
MapReduce: um modelo de programação para grandes conjuntos de dados
Publicados: 2023-01-08MapReduce é um modelo de programação e uma implementação associada para processar e gerar grandes conjuntos de dados com um algoritmo paralelo distribuído em um cluster.
Estamos transformando a forma como trabalhamos com grandes quantidades de dados usando novas tecnologias. Armazéns de dados, como Hadoop, NoSQL e Spark, são alguns dos players mais proeminentes no campo. DBAs e engenheiros/desenvolvedores de infraestrutura estão entre a nova geração de profissionais especializados em gerenciamento de sistemas com alto nível de sofisticação. Em vez de um banco de dados, o Hadoop é um ecossistema de software que permite a computação paralela na forma de arquivos massivos. Essa tecnologia forneceu benefícios significativos em termos de suporte às necessidades de processamento massivo de big data. Para uma grande transação de dados, o cluster Hadoop médio pode levar apenas três minutos para processar uma grande transação que normalmente levaria 20 horas em um sistema de banco de dados relacional centralizado.
Um cluster mapreduce é um cluster com um algoritmo paralelo e um modelo de programação que processa e gera grandes conjuntos de dados da mesma forma que um cluster normal.
O ecossistema Apache Hadoop foi projetado para oferecer suporte à computação distribuída e fornece um ambiente confiável, escalável e pronto para uso. O módulo MapReduce deste projeto é um modelo de programação usado para processar grandes conjuntos de dados que residem no Hadoop (um sistema de arquivos distribuído).
Este módulo é um componente do ecossistema de software livre Apache Hadoop e é usado para consultar e selecionar dados no Hadoop Distributed File System (HDFS). Os dados podem ser selecionados para uma variedade de consultas usando um algoritmo MapReduce que está disponível para fazer tais seleções.
Usando MapReduce, é possível executar grandes tarefas de processamento de dados. Você pode criar programas MapReduce em qualquer linguagem de programação, incluindo C, Ruby, Java, Python e outras. Esses programas podem ser usados simultaneamente para executar programas MapReduce, tornando-os muito úteis na análise de dados em larga escala.
Para que serve o Mapreduce no Mongodb?
Os mapas no MongoDB são um modelo de programação de processamento de dados que permite aos usuários executar grandes conjuntos de dados e gerar resultados agregados a partir deles. MapReduce é o método usado pelo MongoDB para reduzir mapas. Esta função é dividida em dois componentes: uma função de mapa e uma função de redução.
Usando a ferramenta MapReduce do MongoDB, é possível organizar e agregar grandes conjuntos de dados. Este comando, no MongoDB, faz uso das duas entradas primárias no MongoDB: função de mapa e função de redução, para processar uma grande quantidade de dados. Para definir exemplos, siga as etapas abaixo. Definiremos a função map, a função reduce e os exemplos.
MapReduce comparará strings para classificar a saída usando o método de classificação padrão, independentemente de você estar usando o método padrão ou não. Para alterar a maneira como os dados são classificados, você deve primeiro criar um algoritmo de classificação e, em seguida, implementá-lo usando a classe mapper.
SpiderMonkey é um mecanismo JavaScript amplamente utilizado. É bom para aplicações de pequena escala, mas tem algumas limitações. O SpiderMonkey não possui um algoritmo de classificação, por exemplo. Como resultado, se você quiser usar o Mapmapper para classificar os dados, deverá primeiro criar seu próprio algoritmo de classificação e implementá-lo na classe Reduce.
Apesar de sua popularidade, o SpiderMonkey não usa um algoritmo de classificação. Existem outras limitações para SpiderMonkey, mas esta é notável. O SpiderMonkey, por exemplo, não possui um bom coletor de lixo, portanto, se o seu programa começar a ficar lento, talvez seja necessário tomar algumas medidas para torná-lo mais rápido.
Por que usar uma função Mapreduce?
Uma função MapReduce pode ser útil em várias situações. Este método pode ser usado para processamento de dados em lote em alguns casos. Também é útil se você precisar que uma grande quantidade de dados seja manipulada por um único aplicativo ou processo. Uma função MapReduce também pode ser usada para processar dados espalhados por vários nós em um sistema distribuído. Ao utilizar a função MapReduce, os dados dos nós podem ser combinados em uma única saída. Um aplicativo MapReduce é normalmente usado para processar grandes quantidades de dados, embora possa ser necessário lidar com quantidades muito grandes.
