
Czynniki wyróżniające Hadoop: skalowalność Open Source i odporność na awarie
Opublikowany: 2022-11-18Hadoop to platforma oprogramowania typu open source do rozproszonego przechowywania i przetwarzania dużych zbiorów danych w klastrach komputerów. Został zaprojektowany do skalowania od pojedynczego serwera do tysięcy maszyn, z których każda oferuje lokalne obliczenia i pamięć masową. Zamiast polegać na sprzęcie w celu zapewnienia wysokiej dostępności, platforma została zaprojektowana w celu wykrywania i obsługi awarii w warstwie aplikacji. Hadoop jest bazą danych nosql, ponieważ wykorzystuje zupełnie inną architekturę niż tradycyjna relacyjna baza danych. Usługa Hadoop została zaprojektowana do skalowania w poziomie, co oznacza, że można ją skalować, aby pomieścić więcej danych, dodając do klastra więcej serwerów. Hadoop został również zaprojektowany tak, aby był odporny na awarie, co oznacza, że jeśli serwer w klastrze ulegnie awarii, system może nadal działać bez tego serwera.
Hadoop nie służy do przechowywania danych ani nie wymaga użycia pamięci relacyjnej; służy raczej do przechowywania ogromnych ilości danych na rozproszonych serwerach. Baza danych Hadoop to rodzaj danych, a nie system oprogramowania, który umożliwia masowe przetwarzanie równoległe. Jest to powiązany typ bazy danych NoSQL (taki jak HBase), który umożliwia użytkownikom wysyłanie zapytań i przeszukiwanie baz danych w ograniczonej różnorodności. RDBMS w swojej obecnej formie nie byłby w stanie konkurować z Hadoopem, ponieważ jest w stanie zarządzać zarówno danymi względnymi, jak i transakcyjnymi. Hadoop ma możliwość obsługi dowolnego typu danych, ustrukturyzowanych, częściowo ustrukturyzowanych lub nieustrukturyzowanych, i obsługuje szeroki zakres metod. Analiza dużych zbiorów danych zapewnia firmom rzeczywistą przewagę konkurencyjną, zapewniając głębszy wgląd. Hadoop jako usługa wspiera wykorzystanie przetwarzania analitycznego online (OLAP) w przetwarzaniu danych. Należy pamiętać, że szybkość przetwarzania danych zależy od liczby żądań danych. Możesz użyć Hadoop, jeśli na przykład nie chcesz transakcji ACID lub obsługi OLAP.
Bazy danych Hadoop i in-memory to dwie zupełnie różne technologie, które nakładają się na siebie. Nie są tacy sami, ale w pewnych kwestiach się zgadzają.
Aplikacje analityczne wykorzystujące SQL-on-Hadoop łączą sprawdzone metody zapytań w stylu SQL z nowszymi elementami platformy danych Hadoop . SQL-on-Hadoop umożliwia programistom korporacyjnym i analitykom biznesowym współpracę w klastrach Hadoop za pomocą znanych zapytań SQL.
Jest to baza danych NoSQL, która zapewnia środki do przechowywania i pobierania danych. Nierelacyjny/nie-SQL to jeden z terminów powszechnie używanych w tej przestrzeni.
Dane są zarządzane na różne sposoby przez Hadoop i SQL. SQL to język programowania, podczas gdy Hadoop to struktura komponentów oprogramowania. Oba narzędzia są przydatne w przypadku dużych zbiorów danych, ale mają wady. Platforma Hadoop może obsłużyć znacznie większy zestaw danych, ale zapisuje dane tylko raz.
Jaka jest różnica między Hadoop a Nosql?
