
5 najlepszych programów LLM typu open source, które musisz znać [grudzień 2023 r.]
Opublikowany: 2023-12-19Streszczenie:
Poznaj awangardę innowacji AI dzięki 5 najlepszym modelom wielkojęzycznym (LLM) o otwartym kodzie źródłowym w roku 2023. Od przełomowych parametrów 180B Falcona po wielojęzyczność BLOOM – poznaj najnowocześniejsze funkcje kształtujące przyszłość. Odkryj mocne strony i potencjalne zastosowania Llama 2, GPT-NeoX-20B i MPT-7B, umożliwiające firmom bezpieczne skalowanie w ewoluującym środowisku sztucznej inteligencji.
Wstęp
Świat sztucznej inteligencji (AI) zmienia się szybko, a duża część tych zmian wynika z tak zwanych modeli dużych języków (LLM). To nie są zwykłe narzędzia; są jak liderzy nowej fazy technologii. Pomyśl o nich jak o naprawdę inteligentnych systemach, które zmieniają sposób, w jaki korzystamy z naszych telefonów, komputerów i innych gadżetów.
Przedsiębiorstwa mogą zdecydować się na oprogramowanie LLM (Large Language Model) typu open source zamiast polegać na zewnętrznych usługach chatbota, takich jak ChatGPT, Claude.ai lub Phind, aby rozwiązać problemy związane z prywatnością i bezpieczeństwem. Uruchomienie open source LLM na Twoim komputerze gwarantuje, że wrażliwe dane i informacje poufne pozostaną pod kontrolą przedsiębiorstwa, minimalizując ryzyko narażenia na podmioty zewnętrzne. Takie podejście jest szczególnie istotne na platformach, na których interakcje mogą być przeglądane przez ludzi lub wykorzystywane do szkolenia przyszłych modeli. Wykorzystując lokalnie oprogramowanie LLM typu open source, przedsiębiorstwo może utrzymać wyższy poziom bezpieczeństwa i poufności danych, rozwiązując potencjalne problemy związane z prywatnością związane z aplikacjami zewnętrznymi.
Ekscytujące jest to, że wiele z tych LLM to programy typu open source. Oznacza to, że każdy, kto ma zainteresowania i posiada pewne umiejętności techniczne, może z nich korzystać, zmieniać je, a nawet udoskonalać. To tak, jakby mieć superinteligentnego przyjaciela AI, od którego możesz się uczyć i uczyć nowych sztuczek.

5 najlepszych programów LLM typu open source w 2023 r
Na tym blogu przyjrzymy się pięciu niesamowitym programom LLM typu open source. Każdy z nich jest na swój sposób wyjątkowy, wnosząc nowe pomysły i umiejętności do świata sztucznej inteligencji.
Firma Falcon spółka z ograniczoną odpowiedzialnością

Falcon LLM to przełomowy model dużego języka (LLM) opracowany przez Instytut Innowacji Technologicznych (TII) w Abu Zabi. Został zaprojektowany z myślą o napędzaniu aplikacji i przypadków użycia, zapewniając przyszłą odporność naszego świata. Pakiet obejmuje obecnie modele AI z parametrami Falcon 180B, 40B, 7.5B i 1.3B wraz ze starannie dobranym zbiorem danych REFINEDWEB. Razem prezentują różnorodną i kompleksową gamę rozwiązań.
Oto obszerne zestawienie jego kluczowych cech, mocnych stron i potencjalnych zastosowań, wraz z odpowiednimi źródłami do dalszych badań:
Kluczowe cechy:
- Ogromny rozmiar : Dzięki 180 miliardom parametrów Falcon 180B może poszczycić się imponującą zdolnością uczenia się i wydajnością, przewyższającą kilka innych rozwiązań LLM typu open source.
- Wydajne szkolenie : szkolenie na udoskonalonym zestawie danych składającym się z 3,5 biliona tokenów, zapewniające dokładność i jakość przy jednoczesnej optymalizacji wykorzystania zasobów.
- Dostępność oprogramowania typu open source : kod i dane szkoleniowe są publicznie dostępne w serwisie Hugging Face, co sprzyja przejrzystości i wkładowi społeczności.
- Doskonała wydajność : Falcon osiągnął lepsze wyniki niż GPT-3 w różnych testach porównawczych, wymagając jednocześnie mniej zasobów szkoleniowych i wnioskowania, co czyni go bardziej wydajną opcją.
