
Hadoop HDFS e NoSQL: uma combinação poderosa para big data
Publicados: 2023-01-05O Hadoop é uma estrutura de código aberto que permite o processamento distribuído de grandes conjuntos de dados em clusters de computadores usando um modelo de programação simples. O HDFS é o Hadoop Distributed File System que fornece uma maneira escalável e tolerante a falhas de armazenar dados. Os bancos de dados NoSQL são uma nova classe de bancos de dados projetados para fornecer uma alternativa escalável, flexível e de alto desempenho aos bancos de dados relacionais tradicionais.
A principal distinção entre o Hadoop e o HDFS é que o Hadoop é uma estrutura de código aberto para armazenamento, processamento e análise de dados, enquanto o HDFS é um sistema de arquivos que permite aos usuários acessar os dados do Hadoop. Como resultado, o HDFS é um módulo do Hadoop .
SQL e Hadoop podem gerenciar dados de várias maneiras. Uma estrutura Hadoop é usada para montar componentes de software, enquanto uma estrutura SQL é usada para montar bancos de dados. Para big data, é fundamental considerar os prós e contras de cada ferramenta. A plataforma Hadoop armazena dados apenas uma vez, enquanto o Hadoop armazena um número muito maior de conjuntos de dados.
O Hadoop não é um banco de dados, mas sim um software que permite a computação paralela massiva. Essa tecnologia permite que bancos de dados NoSQL (como o HBase) espalhem dados por milhares de servidores com pouca degradação de desempenho.
O Hadoop não armazena dados da mesma forma que o armazenamento relacional. Um servidor distribuído é uma das aplicações que mais o utiliza. Embora seja um banco de dados Hadoop , ele não se qualifica como um banco de dados relacional porque armazena arquivos em HDFS (sistema de arquivos distribuídos).
Qual é a diferença entre Nosql e Hdfs?
É um sistema de arquivos e também é chamado de sistema de arquivos. Já está claro que este aplicativo oferece uma série de recursos. Onde você consegue esse material NOSQL? Poderemos processar grandes quantidades de dados em tempo real usando-o porque não requer o uso de bancos de dados relacionais ou outros recursos.
O gerenciador de armazenamento HBase, executado no Hadoop, fornece leituras e gravações aleatórias de baixa latência. O sistema HBase emprega um recurso de fragmentação automática no qual tabelas grandes são distribuídas dinamicamente. Cada Region Server é responsável por atender a um conjunto de regiões, e há apenas um Region Server capaz de atender a uma Região (ou seja, HMaster e HRegion são dois dos principais serviços fornecidos pelo HBase. O componente HRegion da tabela HBase é responsável por manipular subconjuntos de dados da tabela. Quando um Region Server é iniciado, ele é atribuído a cada Região. Como resultado, o mestre não está envolvido nas operações de leitura e gravação.
Quando se trata de lidar com dados volumosos e não estruturados, os bancos de dados NoSQL, como MongoDB e Cassandra, se destacam em relação aos bancos de dados relacionais tradicionais. As empresas com grandes cargas de trabalho de dados, como Big Data, preferem usar essas ferramentas para processar e analisar rapidamente grandes quantidades de dados variados e não estruturados. O MongoDB armazena dados em coleções, enquanto o hadoop armazena dados em um sistema de arquivos diferente, conhecido como HDFS. É vantajoso ter uma arquitetura diferente como resultado dessa diferença. Também é muito mais rápido consultar dados no MongoDB do que pesquisar em arquivos individuais. Além disso, como o mongodb foi projetado para ambientes de alto volume, ele é adequado para lidar com grandes volumes de dados a um custo relativamente baixo. Recomenda-se que as empresas que requerem soluções de Big Data usem bancos de dados NoSQL. Eles têm inúmeras vantagens em relação aos bancos de dados tradicionais em termos de velocidade de processamento e análise, e são adequados para análise e gerenciamento de dados em larga escala.
O Hadoop é um banco de dados Nosql?
O Hadoop não é um sistema tradicional de gerenciamento de banco de dados relacional. É um sistema de arquivos distribuído que ajuda a armazenar e processar grandes conjuntos de dados em um cluster de servidores comuns. O Hadoop foi projetado para escalar de servidores únicos para milhares de máquinas, cada uma oferecendo computação e armazenamento local.