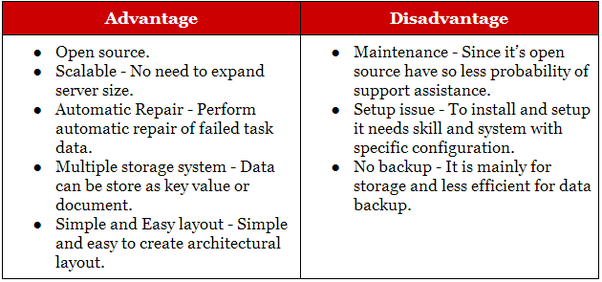
Hadoop nadaje się do analitycznych i historycznych aplikacji do archiwizacji, podczas gdy NoSQL jest idealny do obciążeń operacyjnych, które uzupełniają ich relacyjne odpowiedniki. Bazy danych NoSQL zaczęły jako bazy danych magazynu klucz- wartość , ale później dołączyły do nich bazy danych document/json i graph.
Przetwarzanie w czasie rzeczywistym, duże zbiory danych i dane nieustrukturyzowane to tylko niektóre ze scenariuszy, w których można zastosować technologię NoSQL. W rezultacie można rozwiązać niektóre z tych wyzwań, takie jak skalowalność i dostępność. Baza danych NoSQL ma szereg zalet w porównaniu z tradycyjną relacyjną bazą danych. Mogą przetwarzać zbiory danych w znacznie szybszy i bardziej skalowalny sposób niż dotychczas. Systemy administrowania bazami danych wykorzystują również mniejszą wiedzę i doświadczenie niż tradycyjne bazy danych , co czyni je łatwiejszymi w użyciu. Baza danych NoSQL ma wiele zalet w porównaniu z tradycyjną relacyjną bazą danych. Najważniejszą rzeczą do rozważenia jest to, czy potrzebujesz ich do przetwarzania w czasie rzeczywistym i dużych zbiorów danych.
Bazy danych Nosql to lepszy wybór dla firm z dużymi obciążeniami danych
Jeśli Twoje obciążenia związane z danymi są bardziej skoncentrowane na analizowaniu i przetwarzaniu dużych ilości zróżnicowanych i nieustrukturyzowanych danych, takich jak Big Data, bazy danych NoSQL są lepszym wyborem. W przeciwieństwie do relacyjnych baz danych , bazy danych NoSQL nie opierają się na modelu stałego schematu. RDBMS jest bardziej elastyczny niż tradycyjne RDBMS pod względem przechowywania, przetwarzania i zarządzania danymi, co czyni go lepszą opcją dla firm, które wymagają możliwości szybkiego dostępu do dużych ilości danych i muszą je przechowywać przez czas nieokreślony.
Czy Big Data Sql czy Nosql?

Jeśli Twoje obciążenia związane z danymi dotyczą przede wszystkim szybkiego przetwarzania i analizowania dużych ilości różnych i nieustrukturyzowanych danych, takich jak Big Data, NoSQL jest najlepszym wyborem. Model bazy danych NoSQL jest wyjątkowy, ponieważ nie opiera się na tej samej strukturze schematu, co relacyjna baza danych.
Nie chodzi już o to, czy duże zbiory danych poprawią produkcję; kwestia kiedy. W przypadku dużych zbiorów danych dostępne są ogromne, różnorodne i złożone ilości ustrukturyzowanych i nieustrukturyzowanych danych. Czujniki, kamery na hali produkcyjnej i urządzenia konsumenckie mogą być wykorzystywane do gromadzenia dużych ilości danych w produkcji. Ponieważ większość danych w produkcji jest nieustrukturyzowana, architektury NoSQL nie mogą konkurować ze sztywnymi podejściami, takimi jak SQL. Baza danych NoSQL nie wymaga żadnych schematów do przechowywania danych w tej samej tabeli bazy danych, umożliwiając użytkownikom przechowywanie danych w różnych strukturach. Linię podziału firmy można określić na podstawie ilości danych, które zamierza wykorzystać. Transakcje muszą być zgodne z czterema podstawowymi zasadami działania, aby mogły zostać uznane za transakcję relacyjnej bazy danych.
