
Bigtable do Google: o armazenamento de dados orientado a colunas mais usado
Publicados: 2022-12-19Bigtable é um armazenamento de dados orientado a colunas criado pelo Google. Ele é projetado para lidar com grandes quantidades de dados com um alto grau de flexibilidade. O Bigtable é usado pelo Google há mais de uma década e é a base para muitos de seus serviços, incluindo Gmail, Google Maps e YouTube. Embora o Bigtable não seja o primeiro armazenamento de dados orientado a colunas, certamente é o mais amplamente usado e conhecido.
Neste artigo, examinaremos o modelo de armazenamento NoSQL tridimensional desenvolvido pela Bigtable. Para verificar se está estruturado corretamente, primeiro veremos como ele é implementado em termos teóricos e, em seguida, usaremos o cliente Node.js para fazê-lo. O modelo de armazenamento no Bigtable difere da maneira como você pode encontrá-lo em um banco de dados semelhante. Múltiplas células em uma combinação de linha/coluna podem ser ordenadas por um timestamp por célula. Em vez de salvar as células em uma ordem arbitrária, cada célula tem o valor e um carimbo de data/hora para garantir que as células sejam salvas em uma ordem ordenada. Para este exemplo, usaremos Node.js e JavaScript simples para criar o Google Cloud Bigtable. Neste artigo, veremos como criar uma nova instância do Bigtable usando o código.
Começamos criando um ambiente limpo, lendo e escrevendo nele e depois destruindo-o. Ao executar o código usando o cliente Node.js Bigtable, o cliente Node.js Bigtable pode causar um erro Permission Denied e gerar um link para ativar a Cloud Bigtable Admin API. Você também deve estabelecer uma conta de serviço separada em seu projeto GCP para lidar com a função de Administrador do Bigtable. Para criar uma tabela Bigtable, devemos primeiro construir uma instância do banco de dados e um cluster de tabelas. Basta definir um ID de tabela e um grupo de colunas no cliente Node.js para fazer isso e pronto. Linhas simples podem ser criadas usando o Bigtable em um banco de dados. A única maneira de consultar dados é usar a chave de linha para consultar uma linha específica ou um grupo de linhas.
Embora os tempos de ingestão não tenham relação com a ordem em que as versões são armazenadas, eles afetam a forma como são armazenadas. Não é necessário fornecer a chave de linha inteira; simplesmente um prefixo é suficiente. Quando você precisa consultar várias linhas do Bigtable, sempre aconselho o uso de streaming. Ao usar streaming, o Bigtable não precisa armazenar dados em buffer no servidor antes de enviar linhas, resultando em um desempenho mais rápido. Os filtros podem ser usados para limitar as versões de células, retornando apenas aquelas colunas com nomes de família específicos ou colunas com critérios de qualificação específicos. Isso é especialmente útil se você tiver muitas versões para manter, mas apenas a mais recente é necessária para fins específicos. Os filtros são usados principalmente para reduzir a quantidade de dados que são consultados e enviados para melhorar o desempenho da consulta.
Em outras palavras, o Cloud Bigtable é um banco de dados NoSQL projetado para cargas de trabalho analíticas e operacionais. Esse sistema de banco de dados é um híbrido de plataforma cruzada que usa Hadoop em vez de HBase, que emprega um banco de dados colunar. Um cloud bigtable pode ser usado para alimentar aplicativos com alto rendimento e escalabilidade, com capacidade inferior a 10 MB.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable e Microsoft Azure CosmosDB são exemplos de armazenamentos de colunas largas.
As tabelas não são iguais aos bancos de dados relacionais em termos de armazenamento de chave/valor. As transações só podem ser realizadas uma vez e as junções não são suportadas.
O Google Bigtable é um banco de dados Nosql?
O Google Bigtable é um banco de dados NoSQL projetado para armazenar e gerenciar grandes quantidades de dados. Bigtable é um banco de dados orientado a colunas, o que significa que os dados são organizados em colunas em vez de linhas. Isso o torna adequado para armazenar dados que mudam constantemente, como logs da web ou dados de mídia social. O Bigtable também é altamente escalável, o que significa que pode lidar facilmente com grandes quantidades de dados.
Esse banco de dados NoSQL pode armazenar uma ampla variedade de tipos de dados e é extremamente estável. Ele também lida com fragmentação e replicação, garantindo que o banco de dados esteja altamente disponível e confiável. Muitos aplicativos do Google o utilizam, incluindo Google Analytics, indexação da Web, MapReduce e Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code Hosting e Google For aplicativos que exigem um banco de dados capaz de lidar com um grande número de itens de dados, o Datastore é uma ótima escolha.
