
InfluxDB: um banco de dados de séries temporais
Publicados: 2022-11-18InfluxDB é um banco de dados de séries temporais escrito em Go e desenvolvido pela InfluxData. Ele foi projetado para ser escalável, com foco em alto desempenho de gravação e consultas rápidas. Também é de código aberto, com uma versão comunitária e uma versão corporativa. O InfluxDB é frequentemente usado em conjunto com o Grafana, uma ferramenta de visualização de dados de código aberto. O InfluxDB é uma escolha popular para dados de série temporal, devido ao seu alto desempenho de gravação e consultas rápidas. Também é de código aberto, o que o torna atraente para muitos desenvolvedores.
Para realizar uma comparação, usamos análises de usuários reais do PeerSpot para comparar o InfluxDB com o Oracle NoSQL . Neste artigo, compararemos os recursos, preços, serviço e suporte, facilidade de implantação e ROI dos bancos de dados NoSQL para descobrir qual é o mais adequado para o seu negócio. Desde 2012, nossa pesquisa foi utilizada por 648.701 profissionais. O InfluxDB, que é uma oferta baseada em nuvem, tem o melhor recurso, que é seu banco de dados de série temporal, consultas rápidas em massa de tempo e operações de janela. Existem alguns problemas com a API em massa para InfluxDB, que é incompatível com dados de alta cardinalidade. Use nosso mecanismo de recomendação gratuito para determinar qual banco de dados NoSQL atenderá melhor às suas necessidades. O InluxDB é um programa de software gratuito de código aberto que permite que desenvolvedores e empresas gerenciem dados de séries temporais.
O InfluxDB permite monitorar e analisar a Internet das Coisas (IoT), aplicativos, sistemas, contêineres e infraestrutura. Um revisor citou a agregação de dados e a integração com o Grafana como os recursos mais importantes. O Oracle NoSQL Database destina-se a ser um sistema de banco de dados muito grande e altamente disponível. Estão disponíveis operações completas de criação, leitura, atualização e exclusão (CRUD), bem como uma variedade de garantias de durabilidade e consistência. Com quatro avaliações, o InfluxDB ocupa o quinto lugar no mercado de banco de dados NoSQL, atrás apenas do Oracle No SQL, que ocupa o sétimo lugar com um. Como o banco de dados mais recomendado, possui uma interface muito simples e é leve e poderoso.
O InfluxDB não é um banco de dados relacional porque não inclui nenhuma chave primária ou estrangeira, nenhuma junção de medições e assim por diante. tags como solução: as tags são usadas como uma solução alternativa na teoria, mas são apropriadas apenas para dados com baixa cardinalidade. Você precisará de uma grande quantidade de memória se tiver muitos registros com uma marca de identificação exclusiva.
O banco de dados influxDB é semelhante a um banco de dados SQL, mas há várias diferenças. Esse banco de dados foi projetado especificamente para lidar com dados de séries temporais. Apesar do fato de que os bancos de dados relacionais podem lidar com dados de séries temporais, eles não são otimizados para cargas de trabalho de séries temporais comuns.
O InfluxDB Cloud é uma plataforma de dados de séries temporais totalmente gerenciada e elástica que permite aos usuários iniciar rapidamente e escalar rapidamente para atender às suas necessidades.
Um banco de dados de série temporal (TSDB) criado por InfluxData é um banco de dados de código aberto. Dados de séries temporais, como operações, métricas de aplicativos, dados de sensores da Internet das coisas e análises em tempo real, podem ser armazenados e recuperados usando esta biblioteca em Go.
Graphql é SQL ou Nosql?
No GraphQL, usamos um sistema de tipo para retornar dados com eficiência em consultas dinâmicas, que são uma linguagem de consulta baseada em tipo. SQL (linguagem de consulta estruturada) é um padrão mais antigo e amplamente utilizado para o design, implementação e gerenciamento de estruturas de dados em bancos de dados tabulares e hierárquicos. Se você quiser usar um banco de dados NoSQL para sua API, vá para GraphQL.