Por que é chamado de Mapreduce?
Existem algumas teorias sobre por que é chamado MapReduce. Uma delas é que é um jogo de palavras, uma vez que os algoritmos de redução de mapa envolvem a divisão de um problema em partes menores (mapeamento), a solução dessas peças e a montagem delas novamente (redução). Outra teoria é que é uma referência a um artigo escrito por funcionários do Google em 2004 chamado “MapReduce: Simplified Data Processing on Large Clusters”. No artigo, os autores usam o termo “mapear” e “reduzir” para descrever as duas fases principais do modelo de processamento proposto.
No entanto, é importante observar que o modelo MapReduce é usado apenas de forma limitada. Não é adequado para grandes conjuntos de dados e deve ser paralelizado para funcionar corretamente. Quando se trata de resolver esses problemas, o Apache Spark tem uma alternativa poderosa ao MapReduce. O sistema de computação em cluster Spark é baseado no Hadoop e funciona como uma plataforma de computação de uso geral. Essa ferramenta pode ser usada para acelerar tarefas tradicionais de análise de dados, como mineração de dados e aprendizado de máquina, bem como tarefas de processamento de dados mais complexas, como armazenamento de dados e análise de big data. Este software é construído usando Erlang, uma linguagem de programação escalável e tolerante a falhas. Ele pode lidar com grandes quantidades de dados e pode ser executado em várias máquinas ao mesmo tempo. Além disso, o Spark emprega paralelismo, permitindo que vários nós executem a mesma tarefa ao mesmo tempo. No geral, tem o potencial de automatizar tarefas de análise de dados em larga escala e torná-las mais escaláveis. Se você precisa paralelizar seu processamento e lidar com grandes conjuntos de dados, é uma excelente alternativa ao MapReduce.
Qual é a diferença entre Mapreduce e agregação?
Ao trabalhar com Big Data, o mapreduce é um método importante para extrair dados de uma grande quantidade de dados. O MongoDB 2.2, a partir de agora, inclui a nova estrutura de agregação. Em termos de funcionalidade, a agregação é semelhante ao mapreduce, mas no papel parece ser mais rápido.
Neste cenário, MongoDB Aggregation e MapReduce são executados em contêineres Docker em uma configuração Sharded. O desempenho do pipeline do agregador é superior ao mapreduce porque permite uma navegação mais rápida e fácil. Veja como o problema funciona: o tweet conta pronomes suecos como “den”, “denne”, “denna”, “det”, “han”, “hon” e “hen” (sensível a maiúsculas e minúsculas) em uma hashtag do Twitter. Quantos identificadores de twitter um usuário tem? Mais de 4 milhões de tweets foram enviados. Nesta experiência, primeiro criaremos um banco de dados MongoDB e habilitaremos a fragmentação. Os streams do Twitter foram importados para o banco de dados e as consultas usando MapReduce e Aggregation Pipeline foram executadas.
Mapreduce: a melhor ferramenta de agregação de dados
Um programa mapReduce lê uma lista de documentos de uma coleção e os processa usando um conjunto de funções predefinidas. A operação mapReduce gera um fluxo de documentos prontos para processar que serão processados no estágio de redução. É possível combinar mapsreduce e agregação em uma variedade de situações. O operador de agregação $group é uma ferramenta que pode ser usada para agrupar documentos em um único campo. Quando vários documentos são mesclados usando o operador de agregação $merge, um novo documento pode ser criado. O operador de agregação $accumulator pode ser usado para representar os resultados de várias operações map-reduce em um único documento.
Mapreduce em Mongodb
Mongodb mapreduce é uma tecnologia de processamento de dados para grandes conjuntos de dados. É uma ferramenta poderosa para analisar dados e fornece uma maneira de processar e agregar dados de maneira paralela e distribuída. O MapReduce tem sido usado extensivamente para análise de dados em vários domínios, incluindo análise de tráfego da Web, análise de log e análise de redes sociais.

Ao usar o comando mapReduce , você pode executar operações de agregação map-reduce em uma coleção. A função map pode converter qualquer documento em zero ou muitos outros. Nas versões do MongoDB que variam de 4.2 a anteriores, cada emissão pode conter apenas metade do tamanho máximo do documento BSON. O código JavaScript obsoleto do tipo BSON usado no MapReduce não é mais suportado e o código não pode mais ser usado para suas funções. O MongoDB 4.4 agora não inclui mais o código JavaScript obsoleto do tipo BSON com escopo (tipo BSON 15). O parâmetro scope especifica quais variáveis podem ser acessadas pela função de redução. Para reduzir as entradas, o MongoDB limita o tamanho do documento BSON à metade de seu tamanho máximo.
