
Gdzie przechowywać pliki Baza danych Nosql
Opublikowany: 2022-12-17Jeśli chodzi o przechowywanie plików w bazie danych NoSQL , należy wziąć pod uwagę kilka różnych czynników. Pierwszym z nich jest typ pliku, który chcesz przechowywać. Bazy danych NoSQL najlepiej nadają się do przechowywania danych częściowo ustrukturyzowanych, więc jeśli chcesz przechowywać takie rzeczy, jak obrazy, filmy lub inne dane binarne, możesz rozważyć inne opcje. Drugim czynnikiem, który należy wziąć pod uwagę, jest rozmiar plików, które chcesz przechowywać. Bazy danych NoSQL nie są zaprojektowane do obsługi dużych ilości danych, więc jeśli chcesz przechowywać pliki o rozmiarze kilku gigabajtów, możesz rozważyć inne opcje. Na koniec musisz wziąć pod uwagę bezpieczeństwo plików, które chcesz przechowywać. Bazy danych NoSQL nie są tak bezpieczne jak tradycyjne relacyjne bazy danych, więc jeśli chcesz przechowywać poufne informacje, możesz rozważyć inne opcje.
Obecnie na rynku dostępne są dwa główne systemy zarządzania bazami danych, RDBMS i NoSQL (magazyny klucz-wartość, magazyny rodzin kolumn, bazy danych dokumentów i bazy danych wykresów). Podczas korzystania z relacyjnych baz danych możliwe jest uruchamianie danych z nieustrukturyzowanej bazy danych (BPLOB). Zwykle zakłada się, że dane pliku są przechowywane w innych częściach systemu plików, a nie w bazie danych, a w bazie danych dostępna jest tylko ścieżka lub odwołanie. GridFS może być używany do dużych dokumentów, które można odczytać tylko o rozmiarze mniejszym niż 16 MB. Technika ta służy do przechowywania dużych ilości danych, takich jak obrazy, audio, wideo lub cokolwiek innego w plikach bazy danych. Aby poprawić wydajność, GridFS stosuje indeks w każdym fragmencie i pliku. Aplikacja demonstracyjna, składająca się z encji i relacji, miała dwie warstwy baz danych: jedną dla NoSQL (Kundera) i jedną dla relacyjnych baz danych (Hibernate).
Czy możesz przechowywać pliki w bazie danych Nosql?
Bazy danych dokumentów są bardziej podobne do baz danych NoSQL niż do relacyjnych baz danych. W rezultacie SQL jest klasyfikowany jako „nie tylko SQL”, a wszystkie modele danych są podzielone przez elastyczne modele danych. Baza danych NoSQL może składać się z kilku typów, w tym czystych baz danych dokumentów, magazynów klucz-wartość, szerokokolumnowych baz danych i baz danych wykresów.
Dzięki NoSQL dane mogą być przechowywane w plikach, a nie w bazie danych. Możliwe jest przechowywanie ustawień, przechowywanie małych danych i przechowywanie plików. Podejście NoSQL ma pewne zalety, takie jak łatwość użycia i szybkość, ale ma też pewne wady. Może tak być na przykład dlatego, że musisz kontrolować pracę za pomocą własnego kodu. Dane mogą być serializowane w bazie danych, w tym dane tymczasowe. Jeśli potrzebujesz zapisać niewielkie ilości danych, opcja przechowywania plików jest również opcją. Pliki pamięci podręcznej mogą być również przydatne, jeśli zawierają duże ilości danych. Gdy tylko jedna lub więcej pamięci podręcznych lub sekcji zostanie wyczyszczonych, pliki te mogą zostać automatycznie utworzone i wyczyszczone.
W przypadku katastrofy kopia danych jest zachowywana.
Ma to na celu umożliwienie przechowywania danych, które nie są fizycznie dostępne.
Pliki kopii zapasowych dla Apache Cassandra są przechowywane w tym samym katalogu, co pliki bazy danych dla Apache Cassandra. Do kompresji plików kopii zapasowej użyto algorytmu kompresji gzip.
