
5 maneiras de otimizar seu banco de dados NoSQL
Publicados: 2023-01-12Os bancos de dados NoSQL estão se tornando cada vez mais populares, pois são vistos como mais escaláveis e flexíveis do que os bancos de dados relacionais tradicionais . Há várias maneiras de otimizar um banco de dados NoSQL, que incluem: 1. Projetar o esquema com cuidado: isso é importante, pois um esquema bem projetado pode ajudar a melhorar o desempenho e tornar os dados mais gerenciáveis. 2. Dados de indexação: isso pode ajudar a melhorar o desempenho da consulta. 3. Usando cache: O cache pode ajudar a melhorar o desempenho armazenando dados acessados com frequência na memória. 4. Dados de particionamento: isso pode ajudar a melhorar o desempenho e a escalabilidade, distribuindo os dados por vários servidores. 5. Monitorar o desempenho: Isso é importante para identificar eventuais gargalos e tomar ações corretivas.
Jay Patel, arquiteto do eBay, publicou recentemente um artigo sobre modelagem de dados usando o armazenamento de dados Cassandra. Ele explica como eles projetaram seu modelo de dados usando Cassandra, como usaram colunas e famílias de colunas e como otimizaram os resultados da consulta usando a otimização de consulta. Uma das minhas percepções favoritas de sua abordagem é que ela pode ser aplicada a qualquer banco de dados NoSQL. Antes de otimizar seu modelo de dados, você deve primeiro compreender como ele será acessado. Quando você começa a perceber que suas consultas estão demorando mais, percebe que seu banco de dados relacional está com problemas de desempenho. Quando os dados são normalizados, é menos provável que resulte em junções desnecessárias ou n+1 consultas. Mesmo que a desnormalização seja possível com armazenamentos de dados NoSQL, há custos associados a ela.
O que é otimização de consulta em Nosql?
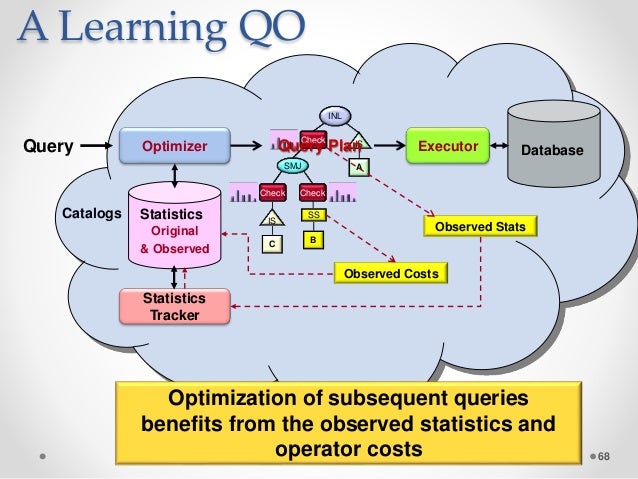
O objetivo da otimização da consulta é encontrar o plano mais eficiente. Ao medir a eficiência, a latência e a taxa de transferência são usadas. Uma otimização baseada em custo custa o mesmo que o custo de memória, CPU e espaço em disco. No mundo NoSQL, a maioria dos bancos de dados agora oferece suporte à linguagem de consulta semelhante a SQL.
Um banco de dados MongoDB é um banco de dados NoSQL, também conhecido como banco de dados de documentos. Este banco de dados foi projetado de forma que seja mais fácil de desenvolver do que outros bancos de dados relacionais. Usando o comando Explain() podemos ver como nossa consulta está funcionando. Você pode usar o Explique para criar um documento que inclua planos de consulta, estágios de consulta e muito mais. Como resultado deste artigo, podemos entender como o índice pode alterar as etapas de digitalização de uma coleção específica. O objetivo deste artigo é examinar os fundamentos da otimização. Os detalhes detalhados da otimização do estágio de agregação serão abordados em artigos subsequentes. Os negros se destacam nos campos da tecnologia. Esta coleção de recursos destaca algumas das coisas que devemos saber.
O que torna o Nosql rápido?
Os bancos de dados Nosql são projetados para serem rápidos e escaláveis. Eles usam uma variedade de técnicas para conseguir isso, como dimensionamento horizontal, sharding e desnormalização.