O uso de dados em escala supermassiva está sendo revolucionado por novas tecnologias. A infraestrutura de big data tem vários players, incluindo Hadoop, NoSQL e Spark. DBAs e engenheiros/desenvolvedores de infraestrutura agora trabalham para eles para gerenciar sistemas complexos em uma nova geração de DBAs e engenheiros de infraestrutura. Como o Hadoop é um ecossistema de software em vez de um banco de dados, ele permite a computação de grandes quantidades de dados a uma taxa eficiente e eficaz. Os benefícios que ele oferece para as enormes quantidades de dados que ele manipula têm mudado o jogo para o processamento de big data. Uma grande transação de dados, como uma que leva 20 horas para ser concluída em um sistema de banco de dados relacional centralizado, pode ser concluída em apenas três minutos em um cluster Hadoop.
Há mais de uma linguagem SQL para escolher. MongoDB, um banco de dados de documentos puro, é um tipo de banco de dados NoSQL; Cassandra, um banco de dados de colunas largas, é outro; e Neo4j, um banco de dados gráfico, é outro. Esse recurso foi criado pelo SQL- on-Hadoop . SQL-on-Hadoop é uma nova classe de ferramentas analíticas que combina consultas SQL estabelecidas com estruturas de dados Hadoop. O SQL-on-Hadoop permite que desenvolvedores corporativos e analistas de negócios colaborem com o Hadoop em clusters de computação de commodities, permitindo a execução de consultas SQL familiares. As vantagens do SQL-on-hadoop. As inúmeras vantagens do SQL-on-Hadoop, além de sua facilidade de uso, valem o tempo e os recursos dos desenvolvedores e analistas de dados corporativos. Para começar, eles podem trabalhar com o Hadoop em clusters de computação de commodities, o que permitirá que eles comecem com análise de big data de maneira rápida e fácil. O SQL-on-Hadoop também permite que eles aproveitem as consultas SQL familiares, facilitando o aprendizado da análise de big data. Além disso, o SQL-on-Hadoop fornece a funcionalidade map/reduce do Hadoop, bem como os recursos avançados de análise de dados que ele fornece.
Bancos de dados Nosql em ascensão
Como resultado, os bancos de dados NoSQL estão se tornando mais populares devido à sua escalabilidade, desempenho de leitura/gravação e flexibilidade de dados. Existem vários bons exemplos de bancos de dados NoSQL no mercado, incluindo DynamoDB, Riak e Redis.
O Hive é um banco de dados NoSQL leve e modular com excelentes métricas de desempenho. Ele é escrito na linguagem de programação Dart pura e é popular entre os desenvolvedores devido à sua simplicidade.
Qual é a diferença entre Hadoop e banco de dados?

Embora o RDBMS não armazene e processe dados, o Hadoop armazena e processa dados como um sistema de arquivos distribuído. Um RDBMS, por outro lado, é um banco de dados estruturado que armazena dados em linhas e colunas e pode ser atualizado com SQL e apresentado em uma variedade de tabelas.
A adoção de tecnologias e ferramentas de big data tem crescido em um ritmo acelerado. Uma distribuição Hadoop de código aberto é executada em um sistema de arquivos distribuído e permite a troca e o processamento de grandes conjuntos de dados. Um RDB é um sistema básico de gerenciamento de banco de dados usado da forma mais simples por todos os sistemas de gerenciamento de banco de dados, como Microsoft SQL Server, Oracle e MySQL. Apesar de ser classificado como uma evolução, um RDBMS é mais parecido com qualquer outro banco de dados padrão do que um grande empreendimento. Não é um banco de dados, mas sim um sistema de arquivos distribuído que pode abrigar e processar grandes coleções de arquivos de dados. Embora sistemas como o Hadoop possam fornecer melhor desempenho, existem algumas desvantagens que raramente são discutidas. Você deve pensar em como gerenciar seu cluster Hadoop, segurança, Presto ou qualquer outra interface que você usa.
