
Dlaczego Nosql skaluje się lepiej
Opublikowany: 2022-11-19Bazy danych Nosql są często chwalone za lepszą skalowalność niż ich relacyjne odpowiedniki. Istnieje kilka kluczowych powodów, dla których tak się dzieje. Po pierwsze, bazy danych nosql są generalnie bardziej skalowalne w poziomie. Oznacza to, że można je łatwo skalować, dodając więcej maszyn do systemu, zamiast aktualizować poszczególne maszyny. Po drugie, bazy danych nosql są zaprojektowane do dystrybucji od podstaw. Oznacza to, że są w stanie lepiej wykorzystać wiele maszyn, z których każda może pracować nad inną częścią zestawu danych. Wreszcie bazy danych nosql wykorzystują prostsze struktury danych niż relacyjne bazy danych. Oznacza to, że są one ogólnie bardziej wydajne zarówno pod względem przestrzeni, jak i czasu, co prowadzi do lepszej skalowalności.
Bazy danych z semantyką SQL są skalowalne w pionie, podczas gdy te z semantyką NoSQL są skalowalne w poziomie. Bazy danych SQL przechowują tabele danych, podczas gdy bazy danych NoSQL przechowują dane w dokumentach, wykresach lub szerokich kolumnach. Bazy danych SQL lepiej radzą sobie z transakcjami wielowierszowymi niż bazy danych NoSQL, ale bazy danych NoSQL są również lepsze w obsłudze danych nieustrukturyzowanych, takich jak dokumenty i JSON.
Narzut związany ze spójnością jest zmniejszony dzięki zastosowaniu baz danych NoSQL, które zostały zaprojektowane tak, aby były elastyczne i szybkie, a tym samym miały mniej ograniczeń niż bazy danych SQL. W rezultacie NoSQL może przechowywać dane w różnych formatach, takich jak dokumenty (pary klucz-wartość) lub obiekty (obiekty).
Dlaczego potrzebujemy MongoDB? MongoDB to baza danych NoSQL , która nie ma związku między danymi a pamięcią. Dane są przechowywane w dokumentach podobnych do JSON, do których można łatwo uzyskać dostęp. Ponadto przy użyciu skalowania poziomego dokumenty można łatwo rozmieścić w wielu węzłach.
Baza danych NoSQL jest pod wieloma względami lepsza niż relacyjna baza danych. Ponieważ bazy danych NoSQL mają elastyczne modele danych, skalują się w poziomie, są niezwykle szybkie w działaniu i bardzo proste w tworzeniu, programiści są przyzwyczajeni do pracy z nimi. Bazy danych NoSQL zazwyczaj mają bardzo elastyczne schematy.
Dlaczego bazy danych Nosql tak dobrze się skalują?
Bazy danych Nosql dobrze się skalują, ponieważ są zaprojektowane do dystrybucji od podstaw. Oznacza to, że mogą korzystać z wielu serwerów, które mogą zapewnić większą moc obliczeniową i pamięć masową niż pojedynczy serwer. Ponadto bazy danych nosql są często projektowane z myślą o wysokiej dostępności, co oznacza, że mogą nadal działać, nawet jeśli jeden lub więcej serwerów ulegnie awarii.
Trudno jest rozwiązać problem tak złożonych sprzężeń SQL. Zadanie połączenia dwóch stołów wymaga znacznego wysiłku. Dołączenie może zająć kilka godzin. Jest to problem, ponieważ skalowanie relacyjnej bazy danych jest trudne. Jeśli chcesz rozszerzyć swoją bazę danych, musisz dodać więcej serwerów. Konieczne jest dodanie większej liczby komputerów do bazy danych, aby obsłużyć zwiększoną liczbę użytkowników. Skalowanie w poziomie relacyjnej bazy danych jest trudne. Koncepcja relacyjnej bazy danych polega na tym, że składa się ona wyłącznie z komputerów. Nie da się dodać kolejnego serwera do swojego systemu i oczekiwać, że baza danych będzie działać. Aby móc z niej korzystać, należy dodać nową bazę danych. Dodawanie użytkowników do relacyjnej bazy danych jest wyzwaniem, ponieważ musi to robić z dużym trudem. Nie możesz dodawać nowych komputerów do swojego systemu i oczekiwać, że baza danych będzie działać poprawnie. Nie ma możliwości zmiany serwera. Zapytania SQL o nieograniczonej naturze powodują wiele problemów. Można to zrobić, wpisując zapytanie SQL do komputera. To jest jasne określenie celu. Zapytania SQL mogą zwrócić tylko kilka wierszy tekstu w zapytaniu. Ze względu na trudność w lokalizowaniu informacji w relacyjnej bazie danych jest to problem. Będzie to wymagało przeszukiwania wszystkich danych w bazie danych w celu zlokalizowania potrzebnych informacji. Dostęp do dużych baz danych może być utrudniony, ponieważ zawierają tak dużą ilość informacji.
