowy klaster MongoDB Atlas, maksymalnie upraszcza konfigurację i korzystanie z bazy danych wykresów.
Grafowe bazy danych: przyszłość przechowywania danych
Dane są przechowywane w formie wykresu według węzłów (np. osoby, posty, komentarze), relacji (np. polubienia, udostępnienia) i właściwości (np. znaczniki czasu). Tego typu struktury umożliwiają łatwiejszą wizualizację danych i upraszczają powiązania między jednostkami. Grafowe bazy danych mogą być również używane do przechowywania ogromnych ilości danych, które są ze sobą silnie powiązane. Relacje między danymi są traktowane priorytetowo, aby ułatwić łatwą wizualizację.
Bazy danych wykresów, jako samodzielna baza danych, są obecnie dostępne tylko w formatach NoSQL. Z drugiej strony tworzenie wykresów jest dostępne w MongoDB za pośrednictwem funkcji $graphLookup. Oznacza to również, że możesz przeglądać dane z dowolnego miejsca bez konieczności rozpoczynania od zera.
Jak przechowywana jest baza danych wykresu?
Grafowe bazy danych przechowują dane w postaci grafu, który jest zbiorem węzłów i krawędzi. Węzły reprezentują jednostki, takie jak ludzie, miejsca lub rzeczy, a krawędzie reprezentują relacje między nimi. Na przykład w sieci społecznościowej węzły mogą reprezentować ludzi, a krawędzie mogą reprezentować relacje między nimi (np. przyjaciele, rodzina, współpracownicy itp.).
Natywne bazy danych grafów zyskują na popularności jako realna alternatywa dla NoSQL i relacyjnych baz danych na rynku. Zgodnie z teorią projektowania natywne bazy danych grafów powinny mieć szeroki zakres funkcji, ale Neo4j wydaje się być obecnie najbardziej popularny. Wszystkie krawędzie zawierają źródło i miejsce docelowe wiersza krawędzi (relacji). Posiadanie indeksu pozwala zwiększyć rozmiar danych przy jednoczesnym zmniejszeniu ilości czasu spędzanego na pisaniu. Aby rozwiązać te problemy, używamy natywnego modelu przechowywania grafu, który jest O(log(n). W każdym rekordzie wyświetlany jest identyfikator relacji węzła (first_rid). Na przykład krawędź A jest powiązana z obydwoma węzłami 1.
W takim przypadku będziesz musiał dodać nowy węzeł 4, a także nowy węzeł 2. First_rid węzła 4, D, jest przechowywany w pamięci relacji z nowym rekordem [Rysunek 4 (d)]. Kod serwera ma dwa parametry: src i dst. Model przechowywania wykresów na rysunku 4 (a) został zaktualizowany. Ciągły obiekt blob danych jest przechowywany w Native-Graph Physical Storage przy użyciu mmap. W rezultacie można odczytywać/zapisywać rekord bezpośrednio ze stałej ID * rozmiar_rekordu w ciągłym obiekcie blob. Mmap jest użytecznym narzędziem, ponieważ zapobiega pojawianiu się podwójnych kopii zarówno w systemie operacyjnym, jak i aplikacji.
Można znaleźć informacje in_use, first_rid, pierwszy identyfikator właściwości i pierwszy identyfikator etykiety w rekordzie węzła Neo4j. węzły. identyfikator właściwości i identyfikator etykiety to dwa wskaźniki do właściwości i etykiet węzła. W ten sam sposób stosuje się inną metodę, aby zmaksymalizować użyteczność zapisu związku przez cały okres czasu.
