
Como os bancos de dados Sql e Nosql escalam
Publicados: 2022-11-18Com a popularidade cada vez maior dos aplicativos da Web e a quantidade de dados que eles geram, a necessidade de bancos de dados que possam ser dimensionados com rapidez e eficiência é mais importante do que nunca. Bancos de dados SQL e NoSQL são duas das escolhas mais populares para desenvolvedores que procuram uma solução de banco de dados escalável. Os bancos de dados SQL existem há décadas e são a escolha tradicional para muitos aplicativos. Eles usam um esquema fixo, o que significa que a estrutura do banco de dados é definida antecipadamente e todos os dados devem estar de acordo com esse esquema. Isso pode tornar os bancos de dados SQL mais difíceis de trabalhar quando os conjuntos de dados são grandes e complexos. Os bancos de dados NoSQL, por outro lado, são relativamente novos e são projetados para trabalhar com conjuntos de dados grandes e complexos. Eles têm um esquema flexível, o que significa que a estrutura do banco de dados pode ser alterada conforme necessário. Isso pode tornar os bancos de dados NoSQL mais fáceis de trabalhar, mas também significa que eles podem não ser tão confiáveis quanto os bancos de dados SQL. Ambos os bancos de dados SQL e NoSQL têm seus prós e contras quando se trata de escalabilidade. Os bancos de dados SQL são mais difíceis de trabalhar, mas são mais confiáveis. Os bancos de dados NoSQL são mais fáceis de trabalhar, mas podem não ser tão confiáveis.
Diferentes técnicas e princípios de dimensionamento podem ser aplicados a um banco de dados, dependendo do seu tipo. O dimensionamento é crítico para bancos de dados NoSQL e não NoSQL, e o conceito de fragmentação do banco de dados é um componente crucial. Quando os servidores são distribuídos, ganhamos os benefícios de poder armazenar mais dados e, ao mesmo tempo, herdar os problemas de um sistema distribuído. Os engenheiros teriam que escrever manualmente a lógica para lidar com o sharding automático em um banco de dados de mainframe porque ele não é compatível. Como solução, coloque um proxy, como um balanceador de carga, na frente do serviço de consulta e do banco de dados. O proxy pode ser reiniciado se o shard for muito grande, o que permitirá que as consultas sejam executadas mais rapidamente. É amplamente assumido que o dimensionamento de bancos de dados NoSQL é um processo altamente automatizado que só é visto pelo usuário final.
Uma arquitetura mestre-escravo é baseada em transações únicas, enquanto uma arquitetura baseada em fragmentos é baseada em transações aleatórias. Uma consulta de leitura direcionada aos fragmentos escravos reduzirá a carga no fragmento mestre. Podemos replicar o banco de dados no nível do data center para garantir que tenhamos um backup. Os nós podem se comunicar uns com os outros trocando informações. É comum que os nós se comuniquem com um número predeterminado de outros nós. Um nó no Cassandra pode simplesmente replicar seus dados em outros nós porque os nós são considerados iguais. O protocolo gossip é um subconjunto de todo o conceito de nós.
Você pode desistir de certas propriedades em um banco de dados distribuído para obter mais delas. Quase sempre é crítico replicar dados para manter a disponibilidade. Você terá uma pequena diferença na consistência de seu banco de dados no início, mas isso melhorará com o tempo. Os bancos de dados SQL são usados para dados de alta precisão em sistemas financeiros, enquanto os bancos de dados NoSQL são usados para dados menos importantes, como contagens de visualizações.
Os dois métodos de dimensionamento de um banco de dados são dimensionamento vertical e aumento da CPU ou RAM de sua máquina de banco de dados existente. Adicione mais máquinas ao seu cluster de banco de dados para lidar com um subconjunto dos dados totais para escalar horizontalmente.
A era da internet e da computação em nuvem permitiu a criação de bancos de dados NoSQL, o que facilitou a implementação de uma arquitetura de expansão. Uma arquitetura de expansão envolve a distribuição do armazenamento de dados e do trabalho necessário para processá-los em um grande número de computadores.