- Różnorodne modele : TII oferuje różne wersje Falcona, w tym modele AI z parametrami 180B, 40B, 7.5B, 1.3B, wyspecjalizowane modele do określonych zadań, takich jak pisanie długich historii.
Silne strony:
- Wysokiej jakości potok danych : rygorystyczne procesy filtrowania i deduplikacji danych TII zapewniają dokładne i niezawodne dane szkoleniowe dla Falcona.
- Możliwości wielojęzyczne : Falcon skutecznie radzi sobie z wieloma językami, chociaż jego głównym celem jest język angielski.
- Potencjał dostrajania : Falcon można dostosować do konkretnych zadań, co dodatkowo zwiększa jego wydajność i możliwości adaptacji.
- Rozwój kierowany przez społeczność : charakter open source pozwala na wspólne ulepszenia i badania, przyspieszając rozwój Falcona.
Potencjalne aplikacje:
- Przetwarzanie języka naturalnego (NLP): Falcon może przodować w różnych zadaniach NLP, takich jak podsumowywanie tekstu, analiza nastrojów i generowanie dialogów.
- Generowanie treści kreatywnych : model może pomóc pisarzom i artystom w generowaniu różnych formatów kreatywnych, takich jak wiersze, scenariusze i utwory muzyczne.
- Edukacja i badania : spersonalizowane doświadczenia edukacyjne, generowanie treści edukacyjnych i wsparcie badawcze to potencjalne zastosowania.
- Biznes i marketing : Falcon może zasilać inteligentne chatboty, personalizować kampanie marketingowe i skutecznie analizować dane klientów.
Dodatkowe zasoby :
- Strona internetowa Falcon LLM: https://www.tii.ae/news/abu-dhabi-based-technology-innovation-institute-introduces-falcon-llm-foundational-large
- Karta modelu Sokoła Przytulającej Twarzy: https://huggingface.co/spaces/tiiuae/falcon-180b-demo
- Wpis na blogu TII Falcon: https://huggingface.co/tiiuae/falcon-180B
- Film YouTube na temat Falcona-180B: https://www.youtube.com/watch?v=9MArp9H2YCM
LAMA 2

Llama 2, model wielkojęzykowy typu open source opracowany przez Meta AI i Microsoft, prezentuje wyjątkowe możliwości w zakresie generowania różnorodnych treści, od wierszy po kod, odpowiadania na pytania i tłumaczenia języków. Przewyższa inne LLM w testach rozumowania i kodowania, kładąc nacisk na bezpieczeństwo poprzez uczenie się przez wzmacnianie i zapewniając „Przewodnik odpowiedzialnego użytkowania”. Będąc jeszcze w fazie rozwoju, użytkownicy powinni być świadomi potencjalnych niedokładności, stronniczych wyników i potrzeby posiadania wiedzy technicznej w celu optymalnego wykorzystania. Odpowiedzialne wykorzystanie ma kluczowe znaczenie dla uwolnienia pełnego potencjału Lamy 2 w rewolucjonizowaniu różnych dziedzin.
