
Potęga Big Data: jak bazy danych NoSQL zmieniają sposób, w jaki przechowujemy i przetwarzamy dane
Opublikowany: 2022-11-22Nie bez powodu XXI wiek został nazwany „wiekiem informacji”. Dane stają się w coraz większym stopniu najcenniejszym towarem na świecie. Termin „big data” odnosi się do zbiorów danych tak dużych i złożonych, że ich przetwarzanie przy użyciu tradycyjnych metod staje się trudne. Potrzeba rozwiązań Big Data stała się oczywista na początku XXI wieku, kiedy firmy internetowe zaczęły generować duże ilości danych od swoich użytkowników. Firmy te musiały znaleźć sposoby na szybkie i wydajne przechowywanie i przetwarzanie tych danych. Jedno z opracowanych rozwiązań nosiło nazwę „NoSQL”, co oznacza „nie tylko SQL”. Ten typ bazy danych został zaprojektowany tak, aby był skalowalny i elastyczny, dzięki czemu idealnie nadaje się do zastosowań związanych z dużymi zbiorami danych . Bazy danych NoSQL są obecnie używane przez jedne z największych firm na świecie, w tym Facebook, Google i Amazon. Okazały się nieocenione w szybkiej i wydajnej obsłudze dużych ilości danych.
Big data to dane, które są trudne do przechowywania i analizowania przy użyciu dowolnego oprogramowania do baz danych. Rozwiązanie NoSQL to takie, które może obsłużyć duże ilości danych; przyjrzymy się im bardziej szczegółowo poniżej. W projektach z dużymi danymi zaleca się stosowanie baz NoSQL. Poniżej przedstawiono kilka sposobów radzenia sobie z problemami związanymi z dużymi danymi . Zamiast przenosić dane z jednego zapytania do drugiego, należy przenieść zapytanie do danych. Zaleca się stosowanie pierścieni mieszających w dystrybucji danych. W czasie rzeczywistym replikacja danych jest wykorzystywana przez bazy danych do tworzenia kopii zapasowych. Aby skalować żądania odczytu w poziomie, dobrą opcją jest replikacja. Problemy z oceną i wykonaniem zapytania muszą być rozdzielone, aby można je było zrozumieć.
Baza danych NoSQL nie ma żadnych połączeń ani relacji, podczas gdy RDBMS tak. Baza danych NoSQL ma znacznie niższe koszty utrzymania niż baza danych RDBMS. Zapotrzebowanie na NoSQL dla programistów i projektantów baz danych jest większe niż w przypadku RDBMS, ale RDBMS zajmuje mniej miejsca. NoSQL to rodzaj bazy danych NoSQL, podczas gdy RDBMS to rodzaj bazy danych RDBMS.
Carlo Strozzi użył terminu NoSQL w 1998 roku, aby opisać lekką relacyjną bazę danych typu open source, która nie udostępniała standardowego interfejsu Structured Query Language (SQL), ale raczej pozostała relacyjna. Jego NoSQL RDBMS różni się od ogólnej koncepcji bazy danych NoSQL, która została opracowana na przełomie XIX i XX wieku.
Korzystanie z baz danych NoSQL opiera się na chęci przezwyciężenia frustracji związanej z SQL, czemu zawsze towarzyszy mnóstwo wspieranych przez przemysł i środowisko akademickie innowacji w technologii baz danych . Rozwój NoSQL rozpoczął się w branży w odpowiedzi na potrzeby odnoszących sukcesy pionierów aplikacji internetowych oraz infrastruktury wymaganej do wyszukiwania i reklamy.
Ponieważ wszystkie dane w hubie/węźle są przechowywane w formie dokumentu, zapytanie i wynik mogą być przenoszone przez sieć bez wpływu na zapytanie.
W jaki sposób Big Data jest powiązany z Nosql?
