
Dlaczego Apache HBase to najlepszy wybór dla Twojego następnego projektu Big Data
Opublikowany: 2022-11-16Apache HBase to otwarta, nierelacyjna, rozproszona baza danych wzorowana na Bigtable firmy Google i napisana w Javie. Jest rozwijany jako część projektu Apache Hadoop Apache Software Foundation i działa na HDFS (Hadoop Distributed File System), zapewniając możliwości podobne do Bigtable dla Hadoop. Podobnie jak Bigtable, HBase jest przeznaczony do obsługi dużych ilości danych z dużą przepustowością i jest odpowiedni dla aplikacji, które wymagają dostępu do danych z małymi opóźnieniami.
HBase, baza danych NoSQL, służy do przechowywania i pobierania danych z dostępem swobodnym. Model danych w nim jest dynamiczny i elastyczny, co pozwala na przechowywanie dowolnego typu danych bez ograniczeń. HBase można zintegrować z MapReduce Apache Hadoop w celu wykonywania operacji masowych (np. indeksowania, analiz itd.). HBase to rzadka, wielowymiarowa, posortowana baza danych oparta na mapach z wieloma wersjami pojedynczego rekordu. Dzięki wbudowanej obsłudze Hadoop MapReduce może obsłużyć duże ilości danych z prędkością błyskawicy i równolegle. Architektura HBase składa się z czterech głównych komponentów: HMaster, HRegion, Hlog i HBase. ZooKeeper to projekt typu open source, który zapewnia kilka podstawowych usług, oprócz kilku podstawowych funkcji.
ZooKeeper zawiera funkcję umożliwiającą rozproszoną synchronizację danych konfiguracyjnych. Gdy węzeł ulegnie awarii w HBase, zkQuorum generuje komunikaty o błędach i rozpoczyna naprawę. Ropa naftowa i ropa naftowa, marketing i reklama, bankowość i giełda to tylko niektóre z dziedzin, w których jest używany HBase.
Jako rozproszony system plików, użycie HDFS w HBase ma pewne zalety. Baza danych może więc przechowywać duże zbiory danych, nawet miliardy wierszy, w krótkim czasie, co pozwala na szybką analizę.
Wykorzystuje zorientowane na kolumny, nierelacyjne podejście do zarządzania bazą danych. Informacje są przechowywane w poszczególnych kolumnach i indeksowane przy użyciu unikalnego klucza wiersza, który jest unikalny dla każdej kolumny. Architektura ta zapewnia szybkie i wydajne wyszukiwanie poszczególnych wierszy i kolumn, a także wydajny proces skanowania poszczególnych kolumn w tabeli.
Apache HbaseNazwa firmyWitryna internetowaPrzychodyFacebookwww.Facebook.com117 miliardów USDHortonworks Incwww.hortonworks.com75 milionówJP Morgan Chasewww.JPMorganChase.com130 miliardów Palo Alto Networks Incwww.palo Alto
W MongoDB do wyboru jest kilka rodzajów funkcji projekcji, filtrowania i agregacji. W przeciwieństwie do Hbase, który łączy dane z kluczowymi wartościami, kluczowe wartości mogą być udostępniane innym aplikacjom. MongoDB umożliwia wyszukiwanie tekstu poprzez dostarczanie natywnych indeksów tekstowych oraz replikację danych HBase .
Czy Hadoop jest bazą danych Nosql?

Hadoop to platforma oprogramowania typu open source do przechowywania i przetwarzania dużych zbiorów danych. Wykorzystuje rozproszony system plików (HDFS) i MapReduce do przetwarzania i analizy danych. Hadoop nie jest tradycyjną relacyjną bazą danych, ale może służyć do przechowywania i przetwarzania danych w podobny sposób.