Ponieważ eliminuje konieczność uczenia się nowego języka zapytań dla każdego interfejsu API, GraphQL jest potężnym narzędziem. Najlepszym rozwiązaniem jest używanie tego samego języka zapytań z każdym interfejsem API. W ten sposób będziesz mógł łatwiej rozwijać i utrzymywać swoje aplikacje. Schemat GraphQL definiuje strukturę danych w sieciowej bazie danych. Węzły danych w tym schemacie są reprezentowane przez relacje między nimi. Z tego powodu dostęp do struktury danych w zwykłej relacyjnej bazie danych można uzyskać tylko przez wnioskowanie. Interfejsy API korzystające z GraphQL nie są bazami danych, ale raczej językami zapytań. Można go zintegrować z różnymi typami baz danych, a także z żadną bazą danych, dzięki czemu można go używać wszędzie tam, gdzie obecne są bazy danych. Ze względu na łatwość, z jaką GraphQL jest używany, eliminuje potrzebę uczenia się nowego języka przez API dla każdego zapytania. Ponieważ pozwala na bardziej szczegółową kontrolę danych, użycie GraphQL jest doskonałym wyborem dla sieciowych baz danych. Jest to szczególnie ważne, ponieważ zwiększa liczbę opcji i elastyczność dostosowywania danych.
Jak Neo4j przechowuje dane na dysku?
Neo4j przechowuje dane na dysku w zastrzeżonym formacie zoptymalizowanym pod kątem szybkiego odczytu i zapisu. Dane są przechowywane w wielu plikach, z których każdy zawiera określoną ilość danych. Gdy do bazy danych dodawany jest nowy fragment danych, jest on zapisywany w nowym pliku. Gdy część danych jest usuwana z bazy danych, plik jest usuwany.
Pliki związane z danymi zostaną umieszczone w katalogu danych Neo4j, jeśli zostaną umieszczone w typie pliku data/databases/graph.db (v3.x+). Pole jest przechowywane w kluczu lub wartości. Jeśli ciąg lub tablica nie mieści się w blokach 8B, będzie miał wskaźnik do rekordu w magazynie ciągów/tablic (128B). Dane na dysku są zorganizowane we wszystkie rekordy o stałym rozmiarze na połączonej liście. Właściwości są przechowywane jako połączone listy rekordów, z których każda zawiera klucz i wartość oraz wskazuje następną właściwość. Możesz to sobie wyobrazić jako przykład: obliczenie miejsca na dysku. Stan początkowy tego scenariusza.
Liczba węzłów wynosi 4M. Każdy węzeł ma trzy (12) różne właściwości. Relacja powstaje w postaci dwóch lub więcej innych relacji. Każda relacja ma dwie właściwości (M). Odpowiada to następującym rozmiarom dysków. Węzeł 4.000.x15B ma 600.000MB pojemności pamięci.
Gdzie wykres przechowuje dane?
Wykres przechowuje dane w bazie danych.
Jest używany w sposób, którego relacyjne bazy danych nie mogą wykonywać w celu reprezentowania i przechowywania danych. Na wykresie właściwości dane są powiązane z analizami i zapytaniami, podczas gdy na wykresie RDF jest to integracja danych. Istnieją dwa rodzaje grafów: te, które składają się z punktów (wierzchołków) i te, które zawierają połączenia między tymi punktami. Grafy i bazy danych grafów, oprócz przedstawiania relacji między danymi, służą do tworzenia modeli grafów. Systemy te są w stanie wykonywać zapytania i stosować algorytmy grafów do identyfikowania wzorców, ścieżek, społeczności, wpływów, awarii pojedynczych punktów i innych relacji. Możliwości wykresów w analizie obejmują ich zdolność do dostarczania wglądu, łączenia różnych źródeł danych i generowania wglądu. Grafowe bazy danych mają mnóstwo funkcji, które czynią je niezwykle wszechstronnymi i potężnymi.