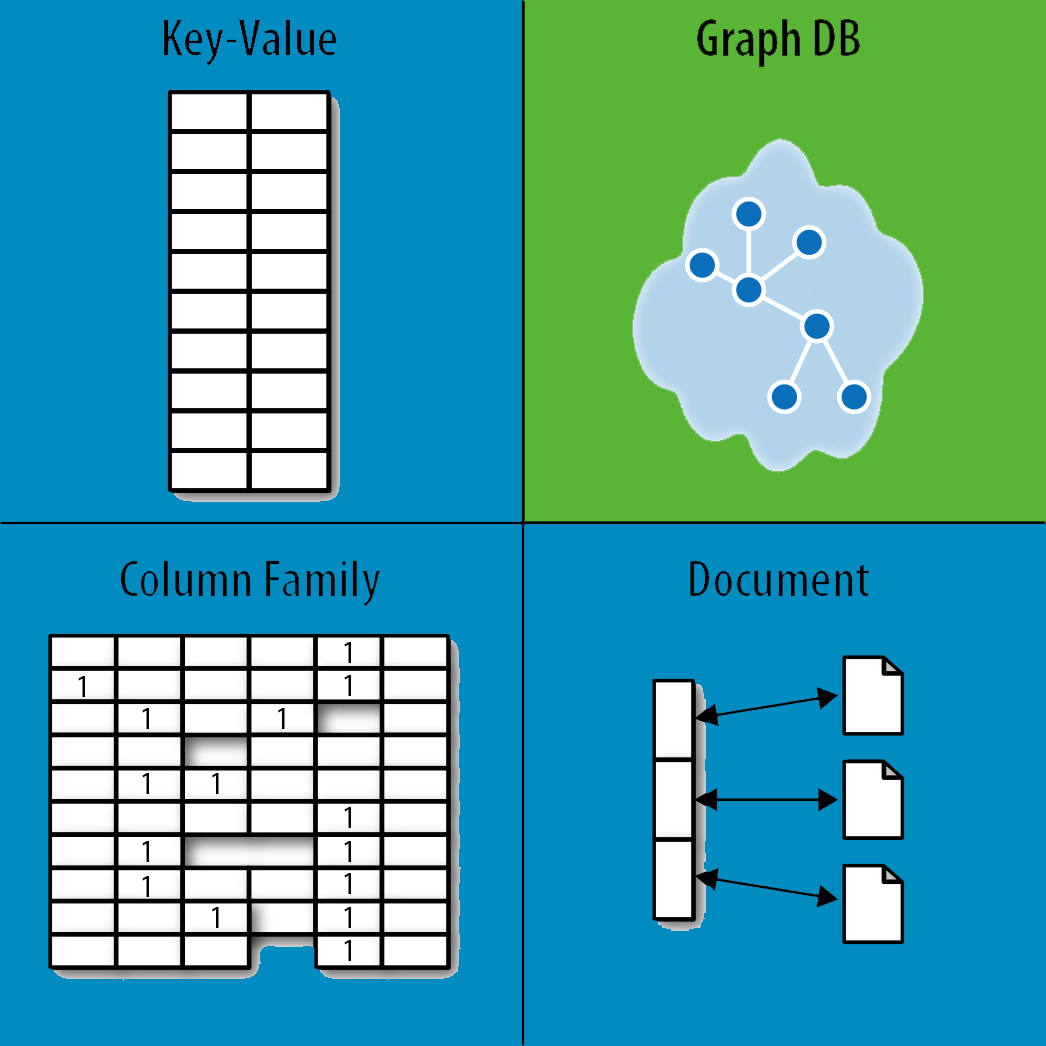
Te firmy, które przetwarzają duże ilości zróżnicowanych i nieustrukturyzowanych danych, takie jak Big Data, częściej używają NoSQL niż inne. Baza danych NoSQL nie opiera się na modelu stałego schematu w taki sam sposób jak relacyjna baza danych.