W MongoDB nie ma potrzeby stosowania dokumentów, ponieważ baza danych jest oparta na modelu danych JavaScript Object Notation (JSON). Ma być szybki i prosty w użyciu, a także mieć dobrze zdefiniowany indeks i możliwości wyszukiwania. Algorytm mapowania/zmniejszania jest używany do przetwarzania ogromnych zbiorów danych w Hadoop, rozproszonym systemie pamięci masowej. Ten produkt został zaprojektowany jako ekonomiczne rozwiązanie do analizy i archiwizacji danych.
Czy Hbase używa Sql?
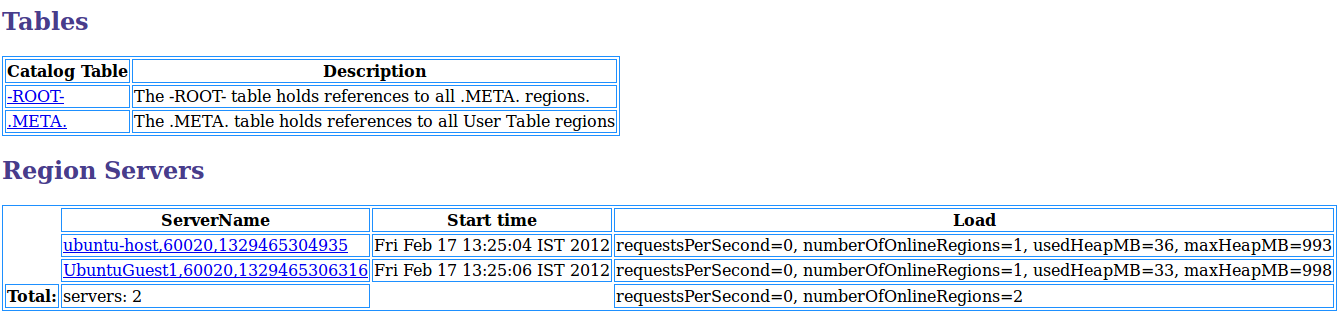
HBase nie jest relacyjną bazą danych i nie używa języka SQL do wykonywania zapytań dotyczących danych. HBase używa projektu magazynu klucz/wartość, który jest zoptymalizowany pod kątem szybkiego dostępu do odczytu/zapisu do dużych zestawów danych.
Ze względu na wysoką skalowalność, obsługę programowania Hadoop z redukcją map i implementację dobrze znanej białej księgi Google BigTable, HBase jest doskonałym wyborem do przechowywania danych nieustrukturyzowanych. Łatwość obsługi HBase jest głównym atutem aplikacji magazynowych, które muszą szybko przetwarzać duże ilości danych.
Co to jest język zapytań Hbase?
Jaspersoft HBase Query Language, który jest językiem deklaratywnym w stylu JSON, umożliwia określenie, jakie dane mają zostać pobrane z HBase. Podczas korzystania z interfejsu HBase REST Server, konektor konwertuje zapytanie na odpowiednie wywołanie API, które jest następnie wykonywane na instancji HBase .
Korzyści z używania tabeli Hbase
Co to jest rodzina kolumn? Rodzina kolumn może odnosić się do zbioru kolumn, które mają wspólną nazwę i typ danych. Nazwiska pracowników mogą zawierać kolumny id,name,hired_on,fired_on. Jakie są korzyści z używania tabel HBase ? Tabela HBase zapewnia następujące korzyści: Zorientowany na kolumny projekt HBase ułatwia przechowywanie i dostęp do danych, które są rzadkie lub nieustrukturyzowane. Ze względu na swoją odporność na awarie, HBase może wytrzymać okazjonalną utratę lub uszkodzenie danych. Ponieważ HBase jest tak prosty w użyciu, możesz szybko zacząć korzystać z magazynu dużych zbiorów danych. Ponieważ HBase jest skalowalny, możesz dodać więcej serwerów do klastra, aby obsłużyć większe zestawy danych.
Do czego nie nadaje się Hbase?