Jeśli zamierzasz przechowywać dużą ilość danych, zaleca się korzystanie z bazy danych Apache Cassandra. Nie ma problemu z tym, że radzi sobie z milionami obiektów; kopie zapasowe są przechowywane w tym samym katalogu co baza danych.
Dlaczego Nosql to najlepszy sposób na przechowywanie dużych plików
MongoDB może bez problemu obsługiwać duże pliki, a duże pliki można łatwo przechowywać w MongoDB. System plików nie jest już używany i korzystanie z niego ma wiele zalet w porównaniu z przechowywaniem plików na komputerze. Dane w bazie danych nie stanowią problemu w taki sam sposób, jak w systemie plików. Ponadto baza danych może służyć do indeksowania plików, dzięki czemu można je szybko przeszukiwać. Z drugiej strony baza danych NoSQL nie zawiera plików; zawiera raczej funkcje. Wybór systemu plików innego niż NoSQL nie jest najlepszym rozwiązaniem, jeśli dane są relacyjne.
Gdzie są przechowywane dane w Nosql?
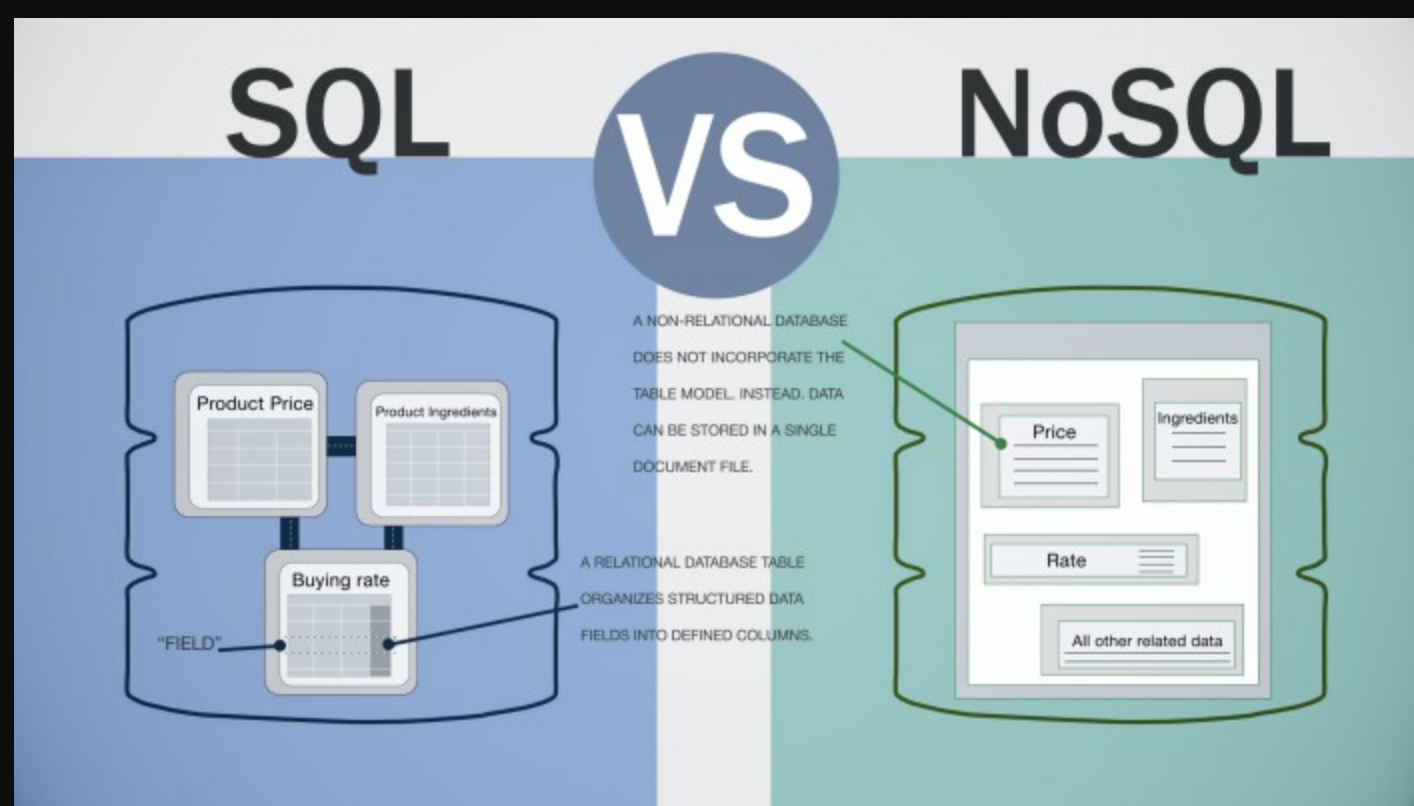
Nie ma konkretnej odpowiedzi na to pytanie, ponieważ zależy to od typu używanej bazy danych NoSQL. Na przykład magazyn klucz-wartość może przechowywać dane w prostym pliku lub w pamięci, podczas gdy baza danych dokumentów może przechowywać dane w dokumentach JSON lub XML. Baza danych zorientowana na kolumny może przechowywać dane w kolumnach zamiast w wierszach, a baza danych wykresów może przechowywać dane w strukturze grafu.