Bazy danych NoSQL, takie jak MongoDB, Apache Cassandra i HBase, rozwijały się znacznie szybciej niż ich odpowiedniki RDBMS . Jeśli korzystasz z obciążeń związanych z danymi, które wymagają szybkiego przetwarzania i analizy dużych ilości zmiennych i nieustrukturyzowanych danych, lepszym rozwiązaniem jest NoSQL. Baza danych bez teorii względności ma wiele zalet w porównaniu z tradycyjnymi produktami RDBMS, w tym wysoką wydajność, skalowalność i dostępność. Baza danych NoSQL będzie bardziej przydatna dla organizacji, które chcą przechowywać i analizować ogromne ilości ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych danych, szczególnie w czasie rzeczywistym. Aby nadążyć za rosnącą ilością danych, do klastra należy dodać więcej serwerów fizycznych. Architektura baz danych NoSQL umożliwia ich skalowanie w poziomie. Ze względu na swój otwarty charakter, NoSQL jest znacznie bardziej opłacalny niż tradycyjne bazy danych. Ponadto, łącząc mocne strony NoSQL i RDBMS, można osiągnąć większą wydajność.
Bazy danych NoSQL mogą przechowywać ogromne ilości danych i zarządzać nimi. Ponieważ mają elastyczny schemat i wysoki poziom wydajności, idealnie nadają się do aplikacji internetowych czasu rzeczywistego i dużych zbiorów danych.
Czy Mongodb to Big Data?
Ostatecznie zarówno Hadoop, jak i MongoDB to świetny wybór do zarządzania dużymi ilościami danych. Chociaż mają wiele podobieństw (np. otwarte źródło, NoSQL, brak schematów i redukcja map), mają różne podejścia do przetwarzania i przechowywania danych.
Co doprowadziło do ewolucji bazy danych Nosql?
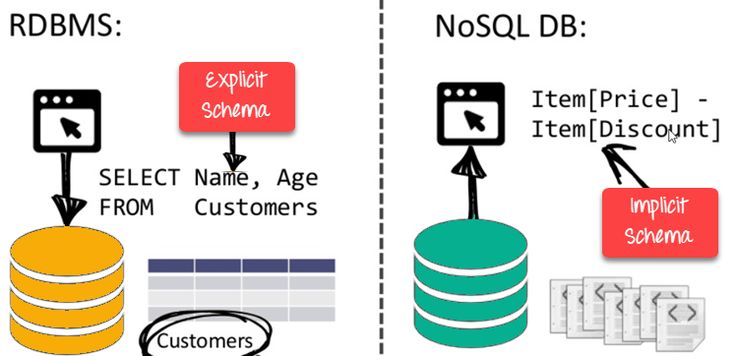
Carlo Strozzi po raz pierwszy użył terminu NoSQL w 1998 r., kiedy opisał „relacyjną” bazę danych typu open source, która nie wymaga SQL. Ponownie wyszło to na jaw w 2009 roku, kiedy Eric Evans i Johan Oskarsson użyli go do opisania nierelacyjnych baz danych.
Koncepcja przechowywania danych w wierszach i kolumnach z określonym kluczem wskazującym na relacje między nimi sięga roku 1970, kiedy po raz pierwszy wprowadził ją Edgar F. Codd. Ze względu na swoją ustrukturyzowaną naturę dane do niedawna były zawsze doskonale dopasowane do relacyjnej bazy danych. Boom na nieustrukturyzowane dane rozpoczął się w wyniku zwiększonego dostępu do Internetu. Rosnąca potrzeba tworzenia, odczytywania, aktualizowania i usuwania danych (CRUD) sprawia, że relacyjne bazy danych są trudniejsze i droższe w użyciu i utrzymaniu. W niektórych przypadkach nie jest możliwe utrzymanie relacji między danymi, ponieważ stało się tak duże zadanie. Wiele utalentowanych osób w dziedzinie technologii stworzyło bazy danych, które nie wymagają schematu ani relacji danych do przechowywania i pobierania nieustrukturyzowanych danych. Duże i nieustrukturyzowane zbiory danych są zapisywane w bazach danych NoSQL, ponieważ stają się one coraz bardziej popularne. Wiele dużych firm, w tym Twitter, Facebook i Google, używa NoSQL, aby poprawić swoje doświadczenia online. Ponieważ niektóre bazy danych są teraz oparte na wielu modelach, mogą przechowywać dane w wielu formatach.