Jak skalowalna jest baza danych Nosql?
Głównym powodem, dla którego NoSQL i nierelacyjne bazy danych przedkładają dostępność nad spójność, jest to, że cenią sobie możliwość obsługi dużych ilości danych, nawet jeśli liczba węzłów bazy danych maleje. Pozwala to na przechowywanie dużych ilości danych, pozwalając na wsparcie skalowalności.
Dlaczego skalowanie Nosql jest łatwe?
Korzyści z używania bazy danych NoSQL są liczne i zróżnicowane, ale jedną z kluczowych zalet jest to, że bazy danych NoSQL są bardzo łatwe do skalowania. Wynika to z ich bardzo uproszczonej struktury w porównaniu z tradycyjnymi relacyjnymi bazami danych ; Bazy danych NoSQL można skalować w poziomie znacznie łatwiej niż relacyjne bazy danych. Oznacza to, że bazy danych NoSQL mogą obsłużyć znacznie większe obciążenia i efektywniej skalować, aby sprostać potrzebom ich użytkowników.
Jak Nosql skaluje się w poziomie

Z drugiej strony bazy danych NoSQL są skalowalne w poziomie, co oznacza, że gdy ruch wzrasta, mogą po prostu dodać więcej serwerów do swojej bazy danych, aby go obsłużyć. Bazę danych NoSQL można dostosować, aby spełniała wymagania dużego lub stale ewoluującego zbioru danych, dzięki czemu staje się potężniejsza i większa.
Co to jest skalowanie pionowe i poziome w Nosql?
W przypadku skalowania w poziomie można w ten sposób dodać więcej maszyn do puli zasobów, natomiast w przypadku skalowania w pionie można dodać więcej mocy obliczeniowej (CPU, RAM) do istniejących maszyn.
Korzyści z używania Mongodb
Ponadto funkcje replikacji MongoDB umożliwiają dystrybucję danych między wieloma węzłami w przypadku gwałtownego wzrostu zapotrzebowania. Innymi słowy, nawet jeśli Twoje dane są rozproszone w dużej liczbie węzłów, Twoje aplikacje będą nadal działać poprawnie.
Jakie są korzyści z nauki MongoDB?
Oprócz skalowalności MongoDB ma wiele zalet. Przede wszystkim powinien być prosty w nauce i użytkowaniu. Charakteryzuje się również dużą szybkością i wydajnością. Trzecią zaletą programu jest to, że zapewnia wysoki poziom trwałości i spójności danych. Wreszcie, koszt produktu jest niski.
Jak Mongodb może skalować się w poziomie?
Zapewnia wbudowany mechanizm dystrybucji danych na wielu serwerach w celu skalowania w poziomie. Przycisk przełączania na stronie konfiguracji interfejsu użytkownika Atlas może służyć do włączania tego procesu, który jest znany jako sharding. Możesz także osiągnąć zerowy czas przestojów dzięki shardingowi.