Magazyn danych pary klucz-wartość Redis w pamięci jest typu open source i można uzyskać do niego dostęp. Baza danych sesji może być używana do różnych celów, takich jak buforowanie, kolejkowanie i przechowywanie danych. Baza danych NoSQL jest powszechnie używana do zastąpienia lub uzupełnienia istniejącej relacyjnej bazy danych. Mają odmienne charakterystyki wydajnościowe od relacyjnej bazy danych, jeśli chodzi o typy trwałości. Klient Pythona to powszechny sposób łączenia się z instancjami MongoDB. MongoEngine to Python ORM zbudowany na bazie PyMongo, który jest specjalnie zaprojektowany dla MongoDB. Używając terminów Wprowadzenie do Graph Databases i Graph Database Comparisons, badamy trendy w magazynach danych NoSQL i porównujemy je z innymi typami magazynów danych. Dowiesz się o znaczeniu NoSQL, sposobie przechowywania danych oraz o tym, co oznacza twierdzenie o spójności, dostępności i tolerancji partycji (CAP). Ogólnie rzecz biorąc, dane sesyjne są przechowywane w pamięci szybciej niż w tradycyjnej bazie danych , która przechowuje dane w sposób ciągły.
Plusy i minusy baz danych Nosql
Bazy danych NoSQL zyskują na popularności ze względu na swoją wszechstronność i możliwość przechowywania danych w różnych formatach. DynamoDB, Riak i Redis to tylko niektóre z baz danych NoSQL, które ludzie znają. Baza danych NoSQL różni się od tradycyjnej relacyjnej bazy danych na wiele sposobów. Podstawową różnicą jest to, że dane są przechowywane w dokumentach JSON, a nie w kolumnach i wierszach. W rezultacie bardziej dynamiczny i elastyczny model przechowywania jest bardziej odpowiedni dla danych specyficznych dla każdego segmentu rynku. Jedną z kluczowych różnic między bazami danych NoSQL a tradycyjnymi bazami danych jest sposób wyszukiwania danych. Ponieważ bazy danych NoSQL używają innej składni zapytań niż relacyjne bazy danych, ich opanowanie może być trudne dla początkujących użytkowników. Mimo to bazy danych NoSQL są doskonałymi kandydatami do bardziej złożonych zadań ze względu na swoją elastyczność i moc. Popularność baz danych NoSQL wynika przede wszystkim z ich zdolności do obsługi szerokiej gamy formatów danych i zarządzania stale rosnącym zakresem źródeł danych. Bazy danych NoSQL mogą obsługiwać szeroki zakres zadań i wyzwań, co czyni je doskonałym wyborem dla organizacji, które muszą zarządzać wieloma zadaniami i wyzwaniami.
Co powinienem przechowywać w Nosql?
Nie ma jednoznacznej odpowiedzi na to pytanie, ponieważ zależy to od konkretnych potrzeb Twojej aplikacji. Jednak niektóre ogólne wytyczne obejmują przechowywanie danych, które są często używane lub aktualizowane, danych, które nie są łatwo relacyjne, oraz danych, które nie mają struktury lub są częściowo ustrukturyzowane.