A grande maioria dos sistemas noSQL são simplesmente chaves persistentes ou armazenamentos de valores (como o Projeto Voldemort). Se suas consultas forem do tipo que exigem que você procure um determinado valor de chave, um sistema que pode fazer isso tão rapidamente quanto um RDBMS deveria. Bancos de dados de documentos (como o CouchDB) também são sistemas nosql populares. A desnormalização é muito usada nesses bancos de dados para estruturar a estrutura de dados. Na verdade, acredito que o desempenho de um aplicativo pode ser medido pelo número de peças necessárias para atender a um único requisito. Quando o NoSQL é usado, o desempenho de um banco de dados NoSQL como o djondb pode ser dez vezes mais rápido se você precisar apenas de uma inserção simples. O desenvolvedor poderá trabalhar com mais eficiência porque o NoSQL permite que ele consuma menos dados.
O principal objetivo dos BANCOS DE DADOS NoSQL (sem limites) é manter um alto nível de escalabilidade. Você deve considerar quais tipos de consultas está executando, quais colunas você usa na tabela e qual implementação de seu servidor está usando. Se você criar mais nós 1000000 rpm estável 2 ms e usar menos código, obterá um nó mais rápido com uma taxa e desempenho estáveis mais altos.
O que torna o Nosql mais rápido que o SQL?
Este método envolve a coleta, consolidação e divisão de várias entidades de dados. Como resultado, um banco de dados NoSQL executa operações de leitura e gravação mais rapidamente do que um banco de dados SQL.
Por que os bancos de dados Nosql estão assumindo o controle
Além de uma variedade de fatores, os bancos de dados NoSQL estão se tornando mais populares. Eles são simples de usar, capazes de lidar com grandes quantidades de dados e podem ser personalizados para atender aos requisitos específicos de sua aplicação. Eles têm muitas vantagens além de serem flexíveis e personalizáveis, o que é impossível encontrar em outros tipos de banco de dados.
Ajuste de Desempenho Nosql

O ajuste de desempenho do Nosql tem tudo a ver com garantir que seu banco de dados nosql esteja sendo executado da maneira mais eficiente possível. Existem algumas áreas-chave nas quais focar ao ajustar seu banco de dados nosql: 1. Certifique-se de que seu banco de dados esteja indexado corretamente. 2. Certifique-se de que suas consultas sejam otimizadas. 3. Certifique-se de que seus dados estejam devidamente normalizados. 4. Certifique-se de que seu banco de dados esteja configurado corretamente. Ao focar nessas áreas-chave, você pode garantir que seu banco de dados nosql esteja executando com desempenho máximo.
Quando o Mango está em alta carga, o script MangoNoSql executa gravações em segundo plano. O recurso Batch Write Behind permite que você escreva nos bastidores. Cada tarefa será executada em paralelo com as outras, colocando em foco os valores de pontos de um pool. Se você notou algum evento de perda de dados NoSQL em seu sistema, é uma boa ideia alterar suas configurações de desempenho. Quando você pressiona o botão Fazer backup agora, uma fila de trabalhos será criada para fazer backup do sistema agora. Todos os valores de ponto que estão prontos para serem gravados em uma lista de memória como parte dos módulos NoSQL são armazenados em mango. Depois disso, ele seleciona até 'Batch write-behind inserts per task' na lista e inicia um thread para inserir as inserções.
Os prós e contras do Nosql
Ao desenvolver bancos de dados NoSQL, é fundamental mantê-los flexíveis e rápidos. Tem menos sobrecarga porque tem menos restrições do que o SQL. O armazenamento Shallow NoSQL é flexível, permitindo que seja distribuído em uma variedade de objetos (documentos ou pares chave-valor). Um banco de dados NoSQL é amplamente considerado como tendo um baixo nível de dificuldade em termos de desenvolvimento, funcionalidade e desempenho. É simples de aprender e é usado por pessoas que preferem armazenar dados que não obedecem aos modelos tradicionais de banco de dados.