Korzyści z bazy danych grafów: Neo4j i Kafka
Jedną z zalet Neo4j jest to, że obsługuje nieograniczoną skalowalność poziomą. Wykorzystując sharding, Neo4j może obsługiwać aplikacje o znaczeniu krytycznym w ciągu kilku minut do milisekund przy znacznie zmniejszonym zużyciu zasobów. Dziennik zatwierdzania Kafki jest dystrybuowany poziomo i umożliwia odporne na błędy, rozproszone operacje. Było tam kilka wymyślnych słów, więc przejrzyjmy je jeden po drugim i zobaczmy, co znaczą. Pierwszą rzeczą, którą należy zrozumieć na temat wykresów, jest to, że nie są one tym samym, co tradycyjne bazy danych. Tabele bazy danych są używane w tradycyjnych bazach danych do przechowywania danych strukturalnych. Z drugiej strony struktura danych używana w bazie danych wykresów jest specjalnie zaprojektowana do przechowywania wykresów. Istnieją dwa rodzaje grafów: węzły i krawędzie. Węzeł reprezentuje element, który jest reprezentowany przez element danych, podczas gdy krawędź reprezentuje połączenie między dwoma węzłami. Innymi słowy, baza danych wykresów nie jest w żaden sposób ograniczona, podobnie jak tradycyjna baza danych. Na przykład tradycyjna baza danych nie pozwala na zawieranie więcej niż jednej tabeli. Grafowe bazy danych przechowują dane w pamięci lub w silniku pamięci masowej. Ponadto bazę danych grafów można skalować w poziomie, co oznacza, że może pomieścić większą liczbę węzłów i krawędzi niż standardowa baza danych. Dane te są również odporne na błędy, co jest kolejną istotną zaletą grafowych baz danych. W rezultacie może poradzić sobie z awarią i nadal działać poprawnie. Na przykład jeden węzeł na grafie nadal może zostać usunięty, jeśli ulegnie awarii, ale reszta bazy danych grafów będzie nadal działać. Z drugiej strony tradycyjne bazy danych nie mogłyby funkcjonować w wyniku awarii jednej z jej tabel. Grafowe bazy danych są potężną strukturą danych ze względu na wszystkie te funkcje, które są przydatne w różnych zastosowaniach. Dzięki przewadze w zakresie wydajności od minut do milionów w porównaniu z innymi bazami danych, jest to baza danych dla aplikacji o znaczeniu krytycznym. Jeśli szukasz bazy danych, która może skalować się w poziomie, ta jest dla Ciebie.

Czy Sql Server może skalować się w poziomie?
Tradycyjna baza danych SQL zazwyczaj nie może być skalowana w poziomie dla operacji zapisu, ponieważ nie możemy dodać więcej serwerów, ale nadal możemy dodawać inne maszyny za pośrednictwem replik tylko do odczytu. Korzystając z dziennika zapisu z wyprzedzeniem, wszystkie operacje zapisu są wykonywane na głównym serwerze i przekazywane do innych maszyn.
Czy skalowanie w poziomie jest tańsze niż skalowanie w pionie?
Istnieją dwa główne powody, dla których skalowanie poziome może być tańsze niż skalowanie pionowe. Pierwszą wadą dodawania nowych serwerów do istniejącego rozwiązania do skalowania pionowego jest to, że może to szybko stać się zbyt kosztowną i czasochłonną inwestycją. W wyniku skalowania poziomego koszty są zazwyczaj niższe, ponieważ dodatkowe węzły można dodawać bez ponoszenia dodatkowych kosztów.
Jednym z powodów niższych kosztów skalowania poziomego jest to, że często jest ono bardziej wydajne. Aby obsłużyć zwiększone obciążenie, dane muszą być przesyłane między serwerami w pionowej farmie serwerów, co skutkuje wolniejszymi czasami odpowiedzi i zwiększonym ruchem. Gdy dane są skalowane w pionie, łatwiej je rozłożyć, co skutkuje wyższą wydajnością.
Przy podejmowaniu decyzji o skalowaniu niezwykle ważne jest uwzględnienie specyficznych potrzeb każdej organizacji, ponieważ zarówno skalowanie pionowe, jak i poziome mają swój własny zestaw zalet i wad. Przy podejmowaniu decyzji bardzo ważne jest staranne rozważenie wszystkich istotnych czynników.
Skalowalność Nosql vs Sql
Główna różnica między Nosql i Sql polega na tym, że Sql jest oparty na modelu relacyjnym, podczas gdy Nosql jest oparty na modelu nierelacyjnym lub rozproszonym. Bazy danych SQL są bardziej skalowalne niż bazy danych Nosql.