Em que ordem os dados são armazenados no Bigtable?
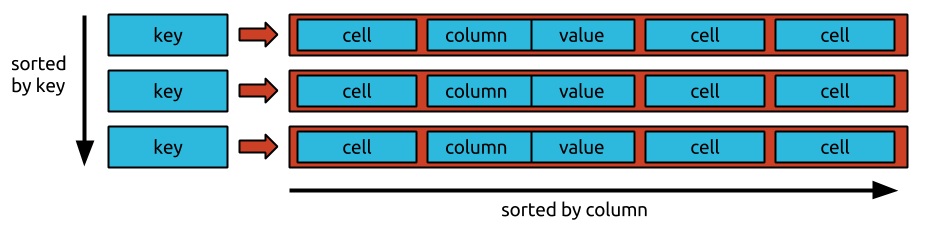
Não há uma ordem específica na qual os dados são armazenados no bigtable. Os dados são armazenados em ordem aleatória, o que dificulta o acesso a dados específicos.
Bigtable do Google: não apenas para armazenar dados
Os dados não podem ser colocados em nenhuma ordem específica dentro do igtable. Como o Bigtable é um banco de dados orientado a linha, todos os dados em uma linha são organizados em colunas, seguidas por uma coluna. Como os dados são armazenados em ordem cronológica inversa, é simples e rápido solicitar o valor mais recente, mas é difícil e demorado solicitar o mais antigo.
Seus dados são mantidos no Colossus, o sistema de arquivos interno de longa duração do Google, que está alojado nos centros de dados do Google, como resultado do uso do Colossus pela Bigtable. O uso do Bigtable é gratuito e você não precisa usar um cluster HDFS ou qualquer outro sistema de arquivos.
Uma consulta a uma fonte de dados externa pode ser executada sem criar uma tabela permanente com o comando combine: Um arquivo de definição de tabela com uma consulta. Há uma definição de esquema embutido, bem como uma consulta. Um arquivo de definição de esquema JSON com uma consulta.
Bigtable x armazenamento de dados
Existem algumas diferenças importantes entre o Bigtable e o Datastore. Primeiro, o Bigtable é um armazenamento de dados orientado a colunas, enquanto o Datastore é orientado a linhas. Isso significa que no Bigtable os dados são organizados em colunas, enquanto no Datastore são organizados em linhas. Em segundo lugar, o Bigtable não tem um conceito de transações, enquanto o Datastore tem. Isso significa que no Bigtable você não pode reverter as alterações para um estado anterior, enquanto no Datastore você pode. Por fim, o Bigtable foi projetado para alta taxa de transferência e baixa latência, enquanto o Datastore foi projetado para alta disponibilidade e escalabilidade.
Qual armazenamento de dados em nuvem pode ser usado para criar bancos de dados em nuvem do Google? Como o Bigtable oferece suporte a grandes cargas de trabalho com cargas de trabalho de back-end complexas, ele é destinado a organizações e empresas maiores. Em contraste com o SQL, que usa uma linguagem de consulta mais restritiva GQL, os armazenamentos de dados executam transações ACID em subconjuntos de dados conhecidos como grupos de entidades (embora a linguagem de consulta GQL seja muito mais aberta). O Google Cloud Datastore e o Google Cloud Bigtable são dois serviços distintos que possuem vários recursos distintos. Além disso, as informações na imagem abaixo podem ajudá-lo a selecionar o provedor de serviços apropriado para você. As respostas acima, bem como o que é discutido no livro Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals, servirão como meu guia para este artigo.
Qual é a diferença entre Bigtable e armazenamento de dados?
Qual é a diferença entre armazenamento de dados e banco de dados? O bigtable e o armazenamento de dados são projetados para processamento e análise de dados de alto volume, respectivamente, enquanto o armazenamento de dados é projetado para dados transacionais de alto valor. O Datastore também é conhecido como banco de dados NoSQL por não aderir ao padrão SQL tradicional, permitindo reter os dados de forma mais flexível e escalável. Que tipo de armazenamento de dados é o Google Bigtable? O modelo de armazenamento Bigtable armazena dados em tabelas altamente escaláveis que são classificadas por mapas de chave e valor. Uma tabela é composta de linhas, cada uma descrevendo uma única entidade, e colunas, cada uma com seu próprio valor. O armazenamento de dados está obsoleto? Como a Cloud Datastore API v1beta3 foi lançada, ela não está mais disponível. No entanto, o produto Cloud Datastore é totalmente funcional e compatível.
banco de dados Bigtable
Um Bigtable é um sistema de armazenamento distribuído para gerenciar dados estruturados projetados para escalar para um tamanho muito grande: petabytes de dados em milhares de servidores de commodities. O Bigtable é um banco de dados orientado a colunas, o que significa que os dados são armazenados por coluna e não por linha.
