
Baza danych Oracle NoSQL
Opublikowany: 2022-12-17Baza danych Oracle NoSQL to rozproszona baza danych typu klucz-wartość. Został zaprojektowany w celu zapewnienia skalowalnego, wydajnego zarządzania danymi przy zachowaniu prostego interfejsu. Baza danych Oracle NoSQL jest zbudowana na bazie Oracle Berkeley DB Java Edition, która zapewnia wydajny, wbudowany silnik bazy danych. Baza danych Oracle NoSQL jest dostępna jako obraz maszyny wirtualnej do pobrania lub jako usługa w chmurze.
In-Memory wykorzystuje unikalną architekturę dwuformatową, która umożliwia równoczesną reprezentację tabel w pamięci. Ponieważ nowy format kolumn jest formatem wyłącznie w pamięci i nie wymaga miejsca na dysku, nie ma dodatkowych kosztów magazynowania ani problemów z synchronizacją magazynu. Zdolność baz danych w pamięci do obsługi zapytań z zadziwiającą szybkością miliardów wierszy na sekundę na rdzeniu procesora jest zdumiewająca. Większość z tych indeksów analitycznych można wyeliminować za pomocą In-Memory, używając formatu kolumn In-Memory, który zmniejsza ilość danych, które należy pobrać, a jednocześnie zapewnia wydajność porównywalną z posiadaniem indeksu w każdej kolumnie. Usunięcie indeksów analitycznych przyspiesza operacje OLTP, ponieważ indeksy nie muszą już być utrzymywane przy każdej transakcji. Do pamięci użytkowników można wstawiać tylko tabele i partycje z uprzywilejowanymi pamięciami.
System zarządzania bazą danych NoSQL w pamięci, taki jak MongoDB i Redis, przechowuje wszystkie dane w pamięci głównej i aktualizuje je na dysku w nieskończoność. Aby zapewnić trwałość, każde żądanie modyfikacji jest zapisywane w dzienniku binarnym. Ponieważ dziennik służy tylko do dołączania, zapisanie go w pośpiechu rzadko stanowi problem.
Czy baza danych Oracle działa w pamięci?

Tak, Oracle Database jest w pamięci. Funkcja przechowywania kolumn w pamięci firmy Oracle umożliwia przechowywanie danych i uzyskiwanie do nich dostępu w pamięci, zapewniając znaczny wzrost wydajności obciążeń analitycznych. W połączeniu z technologią Real Application Clusters (RAC) firmy Oracle baza danych Oracle może zapewnić jeszcze wyższy poziom skalowalności i dostępności.
Database In-Memory to zestaw funkcji, które poprawiają analizę w czasie rzeczywistym i mieszane obciążenia, zapewniając znaczny wzrost wydajności. Magazyn kolumn (magazyn kolumn IM) został dodany do Oracle Database 12c Release 1 (12.1.0.2) jako składnik Oracle Database 12c Release 1 (12.1.0.2). W tradycyjnych relacyjnych bazach danych dane mogą być przechowywane w formacie wierszowym lub kolumnowym. Wybieranie kolumn w kolumnowej bazie danych odpowiada wybieraniu wierszy w bazie danych wierszy. Baza danych In-Memory obejmuje magazyn kolumn w bazie danych, zaawansowane optymalizacje zapytań i rozwiązania dostępu. Magazyn kolumn IM przechowuje kopie wszystkich kolumn, tabel, partycji itd. w skompresowanym formacie kolumnowym przeznaczonym do szybkiego skanowania. Korzystając z przetwarzania równoległego, hurtownie danych i bazy danych o mieszanym przeznaczeniu mogą szybciej obsługiwać rzędy wielkości.
W wyniku zapełnienia dane oparte na wierszach na dysku są przekształcane na dane kolumnowe w magazynie kolumnowym IM. Na przykład, jeśli chcesz podzielić tabelę lub widok na partycje podzielone na partycje, wszystkie partycje lub część partycji można skonfigurować dla populacji. Wyrażenie w pamięci (wyrażenie IM) w DBMS_INMEMORY_ADMIN.IME_CAPTURE_EXPRESSIONS umożliwia identyfikację i wybór gorących wyrażeń. Gdy instancja bazy danych jest uruchamiana ponownie, metoda Database In-Memory FastStart (IM FastStart) oszczędza czas, zmniejszając ilość danych, które muszą zostać wprowadzone do magazynu kolumn IM. Format kolumnowy jest idealny do skanowania danych ze względu na wysoką przepustowość. Możesz użyć analizy danych w czasie rzeczywistym, aby odkrywać nowe możliwości i iteracje. Możliwe jest skanowanie danych w formacie skompresowanym bez uprzedniej dekompresji w bazie danych Oracle.