Nie zaleca się używania relacyjnych baz danych w każdej aplikacji. Chociaż dobrze nadają się do aplikacji wymagających wysokiego poziomu dostępności, bezpieczeństwa i skali, nie nadają się dobrze do aplikacji, które nie wymagają tych funkcji. Nie należy ich używać w relacyjnych bazach danych, takich jak bazy danych NoSQL. Na przykład MongoDB to baza danych NoSQL, której można używać w aplikacjach o wysokiej wydajności i skalowalności . Są mniej odpowiednie dla aplikacji, które wymagają częstych aktualizacji dostępności i zabezpieczeń.
Potęga baz danych Nosql
Ponadto bazy danych NoSQL są bardziej wydajne, ponieważ są zarówno skalowalne w poziomie, jak i niezawodne w pionie. Bazy danych NoSQL mogą obsłużyć więcej żądań na sekundę niż tradycyjne bazy danych SQL, ponieważ przechowują dane w sposób rozproszony.
Dzielenie Nosql
Jest to typ wzorca używany w erze NoSQL do partycjonowania danych. Wzorce partycjonowania umieszczają poszczególne dyski na potencjalnie oddzielnych serwerach na całym świecie. Skalowanie w poziomie pozwala na wsparcie ludzi na całym świecie w dostępie do różnych części zestawu danych.
Czy możesz podzielić bazę danych Nosql?
Dane można podzielić na fragmenty na różne sposoby. Do przechowywania odłamków można używać baz danych SQL lub NoSQL.
Korzyści z normalizacji danych
Podczas pracy z niestandardowymi danymi może być trudno zapewnić szybkie wykonywanie zapytań oraz łatwe odczytanie i zrozumienie danych. Dostosowując swoje dane, możesz zapewnić, że zachowują się one bardziej przewidywalnie i łatwiej z nimi pracować.
Czy Mongodb używa Shardingu?
Akt dystrybucji danych między wieloma maszynami jest określany jako rozpraszanie. We wdrożeniach MongoDB jest dużo dużych danych i wiele operacji o dużej przepustowości, więc sharding jest świetną opcją. Serwer o pojemności mniejszej niż jeden może stanowić wyzwanie dla dużej bazy danych z dużą ilością danych lub aplikacji o dużej przepustowości.
Zalety wielowęzłowej bazy danych
Takie podejście daje kilka korzyści. Dane są tracone w przypadku awarii węzła. Węzeł może obsłużyć więcej odczytów i zapisów niż tylko jeden węzeł. Podczas dodawania lub usuwania węzłów należy najpierw ponownie przydzielić dane.
Która baza danych jest najlepsza do dzielenia?
Putty, znany również jako partycjonowanie poziome, jest dobrze znanym podejściem skalowania w poziomie do operacji na bazie danych. Amazon RDS (Amazon Relational Database Service) to zarządzana w chmurze usługa relacyjnej bazy danych, która zapewnia wiele funkcji ułatwiających sharding.
Indeksowanie vs. Sharding: jaka jest różnica?
Termin „sharding” odnosi się do procesu dzielenia tabeli na wiele części, tak aby mogła być obsługiwana przez wiele maszyn. Kiedy dane są dystrybuowane między maszynami jako część fragmentu, zarządzanie nimi jest łatwiejsze. Dane są przetwarzane w ten sposób, aby były łatwo dostępne dla różnych części systemu.
Indeksowanie to technika przechowywania kolumn w strukturze danych, takiej jak B-Tree lub Hashing. Im szybciej możesz wyszukiwać lub dołączać do zapytania za pomocą indeksu, tym mniej czasu będziesz musiał poświęcić na szukanie poprawnych wartości. Oprócz indeksów są one wymagane do innych celów, takich jak przyspieszenie pobierania danych z baz danych. Z drugiej strony podstawową funkcją shardingu jest przechowywanie danych.
W podobny sposób indeksowanie i sundowning mogą być wykorzystywane do zarządzania danymi. Z drugiej strony indeksowanie bazy danych przechowuje dane w bazie danych, podczas gdy sharding zarządza danymi na maszynach. Ogólnie rzecz biorąc, oba różnią się tym, że indeksy są wymagane do operacji dzielenia na fragmenty, ale pobieranie danych nie.