Nowa fala baz danych: Nosql
W drugiej fali ewolucji baz danych wprowadzane są bazy danych NoSQL. Wzrost danych jest głównym problemem w tej dziedzinie, a ta baza danych została stworzona, aby poradzić sobie z tym problemem.
Dlaczego Nosql jest używany w Big Data?
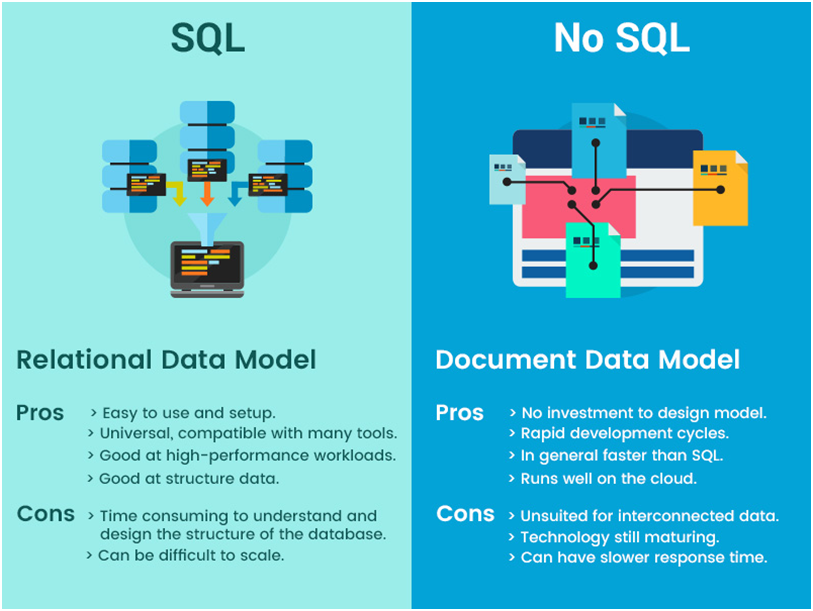
Nosql jest używany w dużych zbiorach danych, ponieważ jest to skalowalny, wysokowydajny system baz danych, który może obsługiwać duże ilości danych. Jest również zaprojektowany tak, aby był łatwo skalowalny i obsługiwał obciążenia o dużym natężeniu ruchu.
Ponieważ RDBMS stał się mniej skuteczny, firmy internetowe, takie jak Amazon, Google, LinkedIn i Facebook, opracowały bazy danych NoSQL, aby przezwyciężyć jego wady. Dzięki NoSQL wymagania dotyczące przetwarzania danych są ograniczone, a dane nieustrukturyzowane są przetwarzane szybko i łatwo. Według Evardo de Oliveiry, dyrektora ds. rozwoju biznesu w FairCom, istnieją pewne problemy z NoSQL, których nie da się rozwiązać za pomocą tradycyjnej bazy danych . Technologia baz danych NoSQL jest używana przez społeczności dużych zbiorów danych w Internecie, Big Data i Big Users. Baza danych NoSQL składa się z wielu baz danych, z których każda ma inny typ przechowywania danych. Najpopularniejsze typy to wykresy, pary klucz-wartość, kolumny i dokumenty. Firmy zorientowane na Internet, takie jak Amazon, eBay itp., potrzebowały bazy danych, takiej jak NoSQL vs. SQL, która najlepiej pasowałaby do zmieniającego się modelu danych, aby stały się bardziej elastyczne w swoich działaniach.