Predykat klauzuli WHERE jest używany wobec skompresowanych danych w bazie danych, gdy kolumny są kompresowane przy użyciu algorytmów, które umożliwiają automatyczną kompresję kolumn. Filtry Bloom przyspieszają łączenie, konwertując predykaty z tabel małych wymiarów na filtry dotyczące dużych wymiarów. Gdy dane są przechowywane w magazynie kolumnowym komunikatora, łatwiej jest organizować i wykonywać złożone zapytania. Tworzenie struktur dostępu jest kluczowym krokiem w poprawie wydajności zapytań analitycznych. Najczęstszym podejściem jest tworzenie indeksów analitycznych, zmaterializowanych widoków i kostek OLAP. Do tabeli należy wstawić wiersz, co wiąże się z modyfikacją wszystkich indeksów. Bazy danych Oracle są przechowywane w formacie Oracle na dysku, który jest identyczny z formatem kolumnowym.
Jest w pełni obsługiwany przez RMAN, Oracle Data Guard i Oracle ASM. Nie wymaga użycia narzędzia do migracji danych zarządzanego przez użytkownika. Jeśli korzystasz z funkcji analitycznych Oracle lub niestandardowego kodu PL/SQL, uzyskasz dostęp do szerszego zakresu zapytań analitycznych. Jedynymi wymaganymi zadaniami są określanie rozmiaru magazynu kolumn IM i określanie wartości obiektów dla populacji. W poniższej tabeli znajdziesz listę najbardziej podstawowych zadań konfiguracyjnych IM Column Store. Możesz pobrać Doradcę In-Memory dla PL/SQL i użyć go do analizy obciążenia przetwarzania analitycznego bazy danych. Przetwarzanie analityczne różni się od innych działań związanych z bazą danych na podstawie liczności planu, użycia zapytań równoległych i innych czynników.
Program In-Memory Advisor nie jest zawarty w pakietach PL/SQL przechowywanych w systemie. Należy najpierw uzyskać pakiet od działu wsparcia Oracle. Szacunki doradcy wskazują na poprawę wydajności przetwarzania analitycznego w oparciu o następujące czynniki. Można wyeliminować czasy oczekiwania na operacje wejścia/wyjścia użytkownika, transfery klastra i zdarzenia zatrzaskiwania pamięci podręcznej bufora. W zależności od typu kompresji, koszty kompresji podlegają heurystyce.
Co znajduje się w pamięci w bazie danych?
Baza danych w pamięci, w przeciwieństwie do bazy danych na dysku lub na dysku SSD, jest przeznaczona do przechowywania danych w pamięci głównie do celów przechowywania danych. Magazyny danych tworzone w pamięci wykorzystują tanią metodę eliminowania konieczności dostępu do dysków w celu skrócenia czasu odpowiedzi.
Zalety baz danych w pamięci
Bazy danych in-memory stały się w ostatnich latach bardziej popularne, ponieważ zapewniają wiele zalet w porównaniu z tradycyjnymi bazami danych. Pierwszą ich zaletą jest to, że mogą przechowywać wszystkie typy danych w tym samym systemie, co czyni je idealnymi do zastosowań, które muszą przechowywać duże ilości nieustrukturyzowanych danych. Oprócz szybkości i wydajności baz danych w pamięci, użytkownicy mogą szybciej uzyskiwać dostęp do danych. Ponadto bazy danych w pamięci mogą być wykorzystywane przez małe firmy i konsumentów, ponieważ są proste w użyciu i łatwe w zarządzaniu.
Czy Oracle ma bazę danych Nosql?
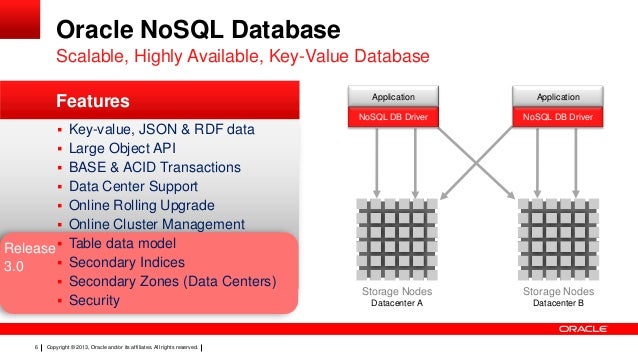
Tak, Oracle ma bazę danych nosql o nazwie Berkeley DB. Berkeley DB to wysoce wydajna, skalowalna baza danych typu open source.