A maioria dos sistemas de banco de dados relacionais, como SQL Server e Oracle, são muito mais fáceis de usar. A maioria das organizações enfrenta um grande problema por não ter pessoal qualificado o suficiente para operar o Hadoop com eficiência, bem como um custo significativo de talento. Se você tiver 10.000 funcionários, precisará de muitos dados para acompanhar todos eles. Essas informações podem ser armazenadas de várias maneiras com o Presto. Uma partição de data pode ser usada para armazenar a posição de uma pessoa todos os dias. O RDBMS, por outro lado, pode ser usado como exemplo de modelo de dados. A única maneira de usar esse método é se você já tiver acesso aos dados do dia anterior.
Qual é a principal diferença entre bancos de dados relacionais e big data?
A principal distinção entre bancos de dados relacionais e big data é que os bancos de dados relacionais são otimizados para armazenar dados estruturados, enquanto big data é otimizado para armazenar dados não estruturados e semiestruturados. Um banco de dados relacional é modelado após o modelo relacional, enquanto um banco de dados big data é modelado após o modelo distribuído. Os dados estruturados podem ser armazenados e processados em bancos de dados relacionais de maneira eficiente. A tabela contém dados e permite acesso e recuperação de linguagem de consulta estruturada (SQL). Big data é definido como qualquer dado não estruturado ou semiestruturado.

Qual é a diferença entre Hadoop e Mongodb?
Como o MongoDB é executado em C, ele é melhor no gerenciamento de memória do que qualquer outro banco de dados. Hadoop é um conjunto de software baseado em Java que fornece uma estrutura para armazenar, recuperar e processar dados. O Hadoop otimiza o espaço com mais eficiência do que o MongoDB.
MongoDB era um banco de dados NoSQL (Not Only SQL) criado em C. Hadoop é uma plataforma de software de código aberto composta principalmente por Java que permite o processamento de grandes quantidades de dados. Além disso, o MongoDB Atlas inclui pesquisa de texto completo, análises avançadas e uma linguagem de consulta intuitiva. O Hadoop é eficiente para armazenar e processar uma grande quantidade de dados, mas o faz em pequenos lotes. Há uma variedade de ferramentas integradas de processamento de dados em tempo real disponíveis no MongoDB. Por causa de seus conectores para ferramentas externas, como Kafka e Spark, o MongoDB simplifica a ingestão e o processamento de dados. As vantagens do Hadoop e do MongoDB sobre os bancos de dados tradicionais no campo de big data são inúmeras. O Hadoop, um sistema de arquivos distribuído, pode ser usado para lidar com arquivos enormes. O MongoDB é o único banco de dados capaz de substituir um banco de dados tradicional em termos de desempenho.
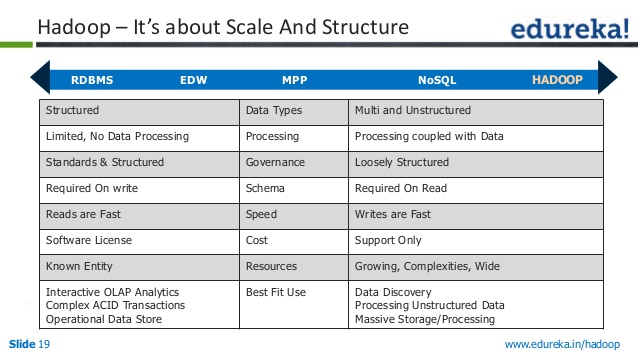
Rdbms x Nosql x Hadoop
Existem três tipos principais de armazenamento de dados – RDBMS, NoSQL e Hadoop. Cada um deles tem seus próprios pontos fortes e fracos, por isso é importante escolher o caminho certo para suas necessidades.
RDBMS (Relational Database Management System) é o tipo mais comum de armazenamento de dados. É fácil de usar e fácil de escalar. No entanto, não é tão flexível quanto NoSQL ou Hadoop e pode ser mais caro de manter.
NoSQL (Not Only SQL) é um novo tipo de armazenamento de dados que está se tornando mais popular. É mais flexível que o RDBMS e pode ser mais escalável. No entanto, não é tão fácil de usar e pode ser mais caro de manter.
