
Replicação Master-Slave Vs Multi-Master em bancos de dados NoSQL
Publicados: 2023-01-13Existem muitos tipos diferentes de replicação que são suportados pelos bancos de dados NoSQL. O tipo mais comum de replicação é a replicação mestre- escravo . Nesse tipo de replicação, há um servidor mestre que contém todos os dados. Os servidores escravos então replicam os dados do servidor mestre. Este tipo de replicação é muito simples e fácil de configurar. Também é muito eficiente e oferece bom desempenho. Outro tipo de replicação compatível com bancos de dados NoSQL é a replicação Multi-Master. Nesse tipo de replicação, existem vários servidores mestres. cada servidor mestre tem uma cópia dos dados. Os servidores escravos então replicam os dados de todos os servidores mestres. Esse tipo de replicação é mais complexo de configurar, mas oferece melhor desempenho e é mais tolerante a falhas.
Além da replicação de dados NoSQL, ele fornece um recurso robusto que permite copiar e armazenar seus dados estruturados, não estruturados e semiestruturados em caso de falha do servidor. Descubra como usar bancos de dados NoSQL em um processo passo a passo simples.
Replicação de dados: como os dados são replicados de um servidor para outro, cada bit de dados pode ser encontrado em vários servidores. Um processo de replicação é dividido em dois estágios: replicação mestre-escravo e replicação com reconhecimento de escravo. A replicação mestre-escravo atribui a um nó a autoridade para lidar com gravações, enquanto a replicação com reconhecimento de escravo permite que os escravos leiam e sincronizem com o mestre.
O MySQL inclui replicação assíncrona unidirecional, na qual um servidor atua como fonte e outro serve como réplica.
O Fator de Replicação (RF), como o nome indica, é o número de nós nos quais os dados (linhas e partições) são replicados. Múltiplos nós (RF=N) são conectados para transmitir dados. O RF de um indica que há apenas uma cópia de uma linha em um cluster e não há como recuperar os dados se o nó travar ou for comprometido.
O que é sharding e replicação no Nosql?
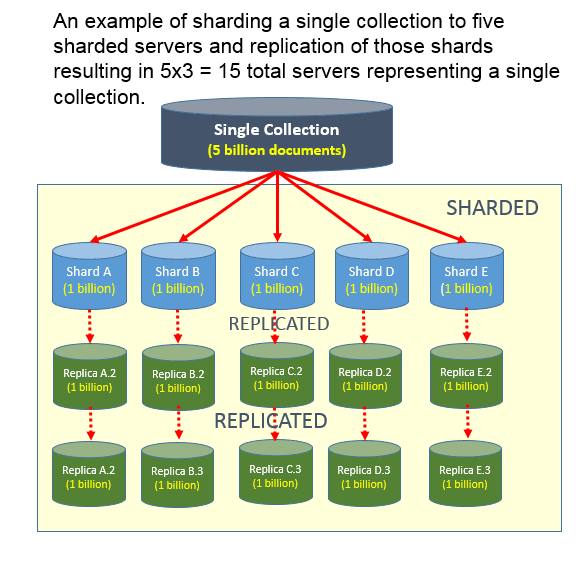
Qual é a diferença entre sharding e replicação? A replicação de dados ocorre quando um nó de servidor primário e um nó de servidor secundário trocam dados. Como backup em caso de falha do servidor principal, isso pode ajudar a aumentar a disponibilidade de dados. A capacidade de dimensionar horizontalmente entre servidores é baseada no uso de uma chave de fragmentação.
Os bancos de dados SQL permitem dividir um conjunto de dados em tabelas e, em seguida, criar uma partição para cada tabela. Um banco de dados NoSQL , como o MongoDB, não possui tabelas, mas sim uma coleção de documentos. O comando mongo shard é usado para fragmentar coleções do MongoDB. Você pode distribuir a carga entre vários servidores em um único ambiente de sharding, resultando em melhor desempenho. Quando se trata de grandes conjuntos de dados, isso é especialmente verdadeiro. Além disso, o sharding pode ajudar a gerenciar e proteger grandes conjuntos de dados, fornecendo integridade de dados. Além de dimensionar seus dados, o Sharding é uma ferramenta fantástica para gerenciá-los com eficiência. Esse padrão é amplamente utilizado em bancos de dados NoSQL devido à sua facilidade de implementação e amplo suporte.
Por que a fragmentação é melhor para gravações de dados
Em geral, a replicação permite o escalonamento horizontal de leituras, mas não permite o escalonamento de dados em vários servidores com uma única chave, ao contrário do sharding.
Que tipo de dados é suportado pelo Nosql?
Os bancos de dados NoSQL são cada vez mais populares porque suportam uma ampla gama de tipos de dados. Isso inclui tipos de dados tradicionais, como números e strings, bem como tipos de dados mais recentes, como JSON e XML. Os bancos de dados NoSQL também oferecem suporte a uma ampla variedade de linguagens de programação, tornando-os uma boa opção para empresas que usam vários idiomas.