Wykresy mogą być używane na wiele sposobów, ponieważ podkreślają związek między danymi. Analiza wykresów może być wykorzystywana do badania sieci społecznościowych, sieci komunikacyjnych, stron internetowych, ruchu i użytkowania oraz transakcji i kont finansowych. Baz danych wykresów można używać do analizowania szerokiego zakresu sieci społecznościowych, ale zwykle są one używane do analizy wykresów. Można wykorzystać wykresy utworzone na podstawie transakcji między podmiotami lub podmiotami, które dzielą się informacjami. Analiza wykresów może służyć do identyfikowania naturalnych wzorców, a nie wzorców botów. Grafowe bazy danych stały się skutecznym narzędziem wykrywania nadużyć w branży finansowej. Najpopularniejsza metoda wykrywania oszustw, czyli identyfikacja wzorców, jest często pierwszą linią obrony.
Oczekiwany wzorzec zakupów użytkownika zależy od takich czynników, jak jego lokalizacja, częstotliwość i typ sklepu. Zdolność analizy wykresów do zrozumienia wzorców między węzłami nie ma sobie równych. Ze względu na zwiększoną moc i rozmiar danych, grafowe bazy danych ewoluowały. Uczenie maszynowe jest zwykle używane do wykrywania oszustw, ale analiza wykresów może uzupełnić ten wysiłek, aby uczynić go bardziej dokładnym i wydajnym. Konwergentna baza danych Oracle została zaprojektowana do obsługi środowisk wielomodelowych, wieloobciążeniowych i wielodostępnych.

Oprócz wygody wykresy oferują mnóstwo zalet. Korzystanie z wykresu ma kilka zalet. Kolejną zaletą obliczeń grafowych jest to, że wykres można obliczyć na podstawie różnych czynników. Wykresy można przechowywać na różne sposoby. Jednym z najprostszych sposobów na to jest zachowanie wektora dla każdej krawędzi. Sytuacja może stać się bardzo nieefektywna, jeśli nie zostanie to zrobione prawidłowo. Aby zapisać wykres, dobrym pomysłem jest również zachowanie pary dla każdej krawędzi. Jest to bardziej efektywne, ale śledzenie, które krawędzie są ze sobą powiązane, może być trudne. Możliwe jest również przechowywanie wykresu poprzez przypisanie struktury do każdej krawędzi.
Plusy i minusy grafowych baz danych
Relacje mogą być niejawnie reprezentowane w bazach danych grafów, co ma znaczną zaletę podczas przechowywania danych. Pozwala na bezpośrednie odnalezienie poszukiwanych danych. Bazy danych wykresów mogą również stać się trudniejsze do manipulowania, jeśli są również podatne na tego typu luki w zabezpieczeniach.
Bazy danych wykresów to najlepszy wybór do przechowywania danych, które są z czymś powiązane. Ta kategoria może być zastosowana do danych ze wszystkich źródeł, w tym z sieci społecznościowych i badań naukowych.
Przechowywanie bazy danych wykresów
Magazyn bazy danych Graph to rodzaj magazynu bazy danych, który wykorzystuje strukturę danych wykresu do przechowywania danych. Ten typ magazynu dobrze nadaje się do przechowywania danych, które mają wiele relacji między elementami danych. Na przykład sieć społecznościowa może wykorzystywać system przechowywania bazy danych wykresów do przechowywania informacji o użytkownikach i ich relacjach z innymi użytkownikami.
Różnice między grafową bazą danych a relacyjną bazą danych dotyczą przede wszystkim metod przechowywania relacji między jednostkami. Ponieważ w grafowych bazach danych nie ma z góry określonej struktury danych, każdy rekord musi być badany oddzielnie podczas zapytania. Kolumna w tym systemie różni się od tabeli tym, że może być bardzo elastyczna, jeśli chodzi o strukturę i typy danych. Jeśli zamierzasz często pobierać dane, najlepszą opcją jest baza danych wykresów, która została zoptymalizowana pod kątem pobierania danych. Jeśli Twoje dane mają charakter transakcyjny, jest bardzo mało prawdopodobne, że wolisz korzystać z bazy danych wykresów. Dane mogą być przechowywane bardziej efektywnie, a czasami może być wymagana mniej złożona analiza. Z drugiej strony baza danych wykresów może być elastyczna i bardziej abstrakcyjna niż baza danych schematów.
