
Escalabilidade horizontal com bancos de dados NoSQL
Publicados: 2022-11-20Os bancos de dados NoSQL são escaláveis horizontalmente, o que significa que eles podem ser dimensionados adicionando mais nós a um sistema, em oposição ao dimensionamento vertical, que se refere à adição de mais recursos a um único nó. Isso significa que um banco de dados NoSQL pode ser fragmentado ou dividido em várias partes, e cada parte pode ser armazenada em um servidor separado. Isso permite o dimensionamento horizontal do banco de dados, que é muito mais eficiente e escalável do que o dimensionamento vertical.
A escalabilidade é crítica para bancos de dados SQL e NoSQL, e o conceito de sharding de banco de dados é uma parte essencial disso. Estamos dividindo o banco de dados em pedaços (shards) como o nome sugere.
Além disso, há uma falta de capacidade de operações dinâmicas no NoSQL. Não há garantia de que o composto terá propriedades ACID. Bancos de dados SQL são uma opção nesses casos. Além disso, se seu aplicativo requer flexibilidade de tempo de execução, evite o NoSQL.
Quais são algumas desvantagens dos bancos de dados NoSQL? Uma das desvantagens dos bancos de dados NoSQL é que eles não têm o suporte de transação ACID (atomicidade, consistência, isolamento, durabilidade) necessário para transações ACID em vários documentos. Muitos aplicativos podem usar atomicidade de registro único com o design de esquema adequado.
O Mongodb pode ser fragmentado?
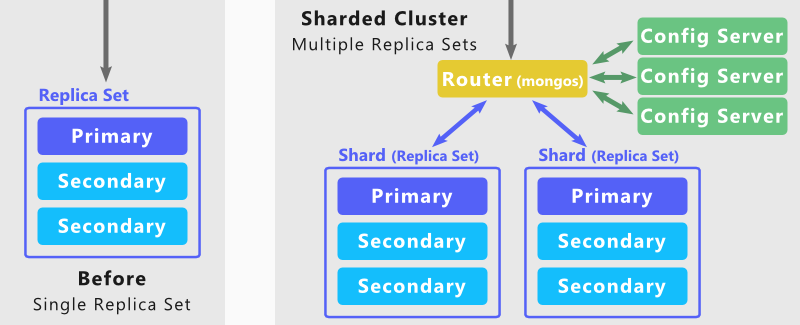
O back-end do MongoDB é construído em uma arquitetura de sharding para suportar conjuntos de dados extremamente grandes e operações de alto rendimento. Grandes bancos de dados com grandes quantidades de dados ou executando aplicativos de alta velocidade podem comprometer a capacidade do servidor.
Usando o MongoDB Sharding, você pode dimensionar seu banco de dados para lidar com um número infinito de usuários simultâneos. Isso é feito aumentando a taxa de transferência de leituras e gravações, bem como a capacidade de armazenamento do sistema. Existem inúmeras coleções que você pode escolher. Para maximizar o desempenho do cluster, escolha a chave de fragmentação com cuidado. O banco de dados MongoDB NoSQL oferece suporte a dois tipos de distribuição de dados em clusters com recursos de fragmentação. Os dados podem ser divididos em intervalos usando o valor de chave de intervalo de um estilhaço. Usando hash hash, o valor de um Shard com hash pode ser calculado.
Algumas chaves de fragmentação podem ser fechadas, mas é improvável que seus valores de hash estejam no mesmo bloco. Ao configurar e ativar a configuração Sharding, o banco de dados poderá ser acessado. Certifique-se de que seus mongos estão conectados. Seus fragmentos também serão adicionados ao cluster. Sempre que executar este procedimento, você terá concluído uma transação para cada fragmento. É necessário habilitar uma configuração de sharding em seu banco de dados. Em seguida, use o método sh.shardCollection() para fragmentar sua coleção. Agora você criou seu primeiro cluster fragmentado. Até agora, roteadores (instâncias mongos) foram usados para interações de aplicativos.
O MongoDB é um excelente banco de dados NoSQL para pequenas e médias empresas que exigem escalabilidade e desempenho. Além disso, inclui recursos como sharding, que permite a distribuição de documentos entre os shards para melhorar o desempenho. Se seu banco de dados atingir 200 GB ou mais, os processos de backup e restauração podem ficar mais lentos. Como resultado, sempre que seu banco de dados MongoDB crescer além de um determinado tamanho, você deve sempre consultar seu provedor MongoDB.
Quais bancos de dados suportam sharding?