Baza danych Bazy danych NoSQL , w przeciwieństwie do relacyjnych baz danych, mogą również przechowywać i przetwarzać dane w czasie rzeczywistym. Krajobraz baz danych rozrósł się na przestrzeni lat, a teraz jest więcej typów danych, więcej zestawów danych i więcej woluminów danych, a tylko bazy danych NoSQL, takie jak HBase, Cassandra i Couchbase, mogą sprostać tym wyzwaniom. Baza danych NoSQL uwzględnia spójność tolerancji partycji dostępności jako część procesu ustalania priorytetów CAP.
Czy Sql czy Nosql jest lepszy dla Big Data?
W rezultacie SQL staje się ważnym aspektem NoSQL, ponieważ jest całkowicie oparty na różnych modelach danych. Tabele zagnieżdżone są reprezentowane przez wiersze i kolumny w relacyjnej bazie danych. Każda tabela w tych tabelach jest połączona kluczem obcym.
Bazy danych Nosql stają się coraz bardziej popularne do przechowywania dużych zbiorów danych
NoSQL może być używany do przechowywania dużej ilości danych. Ten typ bazy danych staje się coraz bardziej popularny wśród firm internetowych ze względu na swoją popularność. Zwolennicy rozwiązań NoSQL twierdzą, że ich technologie mogą skalować się szybciej niż tradycyjne relacyjne bazy danych , jednocześnie zapewniając większą wydajność. MongoDB to baza danych dokumentów, która działa dobrze, jest łatwa w użyciu i zapewnia wysoką dostępność. Ze względu na możliwość obsługi dużych zbiorów danych staje się coraz bardziej popularny wśród firm internetowych.
Co Nosql oznacza w Big Data?
Bazy danych NoSQL (znane również jako SQL) nie mają struktury wierszowej i przechowują dane inaczej niż relacyjne bazy danych. Baza danych NoSQL może mieć różne typy w zależności od jej modelu danych. Najpopularniejsze są typy dokumentów, typy klucz-wartość, typy szerokich kolumn i typy wykresów.
Dlaczego Nosql jest ważny dla przetwarzania danych
NoSQL jest ważną technologią z następujących powodów: umożliwia użytkownikom wysyłanie zapytań do danych, umożliwiając im badanie ich w miarę zmian. Dzięki temu możliwe jest przetwarzanie dużych ilości danych z dużą szybkością w zwinny sposób. NoSQL może być używany do przechowywania nieustrukturyzowanych danych w wielu węzłach przetwarzania, a także na wielu serwerach. Z tego powodu dane mogą być przechowywane w różnych formatach, niekoniecznie w formacie ustrukturyzowanym. Bardzo ważne jest, aby pamiętać, że ta funkcja umożliwia przechowywanie danych w lokalizacjach innych niż centralny serwer.
Z jakiej bazy danych korzysta Big Data?
Amazon Redshift, Azure Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 i inne duże bazy danych to tylko kilka przykładów.

Serwer Sql: najlepszy sposób przechowywania i analizowania dużych zbiorów danych
Klastry dużych zbiorów danych mogą służyć do analizowania i przechowywania dużych ilości danych przy użyciu programu SQL Server. Ponadto mogą pomóc w łączeniu danych relacyjnych z dużymi zbiorami danych w celu tworzenia bardziej wnikliwych zestawów danych. Big data są często wykorzystywane do usprawniania działalności firm, zapewniania lepszej obsługi klienta i tworzenia spersonalizowanych kampanii marketingowych.
Czy Hadoop używa Nosql?
Hadoop to ekosystem oprogramowania, który umożliwia masowe przetwarzanie równoległe, w przeciwieństwie do baz danych, które są używane głównie do zarządzania bazami danych. Na przykład można go użyć do włączenia niektórych typów rozproszonych baz danych NoSQL (takich jak HBase), umożliwiając rozproszenie danych na tysiącach serwerów i mając niewielki wpływ na wydajność.