Jest to język programowania, który używa nietradycyjnych metod przechowywania danych zamiast tradycyjnych metod przechowywania danych. Dostępnych jest kilka typów rozwiązań NoSQL w zależności od zastosowanego modelu danych oraz sposobu dystrybucji replikacji. Przedstawiono opis każdego z tych typów oraz dziedzinę, w której są one stosowane. Identyfikator_regionu i identyfikator_przemysłu są połączone z tabelami obcymi, a nie ciągami tekstowymi, takimi jak Dobroczynność lub Obszar Seattle w reprezentacji profilu. Dokonano tego z różnych powodów, w tym z możliwości postawienia zarzutów karnych. Ponieważ wymagane jest duplikowanie danych, ciąg tekstowy lub identyfikator nie mogą być przechowywane oddzielnie. Normalizacja bazy danych wymaga czegoś więcej niż tylko technicznej zdolności bazy danych; do tego potrzeba czegoś więcej niż struktury dokumentów, takiej jak Couchbase.
Chociaż bazy danych NoSQL stają się coraz bardziej popularne, nie oznacza to, że są idealne do każdej aplikacji. Środowisko NoSQL nie zapewnia elastyczności środowiska wykonawczego, dlatego należy go całkowicie unikać.
W tej kategorii MongoDB jest zdecydowanym zwycięzcą ze względu na swoją wydajność i skalowalność. Ponadto programiści doceniają łatwość użytkowania, jaką zapewnia.
W rezultacie, jeśli szukasz bazy danych NoSQL, która ogólnie dobrze działa i zapewnia doskonałą użyteczność, MongoDB jest dobrym wyborem.
Jak przechowywać obrazy w bazie danych Nosql
Istnieje wiele sposobów przechowywania obrazów w bazie danych nosql. Jednym ze sposobów jest przechowywanie obrazów jako ciągów zakodowanych w formacie base64 w bazie danych. Innym sposobem jest przechowywanie obrazów w systemie plików i przechowywanie ścieżki pliku w bazie danych.
Trwa święta wojna o to, czy przechowywać obrazy w bazie danych, czy w systemie plików. Przez większość czasu schodzę z boku systemu plików, ponieważ jest on znacznie większy. Niezależnie od tego, jak zdecydujesz się kontynuować, każda z opcji najprawdopodobniej będzie dobrze pasować do rozmiaru Twojego projektu. Riak został opisany jako zmieniacz gry w tej dziedzinie. Aby Riak nie spowodował awarii ogromnego serwera, należy użyć odpowiedniej konfiguracji. Jeśli używasz Pythona, moduł y_serial z sourceforge.net może być używany do przechowywania i uzyskiwania dostępu do obrazów (dowolnych dowolnych obiektów Pythona, w tym stron internetowych) w formie skompresowanej, aw przypadku NoSQL jest dostępny dla dowolnego programu Pythona.
Która baza danych ma przechowywać obrazy?
Duże obiekty statyczne powinny być przechowywane na serwerze, takim jak AWS S3, HDFS, Content Delivery Network (CDN), serwer WWW, serwer plików lub cokolwiek innego, co najlepiej pasuje do konkretnego przypadku użycia i budżetu.
Czy możemy przechowywać dane obrazu w bazie danych?
Podczas tworzenia bazy danych można przechowywać w tabeli bazy danych różne małe obrazy i inne informacje. Nie jest wymagane posiadanie tabeli bazy danych, aby na przykład stworzyć internetowy album fotograficzny z listą swoich zdjęć. W przypadku braku kopii zapasowej należy unikać przechowywania obrazów w tabeli bazy danych.
Czy baza danych SQL może przechowywać obrazy?
SQL Server utworzył typ danych IMAGE do przechowywania plików obrazów. Ponieważ IMAGE zostanie wycofany w przyszłej wersji MS SQL Server, Microsoft zaczął sugerować VARBINARY (MAX) jako alternatywę do przechowywania dużej ilości danych w jednej kolumnie.

Baza danych do przechowywania plików
Baza danych do przechowywania plików może służyć do przechowywania różnych plików, w tym obrazów, filmów i dokumentów. Ten typ bazy danych może służyć do przechowywania plików w określonym celu lub do udostępniania plików innym osobom. Baza danych do przechowywania plików może służyć do tworzenia kopii zapasowych plików, porządkowania plików lub przechowywania plików do późniejszego wykorzystania.