Ambos os bancos de dados Type Mismatch e GraphQL foram criados por Cochrane e Herman Camarena. Um sistema de tipos pode ser introduzido usando GraphQL em vez de um sistema NoSQL porque ainda podemos aproveitar as vantagens do NoSQL. A estrutura do documento em uma coleção GraphQL varia ligeiramente de um documento para outro, com algumas exceções. Por causa das APIs do GraphQL, um desenvolvedor pode escolher quais tipos de dados deseja que correspondam aproximadamente aos tipos de back-ends. Para realizar todo o potencial do GraphQL, o problema de incompatibilidades de tipo deve ser resolvido. Como linguagem, tem muitas vantagens, que tornam o problema de incompatibilidade menos grave. Usando ferramentas como o JSON2SDL da StepZen, você poderá automatizar ainda mais o trabalho.
Graphql é independente de fontes de dados
Não é independente de nenhuma fonte de dados para a qual as alterações são armazenadas ou recuperadas. Os dados podem ser acessados e manipulados usando funções arbitrárias conhecidas como resolvedores.
Influx SQL ou Nosql?
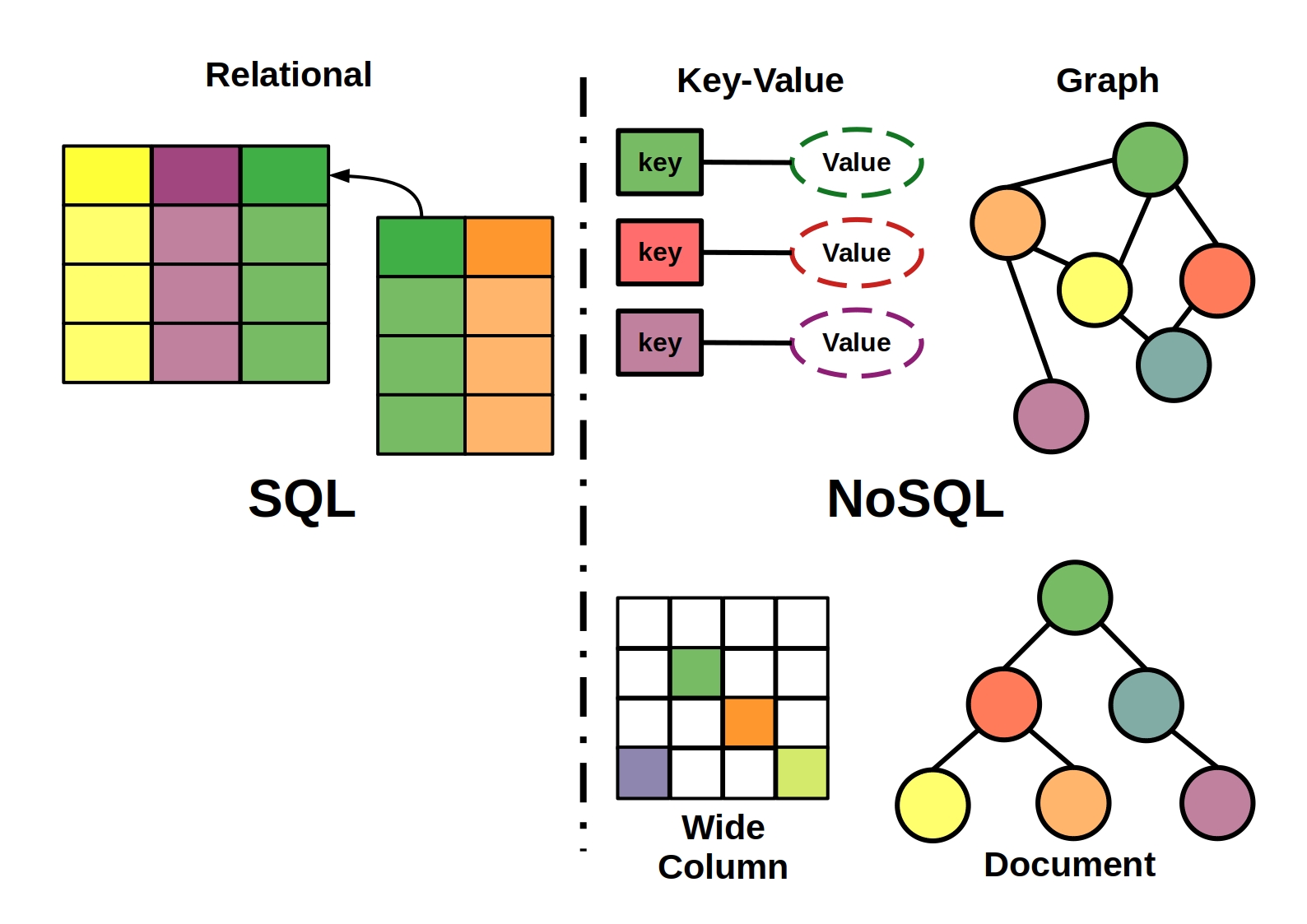
InfluxDB é um banco de dados relacional desenvolvido pela InfluxData. é um banco de dados gratuito e de código aberto que combina big data , NoSQL e escalabilidade. Possui alta disponibilidade, alta velocidade de gravação e está disponível sob demanda. InfluxDB, um banco de dados NoSQL, armazena um conjunto de pontos de dados ao longo do tempo com base em uma série de pontos de dados de séries temporais.
Seu objetivo é ser usado para dados de séries temporais. Cada série de dados possui um timestamp que identifica um único ponto dentro dela. Em uma tabela de banco de dados, a chave primária é sempre definida pelo sistema neste caso, assim como em bancos de dados SQL. Na maioria dos casos, adicionar um novo campo a uma