Gdzie są przechowywane dane Nosql?
Zamiast przechowywać dane w relacyjnej bazie danych, bazy danych NoSQL przechowują dane w dokumentach. Innymi słowy, dzielimy je na SQL i różne elastyczne modele danych w celu ich sklasyfikowania. Baza danych NoSQL może być czystą bazą danych dokumentów, bazą danych magazynu klucz-wartość, bazą danych z szerokimi kolumnami lub bazą danych wykresów.
Jednym z najczęstszych zastosowań baz danych NoSQL jest szybkie przechowywanie dużych ilości niepowiązanych ze sobą danych. NoSQL to rodzaj bazy danych, która nie udostępnia danych relacyjnych. W latach siedemdziesiątych relacyjne bazy danych zyskały popularność jako standard przechowywania danych. Według Bena Finkela, trenera CBT, w NoSQL chodzi o szybkość i elastyczność, a nie o spójność i wydajność. Pomimo swojej szybkości i wydajności, bazy danych zbudowane przy użyciu technologii relacyjnych nie są tak proste, jak się wydaje. Baza danych NoSQL nie wymaga projektowania ani planowania struktur danych. Dzięki temu programiści mogą znacznie szybciej tworzyć, prototypować i wdrażać aplikacje.
Działają podobnie do zwinnego wytwarzania oprogramowania, które również jest popularne. Bazy danych NoSQL mogą przechowywać różne typy danych, co ułatwia ich konfigurację. Bazy danych NoSQL wymagają do działania większej mocy obliczeniowej niż relacyjne bazy danych. Raspberry Pi ma możliwość uruchamiania małych baz danych NoSQL , ale serwery WWW będą znacznie bardziej wymagające. Wykresy, w przeciwieństwie do par klucz:wartość lub dokumentów, są abstrakcyjne. Węzły i krawędzie to dwa składniki grafów. Węzły mogą przechowywać informacje o obiekcie (osobie, miejscu, rzeczy, idei itp.). Relacja między węzłem a jego krawędziami jest wyjaśniona przez krawędzie. Model danych z szerokimi kolumnami jest podobny do wierszy i kolumn w relacyjnej bazie danych.
Na wzrost popularności baz NoSQL składa się kilka czynników. Tradycyjne relacyjne bazy danych są nieefektywne, czasochłonne i podatne na uszkodzenia danych, podczas gdy bazy oparte na mikroserwisach działają lepiej. Nie bez powodu JSON jest preferowanym formatem dla baz danych NoSQL. Mówiąc najprościej, dokumenty JSON są bardziej zwarte i czytelne niż inne typy dokumentów. JSON to format reprezentacji danych stworzony w JavaScript.
JSON jest bardziej czytelny i zwarty niż standardowy format tekstowy.
Bazy danych NoSQL są bardziej wydajne niż tradycyjne relacyjne bazy danych pod względem szybkości i wydajności.
Ułatwiają użytkowanie.
Są bardziej odporne na uszkodzenie danych niż inne zwierzęta.

Różne typy baz danych Nosql
Bazy danych NoSQL, takie jak MongoDB, są popularne ze względu na prostotę przechowywania danych, która jest znacznie łatwiejsza do uchwycenia niż typy modeli danych stosowane w bazach SQL. Deweloperzy często mają bezpośredni dostęp do struktury bazy danych NoSQL.
Baza danych NoSQL to nietabelaryczna baza danych, która przechowuje dane w inny sposób niż relacyjna baza danych (inaczej SQL). Różne typy baz danych NoSQL są oparte na ich modelach danych. Główne typy dokumentów to wykresy, diagramy i zestawienia klucz-wartość.
Jak zainstalować Nosql, aby przechowywać dane w ustrukturyzowanej formie?
Dane mogą być ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane w bazie danych NoSQL, co umożliwia dostęp do nich za pomocą wielu mechanizmów. Główną zaletą ich oprogramowania jest to, że jest częściowo ustrukturyzowane (JSON, XML, ale nie wszystkie pola są znane), co prowadzi do danych nieustrukturyzowanych.
Jak przechowywać dane w nierelacyjnej bazie danych?
Ponieważ nierelacyjna baza danych nie korzysta ze schematu tabelarycznego większości tradycyjnych baz danych, nie ma wierszy ani kolumn. Z drugiej strony nierelacyjne bazy danych wykorzystują model przechowywania zoptymalizowany pod kątem typu danych, które mają być przechowywane.