A capacidade de lidar com grandes quantidades de dados também é vantajosa. Os bancos de dados SQL podem ser dimensionados verticalmente, permitindo que você carregue um servidor maior com mais CPU, RAM e capacidade de SSD.
Como os bancos de dados Nosql escalam?
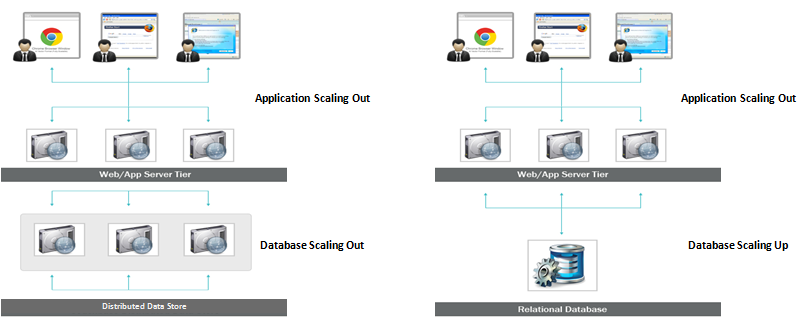
Como os bancos de dados SQL têm escalabilidade vertical, você pode aumentar a carga em um único servidor aumentando a RAM, SSD ou CPU em um banco de dados SQL. Os bancos de dados NoSQL, por outro lado, são escalonáveis horizontalmente, o que significa que eles podem lidar com o aumento do tráfego com mais facilidade adicionando mais servidores.
Rahim Yaseen, do Couchbase, nos guia por alguns pontos críticos à medida que avançamos. Uma grande quantidade de dados está inundando as organizações, e elas estão procurando maneiras de gerenciá-los, armazená-los e explorá-los. A principal decisão no gerenciamento de banco de dados é expandir ou escalar horizontalmente. A fragmentação manual, na qual cada registro é atribuído a um estande diferente, permite que o registro seja distribuído por vários estandes de check-in. Porque tem um esquema bem definido, pré-definido, funciona. Se você tivesse discagem automática, precisaria ir a cada estande e procurar pessoas cujo sobrenome fosse S. Um banco de dados de documentos tem vários padrões de acesso direto que exigem acesso direto aos dados por meio de uma única tecla e navegação para outro documento por meio de uma chave relacionada. A indexação secundária e a consulta são dois grandes desafios ao lidar com dados distribuídos.
Como cada nó deve participar da execução da consulta para executar a consulta, o uso de uma técnica de redução de mapa é desnecessário. À medida que o volume de dados cresce, a expansão no estilo RDBMS torna-se cada vez menos prática. Uma falha de uma arquitetura de expansão subjacente a um grande conjunto de dados quase certamente resultará em um grande ponto de falha. Como um exemplo clássico de um cluster de ultraescala sem compartilhamento, a Internet é um deles.
Um banco de dados NoSQL pode ser dimensionado horizontalmente para atender às necessidades de uma ampla gama de usuários. É possível utilizá-los em qualquer máquina, sem a necessidade de hardware especializado. Como resultado, o NoSQL é uma excelente escolha para sistemas que exigem a capacidade de escalar rapidamente ou sem amplo conhecimento.
Como os bancos de dados Sql escalam?
Uma escala é um número que tem um valor à direita do ponto decimal. Há uma precisão de 5 neste número, por exemplo, e uma escala de 2. No SQL Server, os tipos de dados numéricos e decimais podem atingir uma precisão máxima de 38 bits. O máximo padrão do SQL Server em versões anteriores era 28.
Neste artigo, fornecerei algumas ideias básicas e dicas sobre o dimensionamento de bancos de dados relacionais tradicionais. É amplamente aceito que o dimensionamento deve ocorrer verticalmente (em um único servidor de banco de dados) usando um hardware melhor. É sempre crítico equilibrar eficiência e funcionalidade ao selecionar tipos de dados. A normalização e a desnormalização de dados são duas maneiras fundamentais de pensar nos tipos de dados ideais. Ao analisar grandes quantidades de dados, o pré-processamento de dados pode ser benéfico. Ao usar índices adequados nas tabelas, o desempenho pode ser bastante aprimorado. Devemos saber exatamente como nosso planejador de consulta lida com nossas consultas para garantir que ele execute o trabalho corretamente.