medição pode ser feito simplesmente escrevendo um ponto para ele. Descrições mais detalhadas dos termos do influxDB mencionados nesta seção podem ser encontradas em nosso Glossário de termos. Ao usar o InfluxDB 1.8 com Flux, você pode obter uma compreensão básica de sua sintaxe e conceitos. InfluxQL, uma linguagem de consulta semelhante a SQL, é usada para interagir com o influxDB.
O ambiente SQL foi pensado para que quem veio de outros ambientes fique à vontade com ele. O programa não suporta operações avançadas como UNION, JOIN ou HAVING. O carimbo de data/hora atual do servidor pode ser usado com tempo relativo e now() para calcular o tempo relativo. Esta consulta gera uma lista de dados de foodships. Um banco de dados CR-ud não é um banco de dados CRUD completo, mas sim um banco de dados mais parecido com o afluxDB. Ele foi projetado para priorizar a geração e leitura de dados em vez de atualizar e destruir dados.
InfluxDB e MySQL são dois dos bancos de dados de séries temporais mais amplamente usados. Ambas as ferramentas de código aberto são simples de usar e podem ser personalizadas. O InfluxDB é uma excelente escolha para análise de dados de séries temporais porque é mais simples do que qualquer outro. O InfluxDB oferece várias vantagens sobre o MySQL. O MySQL é mais eficiente em termos de memória e mais rápido de desenvolver do que o InfluxDB. A segunda razão pela qual o InfluxDB é uma ferramenta melhor que o MySQL é que ele é mais estável. Além disso, o InfluxDB fornece melhor suporte para análise de séries temporais do que o MySQL. Para análise de séries temporais, o InfluxDB é uma boa escolha porque é simples de usar, eficiente em termos de memória e confiável. Várias empresas, incluindo Cisco, Power Home Remodeling, AT&T e Windstream Communications, já estão usando o InfluxDB.