Co to jest baza danych Oracle Nosql
Baza danych Oracle NoSQL to skalowalny, rozproszony magazyn klucz-wartość zaprojektowany w celu zapewnienia wysokiej wydajności, skalowalności poziomej i łatwej dostępności. Baza danych Oracle NoSQL to baza danych zgodna z NoSQL, która zapewnia przechowywanie danych w parach klucz-wartość. Baza danych Oracle NoSQL działa na klastrze serwerów towarowych i zapewnia prosty interfejs API języka Java umożliwiający dostęp do bazy danych.
Oracle NoSQL SDK for Spring Data zawiera moduł implementacji Spring Data. Tej funkcji można używać do łączenia się z klastrem Oracle NoQL Database lub usługą Oracle NoQL Cloud Service. Dodaj zależność maven do pliku XML projektu do użytku z zestawem SDK. Aby mieć dostęp do tych informacji, należy skorzystać z poniższych. Nosql.spring jest klientem Oracle. Użycie metody NosqlDbConfig do skonfigurowania bazy danych. Zdefiniuj klasę jednostki w następujący sposób.
Zaleca się utworzenie repozytorium dla rozszerzenia Nosql . Należy napisać klasę aplikacji. Dodając pliki zależności do org.springframework.boot:spring-boot, możesz rozpocząć pracę z Spring Framework.
Przykład Oracle w pamięci
Przykładem Oracle in-memory może być firma korzystająca z bazy danych Oracle do przechowywania i przetwarzania swoich danych w pamięci. Pozwoliłoby to na szybsze przetwarzanie i odzyskiwanie danych, a także zmniejszenie zapotrzebowania na miejsce na dysku.
Bez zmian w bazie kodu typy zapytań, takie jak grupowanie według operacji (zapytania analityczne), poprawiły się od 4 do 27 razy. Wypełnienie zapytania analitycznego online, które wymagało 11 sekund, zajęło 399 milisekund przy użyciu OIM. Dobrym pomysłem jest przechowywanie w pamięci najczęściej używanych partycji w przypadku dużych tabel partycjonowanych. Gdy tabela zawiera bardzo szerokie kolumny, zaleca się wykluczenie kolumn, które są rzadko używane w zapytaniach. Ponieważ każda kolumna nie jest składnikiem zapytania w pamięci, Oracle ustawia pamięć podręczną bufora na 0. Współczynnik kompresji jest zwiększony, dzięki czemu do przetworzenia wymagane jest mniej przetwarzania, co oszczędza miejsce. Im bardziej szczegółowe zapytanie, tym większe przyspieszenie zapewniane przez OIM. Zapytanie, które zwróciło 75 wierszy z 20-metrowej tabeli wierszy z systemem Oracle In-Memory, trwało 69 razy dłużej niż przy użyciu standardowego systemu DBMS . W rezultacie może zapewnić wzrost wydajności nawet 67 razy szybciej (w przypadku wysoce selektywnych zapytań).
Dlaczego obszar Pl/sql zasługuje na więcej pamięci
W przypadku języka PL/SQL i powiązanych z nim obiektów procedury PL/SQL i obiekty globalne są przechowywane w pamięci obszaru PL/SQL. Wszystkie te obiekty mają funkcje zdefiniowane przez użytkownika, są połączone z pakietem PL/SQL i mają uprawnienia do obiektów. Możliwe jest również równoległe wykonywanie Oracle Database z wykorzystaniem pamięci obszarowej PL/SQL.
Ogólnym zaleceniem firmy Oracle jest przydzielenie 95% całkowitej pamięci do obszaru SGA i 5% do obszaru PL/SQL.
Oracle Nosql kontra Cassandra
Istnieje kilka kluczowych różnic między Oracle NoSQL i Cassandra. Po pierwsze, Cassandra jest projektem typu open source, podczas gdy Oracle NoSQL jest systemem zastrzeżonym. Cassandra jest również bazą danych zorientowaną na kolumny, podczas gdy Oracle NoSQL jest bazą danych zorientowaną na wiersze. Wreszcie Cassandra koncentruje się na wysokiej dostępności i skalowalności poziomej, podczas gdy Oracle NoSQL koncentruje się na łatwości użytkowania i zarządzaniu danymi hierarchicznymi.
Apache Cassandra to baza danych NoSQL, która doskonale nadaje się do obsługi obciążeń roboczych o wysokiej wydajności, skalowalności liniowej, dostrajanej spójności i małych opóźnień w różnych obciążeniach. W większości przypadków Apache Cassandra nie będzie najlepszym wyborem dla twojego przypadku użycia, ponieważ brakuje mu spójnej semantyki między relacyjną bazą danych a bazami danych NoSQL z transakcjami ACID. Jeśli potrzebujesz ograniczonej nadmiarowości danych i zgodności z ACID, powinieneś rozważyć użycie baz danych SQL zamiast Oracle. HBase nie jest powszechnie używany przez deweloperów sieci Web lub mobilnych, ponieważ jest przeznaczony do pracy z zimnymi lub historycznymi przypadkami użycia jeziora danych. Z drugiej strony aplikacja Cassandra jest łatwiej dostępna i zdolna do obsługi bardzo wymagających środowisk.