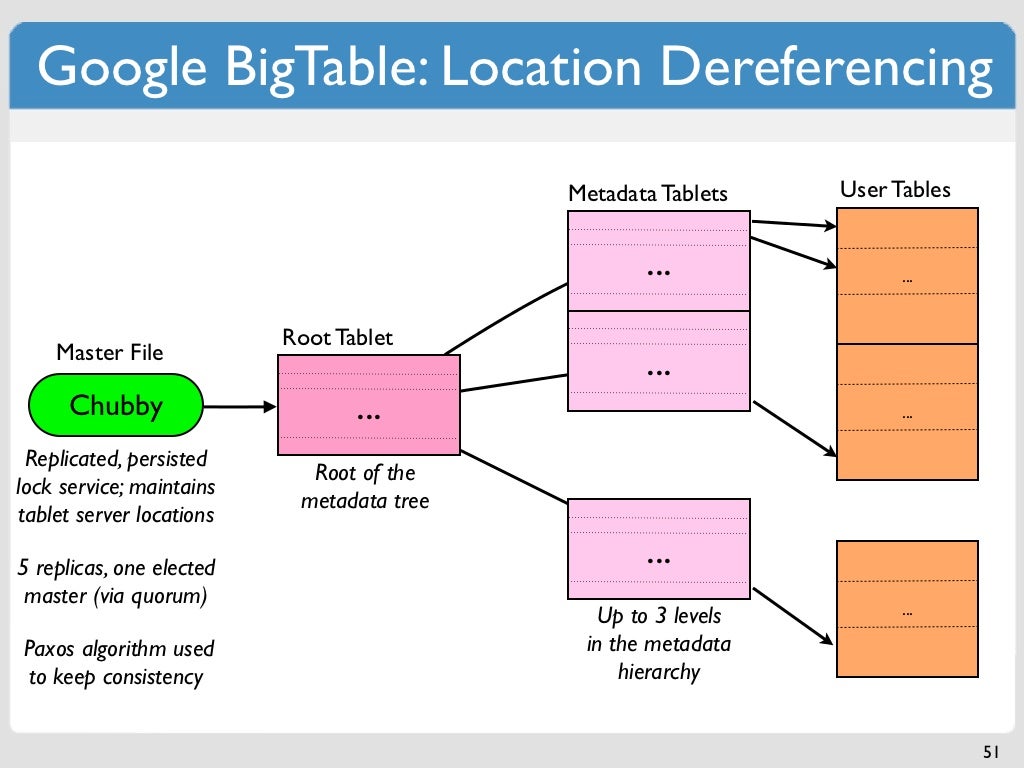
A tabela é uma estrutura esparsa e densamente preenchida com linhas e colunas que podem atingir bilhões de linhas. Uma bigtable é uma excelente escolha para armazenar grandes quantidades de dados com baixa latência. Por oferecer suporte a alta taxa de transferência de leitura e gravação em baixa latência, é uma fonte de dados adequada para operações MapReduce. Ao usar uma tabela Bigtable, ela é particionada em blocos de linhas contíguas conhecidas como tablets para facilitar as consultas. Em um sistema de arquivos chamado Colossus, que o Google usa, os tablets são armazenados no formato SSTable. Um nó Bigtable é um subconjunto de cada tablet, que faz parte da instância Bigtable. Adicionar nós a um cluster pode aumentar o número de solicitações simultâneas que ele pode manipular.