Korzyści z Nosql do analizy dużych zbiorów danych
Duża liczba źródeł danych znajduje się w HBase, która jest bazą danych zorientowaną na kolumny. Cassandra to rozproszona baza danych o strukturze elastycznego schematu.
Obie bazy danych doskonale nadają się do analizy dużych zbiorów danych.
Nie jest możliwe użycie domyślnej tabeli Hive ze względu na jej rozmiar. Celem Pig jest podzielenie danych na łatwe do zarządzania fragmenty, a tym samym przechowywanie ich w tabeli HBase.
Cassandra jest idealna dla danych, które są częściowo ustrukturyzowane. Dzięki Cassandra możesz przechowywać dane w parach klucz-wartość. W ten sposób możesz przeprowadzać określone wyszukiwania na podstawie danych.
Baza danych NoSQL to świetna opcja do analizy dużych zbiorów danych. Możesz przechowywać dane w inny sposób niż tradycyjne bazy danych, co ułatwia zarządzanie nimi.
Co to jest Nosql, jak pasuje do obrazu analizy dużych zbiorów danych
Nosql to rodzaj bazy danych, który służy do przechowywania danych w sposób nierelacyjny. Oznacza to, że dane nie są przechowywane w tabelach, ale w bardziej elastycznym formacie, do którego można łatwo uzyskać dostęp i aktualizować. Bazy danych Nosql są często używane w aplikacjach big data, ponieważ mogą obsługiwać duże ilości danych wydajniej niż tradycyjne relacyjne bazy danych.
Witryny internetowe działają szybciej i wydajniej, gdy są hostowane w rozwiązaniach NoSQL opartych na chmurze i in-memory. Niektóre z tych produktów doskonale radzą sobie z przechowywaniem nieustrukturyzowanych danych, a produkty open source, takie jak Cassandra, MongoDB i Redis, również należą do tej kategorii. Zwolennicy baz danych argumentują, że zapewniają one większą wydajność i skalowalność niż tradycyjne bazy danych. Kilka z tych kluczowych spostrzeżeń, a także unikalne podejście Garantia Data do kompresji sprawiają, że warto mieć na nie oko. Tymi ultraszybkimi bazami danych można zarządzać z absolutną łatwością dzięki technologii, która automatyzuje wszystkie aspekty operacji związanych z zarządzaniem nimi.
Korzyści z baz danych Nosql
W rezultacie bazy danych NoSQL są doskonałym wyborem do przechowywania Big Data, ponieważ zawierają szeroki zakres unikalnych funkcji. Ponieważ są one potężniejsze niż inne rodzaje przechowywania danych, bardzo dobrze radzą sobie z dużymi ilościami danych. Ponadto bazy danych NoSQL są prostsze w użyciu niż tradycyjne bazy danych, co ułatwia skalowanie i zarządzanie nimi.
Dlaczego Nosql jest lepszy w przypadku dużych zbiorów danych
Bazy danych Nosql są znacznie lepiej przygotowane do radzenia sobie z dużymi zbiorami danych ze względu na ich poziomą skalowalność. Oznacza to, że mogą z łatwością dodać więcej węzłów do swojego systemu, aby zwiększyć pojemność pamięci masowej i moc obliczeniową bez konieczności zmiany architektury całego systemu. Kontrastuje to z relacyjnymi bazami danych, które są skalowalne w pionie, co oznacza, że można je skalować tylko poprzez dodanie mocniejszych serwerów, które są zarówno droższe, jak i mniej wydajne.