Otimização de desempenho do Mongodb
O MongoDB é um poderoso sistema de banco de dados orientado a documentos de código aberto. Possui um recurso de pesquisa baseado em índice que torna a recuperação de dados rápida e fácil. No entanto, como qualquer outro sistema de banco de dados, o desempenho do MongoDB pode ser otimizado para garantir uma execução suave e eficiente. Existem algumas coisas básicas que podem ser feitas para otimizar o desempenho do MongoDB. Primeiro, é importante certificar-se de que os índices corretos estejam no lugar. Isso garantirá que os dados possam ser recuperados de forma rápida e fácil. Em segundo lugar, é importante manter o banco de dados bem organizado. Isso ajudará a manter o tamanho dos dados baixo e facilitará a consulta. Por fim, é importante monitorar o banco de dados regularmente para garantir que ele esteja funcionando sem problemas. Seguindo essas dicas simples, é possível manter o MongoDB funcionando sem problemas e com eficiência.

Guy Harrison explica como usar a nova agregação de janelas e o pipeline de agregação no MongoDB 5.0 nesta postagem do blog. Data Lake foi criado como resultado da explosão de interesse em Big Data e Hadoop. Foi desenvolvido o Data Lake, uma alternativa moderna e mais eficiente ao Enterprise Data Warehouse (EDW). O blog desta semana se concentra nos índices de árvore B do MongoDB e em como criar índices concatenados para otimizar pesquisas de várias chaves. Além disso, ao considerar – ou usar – índices, consideramos algumas compensações.
Qual é a melhoria no desempenho no Mongodb?
Se você conhece os padrões de consulta do MongoDB, pode melhorar o desempenho do MongoDB: armazenando os resultados de subconsultas frequentes para reduzir a carga de leitura; e detectando seus padrões de consulta do MongoDB. Certifique-se de ter índices em todos os campos que você consulta regularmente. Se você observar consultas lentas, poderá usar seus logs para identificá-las.
O Mongodb precisa de muito RAM?
O MongoDB requer 1 GB de RAM para ser executado em um único ativo. Se o sistema tiver que começar a trocar memória para disco, isso terá um impacto severo no desempenho e deve ser evitado.
O Mongodb possui otimizador de consultas?
Quando um índice está disponível no MongoDB, o otimizador de consulta determina qual plano de consulta é o mais eficiente e o armazena em cache. O número de “unidades de trabalho” (trabalhos) executadas pelo plano de execução da consulta é usado para determinar o plano de consulta mais eficiente quando o planejador de consulta examina os planos candidatos.
Ferramenta de Otimização de Consulta Mongodb
O Mongodb fornece uma ferramenta de otimização de consulta que permite aos usuários melhorar o desempenho de suas consultas. Essa ferramenta fornece uma maneira de visualizar o plano de execução da consulta e otimizar a consulta com base nos resultados. A ferramenta também permite que os usuários visualizem o plano de execução da consulta em vários formatos, incluindo JSON, BSON e CSV.
O MongoDB fornece estatísticas de execução de consultas como parte de um sistema de inspeção. Essas informações podem ser usadas por um desenvolvedor para otimizar uma consulta. A guia Explicar Plano, por exemplo, permite que os usuários ilustrem graficamente as estatísticas do plano. Além de queryPlanner, operationStats e allExecutionPlans, os modos de detalhamento podem ser usados para explicar. Único, parcial, esparso (não indexe documentos sem o campo de índice), oculto (não veja os resultados do planejador de consulta) e índices multichave são todos suportados pelo MongoDB. Em vez de usar chaves de prefixos de índice ou ordens de classificação variadas, um índice composto é usado para índices. O MongoDB otimiza o desempenho da consulta usando dois índices ou prefixos separados ao conectar dois índices ou seus prefixos.
O pipeline do Mongod contém um estágio que corresponde a um campo que não está indexado. É uma solução simples reescrever o estágio correspondente para usar um campo já existente e indexado. O otimizador procura unidades de trabalho que devem ser executadas ao executar cada plano candidato. Ao executar aplicativos de leitura intensa, o tamanho dos conjuntos de réplicas deve ser aumentado e a fragmentação executada. O estado e a duração da replicação devem ser monitorados. Verdadeiro: atualize todos os documentos correspondentes da forma mais eficiente possível ao usar multi. Examine as métricas de bloqueio em uma ordem específica.
Um longo tempo de bloqueio pode indicar que a estrutura da consulta ou a arquitetura do sistema não está funcionando corretamente. O processamento em lote melhora a eficiência dos recursos. Os eventos no Kafka, por exemplo, podem ser consumidos em lotes em vez de em blocos. É impossível indexar uma consulta em uma coleção fragmentada se o índice não contiver a chave da coleção. Usando $planCacheStats, você pode entender melhor as informações do cache no estágio de agregação. Isso também significa que o cache do plano terá apenas um limite de tamanho de 0,5 GB, que é o mesmo limite de tamanho da versão anterior.
