
É Spark para Nosql
Publicados: 2023-02-05Spark é uma ferramenta poderosa para trabalhar com dados, especialmente grandes conjuntos de dados. Ele foi projetado para ser rápido e eficiente e oferece suporte a uma variedade de formatos de dados, incluindo bancos de dados NoSQL . Os bancos de dados NoSQL estão se tornando cada vez mais populares, pois são adequados para lidar com grandes quantidades de dados. O Spark pode ajudá-lo a consultar e manipular dados NoSQL com eficiência.
Para trabalhar de forma eficaz, é fundamental gerenciar os bancos de dados do seu aplicativo usando Apache Spark e NoSQL ( Apache Cassandra e MongoDB). O objetivo deste blog é fornecer dicas para desenvolver aplicativos Apache Spark usando back-ends NoSQL. É um parque temático, e o TCP/IP sPark tem passeios em CassandraLand e MongoLand. Quando tentamos consultar os dados do DOE, nosso aplicativo Spark começou a girar fora de seu eixo. A lição aqui é que, quando você consulta o Cassandra, as sequências de teclas são importantes. CassandraLand também oferece a montanha-russa Partitioner, que é uma de suas atrações mais populares. Enquanto os clientes aproveitam o passeio na montanha-russa, os operadores do passeio podem rastrear quem andou na montanha-russa todos os dias, mantendo suas informações.
Na lição um, abordaremos o gerenciamento de conexões do MongoDB. Quando você precisa atualizar informações sobre um parque, como o status de associação do novo parque do Departamento de Energia, pode usar os índices mongo . MongoDB e Spark devem ser usados para garantir que sua conexão seja devidamente gerenciada, assim como índices em casos específicos.
O Apache Spark é um sistema de processamento distribuído popular que é de código aberto e criado para uso em grandes cargas de trabalho de dados. Esse recurso, além do cache na memória e da execução de consulta otimizada, permite consultas analíticas rápidas em grandes quantidades de dados.
Com quase o mesmo código, é mais eficiente e versátil, permitindo processar dados em lote e em tempo real ao mesmo tempo. Como resultado, as ferramentas de Big Data mais antigas estão se tornando cada vez mais obsoletas devido à falta dessa funcionalidade.
Que tipo de banco de dados é o Spark?
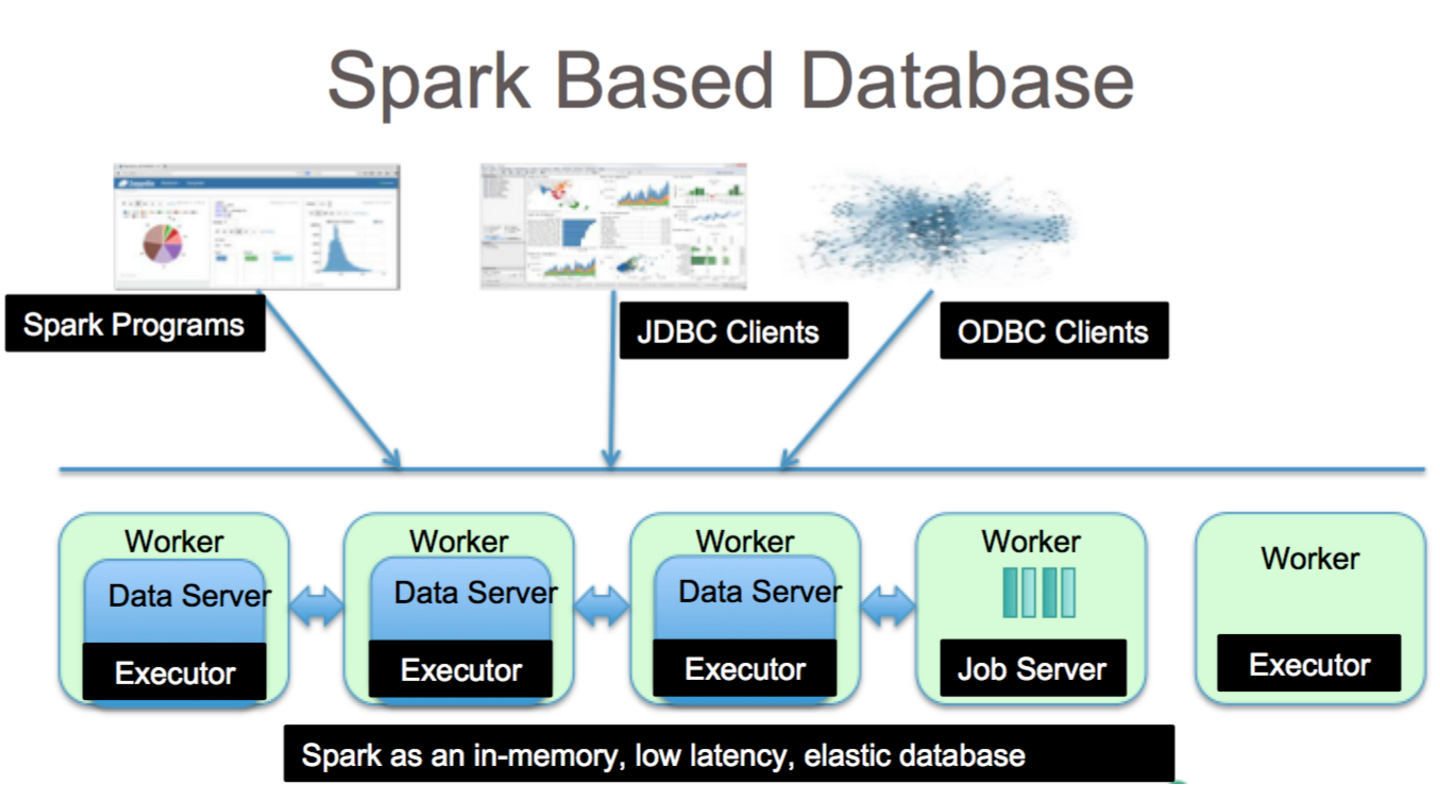