Wykorzystanie dużych zbiorów danych i analiz może znacząco zoptymalizować procesy produkcyjne. Termin „duże zbiory danych” odnosi się do informacji, które są nieustrukturyzowane lub ustrukturyzowane w swojej ogromnej różnorodności i złożoności. Czujniki dostarczają wielu informacji o ruchach ciężarówek wysyłkowych, kamerach w fabrykach i urządzeniach konsumenckich w produkcji. W produkcji preferowane byłyby architektury NoSQL, ponieważ większość danych jest nieustrukturyzowana i nie można ich wykonywać na sztywnych architekturach, takich jak SQL. Bazy danych NoSQL nie wymagają schematów, co oznacza, że dane mogą być przechowywane w różnych strukturach w jednej tabeli bazy danych. Linia podziału jest określona przez charakter danych, które będą wykorzystywane przez każdą firmę. Transakcja w relacyjnej bazie danych musi spełniać cztery podstawowe zasady działania.
Integracja systemów NoSQL z systemami chmurowymi sprawia, że są one idealnym rozwiązaniem podczas pracy z frameworkami przetwarzania w chmurze. Dzięki integracji NoSQL z systemami realizacji produkcji (MES) możliwa jest optymalizacja procesu produkcyjnego w czasie rzeczywistym. W wyniku tej metody wygenerowano szybsze reakcje na zmieniające się warunki przy użyciu analizy dużych zbiorów danych. Bazy danych NoSQL ułatwiają skalowanie i mogą być używane do analizy danych. Jedną z zalet architektur baz danych o szybszej odpowiedzi, takich jak NoSQL, jest to, że kierownictwo może przeprowadzać lepsze symulacje i wpływać na decyzję o stworzeniu konkretnego produktu. Ataki typu „blustery force”, ataki między witrynami i ataki polegające na wstrzykiwaniu to niektóre z najczęstszych luk w zabezpieczeniach bazy danych NoSQL . Gdy użytkownik dodaje dane do poleceń zapytania NoSQL lub instrukcji przechowywania, uruchamiany jest atak iniekcyjny.
Obawy o bezpieczeństwo architektury NoSQL są problemem dla przemysłu wytwórczego. Jeśli atakujący pomyślnie zaatakuje system produkcyjny i przeprowadzi atak typu „odmowa usługi” lub „wstrzyknięcie”, będzie mógł zmienić specyfikacje. To, na wysoce konkurencyjnym rynku, może pomóc konkurentom.
Dlaczego Nosql to najlepszy wybór dla nieustrukturyzowanych danych
Nie ma lepszego typu danych niż dane nieustrukturyzowane, które szybko się zmieniają i są dostępne dla dużej liczby użytkowników.
W jaki sposób bazy danych Big Data i Nosql są identyczne?
Nie ma ostatecznej odpowiedzi na to pytanie, ponieważ zależy to od wielu czynników, w tym konkretnej bazy danych Big Data i NoSQL, a także sposobu ich wykorzystania. Jednak ogólnie rzecz biorąc, zarówno duże zbiory danych, jak i NoSQL są przeznaczone do przechowywania i zarządzania dużymi ilościami danych, i obie używają do tego różnych metod.
Jest to rozproszony i nierelacyjny system baz danych, który może przechowywać duże ilości danych. Systemy te opierają się na potrzebie elastyczności, wydajności i skali oraz mogą być używane przez szerokie grono użytkowników. Baza danych NoSQL jest rozproszona poziomo i ma obsługiwać od setek milionów do miliardów użytkowników. Cameron Purdy, były dyrektor wykonawczy Oracle i ewangelista Javy, wyjaśnia, dlaczego bazy danych NoSQL działają tak dobrze. Na masową skalę bazy danych NoSQL są idealne do wysokowydajnego, elastycznego przetwarzania danych. Może przechowywać nieustrukturyzowane dane na wielu węzłach przetwarzania, a także na wielu serwerach. Czy NoSQL jest lepszy do analizy niż inne platformy? Zależy to od wielu czynników, takich jak rodzaj analizowanych danych, ilość posiadanych danych i to, jak szybko są one potrzebne. W przypadku danych częściowo ustrukturyzowanych, takich jak media społecznościowe, teksty lub dane geograficzne, bazy danych NoSQL, takie jak mongoDB, a także CouchDB, najlepiej nadają się do obsługi.