Funkcje takie jak SQL nie mogą być wykonywane przy użyciu HBase HBase . Ponieważ nie obsługuje struktury SQL, nie ma optymalizacji zapytań. HBase wymaga dużej ilości procesora i pamięci, z dużymi sekwencyjnymi wejściami i wyjściami, podczas gdy zadania Map Reduce są zwykle związane z wejściem lub wyjściem ze stałą pamięcią i wymagają dużo procesora i pamięci.
Hbase: najlepsze rozwiązanie do przechowywania danych dla losowych operacji odczytu i zapisu
Jest idealny dla aplikacji, które wykonują zarówno losowe operacje odczytu, jak i losowego zapisu, a także dla tych, które używają losowych operacji odczytu i losowego zapisu. HBase jest również dobrym wyborem dla aplikacji wymagających dostępu do danych w czasie rzeczywistym.
Czy Hbase jest jak Cassandra?

W przeciwieństwie do Cassandry, która działa na wielu serwerach i wersjach tego samego pliku, Hbase działa na jednym serwerze danych. W rezultacie odczyty Hbase są łatwiej dostępne niż odczyty Cassandry. Dane Hbase są przechowywane w HDFS, gdzie ma filtry bloom i blokowe pamięci podręczne, które pozwalają na szybsze odczyty.
Te bazy danych NoSQL, które mogą obsługiwać duże zestawy danych, zostały zbudowane przez firmę Cassandra i HBase. Mają wiele wspólnych cech, w tym wspólne cechy. Na pierwszy rzut oka oba są różne. W tym artykule przyjrzymy się, jak HBase i Cassandra różnią się pod względem zaangażowanych czynników. Cassandra, podobnie jak HBase, ma infrastrukturę Hadoop , ale ma też różne DBMS i infrastrukturę. Cassandra nie wymaga dodatkowej mocy obliczeniowej. Indeksowanie za pomocą filtrów Bloom jest tym, co robi HBase.
Za pomocą Cassandry można replikować wiele wierszy z pojedynczego adresu WAN z losowymi partycjami. Lepiej jest mieć jedno źródło danych niż wiele źródeł danych na temat Cassandry. Co więcej, instalacja Cassandra Cluster jest łatwiejsza niż HBase Cluster .
Hbase kontra Cassandra: co jest lepsze?
Zarówno Cassandra, jak i HBase mogą być odczytywane i zapisywane w tym samym czasie, ale Cassandra jest szybsza. Co więcej, Cassandra jest szybsza niż HBase.
Hbase kontra Mongodb
Nie ma wyraźnego zwycięzcy przy porównywaniu HBase i MongoDB. Oba systemy mają swoje mocne i słabe strony. HBase lepiej nadaje się do obsługi dużych ilości danych, podczas gdy MongoDB jest bardziej elastyczny i łatwiejszy w użyciu.
Po 4 latach korzystania z couchbase przeszliśmy na MongoDB i przejście przebiegło bezproblemowo. Pomimo otrzymania wsparcia dla przedsiębiorstw, mieliśmy okropne doświadczenia z Couchbase. W przypadku wyszukiwania pełnotekstowego często zwracanych jest wiele typów wyników, jeśli uruchomisz różne zapytania. Nie ma możliwości poprawnego skonfigurowania indeksów w systemie Windows. Serwer produkcyjny może obsługiwać do sześciu użytkowników. Oprócz obsługi pamięci podręcznej w pamięci Couchbase zawiera mniejszą instancję Memcached. Każdy z 5000 dokumentów zajmuje 8 GB pamięci RAM. Nie ma co do tego wątpliwości! W instancji Couchbase było mniej niż 5000 dokumentów, mniej niż 20 indeksów, a zużycie pamięci RAM zawsze przekraczało 8 GB.