Termin „plik” odnosi się do wszystkiego, co przekracza tysiąc słów lub mniej. W bazach danych istnieje kilka rodzajów obiektów blob, które mogą być dużymi, dowolnymi sekwencjami bajtów i są obsługiwane przez dużą liczbę baz danych. Czy możesz sobie pozwolić na ograniczenie (np. do kilku megabajtów) rozmiaru pliku? Własność danych, zarządzanie danymi, czas i uprawnienia są również dość powszechne. W Linuksie zaleca się skonfigurowanie narzędzi inotify(7) do powiadamiania o zdarzeniach związanych z systemami plików (na przykład ext4). Ponieważ pliki są abstrakcją twojego systemu operacyjnego, można je znaleźć niezależnie od bazy danych (zakładając, że istnieją w ten sposób). Niektóre programy zewnętrzne mogą zostać utworzone, odczytane, zapisane lub usunięte. Ponieważ wiele DBMS ogranicza zawartość tablicy, często robisz coś przeciwnego do tego, co sugeruje twoje pytanie.
Plusy i minusy przechowywania plików w bazie danych
Baza danych może przechowywać pliki z różnych powodów, w tym szybszego odzyskiwania danych i bezpieczniejszego przechowywania. Przed podjęciem decyzji bardzo ważne jest rozważenie zarówno zalet, jak i wad obu opcji. W tym artykule zbadamy zarówno przechowywanie plików w bazie danych, jak i przechowywanie ich w innym miejscu, aby określić, co jest lepsze dla aplikacji.
Zawartość plików może być przechowywana w bazie danych lub może być przechowywana w innym miejscu i indeksowana w bazie danych. W tym artykule zademonstrujemy obie te techniki przy użyciu podstawowej aplikacji Image Archive.
Baza danych programu SQL Server może przechowywać nieustrukturyzowane dane plików i hierarchie katalogów dzięki funkcji FileTable. Dostęp do danych opartych na plikach można uzyskać bez transakcji dzięki tej funkcji, która umożliwia również aplikacjom Windows obsługę dostępu opartego na plikach.
Często przyjmuje się, że przechowywanie plików w bazie danych jest wygodniejszą opcją, ponieważ zapewnia lepsze odzyskiwanie danych i jest bezpieczniejsze.
Przechowywanie plików Mongodb
MongoDB oferuje różnorodne funkcje, w tym przechowywanie plików. Dzięki MongoDB pliki mogą być przechowywane w bazach danych, co ułatwia zarządzanie nimi i dostęp do nich. Dodatkowo funkcja przechowywania plików MongoDB oferuje funkcje bezpieczeństwa i prywatności, zapewniając, że pliki są chronione i bezpieczne.
Klienci mogą korzystać z implementacji GridFS we własnych aplikacjach. Ponieważ można pobrać dowolną część kolekcji plików lub fragmentów, każde zapytanie zwróci ten sam wynik. Osiągnięcie wysokiej wydajności odczytu przy małych plikach bezpośrednio z pamięci RAM może być niemożliwe, ale osiągnięcie wysokiej wydajności zapisu byłoby równie możliwe. Nie ma czegoś takiego jak duży plik. Średni rozmiar porcji wynosi 256 KB, co oznacza, że plik o wielkości 600 GB zawiera około 3069 stron. Aby rozwiązać ten problem, należy zacząć od jednego pliku w dużej liczbie odłamków. To prawda, że S3 w formatach o ograniczonej redundancji działa najlepiej dla MongoDB, ale może zajmować nawet dziesięć razy więcej miejsca niż zwykły MongoDB .
Tworzenie katalogu danych MongoDB jest tak proste, jak kopiowanie danych z jednego miejsca do drugiego. Aby rozpocząć, uruchom wiersz polecenia i wpisz md c:/data/db. Po zakończeniu procesu tworzenia katalog danych MongoDB zostanie utworzony, a monit zostanie zakończony. Następujące polecenie zmieni lokalizację katalogu danych MongoDB: Katalog danych MongoDB c:/data/db/mynewdir.