Armazenamentos de dados Nosql
Em vez de armazenar dados em tabelas, os bancos de dados NoSQL armazenam dados em documentos. Como resultado, nós os rotulamos como “não apenas SQL”, e eles podem ser classificados como modelos de dados flexíveis usando uma variedade de métodos diferentes. Os bancos de dados NoSQL são divididos em quatro tipos: bancos de dados de documentos puros, armazenamentos de valores-chave, bancos de dados de colunas largas e bancos de dados de gráficos.
O armazenamento de dados Redis é um armazenamento de pares chave-valor na memória de software livre desenvolvido pela IBM. Ele pode ser usado para armazenar dados de sessão para acesso mais rápido, além de cache, enfileiramento e enfileiramento, e é mais barato que os bancos de dados tradicionais . Um banco de dados NoSQL é freqüentemente usado como um acréscimo em vez de uma substituição para um banco de dados relacional. Um tipo de persistência subjacente tem um conjunto de características diferente daquele armazenado em um banco de dados relacional. O PyMongo, que é construído usando o código Python, permite que você interaja com uma ou mais instâncias do MongoDB usando uma interface comum. O Python ORM construído em torno do PyMongoEngine foi projetado especificamente para o MongoDB. O objetivo do Graph Databases é fornecer uma visão abrangente dos armazenamentos de dados NoSQL e compará-los com outros tipos de armazenamentos de dados. A seguir está uma breve descrição do NoSQL e seus usos, bem como uma descrição do Teorema de Consistência, Disponibilidade e Tolerância à Partição (CAP). os dados da sessão podem ser armazenados na memória mais rapidamente do que em um banco de dados tradicional com armazenamento persistente.
Os bancos de dados NoSQL se beneficiam das seguintes características: escala fácil, alta disponibilidade e baixa latência de acesso aos dados. Os aplicativos de banco de dados são projetados para processar mais tipos de dados do que os bancos de dados tradicionais. Ele simplifica o armazenamento de dados com um modelo simplificado, permitindo um processamento mais rápido e eficiente. Além disso, eles são apropriados para análise de dados em larga escala. Os bancos de dados NoSQL têm várias vantagens sobre os bancos de dados convencionais . As vantagens de tê-los são que eles podem escalar, fornecer altos níveis de disponibilidade e fornecer baixos níveis de latência para acesso aos dados.
Por que os bancos de dados Nosql estão assumindo o controle
Existem inúmeras vantagens em usar bancos de dados NoSQL em relação aos bancos de dados relacionais tradicionais, e eles estão se tornando cada vez mais populares. O design do ObjectStore, que permite o uso mais eficiente de técnicas de programação orientada a objetos, é uma das principais razões para isso. Os bancos de dados NoSQL, além de sua escalabilidade, também oferecem várias outras vantagens. Os dados podem ser manipulados com facilidade porque são grandes e podem ser manipulados em um curto período de tempo. Para qualquer empresa que procura um banco de dados de documentos confiável e escalável , o MongoDB é uma excelente escolha. Além disso, é de uso gratuito e é uma escolha popular para empresas de todos os tamanhos.
Índice de texto do Mongodb
Os índices de texto do MongoDB oferecem suporte ao processamento de texto específico do idioma, incluindo tokenização, lematização e stopwords específicos do idioma. Eles podem ser usados com qualquer campo que contenha texto baseado em idioma.
Criar índices de texto no MongoDB é tão simples quanto usar o método createIndex(). A principal função de um índice de texto é identificar qualquer elemento em uma string ou array de elementos em um texto. Os índices compostos contêm chaves de índice ascendentes e descendentes, além da chave de índice de texto. Nesse caso, vamos pesquisar na coleção de postagens dos alunos criando um índice de texto no campo do título. O MongoDB soma os resultados de cada campo de índice no documento multiplicando seu peso pelo número total de correspondências. O peso padrão de um campo de índice é um, portanto, você pode alterá-lo usando o método createIndex(). Você pode criar vários índices de texto usando o especificador curinga ($**).