Os prós e contras dos bancos de dados Nosql e Sql
Os bancos de dados SQL fornecem melhor processamento de transações em várias linhas do que os bancos de dados NoSQL para dados não estruturados, como documentos e JSON. Os bancos de dados SQL também são usados em sistemas legados que foram escritos em um formato relacional. Os dados do InfluxDB são armazenados em um grupo de fragmentos. Os dados são armazenados em um grupo de fragmentos e armazenados com registros de data e hora definidos no histórico como a duração do fragmento e organizados pela política de retenção (RP). Além disso, dependendo do RP, a duração do grupo de fragmentos pode ser ajustada. Você pode alterar a duração do grupo de estilhaços acessando Gerenciamento de política de retenção. O InfluxDB tem muitas diferenças em termos de estrutura e operação em comparação com os bancos de dados SQL. A finalidade do InfluxDB é armazenar dados históricos. Os dados de séries temporais podem ser armazenados em bancos de dados relacionais, mas esses bancos de dados não são otimizados para cargas de trabalho rotineiras de séries temporais. O cliente InfluxDBQL permite consultas SQL de dados do banco de dados.

Que tipo de banco de dados é o Influxdb?
InfluxDB é um banco de dados de série temporal de código aberto sem dependências externas. É útil para monitorar métricas, eventos e analisar análises.
O banco de dados de código aberto InflluxDB é escrito em um formato de série temporal e é mantido pela InfluxData. Essa plataforma, projetada para armazenar e recuperar dados de séries temporais, é usada para monitorar e registrar métricas e análises de desempenho. A arquitetura do banco de dados do InfluxDB consiste em dois bancos de dados: um Time Series Index (TSI) para dados de série e um índice invertido para medição, tag e metadados de campo. InfluxDB, um banco de dados de código aberto, armazena dados em um formato colunar. Além disso, as colunas no armazenamento de dados podem oferecer suporte a consultas de séries temporais comuns, como varreduras ao longo do tempo. A Time-Structured Merge Tree (TSM) é a estrutura organizacional usada pelo InfluxDB. Um FileStore também é usado para gerenciar o acesso a todos os arquivos TSM em um computador.
O InfluxDB é uma solução de armazenamento de dados poderosa, rápida e econômica que pode ser usada para análise e monitoramento de séries temporais. Ele usa a entrega de dados colunar na qual todos os dados são entregues de uma vez, eliminando a necessidade de ler linhas inteiras para extrair valores de dados específicos. Como resultado, o InfluxDB é uma ferramenta útil para dados frequentemente volumosos e densos, como dados de sensores e sistemas. O InfluxDB, como a maioria dos bancos de dados, fornece alta taxa de transferência de leitura e gravação, bem como funcionalidade colunar devido ao uso de sharding e indexação. Este é um recurso útil porque os dados dos sensores ou logs do sistema, que devem ser mantidos e recuperados regularmente, podem ser armazenados e recuperados. O InfluxDB é uma solução de armazenamento de dados poderosa e flexível, adequada para análise e monitoramento de séries temporais. O formato inclui uma matriz colunar que fornece uma coluna de dados por vez, taxas de transferência de leitura e gravação que são duas vezes mais rápidas e recursos de índice que permitem pesquisa e dimensionamento mais rápidos. O InfluxDB é uma excelente escolha para uma ampla gama de requisitos de armazenamento, incluindo dados volumosos de séries temporais , bem como aqueles que exigem uma solução de armazenamento de dados rápida e eficiente.
Influxdb x Mongodb
Os resultados do InfluxDB demonstraram que ele era muito superior ao MongoDB quando se tratava de ingestão de dados e desempenho de armazenamento em disco. Em termos de ingestão de dados, o InfluxDB supera o MongoDB por um fator de quatro. O InfluxDB, em contraste com o MongoDB, ofereceu 20x a compactação.
