
Format danych HDF5: atrakcyjna opcja przechowywania i zarządzania dużymi zbiorami danych
Opublikowany: 2023-02-13HDF5 to format danych przeznaczony do przechowywania i zarządzania dużymi, złożonymi zbiorami danych. Jest często używany w zastosowaniach naukowych i inżynieryjnych, a jego popularność rośnie w ostatnich latach. HDF5 nie jest bazą danych, ale może służyć do przechowywania danych w formacie hierarchicznym , podobnym do systemu plików. To sprawia, że HDF5 jest atrakcyjną opcją dla aplikacji, które muszą przechowywać duże ilości danych i zarządzać nimi.
Możesz wyodrębnić metadane i surowe dane z plików HDF5 i netCDF4 oraz użyć strumieniowania Hadoop do analizy danych Hadoop za pomocą wirtualnego sterownika plików (VFD) HDF5 Connector HDF5 Hadoop.
Czy Hdf5 jest bazą danych?
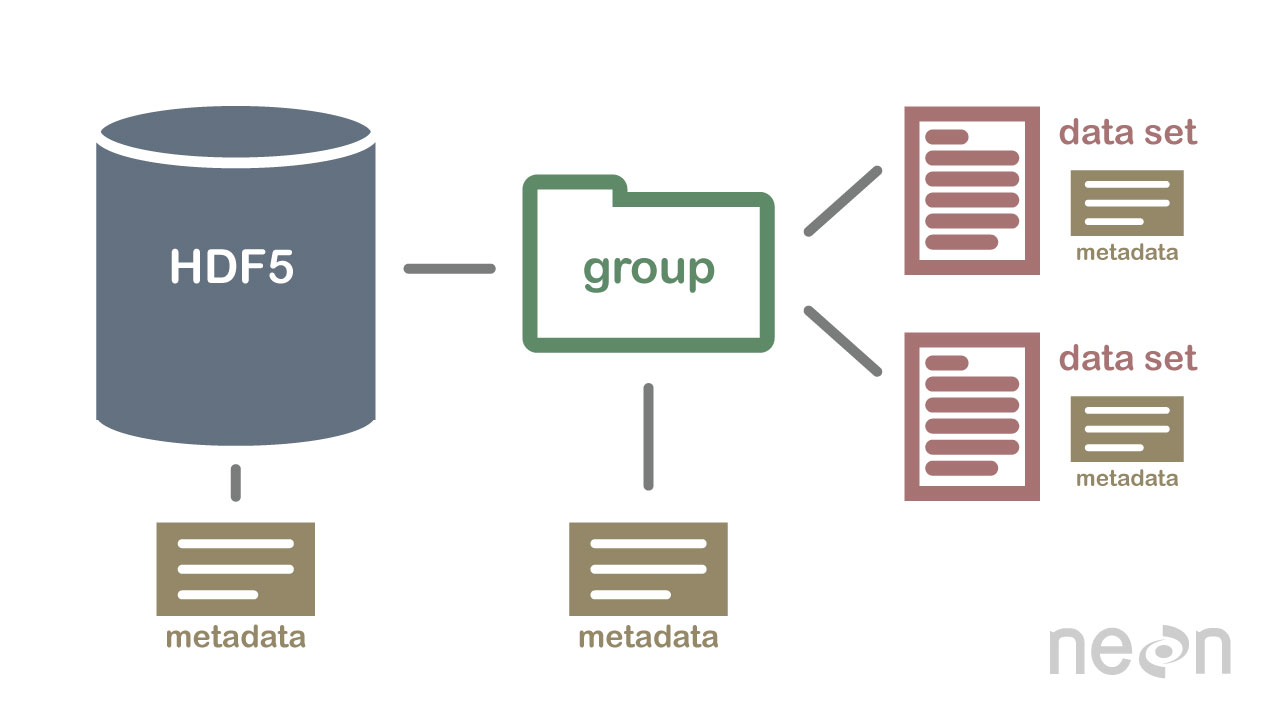
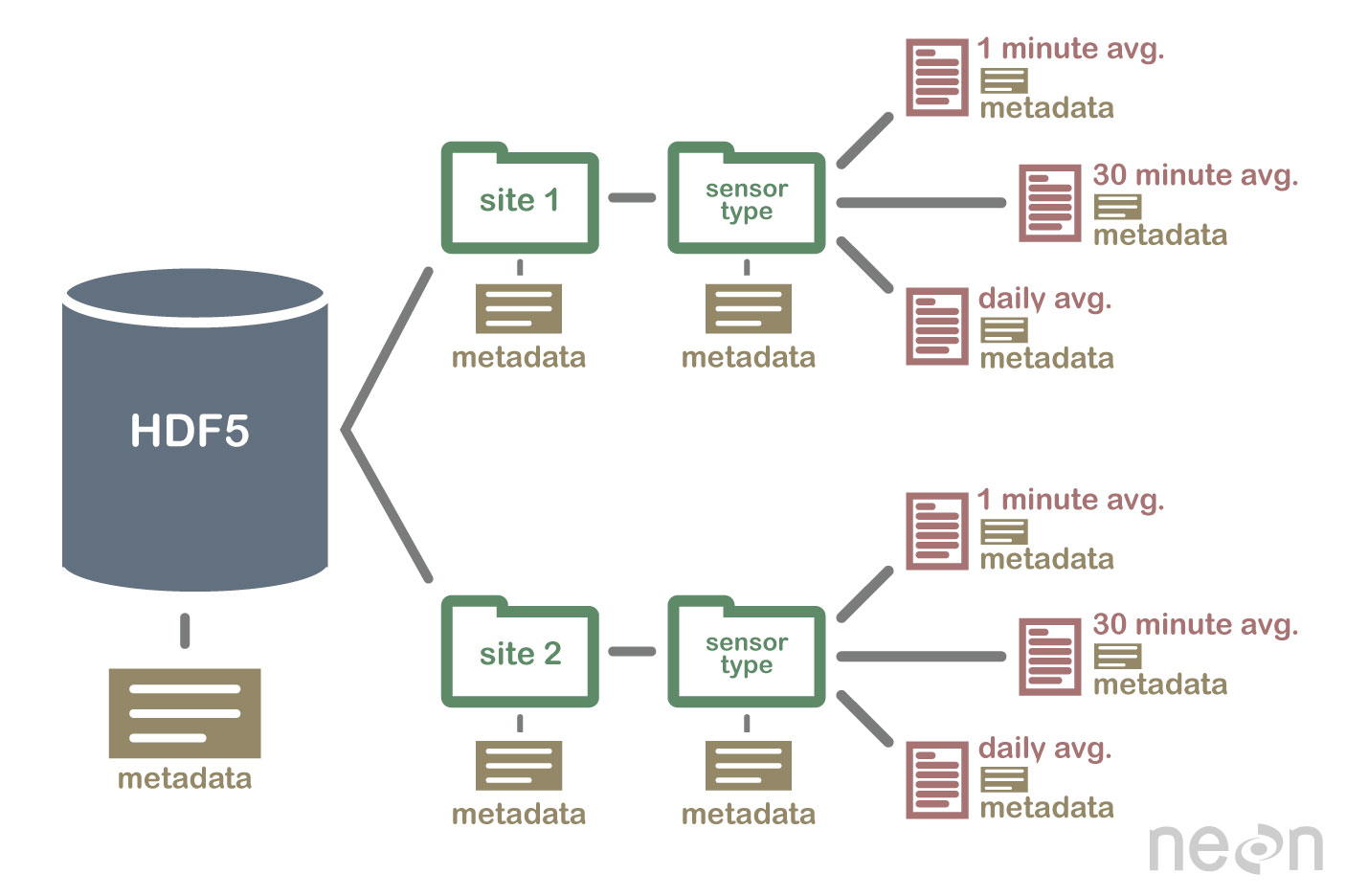
HDF5 nie jest bazą danych, ale może służyć do przechowywania danych w strukturze hierarchicznej, podobnej do systemu plików. HDF5 może być używany do przechowywania danych w różnych formatach, w tym tekstu, obrazów i danych binarnych .