Os bancos de dados que suportam sharding são normalmente projetados para serem executados em vários servidores, com cada servidor hospedando uma parte do banco de dados. Isso permite que o banco de dados seja distribuído em vários servidores, o que pode melhorar o desempenho e a escalabilidade.
Fragmentação em Nosql

Os padrões de particionamento baseados em tecnologias NoSQL incluem hash. O particionamento envolve colocar cada partição em um servidor potencialmente separado – possivelmente em todo o mundo. Usuários de todo o mundo podem se beneficiar dessa expansão, que lhes permite acessar diferentes partes do conjunto de dados ao mesmo tempo.
Um conjunto de dados é distribuído armazenando-o em vários bancos de dados para alcançar o resultado desejado. Como essa abordagem permite a divisão de conjuntos de dados maiores em partes menores, vários nós de dados podem ser usados para armazená-los. Como os dados são distribuídos em várias máquinas, um banco de dados fragmentado pode lidar com mais solicitações do que uma única máquina. Usando o Sharding para lidar com o aumento da carga de forma ilimitada, você pode aumentar a taxa de transferência, a capacidade de armazenamento e a disponibilidade em seu banco de dados. Quando sua carga de trabalho é gravada principalmente para leitura, a replicação de dados fornecerá ganhos significativos de desempenho e talvez você não precise usar o sharding. Uma arquitetura diferente é necessária para uma carga de trabalho baseada principalmente em gravação ou uma que seja combinada com leitura-gravação. Existem muitos tipos e arquiteturas diferentes de sharding.

O uso de sharding baseado em intervalos é um método simples e direto de partição horizontal; no entanto, sua eficácia será determinada pela disponibilidade de chaves adequadas e pela escolha de intervalos apropriados. Um registro de fragmentação hash ou algorítmico é aplicado como uma entrada, onde a função ou algoritmo de hash é usado para gerar uma saída ou valor de hash. Os dados podem ser preservados em um único espaço físico usando fragmentação baseada em hash. Em um banco de dados relacional , os dados associados a uma tabela específica podem ser espalhados por outras tabelas. Mesmo que uma chave adequada não possa ser obtida, o hash das entradas permite uma distribuição uniforme dos dados entre os fragmentos. Ele pode ajudar com operações de transmissão reduzidas, bem como aumentar o desempenho. Um serviço de fragmentação baseado em geografia também mantém os dados relacionados em um único local em um único servidor. Um estilhaço variado é aquele distribuído geograficamente, no qual a chave para a chave é uma chave geolocalizada para os estilhaços. Existem várias outras opções que não são abordadas neste artigo para alocar geoshards.
O que é fragmentação em SQL?
Um armazenamento de dados pode ser distribuído em vários bancos de dados por meio do método de hash e, em seguida, armazenado em várias máquinas. Isso permite que conjuntos de dados maiores sejam divididos em blocos menores e armazenados em vários nós de dados, aumentando a capacidade geral do sistema.
Este algoritmo não garante dados particionados uniformemente
Este algoritmo, de acordo com este algoritmo, garante que os dados serão distribuídos uniformemente pelos estilhaços, mas não garante que serão distribuídos uniformemente pelos estilhaços. Uma linha na coluna de partição com o nome de dados user_id será distribuída igualmente entre os cinco estilhaços; no entanto, os valores de dados para os cinco estilhaços não serão divididos igualmente.
O Mongodb usa sharding?
Usando uma combinação de técnicas, várias máquinas podem compartilhar dados por meio de um método de Sharding. Ao implantar grandes conjuntos de dados e executar operações de alto volume, o MongoDB emprega sharding. Os sistemas de banco de dados com uma grande quantidade de dados ou aplicativos que exigem alto rendimento podem ocupar uma quantidade significativa de capacidade de armazenamento.
O futuro da fragmentação: Postgresql
Faça um plano para o futuro. Não só é possível implantar uma solução de sharding, mas também é uma etapa necessária. Como parte do processo, o ajuste e a otimização são necessários regularmente. Você deve estar ciente de que as soluções de sharding atuais estão evoluindo rapidamente e você deve se manter atualizado. O PostgreSQL fez um progresso significativo no espaço de sharding nos últimos anos, portanto, se você deseja uma solução que possa ser usada em várias plataformas, considere seriamente usá-la.
Fragmentação Nosql Vs Particionamento
O particionamento e os algoritmos para classificar um grande conjunto de dados em seções menores são análogos. Os dados são particionados para que possam ser distribuídos em vários computadores, enquanto o sharding permite que sejam distribuídos em vários computadores. Em geral, os dados particionados são divididos em subconjuntos com base em uma única instância de banco de dados .
O particionamento por subtração é um tipo de partição, além do particionamento horizontal. Outro método é a partição vertical, na qual você divide uma tabela em partes menores. Quando você replica uma partição vertical, ela é chamada de particionamento vertical. Para dividir os dados, copie o esquema e use uma chave de fragmentação. Aqui estão alguns exemplos de quando é apropriado dividir uma tabela. Quando os dados são particionados, geralmente é mais fácil realizar consultas. Suponha que um aplicativo contenha uma tabela Order contendo um registro histórico de pedidos e que essa tabela seja particionada toda semana. Ao solicitar pedidos para uma única semana, você só poderá acessar uma partição da tabela Pedidos. Um procedimento de remoção de partição para esta consulta poderia teoricamente permitir que ela seja executada 100 vezes mais rápido.