Quando examinamos a estrutura de nossos dados, podemos determinar se devemos adicionar índices ou reescrever nossa consulta. Os quatro níveis básicos de isolamento definidos no padrão SQL:1992 afetarão muito a forma como usamos nosso sistema de banco de dados . Antes de decidir se a compactação na camada de aplicativo fornecerá o benefício desejado, você deve primeiro examinar como os dados são armazenados e se a compactação é necessária. Como a inserção de uma coluna em um local específico leva muito tempo, é preferível inserir uma nova coluna no final da tabela. O capô de um banco de dados pode já estar cheio de dados compactados. Podemos escalar horizontalmente para operações de gravação adicionando mais servidores, mas também podemos usar réplicas somente leitura para expandir nossa capacidade. O particionamento com esteróides nos permite armazenar partes da tabela do banco de dados (shard) em diferentes servidores.
Sharding é o processo de armazenamento de dados em bancos de dados. Outra extensão de banco de dados, como TimescaleDb ou PostGIS, pode ser usada para melhorar o processamento de dados e a eficiência de armazenamento. É possível transferir dados de um sistema para outro e processá-los lá. Também podemos enviá-lo para um banco de dados analítico, como Hadoop ou Clickhouse. A distribuição Apache Spark é um software de computação em cluster distribuído gratuito e de código aberto que pode ser usado para computação de dados em larga escala. Outras maneiras de mover dados incluem copiar o banco de dados, extrair dados usando SQL e assim por diante. Se você escolher provedores de nuvem como AWS ou Azure, saiba que eles não oferecem suporte a bancos de dados SQL gerenciados.
Essa limitação é ampliada ao lidar com grandes conjuntos de dados distribuídos em vários nós. Esses conjuntos de dados são divididos em partes gerenciáveis pelo MySQL Cluster e distribuídos para os nós em paralelo. Se o banco de dados tiver um instantâneo a qualquer momento, ele não precisará esperar que uma consulta retorne um resultado. Como resultado, você pode usar essa vantagem de escalabilidade para analisar grandes conjuntos de dados em tempo real ou processar dados em massa. O MySQL Cluster é uma excelente opção para cargas de trabalho que requerem uma operação simples devido à sua facilidade de uso, permitindo economizar tempo e dinheiro, mantendo os mesmos recursos de um banco de dados relacional tradicional. O MySQL Cluster é uma ótima opção para empresas que desejam dimensionar seus bancos de dados horizontalmente sem sacrificar o desempenho. Em vez de um sistema de banco de dados relacional tradicional, as empresas podem economizar tempo e dinheiro utilizando o MySQL Cluster.

Os Estados Unidos da América são um país fundado na ideia de liberdade, a terra dos livres
Nosql ou Sql é mais escalável?
Na maioria dos casos, os bancos de dados SQL podem ser escaláveis verticalmente. Um único servidor pode ser atualizado com mais capacidade de CPU, RAM ou SSD para lidar com mais tráfego. Os bancos de dados NoSQL podem ser dimensionados horizontalmente. Ao fragmentar, você pode aumentar o número de servidores em seu banco de dados NoSQL, permitindo que você lide com mais tráfego.
Os aplicativos exigem mais escalabilidade à medida que se tornam mais complexos. Os armazenamentos de dados que podem ser dimensionados com eficiência e facilidade também devem ser considerados. A principal distinção entre os dois é se o banco de dados deve ser 'ASL' ou 'NoSQL'. Os bancos de dados SQL existem há muito tempo, enquanto os bancos de dados NoSQL são conhecidos por sua facilidade de escalabilidade. Cada operação em um banco de dados NoSQL requer o uso de sharding. Cada operação de dados deve incluir um método de qualificação, que identifica o nó onde os dados residem. Os dados são armazenados em várias máquinas, facilitando as operações de dados mesmo em máquinas de baixa potência.