Uma linha contém um conjunto de entradas de chave ou valor, que são uma combinação da família de colunas, timestamp da coluna e chave. O Bigtable trata todos os dados da mesma maneira: como strings de bytes brutos. Como o Bigtable armazena mutações sequenciais e as compacta regularmente, o número de mutações que podem ser armazenadas em um determinado momento exige mais espaço de armazenamento. O Bigtable comprime seus dados usando um algoritmo sofisticado que é automatizado. Como as deleções são, na verdade, novos tipos de mutações, elas requerem mais espaço de armazenamento a curto prazo. Os métodos de armazenamento proprietários do Google permitem que ele alcance a durabilidade dos dados que excede a obtida pela replicação de três vias HDFS padrão. Além de gerenciar o acesso às tabelas do Bigtable, você pode gerenciar o acesso a outros serviços do Google Cloud atribuindo funções aos usuários na seção Gerenciamento de identidade e acesso (IAM) do seu projeto do Google Cloud. De acordo com a política de criptografia padrão do Google Cloud, todos os dados na nuvem são criptografados em repouso usando os mesmos sistemas de gerenciamento de chaves reforçados que usamos para nossos dados criptografados. Usando um backup, você pode salvar uma cópia do esquema e dos dados de uma tabela e restaurar essa cópia dos dados em uma nova tabela no futuro.
Bigtable x Cassandra
Cassandra e Bigtable usam métodos diferentes para determinar qual nó de processamento deve executar operações de leitura e gravação. No Cassandra, a chave de partição é chamada de chave, enquanto no Bigtable, a chave de linha é chamada de chave. A política de balanceamento de carga para Cassandra deve ser revisada pelo cliente como parte do processo.
Um banco de dados distribuído é aquele que é compartilhado por várias pessoas. Esta empresa incorpora armazenamentos de valor-chave multidimensionais em seu sistema, permitindo processar dezenas de milhares de consultas por segundo (QPS). O objetivo deste documento é comparar e contrastar os dois sistemas de banco de dados. Os principais recursos do Bigtable incluem: Um documento do Sistema de armazenamento distribuído para dados estruturados foi criado. Se o Bigtable determinar que o reequilíbrio de intervalo é necessário para um conjunto de dados, é simples para um nó de processamento alterar os intervalos de dados porque a camada de armazenamento é separada da camada de processamento. O Bigtable também pode ser usado para oferecer suporte à replicação assíncrona em clusters distribuídos geograficamente de até quatro clusters em topologias. A tolerância a falhas do Cassandra está ligada ao seu nível de consistência ajustável.
Ao configurar uma estratégia de topologia de replicação de dados, você pode definir a replicação geográfica. Em geral, uma configuração de QUORUM (ou LOCAL_QUORUM em alguns centros de dados) é usada. Para ser considerado bem-sucedido, a configuração do nível de consistência de uma operação deve ser atendida com uma maioria de nós de réplica respondendo ao nó coordenador. Usando configurações de data center e rack, as réplicas do Cassandra são capazes de suportar mais estresse quando comparadas às réplicas tradicionais. Ao realizar operações de leitura e gravação, a topologia determina quais nós são necessários para garantir a consistência. Uma instância do Bigtable pode conter um único cluster ou um grupo de até quatro réplicas grandes. Bigtable e Cassandra são armazenamentos de dados NoSQL que são armazenamentos de colunas largas.
A chave de linha do Bigtable é usada para classificar os dados globais em uma tabela por ordem. Os nós do Bigtable equilibram automaticamente a responsabilidade nodal para intervalos de chaves, também conhecidos como tablets, como parte do recurso de nós do Bigtable. O serviço Bigtable de um cliente não impõe os tipos de dados de coluna que ele envia. No Bigtable, cada coluna em uma tabela recebe um nome de família. Apesar do fato de as tabelas frequentemente terem mais famílias de colunas (o número máximo de colunas por tabela é 100), cada tabela requer pelo menos uma família de colunas. Uma interseção de chave de linha é composta de duas células (uma família de colunas combinada com um qualificador de coluna). No Cassandra e no Bigtable, existe um método para selecionar o nó de processamento para operações de leitura e gravação.
No Cassandra, a chave de partição é identificada, enquanto no Bigtable, a chave de linha é usada. Uma política de balanceamento de carga que está ciente dos datacenters, como uma política de vários clusters, fornece o potencial para failover. Ambos os bancos de dados usam um método semelhante para finalizar uma gravação e foram otimizados para velocidade. Os dados são armazenados nos dois bancos de dados por meio de arquivos SSTable que são imutáveis. No Cassandra, o coordenador deve notificar o cliente de que a gravação foi concluída antes que várias réplicas respondam. Uma gravação bem-sucedida no Bigtable só pode ser confirmada por uma resposta de um nó, pois cada chave de linha é atribuída a apenas um nó. As células em qualquer banco de dados podem não ser incluídas na SSTable mesclada.