Documentos grandes devolvidos ao servidor podem ser devolvidos e, em seguida, mesclados em reduções subsequentes, quebrando potencialmente o requisito. MongoDB 4.2 é a versão mais recente. Esta opção pode ser usada para criar uma nova coleção fragmentada, bem como map-reduce para criar uma nova coleção com o mesmo nome de coleção. A função finalize recebe como argumentos um valor chave e o valor reduzido da função reduce. Existem três opções para configurar o parâmetro out. Essa opção, além de criar uma nova coleção, não funciona em membros secundários de conjuntos de réplicas. NonAtomic: a opção false só pode ser fornecida se a coleção já existente para passar tiver a especificação explícita.
Usando a função de redução em ambos os resultados do documento novo e existente, se a chave no novo documento for a mesma que a chave no documento existente. Um map-reduce não funciona quando o collectionName é uma coleção não armazenada existente que foi configurada. Nesse caso, o MongoDB é impedido de bloquear seu banco de dados se nonAtomic for true. Somente membros secundários de conjuntos de réplicas que usam essa opção podem ficar fora do conjunto. Nenhuma função personalizada é necessária para reescrever a operação map-reduce. O cust_id é usado para calcular o campo de valor do grupo de estágio $group pelo método cust_id. O estágio $merge combina os resultados do estágio $merge na coleção de saída usando os operadores de pipeline de agregação disponíveis.
Por exemplo, o estágio $out pode ser usado para gravar a saída da coleção agg_alternative_1. Cada documento de entrada pode ser processado com a função de mapa. Cada item no pedido está associado a um novo valor de objeto contendo a contagem de 1 e a quantidade do item no pedido. Em reduzidoVal, o campo de contagem representa a soma dos campos de contagem gerados pelos elementos do array. Se a função finalize modificar o objeto reduzidoVal para incluir um campo computado denominado avg, o objeto modificado será retornado ao usuário. O estágio $unwind divide o documento em um documento para cada elemento da matriz usando o campo de matriz de itens. O estágio $project reformula o documento de saída para espelhar a saída do mapreduce incluindo dois campos -id e value.
Ele substitui o documento existente se não houver nenhum documento existente com a mesma chave do novo resultado. Se você especificar o parâmetro out, mapReduce retornará um documento como uma saída no seguinte formato se desejar gravar resultados em uma coleção. Uma matriz de documentos resultantes é retornada se a saída for gravada em linha. Cada documento contém dois campos: o nome do documento de origem e o nome do documento destinatário. Quando o valor da chave é inserido no campo -id, um campo de valor é criado para reduzir ou finalizar os valores da chave.
O que é Emit no Mongodb?
Como uma função map, a função map pode chamar emits (key,value) a qualquer momento para gerar um documento de saída que inclua a chave e o valor. Uma única emissão no MongoDB 4.2 e anterior pode conter apenas metade do tamanho máximo dos arquivos BSON do MongoDB. A partir da versão 4.4 do MongoDB, a restrição foi removida.
Por que o Mongodb é a melhor escolha para dados flexíveis e escaláveis
Devido à falta de um esquema rígido, o MongoDB é frequentemente associado ao NoSQL. Devido à falta de esquema rígido, os dados podem ser armazenados em qualquer formato conveniente para o aplicativo. A flexibilidade do banco de dados oferece uma vantagem importante ao escalá-lo para cima ou para baixo, pois significa que os dados podem ser armazenados de forma personalizada para as necessidades do aplicativo.
Um diagrama de dados com diagramas ER pode ser usado para visualizar as relações entre vários dados. O diagrama ER descreve uma série de nós que representam uma coleção de dados e as conexões entre eles servem como um identificador.
Os relacionamentos não são aplicados no MongoDB porque não é um banco de dados relacional. O diagrama ER descreve os relacionamentos existentes nos dados e também ajuda a visualizá-los.
O MongoDB é uma excelente escolha para dados flexíveis e escaláveis. Sua flexibilidade permite armazenar dados de uma maneira que faça sentido para um aplicativo, e sua escalabilidade permite lidar com grandes conjuntos de dados de maneira rápida e fácil.