Para facilitar o dimensionamento de armazenamentos NoSQL , são usadas máquinas de commodities simples. Com base no NoSQL, o usuário assume que irá pré-planejar e estruturar os dados de forma que todos os dados necessários para uma operação específica possam ser buscados de uma só vez no mesmo nó. Os dados também devem ser normalizados entre os nós (dados pré-preparados para operação) para serem normalizados. No NoSQL, você pode unir arquivos, mas não espere junções no estilo SQL com estruturas otimizadas. Os aplicativos no mundo NoSQL acreditam que a consistência dos dados é garantida ao longo do tempo. Faz sentido que os sistemas NoSQL forneçam opções para fazer alterações na consistência além do que é necessário. Um aspecto importante de qualquer decisão de arquitetura, como qualquer outro aspecto, é examinar o caso de uso e selecionar o armazenamento de dados correto.
Escolher o banco de dados certo é crítico porque requer um grande número de usuários. MongoDB, Apache HBase e Cassandra são bancos de dados NoSQL que podem ser implantados mais rapidamente do que os bancos de dados padrão . A razão para isso é que eles não aderem ao modelo ACID, o que pode resultar em um desempenho inferior. Os bancos de dados NoSQL, por outro lado, são capazes de executar em altos níveis quando necessário. Ao selecionar um banco de dados, certifique-se de que ele é apropriado para suas necessidades.
Por que usar bancos de dados relacionais?
Faz todo o sentido escalar seu banco de dados verticalmente porque ele é bem protegido e tem baixa latência. Os bancos de dados não relacionais, ao contrário dos bancos de dados relacionais compatíveis com ACID, carecem de consistência e segurança para desempenho e escalabilidade. Um banco de dados NoSQL é uma excelente opção para dimensionamento horizontal, pois não tem limite para o número de servidores e pode ser dimensionado rapidamente devido à sua baixa velocidade de processamento.
Por que o Sql não é escalável horizontalmente?
O SQL não é escalável horizontalmente porque é um sistema de gerenciamento de banco de dados relacional (RDBMS). RDBMSs não são projetados para escalar horizontalmente. Eles são projetados para escalar verticalmente, o que significa que eles são projetados para escalar adicionando mais recursos (CPU, memória, etc.) a um único servidor.
Por que o Nosql é melhor para dimensionamento horizontal?
Um banco de dados NoSQL pode ser escalado horizontalmente. Além de lidar com tráfego mais alto, o sharding permite que você adicione mais servidores ao seu banco de dados NoSQL. Não é nenhum segredo que os bancos de dados NoSQL são a escolha preferida para conjuntos de dados grandes e que mudam com frequência porque seus recursos de escala horizontal excedem seus recursos de escala vertical.
Como dimensionar o banco de dados Nosql
dimensionar bancos de dados nosql é um processo de aumentar a capacidade de um sistema para lidar com cargas de trabalho maiores adicionando mais recursos. O processo de escalar um banco de dados nosql pode ser dividido em duas abordagens principais: escala vertical e escala horizontal.
O dimensionamento vertical é o processo de adicionar mais recursos a um único nó em um sistema, como adicionar mais núcleos de CPU, memória ou armazenamento. Essa abordagem pode ser usada para aumentar a capacidade de um banco de dados nosql para lidar com mais dados ou mais usuários.
A escala horizontal é o processo de adicionar mais nós a um sistema. Essa abordagem pode ser usada para aumentar a capacidade de um banco de dados nosql para lidar com mais dados ou mais usuários adicionando mais nós ao sistema e distribuindo a carga de trabalho entre os nós.