Por causa da cláusula WHERE em uma consulta CQL, é impossível retornar mais de uma linha no Cassandra. Apenas o nó responsável pelo intervalo de chaves deve ser consultado no Bigtable. No nó de processamento, é possível limitar a quantidade de dados que podem ser lidos. Durante uma fase de compactação, os SSTables são mesclados regularmente e os dados armazenados no Bigtable e no Cassandra são armazenados neles. Não há regras que regem o número de versões de timestamp para cada célula, mas pode haver outros limites de tamanho de linha. As garantias de durabilidade dos dados são fornecidas pelo sistema de replicação da Colossus. Bigtable, como Cassandra, tem uma interface de linha de comando e bibliotecas de cliente para muitas linguagens de programação comuns.
Cada nó é atribuído a um SSTable no Bigtable e os dados armazenados nele são servidos por esse nó. Ao dimensionar um cluster do Cassandra, você não precisa levar em conta as réplicas de armazenamento como faz com o Bigtable. Unidades de estado sólido (SSD) ou unidades de disco rígido (HDD) são os tipos de armazenamento mais usados para instâncias do Bigtable . Conforme demonstrado por Cassandra, não há perda de densidade de armazenamento para atingir a tolerância a falhas. É possível dimensionar uma instância do Bigtable para atender aos requisitos de carga de trabalho com esforço mínimo e tempo de inatividade mínimo. Embora existam apenas quatro clusters, cada cluster pode ser criado em qualquer região de nuvem suportada em todo o mundo. O Google recomenda que você teste o desempenho do Bigtable com dados representativos e consultas para gerar uma métrica de QPS por nó.
Cassandra executa um grande número de funções de administração usando componentes gerenciados do Bigtable. Os backups largetable criam cópias restauráveis da tabela, que são armazenadas como objetos no cluster. Os backups consomem menos recursos de nó e são mais baratos do que o armazenamento em nuvem. Outro método para fazer backup do Bigtable é usar uma exportação de dados gerenciados para o Cloud Storage. Tarefas de manutenção interna, como aplicação de patches de sistema operacional, recuperação de nós, reparo de nós, monitoramento de compactação de armazenamento e rotação de certificados SSL, são todas tratadas perfeitamente pelo serviço Bigtable. Os painéis estão disponíveis para monitorar a taxa de transferência e as métricas de utilização em instâncias, clusters e níveis de tabela na página do console Bigtable Google Cloud . Você pode usar o painel de monitoramento para conduzir o ajuste de desempenho avançado.
O artigo da Bigtable descreve um sistema de armazenamento de dados que oferece suporte a escalabilidade massiva. Cada tabela nos dados é dividida em várias partições. Você pode consultar a tabela usando uma chave de linha ou um intervalo de chaves de linha. O documento Bigtable também descreve um método para distribuir o trabalho da tabela em um cluster de nós. O Apache Cassandra, um banco de dados de código aberto, é baseado em alguns dos conceitos do documento Bigtable. Os datacenters usam uma arquitetura de nó distribuído, na qual o armazenamento é compartilhado entre os servidores que fornecem os dados. O acesso ao sistema de armazenamento de dados do Bigtable é fornecido usando a interface de linha de comando cbt e as bibliotecas do cliente. O Bigtable inclui várias linguagens de programação além do Python, simplificando a integração com os aplicativos.
Datastax Astra Cassandra do Google como serviço: fácil de implantar e escalar
O DataStax Astra Cassandra como serviço do Google é uma excelente opção para aprender sobre Cassandra. A interface do usuário do Kubernetes Operator simplifica a configuração, o gerenciamento e o dimensionamento da implantação do Cassandra.
Documentação do Bigtable
A documentação do Bigtable é um ótimo recurso para aprender sobre essa poderosa ferramenta. Ele fornece uma visão geral dos recursos e capacidades do Bigtable, bem como informações detalhadas sobre como usá-lo. A documentação é bem organizada e fácil de seguir, tornando-se um recurso valioso para qualquer pessoa interessada em aprender sobre essa poderosa ferramenta.
O Google Cloud Platform é responsável por hospedar o banco de dados Bigtable do Google. É simples usar o OpenTSDB 2.1 e posterior quando usado em conjunto com o back-end do Google. Tudo o que você precisa fazer é criar uma instância do Bigtable, configurar suas tabelas TSDB usando o shell Bigtable HBase e iniciar os TSDs. Os clientes da Bigtable estão atualmente em versão beta e passando por uma série de mudanças.
O layout de dados eficiente do Bigtable
O Bigtable também é adequado para operações MapReduce. Devido ao seu layout de dados eficiente, o MapReduce pode lidar com grandes volumes de dados em um curto período de tempo.