Hadoop é um tipo de armazenamento de dados projetado para big data. É muito escalável e pode lidar com muitos dados. No entanto, não é tão fácil de usar quanto RDBMS ou NoSQL e pode ser mais caro de manter.
A abordagem de uma empresa para armazenar, processar e analisar dados pode ser bastante aprimorada com a plataforma Apache Hadoop . Um data lake pode executar vários tipos de cargas de trabalho analíticas no mesmo hardware e software, bem como gerenciar volumes de dados em grande escala. Os analistas agora podem interagir efetivamente com os dados em trânsito usando ferramentas como Apache Impala e Apache Spark. O Hadoop, ao contrário do Sistema de Gerenciamento de Banco de Dados Relacional (RDBMS), não possui os mesmos recursos de um banco de dados, mas é mais um sistema de arquivos distribuído capaz de processar grandes quantidades de dados. A quantidade de dados que pode ser processada de forma fácil e eficaz é chamada de Volume de Dados. Em outras palavras, é o processo de volume total de dados durante um período de tempo específico que pode ser otimizado. Ele tem a capacidade de armazenar e processar dados de uma ampla variedade de fontes e prepará-los para análise.
Em uma pequena quantidade, o RDBMS só poderia gerenciar dados estruturados e semi-estruturados. O Hadoop é incapaz de lidar com dados de várias fontes ou qualquer estrutura estruturada. O tempo de resposta, a escalabilidade e o custo são alguns dos outros fatores importantes a serem considerados.
Por que o Rdbms ainda é o sistema de gerenciamento de banco de dados mais popular
O sistema de gerenciamento de banco de dados mais utilizado no mundo é o RDBMS. Ele oferece uma ampla gama de recursos, além de ser extremamente confiável. O banco de dados relacional é mais adequado para armazenar dados necessários para acesso de vários usuários.
Os bancos de dados NoSQL estão ganhando popularidade em parte devido às suas vantagens de desempenho em relação aos bancos de dados relacionais. Eles também permitem que você armazene grandes quantidades de dados que não precisam ser compartilhados com vários usuários.
Hadoop NosqlName
Em um cluster de hardware de commodity, o Hadoop armazena Big Data. Você tem a opção de alterar qualquer função que não funcione ou atenda às suas necessidades, se necessário. Em contraste, um sistema de gerenciamento de banco de dados NoSQL é um tipo de sistema de gerenciamento de banco de dados usado para armazenar dados estruturados, semiestruturados e não estruturados.
Hdfs é um banco de dados
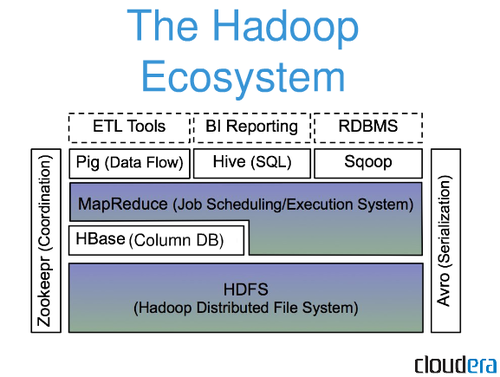
O sistema de arquivos HDFS é um sistema de arquivos distribuído executado em hardware comum. Um único cluster Apache Hadoop pode ser configurado para suportar centenas (e até milhares) de nós usando esse recurso. Apache Hadoop, que também inclui MapReduce e YARN, é composto de vários componentes principais.
O acesso de alto desempenho aos dados é fornecido pelo Hadoop Distributed File System (HDFS), que é um componente do sistema operacional Hadoop . O nó de nome primário de um cluster é responsável por controlar onde os dados do arquivo do cluster são armazenados. Além de gerenciar o acesso a arquivos, o nó Nome gerencia o acesso a arquivos como leituras, gravações, criações, exclusões e assim por diante. O Yahoo introduziu o Hadoop Distributed File System como parte de sua colocação de anúncios online e requisitos de mecanismos de busca. O protocolo HDFS expõe um namespace do sistema de arquivos para armazenar dados do usuário. Os DataNodes podem se comunicar uns com os outros durante as operações normais de arquivo porque eles se comunicam entre si. O Hadoop Distributed File System (HDFS) é um componente de muitos data lakes de software livre. O HDFS é usado pelo eBay, Facebook, LinkedIn e Twitter para analisar grandes quantidades de dados. No caso de falha de um nó ou hardware, a replicação de dados é necessária para que o HDFS funcione corretamente.