Se você tiver um ambiente Node.js em funcionamento, poderá concluir este tutorial. Criei uma pasta chamada nodejs-dynamodb-sample contendo os arquivos DynamoDB que importei. Consulte minha página do GitHub para obter um link para a amostra. O aplicativo de amostra está disponível para pesquisar e recuperar dados de filmes do DynamoDB. Neste artigo, usaremos o serviço de gerenciamento de identidade e acesso (IAM) da Amazon para armazenar dados no S3 e acessar o DynamoDB no Amazon Web Services (AWS). Você deve primeiro se registrar e criar um usuário para usar o serviço IAM da Amazon. Você pode criar uma nova conta POST /movies inserindo o título e o ano de um filme.
Se você deseja acompanhar os filmes de um ano específico, insira um campo com chave. Você pode então passar para a criação de seu próprio aplicativo com base neste. Se você não excluir suas tabelas depois de usadas, corre o risco de incorrer em custos de hospedagem e serviço da AWS. Ao visitar o console do DynamoDB no Amazon Web Services, você pode ver quanto armazenamento você tem na AWS. Você pode visualizar os itens em uma tabela na tabela Itens, acessar métricas de seu aplicativo e ver o custo mensal estimado clicando em 'Filmes'. O código para este exercício pode ser encontrado na minha página do GitHub, https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Os prós e contras dos bancos de dados Nosql e Sql
Por vários motivos, os bancos de dados NoSQL surgiram como uma alternativa aos bancos de dados SQL tradicionais . O processo de dimensionamento é praticamente invisível para o usuário final porque foi projetado com o dimensionamento em mente. Como resultado, eles são ideais para aplicativos que exigem alta taxa de transferência ou baixa latência. Os bancos de dados NoSQL são mais adequados para dados não estruturados, como documentos, enquanto os bancos de dados SQL são mais adequados para transações de várias linhas. Em geral, há uma diferença na forma como as transações são tratadas em cada tipo de banco de dados. Os bancos de dados SQL são diferenciados por linhas de tabela para transações, enquanto os bancos de dados NoSQL são diferenciados por documentos para transações. Embora essa diferença nem sempre seja óbvia, pode ser significativa em certos casos.
Como o Nosql escala horizontalmente
Os bancos de dados Nosql são projetados para serem escaláveis, o que significa que eles podem lidar com quantidades crescentes de dados e tráfego sem diminuir a velocidade. Uma maneira de conseguir isso é escalando horizontalmente, o que significa adicionar mais servidores ao sistema conforme necessário. Isso contrasta com o dimensionamento vertical, o que significa adicionar servidores mais poderosos.
Bancos de dados Nosql são mais fáceis de dimensionar horizontalmente
Como os bancos de dados NoSQL não têm esquema, é mais fácil escalar horizontalmente porque os objetos podem ser armazenados em diferentes servidores sem a necessidade de unir linhas. Você carrega o banco de dados do sistema de vários servidores como parte do dimensionamento horizontal.
Diferença entre SQL e Nosql
Bancos de dados SQL são bancos de dados relacionais que usam linguagem de consulta estruturada para armazenar e recuperar dados. Os bancos de dados NoSQL são bancos de dados não relacionais que não usam linguagem de consulta estruturada e geralmente são mais escaláveis e têm melhor desempenho do que os bancos de dados SQL.
Linguagens de consulta estruturada (SQL) estão entre as linguagens de programação mais usadas e populares para sistemas de gerenciamento de banco de dados relacional . Os dados armazenados e recuperados em modelos NoSQL diferentes de formulários tabulares são mais facilmente acessíveis. Ambos os produtos são listados com um entendimento completo de suas vantagens e desvantagens para fornecer uma visão clara de seus prós e contras. SQL é a linguagem de programação mais popular para RDBMS e é usada para armazenar dados não estruturados, semiestruturados e estruturados, enquanto NoSQL é a linguagem de programação mais popular para armazenar dados estruturados, não estruturados e semiestruturados. Dependendo dos seus requisitos e do projeto em que você está trabalhando, qual é o melhor é uma boa opção. Há uma distinção entre os dois tipos: o primeiro é focado em consultas complexas com consistência de dados e propriedades ACID, enquanto o último é baseado em objeto e pode lidar com uma ampla variedade de tipos de dados.