Depois de passar mais de 4 anos usando o couchbase, mudamos para o MongoDB e não poderíamos estar mais felizes. Recebemos suporte empresarial, mas a experiência foi péssima, apesar de estarmos listados como Couchbase Partner. Para executá-lo corretamente, você precisará de pelo menos seis servidores em seus requisitos mínimos. Seis servidores serão necessários na produção. Uma instância menor do Memcached é enviada com a instância do Couchbase para lidar com o cache na memória. Este programa tem 8 GB de RAM e pode suportar 5000 documentos. Não estou sendo jocoso aqui. Em uma instância do Couchbase, havia menos de 5.000 documentos, menos de 20 índices e mais de 8 GB de RAM.
O banco de dados InfluxDB é uma escolha muito boa para dados de séries temporais. Como resultado, é uma excelente escolha para armazenar dados confidenciais, pois permite ao desenvolvedor controle total sobre a segurança de seus dados. Além disso, o suporte da comunidade do InfluxDB é excelente, facilitando o contato com a organização quando necessário.
Por que o Orientdb é o melhor banco de dados de gráficos
O OrientDB, ao contrário do MongoDB, oferece várias vantagens.
Como o OrientDB não tem esquema, você pode modelar seu modelo de dados com facilidade.
Como o OrientDB é compatível com ACID, seus dados serão consistentes e duráveis.
O desempenho do OrientDB é superior ao do MongoDB, tornando-o uma excelente opção para armazenar dados de séries temporais.
O OrientDB pode ser a melhor opção para você se estiver procurando por um banco de dados gráfico. Quando você dominar o True Graph Engine, não precisará lidar com nenhum outro tipo de dados ou implementar nenhum outro sistema.
Prós Influxdb
Existem muitas razões para amar o InfluxDB. Aqui estão apenas alguns: – Primeiro, o InfluxDB é incrivelmente fácil de instalar e executar. Na verdade, você pode ter uma instância funcionando em apenas alguns minutos com muito pouca configuração. – Em segundo lugar, o InfluxDB tem um excelente desempenho de gravação. Ele pode lidar facilmente com milhões de pontos de dados por segundo sem suar a camisa. – Em terceiro lugar, o InfluxDB tem um modelo de dados muito flexível que pode ser facilmente personalizado para atender às suas necessidades. – Quarto, o InfluxDB possui uma linguagem de consulta avançada que oferece suporte a muitos tipos diferentes de consultas. – Quinto, o InfluxDB se integra bem com muitos tipos diferentes de fontes de dados e aplicativos. No geral, o InfluxDB é uma excelente escolha para dados de séries temporais. É fácil de usar, tem ótimo desempenho e é muito flexível.
InflluxDB é um banco de dados de séries temporais. Para maximizar o desempenho desse caso de uso, é fundamental fazer compensações, principalmente em termos de funcionalidade. Dados com carimbos de data/hora muito recentes constituem a grande maioria das gravações e são adicionados em ordem crescente. Os dados em questão raramente são atualizados e as atualizações controversas são raras. Era difícil para os designers aumentar o desempenho lidando com dados efêmeros e não consecutivos. Um banco de dados com um grande número de leituras e gravações deve ser grande o suficiente para manipulá-lo.
O banco de dados de séries temporais mais poderoso é um serviço que combina o InfluxDB Cloud e um banco de dados de séries temporais. Essa ferramenta gratuita é simples de usar, rápida, sem servidor e elástica, além de oferecer suporte a ferramentas populares como Docker e Prometheus. Devido à popularidade do InfluxDB de código aberto, a empresa cresceu e se tornou uma das empresas mais bem-sucedidas do setor. O ano viu uma expansão dramática do alcance do InfluxData, com mais de 450.000 instâncias ativas do InfluxDB rodando em todo o mundo. Cientistas e engenheiros de dados que precisam de um poderoso banco de dados de série temporal que seja simples e rápido de implantar são candidatos ideais para o InfluxDB Cloud.