Główną różnicą między Amazon DynamoDB i Apache HBase jest to, że Amazon DynamoDB jest zbudowany na HDFS, który zapewnia szybkie wyszukiwanie rekordów (i aktualizacje) dla dużych tabel. Rozproszony system plików, taki jak HDFS, jest idealny do przechowywania dużych plików. Z drugiej strony HBase jest zbudowany na bazie HDFS i może z łatwością wyszukiwać (i aktualizować) rekordy dla dużych tabel.
Ponadto Amazon DynamoDB jest magazynem kluczy/wartości i dokumentów, w przeciwieństwie do Apache HBase, który jest magazynem kluczy/wartości i dokumentów. Aby uzyskać pełniejsze porównanie Amazon DynamoDB i Apache HBase jako magazynów danych NoSQL, rozważ model danych klucz/wartość dla Amazon DynamoDB.

Hbase vs Mongodb: która baza danych jest lepsza?
Dzięki HBase łatwo jest przechowywać i wyszukiwać duże ilości danych. Ten oparty na chmurze system jest elastyczny, trwały i ma wiele unikalnych funkcji, które czynią go idealnym wyborem dla wielu różnych firm. MongoDB to doskonała baza danych NoSQL dla aplikacji intensywnie korzystających z pamięci, ale Hadoop zapewnia lepsze zarządzanie przestrzenią.
Hbase kontra Cassandra
Platforma Hbase służy do przechowywania danych w dużych bazach danych, podczas gdy platforma Cassandra może służyć do pozyskiwania i przechowywania dużych ilości danych. W czasie rzeczywistym najlepiej jest używać Cassandry do interaktywnego przetwarzania danych i transakcji.
(Pamięć masowa) Cassandra vs Hbase — jaka jest różnica? Apache Cassandra jest uważana za klasę systemu NoSQL, ponieważ została zaprojektowana do tworzenia najbardziej stabilnych i skalowalnych repozytoriów macierzy danych. Użytkownicy Cassandry mogli wnieść wkład w społeczność, korzystając z jej komponentu open source, co pozwoliło im omówić wszystkie problemy i zapytania. System zarządzania bazą danych Cassandry jest niezwykle wydajny. Twórcy będą mogli skorzystać z możliwości wielordzeniowych maszyn. Kolumna Cassandry zawiera wagę preferencji użytkownika w wierszach. Infrastruktura Hadoop, która obejmuje Zookeeper, Hbase master, węzły danych i węzły nazw, jest używana do uruchamiania Hbase.
Cassandra wykorzystuje specyficzny język zapytań i CQL wzorowany na SQL. Protokół Zookeeper służy do zbierania danych przez inne węzły. Z drugiej strony Cassandra lepiej nadaje się do pozyskiwania i przechowywania danych na dużą skalę niż Hbase, który jest używany do przechowywania małych informacji w dużych bazach danych.
Dlaczego Cassandra jest najlepszym rozwiązaniem Nosql dla Netflix
W świecie Cassandry i HBase są one bardzo różne. Architektura HBase jest przeznaczona wyłącznie do obsługi zarządzania danymi, podczas gdy architektura Cassandry ma wspierać przechowywanie i zarządzanie danymi bez polegania na jakimkolwiek innym systemie.
HBase jest obecnie używany przez wiele organizacji i jest używany wewnętrznie przez wszystkich. Kiedy potrzebujemy sklepu NoSQL, może on rozwiązać szeroki zakres problemów i zapewnić różnorodne unikalne rozwiązania. Rozwiązania pamięci masowej NoSQL firmy HBase są najlepsze na rynku.
Cassandra, oprócz tego, że jest komponentem infrastruktury globalnie dystrybuowanej usługi przesyłania strumieniowego Netflix, jest również dostępna w Amazon Web Services.