Czym Big Data różni się od bazy danych?
Tradycyjne dane są zwykle ustrukturyzowane w scentralizowanym systemie baz danych, podczas gdy duże zbiory danych są rozproszone. Każdy komputer w sieci uczestniczy w obliczeniach. W rezultacie duże zbiory danych można znacznie zwiększyć w porównaniu z tradycyjnymi danymi, a także czerpać korzyści z lepszej wydajności i oszczędności.
Dlaczego klastry Sql Server Big Data to dobry wybór dla aplikacji Big Data
SQL Server Big Data Clusters są dobrze przystosowane do aplikacji dużych zbiorów danych ze względu na wysoki poziom funkcji. Możesz użyć tych funkcji, wybierając *br Masz większą elastyczność w sposobie interakcji z dużymi zbiorami danych podczas podejmowania decyzji dotyczących sposobu ich obsługi. Duża szybkość przesyłania danych może być obsługiwana przez duże centrum danych. Rezultatem jest wysoce wydajna operacja. Użycie narzędzi SQL Server, które są kompatybilne z innymi technologiami SQL Server.
Czy wszystkie bazy danych Nosql są podobne?
Bazy danych SQL i bazy danych NoSQL znacznie różnią się typami danych, które zawierają. Używają modelu danych, który różni się od tradycyjnego modelu tabeli wierszy i kolumn, który można znaleźć w systemach zarządzania relacyjnymi bazami danych (RDBMS). Podobnie bazy danych NoSQL znacznie się od siebie różnią.
Mongodb to idealny wybór do przechowywania i wyszukiwania danych na dużą skalę.
Ponieważ jest tak szybki zarówno pod względem operacji odczytu, jak i zapisu, MongoDB jest fantastycznym wyborem do przechowywania i wyszukiwania danych na dużą skalę.
Oprócz tego, że jest bardzo elastyczny, MongoDB może być również używany do tworzenia własnych baz danych i zarządzania nimi.
Analiza danych Nosql
Prawdą jest, że „NoSQL” odnosi się do „nie tylko SQL”. Dane nie są tutaj rozdzielane na wiele tabel, ponieważ umożliwia to umieszczenie całego zestawu danych w strukturze pojedynczej kolumny. Gdy masz do czynienia z dużą ilością danych w bazie danych NoSQL, nie musisz się martwić o problemy z wydajnością.
Dlaczego bazy danych Nosql, takie jak Mongodb i Cassandra, są idealne do analizy dużych zbiorów danych
MongoDB, ze względu na elastyczne wymagania schematu, jest lepszym wyborem do obsługi dużych zbiorów danych ze względu na swój charakter NoSQL. Możesz użyć tej metody do przechowywania danych w sposób, który jest dla Ciebie najwygodniejszy. Baza danych MongoDB może być używana do przechowywania danych w sposób, który jest zarówno elastyczny, jak i łatwy do zapytania. Ta przewaga nad bazami danych SQL pozwala użytkownikom przeprowadzać bardziej wyrafinowaną analizę danych.
Cassandra, kolejna baza danych NoSQL, jest często używana w analizie dużych zbiorów danych. Ten rodzaj pracy dobrze pasuje do Cassandry, ponieważ ma wiele zalet. Jedną z jego głównych zalet jest wysoka skalowalność i dostępność. Dzięki temu system może przetwarzać duże ilości danych i analizować je niemal natychmiast. Ponadto Cassandra ma wiele funkcji na poziomie przedsiębiorstwa, które czynią ją doskonałym wyborem. System ten ma wiele zalet, w tym możliwość obsługi dużej liczby strumieni danych.