Gridfs to świetny sposób na przechowywanie dużych plików w Mongodb
MongoDB ma fantastyczną funkcję o nazwie GridFS, której można używać do przechowywania dużych plików. Jeśli masz system plików, który ogranicza liczbę plików w katalogu, GridFS może przechowywać tyle plików, ile potrzebujesz. GridFS umożliwia również przechowywanie wielu plików w tym samym katalogu w tym samym czasie.
Przechowywanie plików w relacyjnej bazie danych
Przechowywanie plików w relacyjnej bazie danych to proces, w którym dane są przechowywane w powiązanych ze sobą plikach. Ten proces może służyć do przechowywania danych w różnych formatach, w tym tekstu, obrazów i SQL.
Powszechnie uważa się, że przechowywanie plików binarnych w bazie danych to zły pomysł. Uważa się, że dotyczy to szczególnie czytania i pisania. Jest to jedna z najbardziej podstawowych cech relacyjnej bazy danych: jest w pełni ACID. Jeśli przechowujesz dane w bazie danych do poufnych celów, korzystne może być (ponowne) rozważenie przechowywania plików w bazie danych jako obiektów BLOB. Oracle SecureFiles, jak sama nazwa wskazuje, jest przeznaczony przede wszystkim jako narzędzie marketingowe, ale może być używany do rozwiązywania różnych problemów typu BLOB. SecureFiles jest również niezwykle prosty w użyciu. To dokładnie tak, jak każdy inny rodzaj płynu.
Tworząc kolumnę BLOB, możesz po prostu określić STORE AS SECUREFILE w kolumnie CREATE BLF. Gdy Oracle obsługuje FUSE, Linux powinien mieć możliwość zamontowania obiektu BLOB SecureFile jako systemu plików. Zamiast blokowania w Oracle, twoje pliki binarne niekoniecznie są blokowane w jakikolwiek sposób.
Różne sposoby przechowywania danych w relacyjnej bazie danych
Dane tabelaryczne są niezbędnym elementem relacyjnej bazy danych. Dane tabeli przechowują informacje w określonej kolejności, podobnie jak dane folderów, ale towarzyszą im również kolumny i wiersze. Każda tabela ma swoją nazwę, a każda kolumna w niej jest powiązana z określonym typem danych. Na przykład nazwa tabeli dla osób może zawierać kolumnę zawierającą imię i nazwisko osoby, nazwisko i adres e-mail. Każdy wiersz zawiera dokument. Struktura każdego dokumentu w tabeli jest różna, ale wszystkie dokumenty w tabeli są przechowywane w tej samej kolejności. Każda kolumna w tabeli reprezentuje pole w dokumencie, podczas gdy każde pole w dokumencie reprezentuje kolumnę w tabeli. Na przykład tabela z kolumną ludzie może zawierać pole z imieniem. Baza danych najpierw sprawdzi dokument w tabeli, aby sprawdzić, czy jest to dokument, do którego można uzyskać dostęp. Dokument nie może zostać znaleziony, jeśli nie jest widoczny w indeksach tabeli; baza danych następnie go szuka. Jeśli dokumentu nie można znaleźć w indeksach, baza danych poszuka go w plikach tabeli. Dane w relacyjnej bazie danych mogą być przechowywane w magazynie opartym na tabelach, który jest najbardziej powszechnym typem przechowywania danych. System przechowywania oparty na tabelach tworzy oddzielną tabelę dla każdego dokumentu. Nazwa tabeli ma taką samą nazwę jak nazwa pliku dokumentu. Przechowywanie danych oparte na indeksach, znane również jako przechowywanie relacyjnych baz danych, to kolejny popularny sposób przechowywania dokumentów w relacyjnej bazie danych. Każdy dokument jest przechowywany oddzielnie w systemie przechowywania opartym na indeksach. Nazwa indeksu ma taką samą strukturę jak nazwa pliku. Przechowywanie oparte na kolumnach to trzeci powszechny typ przechowywania danych używany do dokumentów w relacyjnej bazie danych. Każdy dokument w magazynie opartym na kolumnach jest przechowywany w osobnej kolumnie. Gdy nazwa kolumny jest taka sama jak nazwa pliku, nie ma między nimi rozróżnienia. Bardzo ważne jest, aby pamiętać, że każdy rodzaj przechowywania danych ma swój własny zestaw zalet i wad. Przechowywanie oparte na tabelach jest najbardziej powszechnym rodzajem przechowywania danych. Wadą przechowywania opartego na tabelach jest to, że znalezienie dokumentu, jeśli nie znasz nazwy jego tabeli, może być trudne. Jedną z zalet przechowywania opartego na tabelach jest łatwość dodawania i usuwania dokumentów.