Jaka jest różnica między Cassandrą a Oracle?
Oracle Database Management System (ODMS) to system zarządzania relacyjnymi bazami danych (RDBMS), który jest dostępny w dwóch formatach: S.NO.ORACLE CASSANDRA1. Został opracowany przez Oracle Corporation w 1980 r. i stworzony przez Apache Software Foundation w 2008 r.; 2. Napisano, że dostęp do oprogramowania open source można uzyskać, uruchamiając siedem wierszy więcej.
Czy Oracle jest bazą danych Nosql?
Usługa Oracle NoSQL Database Cloud Service ułatwia programistom tworzenie aplikacji przy użyciu modeli baz danych opartych na dokumentach, kolumnach i klucz-wartość, zapewniając przewidywalny czas odpowiedzi w milisekundach, replikację danych w celu zapewnienia wysokiej dostępności i aplikacje oparte na dokumentach.
Czy Cassandra i Nosql to to samo?
Cassandra to darmowy i rozproszony system zarządzania bazą danych magazynu o szerokim kolumnie , oparty na otwartym kodzie źródłowym Cassandra.
Czy Netflix korzysta z Cassandry?
Cassandra w Amazon Web Services jest kluczowym elementem infrastruktury globalnej usługi przesyłania strumieniowego Netflix.
Baza danych Oracle Nosql kontra Mongodb
Istnieje wiele różnic między Oracle NoSQL Database a MongoDB. Po pierwsze, MongoDB to baza danych zorientowana na dokumenty, podczas gdy baza danych Oracle NoSQL to magazyn klucz-wartość. Oznacza to, że MongoDB przechowuje dane w dokumentach podobnych do JSON, podczas gdy Oracle NoSQL Database przechowuje dane w parach klucz-wartość. Po drugie, MongoDB obsługuje indeksy pomocnicze, podczas gdy baza danych Oracle NoSQL nie. Po trzecie, MongoDB ma bogatszy język zapytań niż Oracle NoSQL Database. Po czwarte, MongoDB obsługuje auto-sharding, podczas gdy baza danych Oracle NoSQL nie. Wreszcie, MongoDB jest open source, podczas gdy Oracle NoSQL Database nie.
MongoDB jest prosty w konfiguracji i zapewnia niesamowitą elastyczność pod względem elastyczności projektowania. Jeśli Twoje formaty danych nie są spójne, dobrym wyborem jest baza danych NoSQL, taka jak Oracle NoSQL Database. Jeśli potrzebujesz mniejszej nadmiarowości danych i zgodności z ACID, użycie bazy danych SQL może być dla Ciebie najlepszą opcją. Ponieważ bazy danych NoSQL, takie jak MongoDB, nie mają interfejsów graficznych, zazwyczaj nie są przeznaczone do użytku w połączeniu z tradycyjnymi bazami danych. Aby poprawić użyteczność, należy zainstalować aplikacje firm trzecich, które umożliwiają wizualne przeglądanie schematów i przechowywanych dokumentów. Jeśli nie znasz administratora bazy danych lub administratora systemu, jak korzystać z MongoDB, dobrym pomysłem jest skontaktowanie się z zewnętrznym dostawcą usług hostingowych MongoDB.
Kluczowe różnice między Mongodb a Oracle
Istnieje kilka znaczących różnic między MongoDB i Oracle, które należy wziąć pod uwagę przy podejmowaniu decyzji o zakupie oprogramowania. Platforma MongoDB jest dobrze znana ze swojej zdolności do obsługi dużych ilości danych, podczas gdy Oracle jest częściej używany do tworzenia aplikacji korporacyjnych. Ponadto MongoDB zawiera zaawansowane funkcje wyszukiwania dowolnego pola lub zakresu zapytań, podczas gdy możliwości Oracle są mniej ograniczone. Oracle skaluje się w pionie, ponieważ opiera się na dzieleniu na fragmenty, podczas gdy MongoDB skaluje się w poziomie, ponieważ opiera się na dzieleniu na fragmenty. Ponadto MongoDB jest zbudowany na architekturze systemu rozproszonego, a nie na monolitycznym projekcie z jednym węzłem, co odróżnia go od Oracle pod względem architektury.