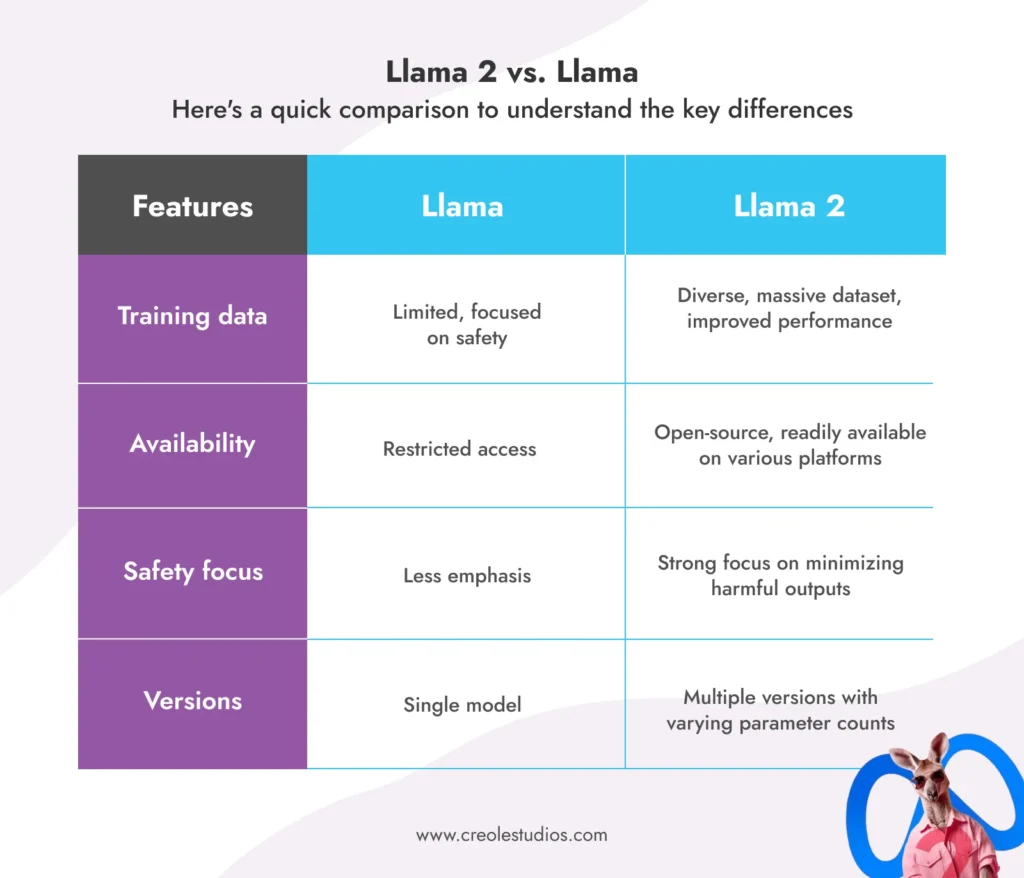
Zbudowana na fundamencie oryginalnej Lamy, Llama 2 przewyższa swoją poprzedniczkę pod kilkoma względami:
- Zróżnicowane szkolenie : szkolenie na znacznie większym i zróżnicowanym zestawie danych, zapewniające lepsze zrozumienie i wydajność w przypadku różnych zadań.
- Otwarta dostępność : w przeciwieństwie do ograniczonego dostępu swojej poprzedniczki, Llama 2 jest łatwo dostępna do celów badawczych, rozwojowych, a nawet zastosowań komercyjnych na platformach takich jak AWS, Azure i Hugging Face.
- Nacisk na bezpieczeństwo : Meta nadała priorytet bezpieczeństwu, wdrażając środki minimalizujące dezinformację, stronniczość i szkodliwe wyniki.
- Udoskonalone szkolenie : oferowane w różnych wersjach z liczbą parametrów od 7 miliardów do 70 miliardów, zaspokajające różnorodne potrzeby i zasoby.
Lama 2 kontra Lama:
Oto krótkie porównanie pozwalające zrozumieć kluczowe różnice:
Potencjalne zastosowania Lamy 2:
- Chatboty i wirtualni asystenci : ulepszone możliwości dialogu mogą zapewnić bardziej naturalne i wciągające interakcje.
- Generowanie tekstu i treść kreatywna : generuj różne formaty kreatywne, takie jak wiersze, skrypty lub kod, pomagając pisarzom i artystom.
- Generowanie kodu i programowanie : Pomóż programistom w zadaniach takich jak uzupełnianie kodu i wykrywanie błędów.
- Edukacja i badania : personalizuj doświadczenia edukacyjne, generuj treści edukacyjne i pomagaj badaczom w różnych zadaniach.
- Biznes i marketing : Popraw obsługę klienta za pomocą chatbotów, personalizuj kampanie marketingowe i analizuj dane klientów.
Ograniczenia i uwagi:
- Podobnie jak wszystkie LLM, Lama 2 jest wciąż w fazie rozwoju i może generować niedokładne lub stronnicze wyniki.
- Odpowiedzialne i etyczne korzystanie ma kluczowe znaczenie dla uniknięcia potencjalnego niewłaściwego użycia i stronniczości.
- Różne wersje wymagają różnych zasobów obliczeniowych, dlatego ważny jest wybór tej właściwej.
Zasoby:
- Strona internetowa Meta AI LLAMA: https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- Post na blogu Meta AI na temat LLAMA2: https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- Karta modelu Hugging Face LLAMA2: https://huggingface.co/models?search=llama
BLOOM spółka z ograniczoną odpowiedzialnością

Bloom LLM, zrodzona dzięki wspólnym wysiłkom globalnej społeczności, stała się prawdziwą siłą w krajobrazie sztucznej inteligencji typu open source. Oto obszerne zestawienie jego kluczowych funkcji, potencjalnych zastosowań i tego, co czyni go wyjątkowym:
Co to jest BLOOM LLM?