Em um banco de dados NoSQL, existem quatro tipos: pares chave-valor, colunas, gráficos e documentos. Cada categoria tem seu próprio conjunto de características e limitações. O banco de dados MongoDB é um banco de dados NoSQL popular . Este é um banco de dados de par chave-valor que armazena ambos os pares. Este aplicativo é simples de usar, escalável e rápido. Bancos de dados orientados a documentos são o foco do CouchDB. Este aplicativo é simples de usar e flexível o suficiente para acomodar vários usuários. O banco de dados CouchBase é orientado a colunas e se concentra em transações. O banco de dados do Cassandra é baseado em uma arquitetura altamente orientada a colunas. O sistema de armazenamento HBase é uma solução de armazenamento escalonável, distribuída e em escala de petabytes para grandes conjuntos de dados. É um banco de dados de memória distribuída que roda no Redis. Usando o Riak como um armazenamento de dados, você pode criar um sistema de alto desempenho de código aberto. O Neo4J, como um banco de dados gráfico, é construído em uma plataforma Java.
Por que o Nosql é a melhor escolha para empresas que precisam escalar rapidamente
Para negócios que precisam escalar rapidamente, o NoSQL é uma boa escolha porque tem uma arquitetura mais flexível e pode ser escalado horizontalmente. Além disso, os bancos de dados NoSQL não são tão sensíveis a alterações de esquema quanto os bancos de dados relacionais tradicionais.
A replicação de dados Nosql é
A replicação de dados Nosql é um processo de cópia de dados de um banco de dados nosql para outro banco de dados nosql. Isso é feito para manter os dados seguros e garantir que estejam sempre disponíveis em caso de falha.
Nosql Vs. Rdbms: qual é melhor para desempenho?
Há um crescente corpo de pesquisa que mostra que os bancos de dados NoSQL, como o MongoDB, superam os RDBMSs tradicionais. A tecnologia permite que os dados sejam fragmentados e replicados, tornando-os ideais para aplicativos que exigem alto rendimento e acesso rápido aos dados. Embora os dados às vezes possam ser replicados, nem sempre é possível.
Replicação mestre-escravo em Nosql
A replicação mestre-escravo é um tipo de replicação em que os dados são copiados de um servidor primário (“mestre”) para um ou mais servidores secundários (“escravos”). Os servidores escravos podem ser usados para operações de leitura, mas todas as operações de gravação devem ser enviadas para o mestre. Esse tipo de replicação é frequentemente usado em bancos de dados Nosql, pois pode fornecer alta disponibilidade e escalabilidade. Por exemplo, se o servidor mestre cair, os escravos ainda poderão ser usados para atender às solicitações de leitura. E, se for necessária mais capacidade de leitura, podem ser adicionados servidores escravos adicionais.
Os desafios da replicação mestre-escravo
Pode ser difícil manter dados em todos os nós escravos no modelo de replicação mestre-escravo. Se um dos nós escravos ficar inativo, os dados desse nó escravo serão perdidos.
Qual modelo de replicação suporta operações de leitura e gravação de banco de dados em todos os nós?
O modelo de replicação que suporta as operações de leitura e gravação do banco de dados em todos os nós é o modelo de replicação mestre -mestre. Esse modelo permite que cada nó atue como um mestre, o que significa que cada nó pode ler e gravar no banco de dados. Isso é benéfico para organizações que precisam ter alta disponibilidade e redundância, pois todos os nós podem continuar operando mesmo se um nó ficar inativo.

Qual modelo de aplicativo suporta operações de leitura e gravação de banco de dados em todas as notas?
Os RDBMSs geralmente usam um modelo de esquema na gravação, no qual uma estrutura de dados é definida antecipadamente e todas as operações de leitura e gravação dependem dessa estrutura.
Alterações e atualizações do banco de dados podem ocorrer no modo de leitura e gravação
Alterações e atualizações podem ocorrer no modo de leitura/gravação quando o banco de dados é aberto no modo de leitura/gravação, que é controlado por OpenReadWrite() ou OpenWrite. DatabaseReader é uma classe que pode ser usada para ler e gravar dados em um banco de dados. Os dados podem ser gravados em um banco de dados usando o objeto DatabaseWriter.
Que tipo de banco de dados oferece suporte a nós conectados por relacionamentos?
Os relacionamentos podem ser armazenados e acessados em bancos de dados de gráficos usando relacionamentos estruturados. Os relacionamentos são os aspectos mais valiosos dos bancos de dados de gráficos porque são alguns dos cidadãos mais valiosos. Os nós são usados em bancos de dados grafos para armazenar entidades de dados e as arestas são usadas para conectar entidades.
Mongodb e Node.js: o emparelhamento perfeito para trabalhar com gráficos em Javascript
Se você quiser usar gráficos em JavaScript, você deve usar o MongoDB. MongoDB é o banco de dados NoSQL mais popular, enquanto Node.js também é uma linguagem de programação JavaScript popular.
Como funciona a replicação de banco de dados não relacional?
Em uma instância Peer-to-Peer NoSQL Data Replication , os dados são replicados de um banco de dados para outro com base no conceito de que cada cópia deve manter sua própria cópia atualizada. A única vez que isso pode funcionar é se cada cópia do esquema armazenar o mesmo tipo de dados no mesmo formato. O outro aspecto crítico desse método de replicação de dados é a restauração do banco de dados.