Co to jest dzielenie i replikacja w Nosql?
Jaka jest różnica między dzieleniem na fragmenty a replikacją? Replikacja danych to czynność przesyłania danych z jednego głównego węzła serwera do drugiego. Jako kopia zapasowa może to poprawić dostępność danych, a także pomóc w odzyskaniu serwera podstawowego w przypadku jego awarii. Można go używać do skalowania na wielu serwerach w oparciu o klucz fragmentu.
Ważenie zalet i wad replikacji i dzielenia na fragmenty
Zarówno replikacja, jak i sharding to dobre opcje zarządzania danymi. Replikacja może pomóc w skalowaniu odczytów w poziomie, ale fragment może pomóc w skalowaniu w poziomie zapisów danych przez partycjonowanie danych na wielu serwerach przy użyciu klucza fragmentu. Aby uzyskać dostęp do odłamka, musisz najpierw wybrać dobry klucz.
Ponadto przechowywanie danych w odłamku może poprawić dostępność danych, umożliwiając wielu serwerom dostęp do tych samych danych w przypadku awarii jednego z nich. Jednak wyszukiwanie danych rozproszonych na wielu serwerach może być trudniejsze.
Przed podjęciem decyzji bardzo ważne jest rozważenie zalet i wad każdej opcji.
Ruch Nosql
Niedawno w społeczności programistów nastąpił ruch w kierunku tak zwanych baz danych „NoSQL”. Są to bazy danych, które nie używają tradycyjnego modelu relacyjnego, a zamiast tego używają bardziej elastycznego modelu danych bez schematu. Dzięki temu są bardziej odpowiednie dla nowoczesnych aplikacji internetowych, w których model danych jest często bardziej płynny i częściej się zmienia.
Bazy danych Nosql zyskują na popularności: dlaczego zyskują popularność
Wzrost popularności baz NoSQL w ostatnich latach można przypisać różnym czynnikom. Pierwszym problemem związanym z relacyjnymi bazami danych było to, że nie nadążały za popytem w okresie największej popularności Internetu w latach 90. W wyniku tego rozwoju nierelacyjne bazy danych stały się bardziej wrażliwe na napływ danych.
Innym powodem popularności baz danych NoSQL jest to, że zapewniają większą elastyczność w sposobie obsługi danych. Bazy danych MongoDB mogą osiągnąć większą wyrazistość, wykorzystując dowolny model danych, który jest wystarczająco wyrazisty, zamiast tradycyjnego modelu opartego na tabelach. W rezultacie programiści mają większą swobodę przechowywania danych w najbardziej efektywny sposób.
Bazy danych NoSQL napotykają pewne wyzwania, ale zapewniają znaczną przewagę nad tradycyjnymi relacyjnymi bazami danych pod względem elastyczności i wydajności.
Bazy danych Nosql
Baza danych Nosql to baza danych, która nie używa tradycyjnego języka SQL jako języka zapytań. Bazy danych Nosql są często używane w aplikacjach big data, w których skala danych sprawia, że użycie SQL jest niepraktyczne.
Czym są bazy danych Nosql?
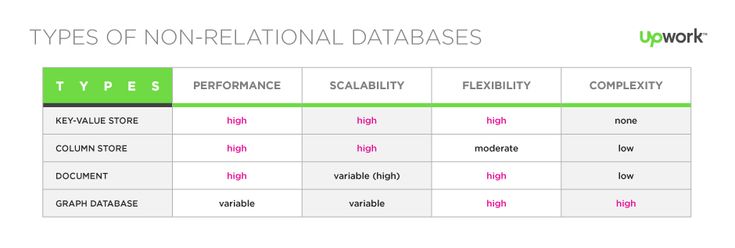
Dane są przechowywane inaczej w bazach danych NoSQL (znanych również jako SQL) niż w relacyjnych bazach danych. Na podstawie ich modelu danych bazy danych NoSQL można podzielić na różne typy. Najpopularniejsze są typy dokumentów, typy klucz-wartość, typy szerokich kolumn i typy wykresów.
Jaki jest przykład Nosql?
Na rynku można znaleźć oparte na tabelach bazy danych NoSQL, takie jak Cassandra, HBase i Hypertable.