BLOOM to ogromny, wielojęzyczny LLM, oferujący 176 miliardów parametrów i przeszkolony w zakresie oszałamiających 46 języków i 13 języków programowania. Opracowany w ramach całorocznego wspólnego projektu z udziałem Hugging Face i badaczy z ponad 70 krajów, BLOOM ucieleśnia ducha sztucznej inteligencji o otwartym kodzie źródłowym.
Kluczowe cechy BLOOM:
- Wielojęzyczność : generuj spójny i precyzyjny tekst w aż 46 językach, wykraczając poza typowe modele skoncentrowane na języku angielskim.
- Dostęp typu open source : zarówno kod źródłowy, jak i dane szkoleniowe są publicznie dostępne, co sprzyja przejrzystości i udoskonaleniom kierowanym przez społeczność.
- Generowanie tekstu autoregresyjnego : płynnie rozszerza i uzupełnia sekwencje tekstowe, dzięki czemu idealnie nadaje się do różnych zadań kreatywnych i informacyjnych.
- Ogromna liczba parametrów : Dzięki 176 miliardom parametrów BLOOM zalicza się do najpotężniejszych rozwiązań LLM typu open source, oferujących doskonałą wydajność.
- Globalna współpraca : rozwój modelu ilustruje siłę współpracy międzynarodowej w rozwijaniu technologii sztucznej inteligencji.
- Bezpłatna dostępność : każdy może uzyskać dostęp do BLOOM i korzystać z niego za pośrednictwem platformy Hugging Face, demokratyzując dostęp do najnowocześniejszych narzędzi AI.
- Szkolenie na skalę przemysłową : szkolenie na ogromnej ilości danych tekstowych przy użyciu znacznych zasobów obliczeniowych, co zapewnia solidną wydajność.
Potencjalne zastosowania BLOOM:
- Komunikacja wielojęzyczna : Ułatw komunikację międzykulturową poprzez tłumaczenie tekstu i generowanie treści specyficznych dla języka.
- Twórcze pisanie i generowanie treści : pomagaj pisarzom i artystom w różnych formatach, takich jak wiersze, scenariusze, kod, utwory muzyczne itp.
- Edukacja i badania : personalizuj doświadczenia edukacyjne, generuj materiały edukacyjne i wspieraj wysiłki badawcze w różnych dziedzinach.
- Biznes i marketing : Popraw obsługę klienta dzięki wielojęzycznym chatbotom, personalizuj kampanie marketingowe i skutecznie analizuj dane.
- Rozwój sztucznej inteligencji o otwartym kodzie źródłowym : Służy jako podstawa do dalszych badań i rozwoju w zakresie sztucznej inteligencji o otwartym kodzie źródłowym, wspierając innowacje społeczności.
Co sprawia, że BLOOM jest wyjątkowy?
- Wielojęzyczność : W przeciwieństwie do wielu LLM skupiających się głównie na języku angielskim, wielojęzyczne możliwości BLOOM otwierają nowe możliwości globalnej komunikacji i zrozumienia.
- Otwartość i przejrzystość : Publiczny dostęp do kodu i danych szkoleniowych pozwala na szersze uczestnictwo w ulepszaniu i wykorzystywaniu modelu.
- Wspólny rozwój : stworzenie modelu w drodze globalnej współpracy pokazuje potencjał sztucznej inteligencji typu open source w zakresie pokonywania barier geograficznych i kulturowych.
Ograniczenia i uwagi:
- Podobnie jak w przypadku wszystkich LLM, BLOOM jest wciąż w fazie rozwoju i może generować niedokładne lub stronnicze wyniki. Odpowiedzialne i etyczne użytkowanie ma kluczowe znaczenie.
- Efektywne wykorzystanie BLOOM wymaga pewnej wiedzy technicznej i zrozumienia jego możliwości.
- Duży rozmiar modelu może wymagać znacznych zasobów obliczeniowych do wykonania niektórych zadań.
Zasoby:
- Strona BigScience BLOOM: https://huggingface.co/bigscience/bloom-intermediate
- Karta modelu BLOOM z przytulającą twarzą: https://bigscience.huggingface.co/blog/bloom
- Wpis na blogu BigScience na temat BLOOM: https://huggingface.co/bigscience/bloom
- Repozytorium kart modeli BLOOM na GitHub: https://github.com/bigscience-workshop/model_card
GPT-NeoX-20B

Jest to kolejny LLM typu open source, który zyskuje na znaczeniu i prezentuje niezwykłe możliwości i potencjał. Oto zestawienie jego kluczowych cech, mocnych stron i potencjalnych zastosowań:

Co to jest GPT-NeoX-20B?