Dane w formacie hierarchicznym (HDF5) są niezwykle przydatne w badaniach naukowych. System plików HDF5, ponieważ jest podobny do systemu plików w sposobie, w jaki jest bardzo wydajny, jest doskonałym formatem. Jeśli chodzi o dane zakodowane w tym formacie, dostęp do nich może być trudny. Ten przewodnik przeprowadzi Cię przez proces, w jaki Apache Drill może pomóc w łatwym dostępie do zestawów danych HDf5 i zapytaniu o nie. Drill ma dostęp do poszczególnych plików HDF5 poprzez opcję defaultPath. Osiąga się to poprzez bezpośrednie wykonanie funkcji table() podczas zapytania lub poprzez konfigurację. Wyniki tego zapytania można znaleźć w poniższej tabeli. Drill może następnie wybrać kolumny i filtrować je pojedynczo, filtrować, agregować lub łączyć z innymi danymi, które może wyszukiwać.
Specyfikacja HDF5 definiuje format pliku do przechowywania tablic danych. Tablica danych może składać się z dowolnego typu danych, w tym danych łańcuchowych, zmiennoprzecinkowych, złożonych i liczb całkowitych. Tablica może zawierać dane dowolnego rozmiaru i może mieć dowolny kształt. W HDF5 należy najpierw utworzyć plik nagłówkowy, aby utworzyć zbiór danych. Plik nagłówkowy zawiera informacje o zbiorze danych oraz metadane. Plik nagłówkowy zawiera dwie ważne informacje: nazwę zestawu danych i numer wersji zestawu danych. Tablica danych służy do przechowywania danych zestawu danych. Bloki składają się z danych w tablicy danych. W tablicy danych każdy blok danych zawiera ciągły zestaw danych. Liczba bloków zestawu danych jest określana przez liczbę zawartych w nim bajtów. Dostęp do danych można uzyskać na wiele sposobów zgodnie ze specyfikacją HDF5. metody indeksowania są najczęściej używane do uzyskiwania danych w zbiorze danych. Korzystając z tych metod, możesz uzyskać dostęp do danych, wprowadzając nazwę bloku w tablicy danych, do którego chcesz uzyskać dostęp. Metoda struktury może służyć do uzyskiwania dostępu do danych w zbiorze danych. Korzystając z tych metod, można uzyskać dostęp do danych przy użyciu struktury tablicy danych. W poniższym przykładzie można uzyskać dostęp do danych w tablicy danych przy użyciu wartości przesunięcia i długości metody struktury. Innym sposobem uzyskiwania danych ze zbioru danych jest użycie metod funkcyjnych. Dane można uzyskać, korzystając z jednej z metod, wybierając funkcję w pliku nagłówkowym danych. Metodę dostępu do tablicy danych można wykorzystać, definiując wartość w pliku nagłówkowym jako element tablicy danych tablicy. Na koniec można uzyskać dostęp do danych w zbiorze danych przy użyciu metody dostępu. Korzystając z tych metod, można uzyskać dostęp do danych przy użyciu uprawnień dostępu ustawionych w pliku nagłówkowym. Innymi słowy, korzystając z uprawnienia do odczytu, można uzyskać dostęp do danych w tablicy danych za pomocą metody dostępu. Dane mogą być tworzone i wykorzystywane na różne sposoby przy użyciu specyfikacji HDF5. Metoda create jest najczęstszą metodą tworzenia zestawu danych. Korzystając z metody create, możesz utworzyć zestaw danych, wprowadzając nazwę zestawu danych i numer wersji zestawu danych. Oprócz specyfikacji HDF5, wykorzystanie zbiorów danych można osiągnąć na różne sposoby. Najczęściej stosowana metoda.

Czy Hdf5 to relacyjna baza danych?