O Apache Spark é uma estrutura de processamento de dados que pode lidar com dados de vários repositórios de dados, incluindo (HDFS), bancos de dados NoSQL e bancos de dados relacionais.
Embora tenha havido vários ciclos de hype para bancos de dados relacionais, eles continuarão a ser populares, independentemente dos avanços mais recentes e da ascensão dos bancos de dados NoSQL. Com o tempo, tornou-se cada vez mais difícil armazenar dados em bancos de dados relacionais. Neste artigo, veremos alguns dos avanços significativos no aproveitamento do poder do banco de dados relacional em escala global. Quando foi lançado pela primeira vez, a interface entre Spark e Big Data Analysis era mínima. Muitas pessoas escreveram muito código para executar esse programa, que era poderoso, mas relativamente lento. Os usuários poderão combinar esses dois modelos no banco de dados Spark SQL com facilidade. Ele também aceita uma ampla variedade de formatos de dados de várias fontes.
O projeto de código aberto Apache Spark é o mais ativo, com centenas de colaboradores contribuindo para ele. Além de ser um projeto de código aberto gratuito, o Spark SQL começou a ganhar popularidade nas principais indústrias. Além do Spark SQL, aproximadamente dois terços dos clientes do Databricks Cloud (o serviço hospedado executando o Spark) usam outras linguagens de programação. Após a conclusão de nosso primeiro estudo de caso, demonstraremos como aplicar databricks ao caso neste estudo de caso prático. Um Spark DataFrame é um conjunto de linhas (tipos de linha) que são distribuídas com o mesmo esquema. Cada coluna no conjunto de dados é rotulada com um nome. A API do DataFrame permite que os desenvolvedores integrem código processual e relacional.

O Spark também pode lidar com funções avançadas, como UDFs. Uma tabela em um banco de dados relacional é semelhante a um dataframe em um banco de dados de dataframe, mas há mais otimizações envolvidas. Eles podem ser manipulados da mesma forma que as coleções distribuídas nativas (RDDs) do Spark. Em geral, a consulta Spark SQL é mais rápida que a consulta Shark e é mais competitiva com o Impulsa. Na Consulta 3a, onde a seletividade da consulta faz com que uma das tabelas fique muito pequena, há uma diferença significativa entre Impala e Impala.