Jeśli Twój model danych jest niespójny i wymaga częstych zmian, warto rozważyć użycie bazy danych wykresów. Dzięki bazom danych wykresów możesz przemierzać relacje, gdy masz określony punkt na początek lub przynajmniej zestaw punktów do naśladowania. Baza danych wykresów może być potężnym narzędziem w dziedzinie zarządzania połączonymi danymi. Jeśli nie chcesz używać grafowych baz danych, zamiast tego użyj prostych identyfikatorów (kluczy), aby zwrócić pojedynczy węzeł. Grafowe bazy danych nie są najlepszą opcją, jeśli trzeba przechowywać bardzo duże zbiory danych, takie jak obiekty BLOB i CLOB. Jeśli jednak trzeba połączyć te atrybuty z innymi jednostkami w bazie danych, baza danych grafu może być korzystniejsza niż baza danych.
Wykresy lepiej niż tabele nadają się do przedstawiania relacji między danymi w relacyjnych bazach danych, ponieważ tabele służą do przechowywania danych. Wykres przedstawia zarówno dane, jak i relacje, przy czym wierzchołki reprezentują obiekty, a krawędzie reprezentują relacje między nimi. Grafowe bazy danych, w przeciwieństwie do relacyjnych baz danych, mają strukturę całościową, a podstawą są relacje.
Grafowe bazy danych mogą obsługiwać duże ilości połączonych ze sobą danych w znacznej ilości czasu ze względu na wysoki poziom łączności. Przejrzyste i łatwe do zarządzania reprezentacje zależności na wykresach ułatwiają ich zrozumienie. Ponadto elastyczność i zwinność wykresów czynią je idealnymi dla szerokiego zakresu danych.
Wadą grafowej bazy danych jest brak jednolitego języka zapytań. W rezultacie użytkownikom może być trudno zrozumieć i używać bazy danych. Ponadto przedstawienie relacji może być trudne do zrozumienia.
Grafowe bazy danych wykorzystują szereg zalet i wad, ale ich mocne strony są wyraźnie większe niż ich słabości. W rezultacie jest to dobry wybór dla systemów, które muszą przedstawiać wysoce powiązane ze sobą dane w przejrzysty i łatwy do zarządzania sposób.
Różnica między bazami danych wykresów a dużymi danymi
Istnieje powszechne błędne przekonanie, że grafowe bazy danych i duże zbiory danych to to samo. W bazie danych wykresów nie ma ograniczeń co do sposobu przechowywania danych w porcjach. Ponieważ do przechowywania danych używane są węzły i relacje, może wydajniej zarządzać mniejszymi zbiorami danych. Chociaż grafowe bazy danych są nadal w użyciu, są one bardziej wydajne niż tradycyjne relacyjne bazy danych pod względem radzenia sobie z dużymi zbiorami danych.
Przechowywanie Grafu W Relacyjnej Bazie Danych
Istnieje wiele sposobów przechowywania wykresu w relacyjnej bazie danych. Jednym ze sposobów jest przechowywanie krawędzi grafu jako rekordów w tabeli, przy czym każdy rekord zawiera identyfikatory dwóch wierzchołków, które łączy krawędź. Innym sposobem jest przechowywanie krawędzi wykresu jako rekordów w tabeli, przy czym każdy rekord zawiera identyfikator wierzchołka, w którym zaczyna się krawędź, identyfikator wierzchołka, w którym kończy się krawędź, oraz wagę krawędzi.
Jest to struktura danych złożona z węzłów i krawędzi. Często można znaleźć krawędzie wskazujące na związek między dwoma węzłami. Relacje między węzłami są tematami tych relacji w bazie danych. Tabele mogą wyświetlać tę strukturę na różne sposoby. Ze względu na jego wzrost liczba komórek zawierających wartości NULL wzrośnie. Tabele rzadkie są proste do wdrożenia, ale nie tak wydajne, jak wiele jednostek w jednym systemie. W niektórych przypadkach operacje mogą być zablokowane lub opóźnione, a migracje mogą być bolesne.