Exemplo de banco de dados Hadoop
Um banco de dados Hadoop é um banco de dados que usa o Hadoop Distributed File System (HDFS) para seu armazenamento subjacente. Os bancos de dados Hadoop são normalmente usados para armazenar grandes quantidades de dados que são grandes demais para caber em um único servidor.
Uma estrutura de software livre para armazenar e processar grandes conjuntos de dados de maneira distribuída em hardware comum, o Apache Hadoop é usado em vários aplicativos. É uma versão de código aberto do paradigma do Google que foi usado em seu artigo MapReduce de 2004. Abordaremos algumas das perguntas mais frequentes dos iniciantes no ecossistema de Big Data neste artigo. A plataforma Apache Hadoop concentra-se no processamento de dados distribuídos em vez de armazenamento de banco de dados ou armazenamento relacional. Apesar da presença de um componente de armazenamento conhecido como HDFS (Hadoop Distributed File System), que armazena os arquivos usados para processamento, o HDFS se enquadra na categoria de banco de dados relacional. O Hive, assim como o HiveQL, pode ser usado para consultar o armazenamento HDFS do HDFS, que é integrado ao HDFS.
O que é um exemplo de Hadoop?
O Hadoop pode ser usado por empresas de serviços financeiros para avaliar riscos, construir modelos de investimento e criar algoritmos de negociação; O Hadoop também tem sido usado para auxiliar na criação e gerenciamento desses aplicativos. Essa tecnologia é usada pelos varejistas para ajudá-los a entender e atender melhor seus clientes, analisando dados estruturados e não estruturados.
Os muitos usos do Hadoop
O Hadoop pode ser usado para gerenciar dados em grandes aplicativos de dados, como análise de big data, análise de dados em tempo real, pesquisa científica e armazenamento de dados. Como resultado, é uma plataforma versátil e adaptável ideal para uma ampla gama de aplicações.
Spark é um banco de dados Nosql
Um NoSQL DataFrame, de acordo com a documentação, é um formato de fonte de dados para o Spark DataFrame. DataPruning e filtragem (pushdown de predicado) estão disponíveis nesta fonte de dados, o que permite que as consultas do Spark sejam executadas em quantidades menores de dados, e apenas os dados necessários para o trabalho ativo são carregados.
É preciso muito esforço tático para conectar um banco de dados Apache Spark e NoSQL (Apache Cassandra e MongoDB) um ao outro. Este blog é sobre como criar aplicativos Apache Spark em back-ends NoSQL. O TCP/IP sPark é um destino de parque temático popular com um grande número de passeios em suas conhecidas seções CassandraLand e MongoLand. Quando nosso aplicativo Spark estava procurando dados do DOE, ele perdeu o controle e ficou frustrado. A lição aqui é que a sequência de chaves do Cassandra é crítica no processo de busca de dados. CassandraLand também tem uma montanha-russa popular chamada Partitioner. Os clientes em passeios de montanha-russa são incentivados a acompanhar seu histórico de passeios para que os operadores possam rastrear quem andou nele a cada dia. Lição 1 do Mongo – Gerencie as conexões do MongoDB corretamente Ao atualizar dados, como o status da associação do novo parque do Departamento de Energia, os índices do Mongo podem ser muito úteis. No caso de atualizações específicas, o MongoDB e o Spark devem garantir o gerenciamento e a indexação adequados da conexão.
Spark: o futuro do big data
O Apache Spark, um sistema de processamento distribuído desenvolvido em colaboração com a Apache Software Foundation, é um sistema de processamento de big data baseado em Hadoop. Uma estrutura de software livre que pode ser usada para otimizar grandes conjuntos de dados e preencher a lacuna entre modelos procedimentais e relacionais. Além disso, o Spark oferece suporte ao MongoDB, permitindo que ele seja usado para análise em tempo real e aprendizado de máquina.