
Benefícios do banco de dados NoSQL
Publicados: 2022-11-22Os bancos de dados NoSQL são bancos de dados não relacionais que permitem uma maneira mais flexível de armazenar dados. Isso significa que os dados podem ser armazenados de várias maneiras diferentes, inclusive como pares chave-valor, orientados a documentos ou orientados a colunas. Os bancos de dados NoSQL são frequentemente usados para armazenamento de dados em grande escala, pois são mais escaláveis e podem lidar com uma quantidade maior de dados do que os bancos de dados relacionais tradicionais.
Fundamentalmente, o NoSQL permite o armazenamento rápido de grandes quantidades de dados não relacionados. Um banco de dados NoSQL é essencialmente incapaz de armazenar qualquer dado relacional. Durante a década de 1970, o uso de bancos de dados relacionais tornou-se o padrão para armazenamento de dados. De acordo com Ben Finkel, instrutor de CBT, o NoSQL valoriza velocidade e flexibilidade em vez de consistência e eficiência. Construtores de banco de dados e engenheiros de manutenção devem ser altamente qualificados para construir e manter bancos de dados relacionais que sejam rápidos e eficientes. Um banco de dados NoSQL não requer a criação ou planejamento de um banco de dados. Como resultado, os desenvolvedores podem criar, prototipar e implantar aplicativos com muito mais rapidez.
Além disso, eles são semelhantes ao desenvolvimento ágil, que é mais popular hoje em dia. Não é necessário alterar os bancos de dados NoSQL e eles podem armazenar uma ampla variedade de tipos de dados. O número de bytes em um banco de dados NoSQL é maior que o número em um banco de dados relacional . O Raspberry Pi pode executar um banco de dados NoSQL, mas terá muito mais dificuldade em lidar com a carga de um servidor web. Os gráficos são muito diferentes dos pares chave:valor e documentos. Nós e arestas são as duas partes de um grafo. Os nós contêm informações sobre um objeto (pessoa, lugar, coisa, ideia, etc…), que podem ser usadas por outros nós. As relações de vizinho mais próximo são explicadas por relacionamentos de aresta. Usamos um modelo de dados de coluna larga porque ele se parece com as linhas e colunas que veríamos em um banco de dados relacional.
Ao contrário dos bancos de dados relacionais, que contêm linhas e colunas, os bancos de dados NoSQL são compostos de documentos JSON. Responderemos rapidamente: NoSQL significa simplesmente “não apenas SQL” em vez de “nada de SQL”.
O que é linha em Nosql?
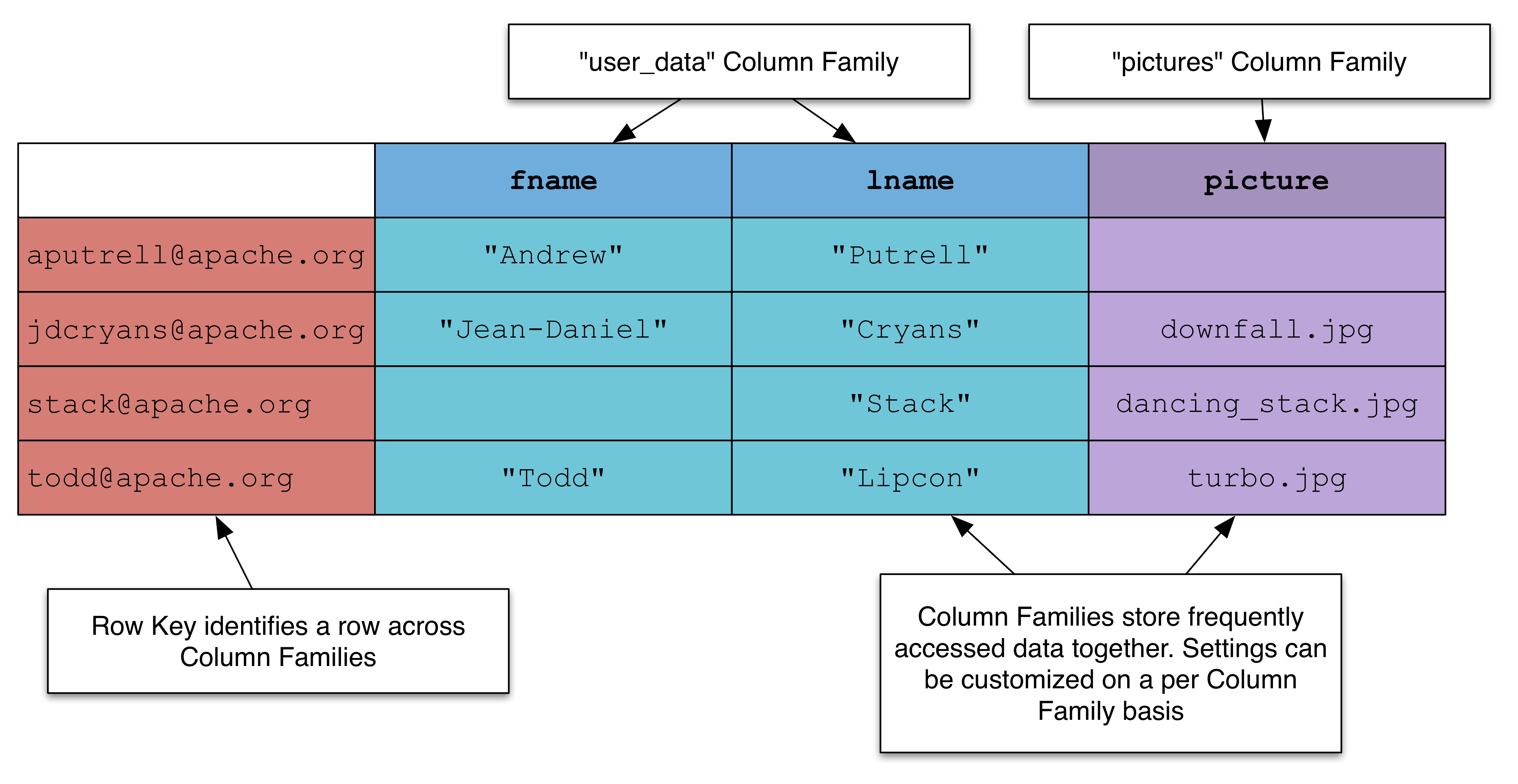