HDF5 nie jest relacyjną bazą danych.
Czy Graphql Nosql czy Sql?
Głównym celem GraphQL jest wykorzystanie systemu typów do szybszego i wydajniejszego zwracania danych. SQL (strukturalny język zapytań) to starszy, szerzej używany język do przechowywania danych w tabelarycznych lub relacyjnych systemach baz danych . Jeśli chcesz, aby Twoje API było zbudowane na podstawie bazy danych NoSQL, dobrym pomysłem byłoby pracować z GraphQL.
The Type Mismatch to baza danych GraphQL i NoSQL stworzona przez Hermana Camarenę i Rogera Cochrane'a. Użycie GraphQL może skutkować wprowadzeniem systemu typów zamiast systemu NoSQL, eliminując elastyczność stworzoną przez systemy NoSQL. Kolekcja GraphQL zawiera szeroką gamę dokumentów, które mają spójną strukturę i zawierają kilka wyjątków. Ponieważ GraphQL ma wbudowany zestaw typów danych , które pasują do typów backendów, programiści mogą wybrać typy danych do utworzenia. GraphQL powinien zająć się kwestią niezgodności typów, aby w pełni wykorzystać swój potencjał. Pod względem swoich funkcji zapewnia rozwiązanie niedopasowania niższego poziomu ze względu na wiele zalet. Praca jest coraz bardziej zautomatyzowana dzięki narzędziom takim jak JSON2SDL firmy StepZen.
Jest to potężne narzędzie, które można wykorzystać do tworzenia bardziej odpornych i wydajnych aplikacji, ale SQL nie jest substytutem. Jeśli chodzi o konserwację, może to mieć negatywny wpływ, ponieważ utrudnia niektóre zadania.
Graphql: język zapytań dla dowolnej bazy danych
Język zapytań GraphQL pozwala klientom i serwerom komunikować się ze sobą. Instancja GraphQL może pobierać i utrwalać zmiany ze źródła danych lub stanu trwałego. Resolwer to zestaw dowolnych funkcji używanych do uzyskiwania dostępu do danych i manipulowania nimi. API jest dostępne w różnych bazach danych, a GraphQL może być używany z dowolną. Baza danych MongoDB to popularna baza danych źródła danych , która jest niezależna od różnych typów danych.
Czy Nosql używa drzew B?
Bazy danych NOSQL nie używają drzew B, ponieważ nie są oparte na modelu relacyjnym. Bazy danych NOSQL są często oparte na parach klucz-wartość, magazynach dokumentów lub bazach danych grafów.
B-drzewa to domyślna struktura indeksowania w MongoDB. W przypadku przechowywania danych B-drzewo jest bardziej wydajną metodą. Dane można organizować za pomocą liczb całkowitych i łańcuchów, jeśli są one używane razem. W rezultacie bazy danych z dużą ilością danych powinny rozważyć jej użycie. Ponieważ drzewa B mogą zajmować dużo miejsca, są wydajnym modelem. Jest to korzystne w przypadku baz danych, które muszą przechowywać dużą ilość danych. B-drzewa są również dobrym wyborem dla baz danych, które muszą organizować dane w określony sposób.
Która baza danych używa B-drzewa?
Istnieje od dawna i może być używany w wielu bazach danych. Bazy danych NoSQL można budować na silnikach B-drzewa, oprócz silników B-drzewa. Na przykład MongoDB indeksuje dane w B-drzewach. Algorytm jest taki sam dla DBMS, jak dla relacyjnej bazy danych, chociaż istnieją pewne wyjątki. Łańcuchy i liczby całkowite mogą być używane do organizowania danych w B-drzewie.
Która baza danych używa B-drzewa? Mysql w poniższym artykule wykorzystuje zarówno Btree, jak i B+tree. SQL Server przechowuje indeksy na podstawie utrwalonych danych opartych na kluczach w postaci BTree. W rezultacie każdy węzeł w takim drzewie pojawia się jako pojedyncza strona.