- Opracowany przez EleutherAI, GPT-NeoX-20B to model języka autoregresyjnego o 20 miliardach parametrów wyszkolony na Pile, ogromnym zbiorze danych tekstu i kodu.
- Jego architektura zapożycza się z GPT-3, ale zawiera znaczące optymalizacje w celu poprawy wydajności i efektywności.
- GPT-NeoX-20B wyróżnia się w kilku obszarach:
- Rozumowanie nieliczne : wyjątkowo dobrze radzi sobie z zadaniami wymagającymi zrozumienia i zastosowania informacji z ograniczonej liczby przykładów.
- Generowanie długich tekstów : Generuje spójny i poprawny gramatycznie tekst nawet w przypadku długich sekwencji.
- Generowanie i analiza kodu : Potrafi zrozumieć i wygenerować kod, pomagając programistom w różnych zadaniach.
Mocne strony GPT-NeoX-20B:
- Otwarte oprogramowanie : kod i wagi modelu są publicznie dostępne, co zachęca społeczność do wkładu i badań.
- Efektywne szkolenie : wykorzystuje bibliotekę DeepSpeed do wydajnego szkolenia, wymagającego mniej zasobów obliczeniowych w porównaniu do innych LLM.
- Silne uczenie się w kilku krokach : wyjątkowo dobrze radzi sobie z zadaniami z ograniczoną ilością danych, dzięki czemu można je dostosować do różnych scenariuszy.
- Generowanie długiego tekstu : Generuje spójny i poprawny gramatycznie tekst nawet w przypadku długich sekwencji, idealny do kreatywnego pisania i generowania treści.
- Generowanie i analiza kodu : Rozumie i generuje kod, potencjalnie pomagając programistom w wykrywaniu błędów, uzupełnianiu kodu i innych zadaniach.
Potencjalne zastosowania GPT-NeoX-20B:
- Osobiści asystenci i chatboty : Zwiększ ich możliwości w zakresie rozumienia złożonych pytań i żądań oraz odpowiadania na nie.
- Twórcze pisanie i generowanie treści : pomagaj pisarzom i artystom w generowaniu różnych formatów kreatywnych, takich jak wiersze, scenariusze, utwory muzyczne itp.
- Edukacja i badania : personalizuj doświadczenia edukacyjne, generuj treści edukacyjne i wspieraj badania w różnych dziedzinach.
- Tworzenie oprogramowania : pomagaj programistom w zadaniach takich jak uzupełnianie kodu, wykrywanie błędów i analiza kodu.
- Badania nad sztuczną inteligencją typu open source : służą jako podstawa do dalszych badań i rozwoju w zakresie sztucznej inteligencji typu open source, wspierając innowacje.
Ograniczenia i uwagi:
- Podobnie jak w przypadku wszystkich LLM, GPT-NeoX-20B jest wciąż w fazie rozwoju i czasami może generować niedokładne lub stronnicze wyniki. Odpowiedzialne i etyczne użytkowanie ma kluczowe znaczenie.
- Wykorzystanie jego pełnego potencjału może wymagać pewnej wiedzy technicznej i zrozumienia jego możliwości.
- Rozmiar modelu może wymagać znacznych zasobów obliczeniowych do wykonania niektórych zadań.