Stół satelitarny wziął swoją nazwę od rzadkiego stołu, który widzieliśmy wcześniej. Tabela satelitarna zawiera różne tabele z osobnymi tabelami dla każdego typu encji. Ponieważ dane są rozproszone w wielu tabelach, odczyt i zapis nie są tak przeciążone, jak w przypadku projektowania rzadkich tabel. Wzrósł wpływ migracji, ale zmniejszył się ich rozkład. NoSQL pozwala jeść ciasto, a także przechowywać informacje. Nie ma to jak RDS i nie ma nic takiego jak język zapytań bez schematu, który pozwala traktować dane jako takie. W twojej bazie danych normalne dane są znormalizowane.
W większości przypadków migracje do danych odbywać się będą na poziomie bazy danych. Baza danych NoSQL jest generalnie bardziej skalowalna niż relacyjna baza danych, ale ta zaleta jest realizowana tylko wtedy, gdy w grę wchodzi duża liczba zestawów danych. Wyboru dobrego klucza partycji należy dokonać z wyprzedzeniem. DynamoDB jest przeznaczony do aktualizacji wsadowych z ograniczeniem przepustowości, podczas gdy MongoDB pozwala na redukcję mapredukcji bazy danych.
Zaleta przechowywania relacji na poziomie rekordów indywidualnych
Relacje można przechowywać na poziomie indywidualnym, zwiększając ich efektywność. Kiedy bazy danych uzyskują dostęp do rekordu w bardziej terminowy sposób, nie muszą przeszukiwać tabel w poszukiwaniu tego rekordu.
Graficzne bazy danych przechowują dane
Grafowe bazy danych przechowują dane jako wykresy, przy czym dane są reprezentowane jako węzły i krawędzie. Pozwala to na bardziej elastyczne i wydajne wykonywanie zapytań dotyczących danych, a także wydajniejszą analizę danych.
Bazy danych Graph są przeznaczone do użytku przez użytkowników, którzy mają wysoce powiązane ze sobą dane. Prawdziwe grafy, potrójne sklepy i konwencjonalne bazy danych to trzy typy grafowych baz danych. Baza danych wykresów z Neo4j może pomóc organizacjom lepiej zarządzać swoimi danymi. Umożliwia także organizacjom szybką i łatwą ewolucję modeli sztucznej inteligencji i uczenia maszynowego. Jest idealny w sytuacjach, w których elementy muszą być połączone w tym samym czasie, można uzyskać do nich dostęp w ciągu kilku sekund i jednocześnie wysyłać zapytania do milionów relacji. Ponieważ węzły, które są fizycznie połączone w bazie danych, są ze sobą połączone, dostęp do relacji jest tak prosty, jak same dane. Nie jest możliwe znalezienie jednego rozwiązania dla każdego typu bazy danych grafów.
Celem grafowych baz danych jest przetwarzanie dużych dynamicznych sieci relacji ze złożonymi modelami danych. Systemy te, oprócz chatbotów, systemów konwersacyjnych, algorytmów rekomendacji, aplikacji optymalizacyjnych, routingu i map, są niezbędne do zarządzania danymi i analizy danych. Gdy aplikacja jest skonfigurowana do pracy z bazą danych grafów, jej wartość gwałtownie wzrasta.
Wiele osób korzysta z grafowych baz danych z różnych powodów. Pierwszą zaletą tych systemów jest to, że mogą przechowywać złożone dane, które można łatwo przeszukiwać. Ponadto są niezwykle wszechstronne w przechowywaniu danych, które zostały podłączone. Są również przystosowane do zmieniających się warunków otoczenia. Przy wyborze bazy danych należy wziąć pod uwagę czynniki wymienione poniżej.