Os diferentes tipos de replicação
*br *Replicação de armazenamento *br É um tipo de replicação que armazena alterações de dados de maneira consistente. Um servidor de réplica de origem cria um instantâneo do banco de dados com informações do estado atual depois de criar um. Em seguida, o instantâneo é enviado ao servidor de réplica de destino. Após o instantâneo, o servidor de réplica de destino constrói uma nova cópia do banco de dados. Fazendo referência à replicação transacional em dados As transações são armazenadas em dados que mudam com frequência e podem ser replicadas usando a replicação transacional. Uma transação é agrupada e replicada em um único lote. As alterações nos dados são replicadas por um processo conhecido como replicação. A replicação ponto a ponto pode ser realizada por meio do uso de servidores. A replicação de dados ponto a ponto é um tipo de replicação de dados que se destina a replicar dados que não são alterados com frequência. Na replicação de dados ponto a ponto, um cluster de nós replica os dados. Cada nó em um cluster tem seu próprio modelo de dados. Os nós do cluster não se conhecem.
Replicação de banco de dados de documentos Nosql
Os bancos de dados de documentos Nosql são projetados para fornecer alta disponibilidade e escalabilidade, replicando dados em vários servidores. Isso permite que o banco de dados continue operando mesmo se um ou mais servidores falharem.
Grande banco de dados Nosql
Não há uma resposta definitiva para essa pergunta, pois depende das necessidades específicas do usuário. No entanto, alguns dos grandes bancos de dados nosql mais populares incluem MongoDB, Cassandra e Hadoop. Esses bancos de dados são todos projetados para fornecer escalabilidade e alto desempenho, tornando-os ideais para processamento de dados em larga escala.
Um banco de dados NoSQL como o MongoDB, por exemplo, é ideal para big data porque pode lidar com grandes quantidades de dados de forma rápida e fácil. Como o MongoDB é um MongoDB orientado a documentos, ele pode lidar com enormes quantidades de dados. Em outras palavras, o MongoDB pode lidar com dados em vários formatos, incluindo JSON, BSON e JavaScript Object Notation (JSON). Também torna os dados simples de acessar e armazenar. Além disso, o MongoDB é escalável, o que significa que pode processar grandes quantidades de dados.
Qual banco de dados Nosql é melhor para Big Data?
Eles criam os formatos que as ferramentas analíticas podem usar para converter dados não estruturados e semiestruturados em formatos que podem ser usados em seus aplicativos. Os requisitos exclusivos para armazenar big data tornam os bancos de dados NoSQL (não relacionais), como o MongoDB, uma excelente escolha.
Por que o Mongodb é a melhor escolha para armazenar Big Data
O MongoDB é uma excelente opção para armazenar e gerenciar grandes quantidades de dados. As operações CRUD (criar, ler, atualizar, excluir), a estrutura de agregação, a pesquisa de texto e o recurso Map-Reduce tornam simples para os usuários acessar, manipular e analisar os dados.
Big Data é Nosql?
Se suas cargas de trabalho de dados estiverem mais focadas no processamento e análise rápidos de grandes volumes de dados variados e não estruturados, como Big Data, o NoSQL é uma escolha melhor. Os bancos de dados NoSQL não têm as mesmas restrições de tipos de dados que os bancos de dados relacionais.
Por que os bancos de dados Nosql são o futuro do gerenciamento de dados
O banco de dados NoSQL está se tornando cada vez mais popular como resultado de suas vantagens significativas de desempenho em relação aos bancos de dados relacionais tradicionais. É um ativador de banco de dados NoSQL que habilita certos tipos de bancos de dados NoSQL, como HBase, permitindo que os dados sejam distribuídos por milhares de servidores sem reduzir o desempenho. A plataforma de nuvem do Google (GCP) fornece um conjunto diversificado de serviços de banco de dados, que são únicos em sua capacidade de processar conjuntos de dados muito grandes e dinâmicos sem a necessidade de um esquema.
As grandes empresas usam Nosql?
Tecnologia de banco de dados baseada em Cloud Computing, Web, Big Data e Big Users. Ao oferecer o NoSQL como uma alternativa ao RDBMS tradicional, o NoSQL tornou-se uma opção viável para muitas empresas populares da Internet, como LinkedIn, Google, Amazon e Facebook.
O Nosql é o futuro para os bancos de dados de back-end do Instagram?
Neste ponto, o Instagram parece preferir o PostgreSQL como seu banco de dados principal como back-end principal, embora isso possa mudar. Cassandra, um popular banco de dados NoSQL, pode ou não ser o mais adequado para o Instagram. O Cassandra é uma ferramenta excelente para armazenar grandes quantidades de dados, mas tem um histórico ruim de desempenho.
No momento, é difícil prever se o Instagram usará ou não bancos de dados NoSQL como seu principal banco de dados de back-end. PostgreSQL e Cassandra são excelentes opções, mas não podem competir com o SQL em termos de desempenho.