É uma ferramenta fantástica para análise de dados com Spark SQL. A sintaxe HiveQL, Hive SerDes e HiveDFs podem ser acessados por meio da sintaxe HiveQL, bem como Hive SerDes e HiveDFs. Metastores Hive , SerDes e UDFs já foram implementados. Apesar de o Spark ser um banco de dados, ele também é um banco de dados NoSQL. Como resultado, ao criar uma tabela gerenciada no Spark, você poderá usar uma variedade de ferramentas compatíveis com SQL para armazenar seus dados. As expressões SQL podem ser usadas para acessar tabelas no Spark conectando-se ao JDBC por meio de conectores de jdbc.org. Como resultado, você também pode usar ferramentas de terceiros, como Tableau, Talend e Power BI. A capacidade de usar o Spark é ideal para análise de dados e é uma ferramenta útil para uma ampla gama de setores.
Spark SQL: o melhor dos dois mundos
Ele preenche a lacuna entre os dois modelos mencionados anteriormente, os modelos procedimentais e relacionais, incluindo dois componentes principais. Como resultado, você pode executar operações relacionais em larga escala em fontes de dados externas e coleções distribuídas integradas do Spark usando uma API DataFrame.
O que é faísca no banco de dados? É uma estrutura de código aberto que usa aprendizado de máquina, processamento de consulta interativa e cargas de trabalho em tempo real. Esta empresa não possui sistema de armazenamento próprio; em vez disso, ele emprega análises em outros sistemas de armazenamento, como HDFS, Amazon Redshift, Amazon S3, Couchbase e outros, além do seu próprio. Quando se trata de processamento de dados estruturados, o Spark SQL não é apenas um banco de dados; também é um módulo. A grande maioria é escrita em DataFrames, que são as abstrações de programação que funcionam em conjunto com consultas SQL.
Qual é o tipo de SQL sql para “sparksql”? O Hive SQL suporta a sintaxe HiveQL, bem como Hive SerDes e UDFs, permitindo que você acesse armazéns Hive que foram criados anteriormente. Usar metastores Hive, SerDes e UDFs existentes no Spark SQL não é difícil.
O Mongodb pode executar o Spark?
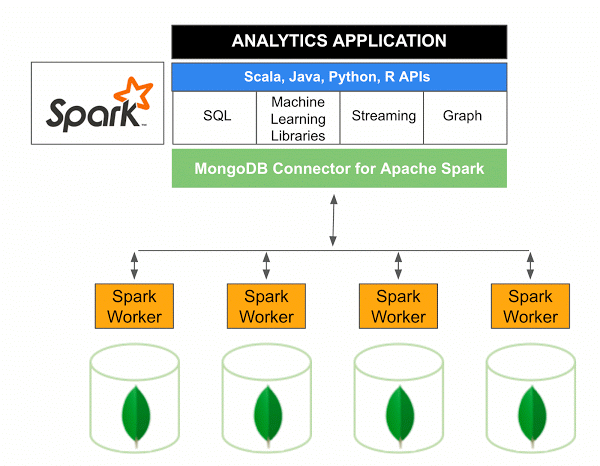
A versão 10.0 do MongoDB Connector for Apache Spark inclui suporte para Spark Structured Streaming por meio da nova API de fontes de dados Spark V2 , bem como a implementação da nova API V2 de fontes de dados Spark.
O conector MongoDB para Spark é um projeto de código aberto que permite gravar dados do MongoDB e lê-los do MongoDB usando Scala. Devido aos métodos utilitários dos conectores, as interações entre Spark e MongoDB são simplificadas, tornando-se uma combinação poderosa para criar aplicativos analíticos sofisticados. Usando seus recursos integrados de replicação e sharding, o Spark pode ser implementado em uma variedade de cargas de trabalho que usam bancos de dados MongoDB .
Spark: a maneira rápida de criar aplicativos ricos em dados
Com a ajuda do Spark, uma ferramenta poderosa, você pode desenvolver rapidamente aplicativos mais funcionais. Ao incorporar o MongoDB, os desenvolvedores podem acelerar o processo de desenvolvimento utilizando uma única tecnologia de banco de dados. Além disso, o Spark é nativo da nuvem e inclui suporte para armazenamentos de dados NoSQL , tornando-o ideal para aplicativos com uso intensivo de dados.