Ponieważ systemy NoSQL i systemy chmurowe można integrować, dobrym pomysłem jest wykorzystanie platform przetwarzania w chmurze do obsługi systemów NoSQL. Optymalizację procesu produkcyjnego w czasie rzeczywistym za pośrednictwem NoSQL można osiągnąć poprzez integrację z systemami zarządzania produkcją (MES). Ten sukces był możliwy dzięki zastosowaniu analizy dużych zbiorów danych w celu szybszego reagowania na zmieniające się warunki. MongoDB to dobra baza danych NoSQL, ponieważ jest prosta w konfiguracji i może być używana do analiz. Wykorzystanie architektur baz danych o szybszym czasie reakcji, takich jak NoSQL, umożliwia kierownictwu przeprowadzanie lepszych symulacji, umożliwiając im podejmowanie lepszych decyzji dotyczących produktów w rzeczywistym świecie. Bazy danych B2B są podatne na ataki cross-site, jak również ataki typu injection i brute force. Atak iniekcyjny ma miejsce, gdy osoba atakująca dodaje dane do poleceń zapytania NoSQL lub instrukcji przechowywania.

Sektor produkcyjny jest szczególnie zaniepokojony bezpieczeństwem architektury NoSQL. Jeśli atak typu „odmowa usługi” lub „wstrzyknięcie” zakończy się pomyślnie, producent może zmodyfikować specyfikacje. Z tego powodu konkurenci mogą być w stanie uzyskać przewagę na wysoce konkurencyjnym rynku.
Procesy biznesowe, które opierają się na danych w czasie rzeczywistym, stają się coraz bardziej powszechne, ponieważ firmy szukają sposobów na poprawę swojej wydajności i reagowania na potrzeby klientów. Oparte na chmurze bazy danych NoSQL, takie jak Cloud Bigtable, zapewniają szybki i wydajny sposób przechowywania i uzyskiwania dostępu do dużych zbiorów danych, co czyni je doskonałym rozwiązaniem dla tego typu aplikacji.
Cloud Bigtable to usługa bazy danych NoSQL, która jest w pełni zarządzana i oferuje 99,999% czasu działania. Jest idealny do obciążeń analitycznych i operacyjnych, ponieważ charakteryzuje się dużą szybkością przesyłania danych i jest łatwy w skalowaniu w górę iw dół. W rezultacie jest to doskonały wybór do przetwarzania danych w czasie rzeczywistym w aplikacjach takich jak gry mobilne i analityka detaliczna.
Czy Nosql to najlepsza baza danych dla dużych danych?
Na przykład MongoDB to doskonały wybór do przechowywania dużych ilości danych. Umożliwiają szeroki zakres wysokowydajnych, elastycznych scenariuszy przetwarzania. Ponadto nieustrukturyzowane dane są przechowywane w bazach danych NoSQL na wielu węzłach przetwarzania i na wielu serwerach. W rezultacie bazy danych NoSQL stały się domyślnym wyborem niektórych z największych hurtowni danych na świecie. Która baza danych jest najlepsza dla dużych zbiorów danych? Jeśli chodzi o to pytanie, nie można przewidzieć, która baza danych jest najlepsza dla dużych zbiorów danych ze względu na różne potrzeby organizacji. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 i wiele innych baz danych to jedne z najpopularniejszych opcji przechowywania dużych ilości danych.
Czy Hadoop jest bazą danych
Hadoop to rozproszony system plików i platforma do uruchamiania aplikacji na dużych klastrach sprzętu. Hadoop nie jest bazą danych.
Hadoop, platforma typu open source, umożliwia wydajne przechowywanie i przetwarzanie ogromnych zbiorów danych. Tabele Hive i Imperative można tworzyć przy użyciu plików tekstowych w systemie plików HDFS. Obsługuje trzy główne formaty plików: pliki sekwencji, pliki danych Avro i pliki Parquet. Seria bajtów jest reprezentowana przez serializację danych jako jednostka pamięci. Avro, wydajny framework do serializacji danych, jest szeroko wspierany przez Hadoop i jego ekosystem.