Zasoby:
- Repozytorium EleutherAI GitHub: Jest to oficjalne repozytorium GPT-NeoX-20B, w którym można znaleźć kod źródłowy, skrypty szkoleniowe i wstępnie wytrenowane modele. (Źródło: https://github.com/EleutherAI/gpt-neox)
- Karta modelu Hugging Face: Karta modelu Hugging Face zapewnia kompleksowy przegląd GPT-NeoX-20B, w tym jego możliwości, ograniczenia i wyniki testów porównawczych. (Źródło: https://huggingface.co/EleutherAI/gpt-neox-20b)
- Wpis na blogu EleutherAI: Ten wpis na blogu EleutherAI przedstawia GPT-NeoX-20B, omawia jego architekturę i proces szkolenia oraz podkreśla niektóre z jego potencjalnych zastosowań. (Źródło: https://www.opensourceforu.com/2022/04/eleutherai-releases-gpt-neox-20b-a-20-billion-parameter-ai-language-model/)
MPT-7B

MPT-7B , skrót od MosaicML Pretrained Transformer, to potężny program LLM typu open source opracowany przez MosaicML Foundations. Może pochwalić się 7 miliardami parametrów i jest szkolony na ogromnym zestawie danych składającym się z 1 biliona tokenów, co czyni go skutecznym konkurentem w krajobrazie LLM. Oto zestawienie jego kluczowych funkcji i potencjalnych zastosowań, wraz z kilkoma odpowiednimi źródłami do dalszych badań:
Kluczowe cechy:
- Licencjonowanie komercyjne : W przeciwieństwie do wielu modeli typu open source, MPT-7B jest licencjonowany do użytku komercyjnego, otwierając firmom drzwi do wykorzystania jego możliwości.
- Obszerne dane szkoleniowe : szkolenie MPT-7B na zróżnicowanym zestawie danych składającym się z 1 biliona tokenów zapewnia solidną wydajność i możliwość dostosowania do różnych zadań.
- Obsługa długich danych wejściowych : model może obsługiwać wyjątkowo długie dane wejściowe bez utraty dokładności, dzięki czemu idealnie nadaje się do zadań takich jak podsumowywanie długich dokumentów.
- Szybkość i wydajność : zoptymalizowany pod kątem szybkiego uczenia i wnioskowania, MPT-7B zapewnia terminowe wyniki, kluczowe dla rzeczywistych zastosowań.
- Kod open source : Wydajny kod szkoleniowy modelu typu open source promuje przejrzystość i ułatwia wkład społeczności w jego rozwój.
- Doskonałość porównawcza : MPT-7B wykazał wyższą wydajność w porównaniu z innymi modelami typu open source w zakresie parametrów 7B-20B, nawet dorównującą jakością LLaMA-7B.
Potencjalne aplikacje:
- Analityka predykcyjna : MPT-7B może analizować duże zbiory danych w celu identyfikacji wzorców i trendów, informowania o decyzjach biznesowych i optymalizacji operacji.
- Wspomaganie podejmowania decyzji : Model może pomagać w złożonych procesach decyzyjnych, dostarczając spostrzeżeń i rekomendacji na podstawie przeanalizowanych danych.
- Generowanie treści i podsumowywanie : MPT-7B może generować różne kreatywne formaty tekstu, takie jak wiersze, skrypty lub kod, lub skutecznie podsumowywać długie dokumenty.
- Chatboty obsługi klienta : Rozumiejąc język naturalny i kontekst, MPT-7B może obsługiwać inteligentne chatboty w celu poprawy jakości obsługi klienta.
- Badania i rozwój : model może wspierać wysiłki badawcze w różnych dziedzinach poprzez analizę danych, generowanie hipotez i pomoc w twórczych poszukiwaniach.
Dodatkowe zasoby:
- Strona internetowa MosaicML MPT-7B: https://www.mosaicml.com/blog/mpt-7b
- Karta modelu Hugging Face MPT-7B: https://huggingface.co/mosaicml/mpt-7b
- Post na blogu MosaicML na temat MPT-7B: https://www.mosaicml.com/blog/mpt-7b
Wykorzystaj OpenSource LLM w Creole Studios
Modele wielkojęzyczne typu open source (LLM) przekształcają sztuczną inteligencję, oferując firmom elastyczność i innowacje. Świetnie nadają się do tworzenia nowych rozwiązań technologicznych i obniżania kosztów rozwoju. Jednak wyzwania takie jak prywatność danych i dostosowywanie do konkretnych potrzeb biznesowych mogą być złożone.
Creole Studios jest idealnym partnerem w radzeniu sobie z tymi wyzwaniami. Nasza wiedza specjalistyczna w zakresie sztucznej inteligencji i uczenia maszynowego oznacza, że możemy pomóc Twojej firmie efektywnie i bezpiecznie wykorzystać pełny potencjał rozwiązań LLM typu open source. Koncentrujemy się na tworzeniu dostosowanych do indywidualnych potrzeb rozwiązań, które są zgodne z Twoimi unikalnymi celami, zapewniając przewagę w szybko rozwijającym się krajobrazie sztucznej inteligencji.
Nawiąż współpracę z Creole Studios, aby przekształcić swoją podróż związaną ze sztuczną inteligencją dzięki mocy rozwiązań LLM typu open source.