Baza danych Nosql
Baza danych NoSQL to baza danych, która nie korzysta z tradycyjnej struktury relacyjnej bazy danych opartej na tabelach. Bazy danych NoSQL są często używane do przechowywania dużych ilości danych, których nie można łatwo przechowywać w relacyjnej bazie danych.
Baza danych Bazy danych NoSQL przechowują dane w dokumentach, a nie w tabelach o charakterze relacyjnym. Hurtownia danych to zbiór składników oprogramowania, które można skonfigurować tak, aby w elastyczny, skalowalny i szybki sposób spełniały potrzeby nowoczesnej firmy w zakresie zarządzania danymi. Baza danych NoSQL może składać się z jednego lub kilku typów baz danych, w tym baz danych zawierających wyłącznie dokumenty, magazynów klucz-wartość, baz danych o szerokich kolumnach i baz danych wykresów. Firmy z listy Global 2000 szybko wdrażają bazy danych NoSQL do obsługi aplikacji o znaczeniu krytycznym. Powodem tego jest pięć trendów, które są trudne do zaimplementowania w większości relacyjnych baz danych. Ze względu na stały model danych relacyjne bazy danych są nieefektywne w zwinnym rozwoju, co czyni je istotną przeszkodą. Modele NoSQL są oparte na modelach aplikacji i zawierają model danych.
Użycie NoSQL nie oznacza, że dane muszą być modelowane na zawsze. JSON to de facto format przechowywania danych w bazie danych zorientowanej na dokumenty. W ten sposób ramy ORM są zmniejszone, a tworzenie aplikacji jest uproszczone. W Couchbase Server 4.0 wprowadzono język zapytań N1QL (czyt. nikiel). Ten program obsługuje również agregację (GROUP BY), sortowanie (SORT BY), łączenia (LEFT OUTER) i inne typy instrukcji oprócz standardowego SELECT / FROM / WHERE. Rozproszona baza danych NoSQL może oferować szereg istotnych korzyści operacyjnych, ponieważ wykorzystuje architekturę skalowalną w poziomie i nie ma pojedynczego punktu awarii. Dostępność staje się kwestią krytyczną, ponieważ coraz więcej klientów wchodzi w interakcje z organizacjami online za pośrednictwem aplikacji internetowych i mobilnych.
Bazy danych NoSQL są proste w konfiguracji, konfiguracji i skalowaniu. Zostały one specjalnie zaprojektowane do obsługi odczytów, zapisów i przechowywania. Można ich używać w dowolnym rozmiarze i można ich używać do zarządzania i monitorowania klastrów o różnych rozmiarach. Baza danych NoSQL została zbudowana w celu replikacji między wieloma centrami danych bez konieczności stosowania dodatkowego oprogramowania. Ponadto zapewnia natychmiastowe przełączanie awaryjne za pośrednictwem routerów sprzętowych, umożliwiając aplikacjom samodzielne przywracanie po awarii w przypadku awarii bazy danych. Obecnie NoSQL jest używany w coraz większej liczbie aplikacji internetowych, mobilnych i Internetu rzeczy (IoT).
Dlaczego bazy danych Nosql przejmują popularność
Często zdarza się, że bazy danych NoSQL są popularne ze względu na różne czynniki. Oferują nowy sposób patrzenia na dane, który może być bardziej wydajny dla konkretnej aplikacji. Ponadto mogą obsługiwać większe ilości danych niż tradycyjne bazy danych ze względu na swoją skalowalność. Po trzecie, projektowanie i konserwacja tych baz danych jest znacznie prostsza niż w przypadku tradycyjnych baz danych.