Apache Hbase
HBase to open-source, rozproszony, zorientowany na kolumny sklep wzorowany na Bigtable firmy Google. Tak jak Bigtable wykorzystuje rozproszone przechowywanie danych zapewniane przez system plików Google, tak HBase zapewnia możliwości podobne do Bigtable oprócz Hadoop i HDFS. Funkcje HBase obejmują skalowalność liniową i modułową, spójne odczyty i zapisy o małych opóźnieniach oraz automatyczne i konfigurowalne dzielenie tabel na fragmenty.
Hadoop przechowuje i przetwarza ogromne ilości danych przy użyciu rozproszonego systemu plików i MapReduce. HBase, która jest rozproszoną bazą danych zorientowaną na kolumny, jest zbudowana na platformie Hadoop. Projekt jest zarówno open-source, jak i skalowalny w poziomie. Duża tabela Google, która jest podobna do Google, umożliwia swobodny dostęp do danych strukturalnych. Z drugiej strony HBase znajduje się na szczycie systemu plików Hadoop i zapewnia dostęp do odczytu i zapisu do systemu plików. System plików HDFS może być używany do przechowywania danych, bezpośrednio lub przez HBase. HBase, zorientowana na kolumny baza danych, jest zbudowana w taki sposób, że wiersze są sortowane. Tabela może mieć więcej niż jedną rodzinę kolumn, a każda rodzina kolumn może mieć więcej niż jedną kolumnę.
Hadoop vs. Hbase
Duże, rzadkie zestawy danych są obsługiwane przez Hadoop wydajniej. Gdy dane są przetwarzane w czasie rzeczywistym, możliwości obsługi HBase przewyższają możliwości innych platform.
Hbase kontra Hive
Hive i HBase to dwie różne technologie, które działają w Hadoop, Hive to silnik podobny do SQL, który uruchamia zadania MapReduce, a HBase to baza danych kluczy/wartości NoSQL. Hive to solidny aparat zapytań, który umożliwia wysyłanie zapytań w czasie rzeczywistym, podczas gdy HBase to solidny aparat zapytań, który umożliwia wysyłanie zapytań w czasie rzeczywistym.
Apache Hadoop i Apache HBase to dwie odrębne technologie Big Data, które mogą służyć różnym celom, prawie w każdym przypadku. Każda technologia w oczach systemów big data musi być ze sobą połączona. Jakie są różnice między Hive i HBase? Apache Hadoop MapReduce i HBase można połączyć w celu utworzenia bazy danych NoSQL. Jedną z największych luk w HBase jest brak usług, które dopuszczają możliwość swobodnego dostępu. Wiadomo również, że skaluje się poziomo przy użyciu gotowych serwerów regionalnych, jest wysoce dostępny, spójny i tylko na dolnym końcu spektrum opóźnień No SQL. Hadoop jest używany na dwa różne sposoby: Hive i HBase. Hive to silnik podobny do SQL, który uruchamia zadania MapReduce, podczas gdy HBase to baza danych NoSQL z kluczami i wartościami. Zamiast mieć konkurenta, te dwie technologie powinny współpracować.
Hive lub Hbase do Twojego następnego projektu danych?
Hive istnieje już od dłuższego czasu. Korzystanie z HBase ma pewne zalety w porównaniu z innymi hurtowniami danych na rynku, ale wciąż jest w powijakach. Hive jest popularnym wyborem dla wdrożeń hurtowni danych wśród wielu organizacji. To doskonały wybór w sytuacjach, gdy nie potrzebujesz pełnych funkcji bazy danych NoSQL, ale nadal potrzebujesz magazynu NoSQL. Rozwiązania pamięci masowej NoSQL firmy HBase są najlepsze na rynku.
Cassandra Nosql
Cassandra to potężna baza danych NoSQL, która jest idealna dla aplikacji wymagających wysokiej dostępności i skalowalności poziomej. Cassandra jest łatwa w użyciu i zapewnia solidny zestaw funkcji, które czynią ją idealnym wyborem dla szerokiej gamy zastosowań.