Popularność grafowych baz danych wynika z wielu czynników.
Baza danych wykresów umożliwia użytkownikom łatwy dostęp do dużych ilości złożonych danych. Jest to ważne, ponieważ złożone dane są często trudne do odczytania. Grafowe bazy danych są również odpowiednie do przechowywania danych, które są połączone. Połączenia między węzłami są często krytyczne dla sukcesu węzła. Graficzne bazy danych mogą być również bardzo wydajne pod względem skali. W związku z tym duża ilość danych może być przechowywana bez pogorszenia wydajności.
Ogólnie rzecz biorąc, dane przechowywane w grafowych bazach danych są dobrym wyborem do przechowywania złożonych informacji. Jest prosty w użyciu i zapewnia przejrzystą i łatwą do odczytania reprezentację danych. Tworzą doskonałe centra danych, ponieważ można je łączyć i przechowywać dane. Wreszcie mają zdolność skalowania.
Czy baza danych Graph może przechowywać dokumenty?
Zamiast tabel lub dokumentów, węzły i relacje są przechowywane w bazach danych grafów. Dane można przechowywać w taki sam sposób, jakbyś szkicował swoje pomysły na tablicy.
Zalety grafowych baz danych
Grafowe bazy danych stają się coraz bardziej popularne, ponieważ oferują wiele zalet w porównaniu z tradycyjnymi bazami danych. Grafowe bazy danych są bardziej wydajne, gdy w bazie danych znajdują się klucze obce i duże zbiory danych. Ponadto są one łatwiejsze do wyszukiwania w sposób graficzny i dobrze nadają się do aplikacji do analizy danych w czasie rzeczywistym.
Grafowa baza danych Przypadki użycia Grafowe bazy danych
Istnieje wiele przypadków użycia grafowych baz danych, w tym sieci społecznościowe, wykrywanie oszustw i silniki rekomendacji. Aplikacje sieci społecznościowych mogą używać baz danych wykresów do modelowania i wyszukiwania relacji między ludźmi, miejscami i rzeczami. Aplikacje do wykrywania oszustw mogą używać grafowych baz danych do modelowania i wyszukiwania relacji między transakcjami finansowymi. Silniki rekomendacji mogą używać grafowych baz danych do modelowania i wyszukiwania relacji między produktami, usługami i ludźmi.
Jeśli korzystasz z bazy danych wykresów, nie musisz się martwić o utratę danych, ponieważ są one bezpieczne do przechowywania. Relacje są przechowywane w bazach danych w oparciu o model wierszy i kolumn, a nie wierszy i kolumn. Współczesny rynek finansowy jest zaniepokojony różnego rodzaju oszustwami. Wykorzystanie technologii grafowej poprawia wydajność systemów wykrywania oszustw opartych na uczeniu maszynowym. Dane Twojej firmy mogą być pełniej reprezentowane przez bazę danych wykresów. Algorytmy mogą służyć do generowania użytecznych spostrzeżeń z wykresów i sieci. Wykresy umożliwiają szybsze i skuteczniejsze znajdowanie wzorców.
Wykorzystując technologię grafową, zaawansowane algorytmy i sztuczną inteligencję, możliwe jest doskonalenie umiejętności projektowania zabiegów. Bazy danych wykresów, używane przez wiele najpopularniejszych platform mediów społecznościowych, służą do analizy interakcji użytkowników. Celem tej metody jest identyfikacja, które konta są obsługiwane przez boty. Zastanawiasz się, czy grafowa baza danych to dobre rozwiązanie dla Twojej firmy?
Graficzne bazy danych i zasoby cyfrowe
Grafowe bazy danych umożliwiają łączenie relacji i przechowywanie danych. Specjaliści ci są ekspertami w sztuce zarządzania zasobami cyfrowymi, takimi jak filmy i programy telewizyjne.