Exemplo Mongodb de redução de mapa
No MongoDB, map-reduce é um paradigma de processamento de dados para agregar dados de coleções. É semelhante às funções de mapa e redução na programação funcional.
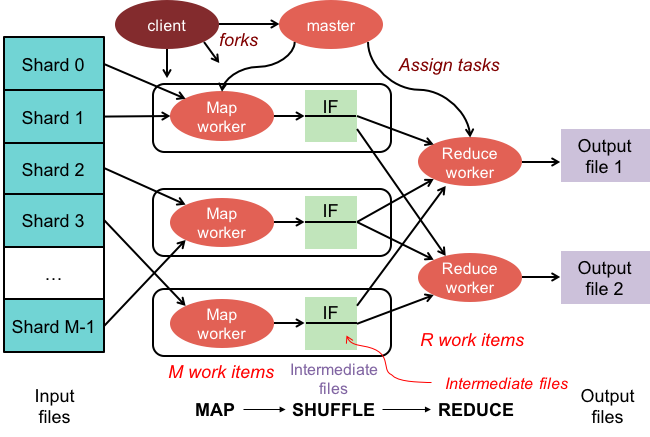
As operações de redução de mapa têm duas fases:
1. A fase de mapeamento aplica uma função de mapeamento a cada documento da coleção. A função de mapeamento emite um ou mais objetos para cada documento de entrada.
2. A fase de redução aplica uma função de redução aos documentos emitidos pela fase de mapa. A função de redução agrega os objetos e produz um único objeto como saída.
Por exemplo, considere uma coleção de artigos. Podemos usar map-reduce para calcular o número de palavras em cada artigo.
Primeiro, definimos uma função de mapeamento que emite um par chave-valor para cada documento, onde a chave é o id do artigo e o valor é o número de palavras do artigo.
Em seguida, definimos uma função de redução que soma os valores de cada chave.
Finalmente, executamos a operação map-reduce na coleção. O resultado é um documento que contém os dados agregados.
Em mongosh, existe um banco de dados. O método mapReduce() é um wrapper em torno do comando mapReduce. Vários exemplos nesta seção, como uma alternativa de pipeline de agregação sem uma expressão de agregação customizada, são fornecidos. Os mapas podem ser traduzidos com expressões personalizadas usando Map-Reduce para exemplos de tradução de pipeline de agregação. A operação map-reduce pode ser alterada sem a necessidade de definir funções customizadas usando os operadores de pipeline de agregação disponíveis. A função map pode ser usada para processar cada documento na entrada. Cada item tem seu próprio valor de objeto associado a um novo valor contendo o número 1, o número da quantidade do pedido e uma lista de itens.
Se a chave no documento atual for a mesma que a chave no novo documento, a operação substituirá esse documento. Você pode reescrever a operação map-reduce usando operadores de pipeline de agregação em vez de definir funções customizadas. O estágio $unwind divide o documento pelo campo de matriz de itens, resultando em um documento para cada elemento da matriz. Quando o estágio $project remodela o documento de saída, a saída map-reduce é espelhada. Uma operação substitui um documento existente que possui a mesma chave do novo resultado.
O que é a função Mapper no Hadoop?
Como redutor, você deve combinar os dados dos mapeadores para gerar uma resposta unificada. A saída de redução é produzida quando um conjunto de saídas de mapa é aceito como entrada, cada uma representando um subconjunto do resultado gerado.
Os mapeadores são usados para dividir os dados em blocos gerenciáveis e, em seguida, atribuir cada bloco a uma tarefa com base em seu tamanho. Os dados de entrada são recebidos pela função mapeadora, onde existem parâmetros que indicam a tarefa a ser executada.
Uma série de itens corresponde aos pedaços de dados que foram mapeados pelo mapeador na saída. Como resultado, a saída do mapa é encaminhada para o redutor, que a converte em uma saída reduzida.
Os erros também são tratados pela função do mapeador. Um mapeador retornará uma saída de erro neste caso, que não é uma saída de mapa. Como o redutor não pode processar esses dados, o mapeador retornará uma mensagem de erro.
Ecossistema Hadoop
O ecossistema Hadoop é uma plataforma para processamento e armazenamento de big data. Ele consiste em vários componentes, cada um com uma função específica a desempenhar no processamento e armazenamento de dados. Os componentes mais importantes do ecossistema são o Hadoop Distributed File System (HDFS), a estrutura MapReduce e a biblioteca Hadoop Common .