Apache Cassandra to szeroko dostępny projekt społeczności Apache, który jest dostępny bezpłatnie. Apache Cassandra umożliwia przechowywanie i zarządzanie szybkimi ustrukturyzowanymi i nieustrukturyzowanymi danymi na wielu serwerach towarowych. Cassandra, która działa w połączeniu z Google Bigtable i Amazon Dynamo, pozwala użytkownikom zarządzać bazami danych z dowolnego miejsca. Oferuje wysoki poziom dostępności i jest pozbawiony większych problemów. Cassandra została wdrożona przez niektóre z największych firm IT. Każdego dnia Instagram przesyła do bazy Cassandra około 80 milionów zdjęć. Składa się z Apache Cassandra i MongoDB. Wielowęzłowy klaster Cassandra to bardzo prosty sposób na łatwe skalowanie Cassandry w celu zaspokojenia nagłego wzrostu popytu.
Czy Cassandra to Nosql?
Baza danych NoSQL, taka jak Cassandra, może być dystrybuowana. Bazy danych NoSQL są lekkie, otwarte, nierelacyjne i sprawiedliwie rozmieszczone w swojej konstrukcji. Wyróżniają się możliwością skalowania w poziomie, a także możliwością elastycznego definiowania schematów.
Mongodb Nosql
Modele dokumentów w MongoDB nie są relacyjne, co czyni je bazą danych. Od tradycyjnych relacyjnych baz danych, takich jak Oracle, MySQL i Microsoft SQL Server, różni się tym, że jest tak zwaną bazą danych NoSQL (NoSQL = Not-only-SQL).
MongoDB jest jedną z najczęściej używanych baz danych NoSQL i może przechowywać dane w formacie JSON. Wydajność, skalowalność i dostępność MongoDB są podobne do innych języków skryptowych/analitycznych baz danych, takich jak SQL, Oracle i Oracle. Celem tego rozdziału jest wyjaśnienie podstawowych pojęć i typów NoSQL.
Jakim rodzajem Nosql jest Mongodb?
Baza danych dokumentów składa się z wielu kluczy połączonych ze sobą złożoną strukturą danych. Dokument może być zagnieżdżony, jak również zawierać różne pary klucz-wartość, pary klucz-tablica i tak dalej. MongoDB jako baza danych dokumentów jest bardzo podobna do Dokumentów Google.
Czy Mongodb jest najlepszym Nosql?
Trzecią najlepszą bazą danych NoSQL jest MongoDB, która ma służyć jako baza danych dokumentów ogólnego przeznaczenia. Ponieważ jest zorientowany na dokumenty, może uporządkować wszystkie informacje w jednym miejscu, ułatwiając dostęp do wszystkich w jednym temacie.
Która baza danych jest dla Ciebie najlepsza?
Ostatecznie nie ma wyraźnego zwycięzcy między dwiema bazami danych, z których każda ma mocne i słabe strony. Baza danych powinna być dostosowana do konkretnych potrzeb i preferencji.
Jak działa Mongodb Nosql?
MongoDB to baza danych NoSQL, która jest dostępna za darmo. Jako nierelacyjna baza danych może obsługiwać dane ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane, a także może obsługiwać dowolny format pliku. Stosowany jest model danych zorientowany na dokumenty i nieustrukturyzowany język zapytań. MongoDB, który jest niezwykle elastyczny, może przechowywać i łączyć wiele typów danych.
Mongodb: podstawowy wybór dla dużych i małych firm
MongoDB to doskonały wybór dla aplikacji o znaczeniu krytycznym, ponieważ można go skalować i ma doskonałą wydajność. W rezultacie Netflix, Uber i Airbnb należą do firm, które od lat wykorzystują go do zasilania swoich najbardziej wymagających i największych aplikacji.
Platforma MongoDB ułatwia korzystanie ze start-upów i małych firm. Ponadto dobrze nadaje się do przechowywania w chmurze, umożliwiając firmom skalowanie w górę lub w dół w razie potrzeby.