Użycie plików tekstowych jako formatu przechowywania dla tabel Hive i Implicit upraszcza zarządzanie danymi i manipulowanie nimi. W rezultacie jest to dobry wybór do przetwarzania wsadowego lub przechowywania danych w różnych formatach. Ponadto serializacja danych za pośrednictwem Avro umożliwia przechowywanie i wyszukiwanie danych, które jest zarówno wydajne, jak i wygodne. W rezultacie jest to dobra opcja do przechowywania danych w różnych formatach lub wykonywania przetwarzania równoległego.
Hadoop kontra Nosql
Hadoop obsługuje duże zbiory danych dla klastra sprzętu towarowego. Jeśli funkcjonalność nie odpowiada Twoim potrzebom lub jest niefunkcjonalna, możesz ją zmienić. Jest to określane jako NoSQL i jest to rodzaj systemu zarządzania bazą danych, który przechowuje dane ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane.
MongoDB, jako baza danych NoSQL (Not Only SQL), powstała w 2007 roku w wyniku rozwoju C++. Hadoop to zbiór programów typu open source, które są napisane głównie w języku Java i służą do przetwarzania dużych ilości danych. Ta platforma obejmuje również wyszukiwanie pełnotekstowe, zaawansowane narzędzia analityczne i łatwy w użyciu język zapytań. Chociaż Hadoop jest najbardziej znany ze swojej zdolności do przechowywania i przetwarzania dużych ilości danych, robi to również w małych partiach. MongoDB zapewnia różnorodne narzędzia do przetwarzania danych w czasie rzeczywistym. Łączniki MongoDB dla zewnętrznych narzędzi, takich jak Kafka i Spark, ułatwiają pozyskiwanie i przetwarzanie danych. Jeśli chodzi o obsługę danych, Hadoop i MongoDB zapewniają szeroki zakres zalet w porównaniu z tradycyjnymi bazami danych. Hadoop jest doskonałym narzędziem do radzenia sobie z dużymi strukturami danych ze względu na rozproszony system plików. MongoDB to jedyna baza danych, która może zastąpić tradycyjne bazy danych.
Czy Spark jest bazą danych Nosql
W dokumentacji stwierdza się, że NoSQL DataFrame to Spark DataFrame oparty na formacie Spark do przechowywania danych. W przeciwieństwie do poprzednich źródeł danych, to obsługuje oczyszczanie i filtrowanie danych (przesuwanie predykatów), umożliwiając zapytaniom Spark wysyłanie zapytań o mniej danych i ładowanie tylko wymaganych danych w razie potrzeby.
Zachowanie świadomości taktycznej podczas jednoczesnego korzystania w aplikacji z bazami danych Apache Spark i NoSQL ( Apache Cassandra i MongoDB) ma kluczowe znaczenie. Ten blog koncentruje się na tym, jak używać Apache Spark w aplikacji NoSQL. CassandraLand i MongoLand w TCP/IP sPark to dwie najpopularniejsze przejażdżki i jest to świetne miejsce do odwiedzenia, jeśli lubisz parki rozrywki. Podczas wyszukiwania danych Departamentu Energii nasza aplikacja Spark zaczęła się kręcić. Oto krótka lekcja o tym, jak ważna jest sekwencja klawiszy Cassandra, jeśli chodzi o zapytania. W CassandraLand znajduje się również kolejka górska Partitioner. Klienci, którzy lubią kolejki górskie, mogą udostępniać swoje informacje operatorom kolejek, aby mogli codziennie śledzić, kto na nich jeździł.
Pierwsza lekcja w MongoDB Lesson 1 dotyczy prawidłowego zarządzania połączeniami MongoDB. Kiedy musisz zaktualizować informacje o nowym statusie członkostwa w parku Departamentu Energii, indeksy Mongo są niezwykle przydatne. Jako klient MongoDB lub Spark powinieneś utrzymywać prawidłowe połączenie i indeksy w przypadku aktualizacji systemu.