Não há uma resposta definitiva para essa pergunta, pois o termo “linha” pode significar coisas diferentes para pessoas diferentes quando se trata de trabalhar com bancos de dados NoSQL. Em geral, no entanto, uma linha é simplesmente um registro em um banco de dados NoSQL composto por um ou mais pares chave-valor. Cada chave em uma linha corresponde a um atributo específico dos dados armazenados e o valor são os dados reais associados a esse atributo.
As linhas da tabela, em contraste com os registros do esquema da tabela, possuem propriedades adicionais que as tornam valores de registro. Essas propriedades devem ser avaliadas usando as funções listadas nesta seção. A função modify_time exibe a hora de modificação mais recente (em UTC) de cada linha. O tempo de inserção é retornado se a linha nunca foi modificada desde sua inserção. Você pode usar a função de partição para ver o ID da partição na qual a(s) linha(s) de dados está(ão) armazenada(s). Se esta função for usada, você poderá identificar potenciais pontos de acesso de armazenamento ou um desequilíbrio em seu banco de dados Oracle NoSQL. A função row_storage_size retorna a capacidade de armazenamento (em bytes) da linha de dados fornecida.
Armazenamentos de colunas largas, como bancos de dados relacionais, oferecem algumas vantagens distintas. Os armazenamentos de colunas largas têm vantagens além de sua capacidade de dimensionamento horizontal, o que significa que eles podem lidar com um grande número de documentos sem enfrentar problemas de desempenho causados por altos níveis de simultaneidade. Lojas de colunas largas também são capazes de adaptabilidade. Essas tecnologias podem ser usadas em uma variedade de aplicativos, incluindo aplicativos da Web, data warehouses e mecanismos de pesquisa. Armazenamentos de colunas largas podem não ser apropriados para aplicações que requerem desempenho excepcional.
Linhas em Mysql Vs Mongodb
No MySQL, você cria uma linha de tabela atribuindo um valor a uma coluna na tabela. Uma matriz contém um registro de todas as linhas da tabela, que inclui propriedades da tabela, como valores de coluna.
Uma linha é um registro em uma tabela, que é um tipo de banco de dados. Os dados contidos em uma linha são organizados da mesma forma, portanto, é um registro completo de informações de itens específicos. Às vezes, uma linha é chamada de tupla, mas não o tempo todo.
No MongoDB, as linhas não precisam ser assinadas pelo esquema antes de serem exibidas. Você pode simplesmente inserir campos sempre que quiser. O MongoDB inclui um modelo de dados que permite representar relacionamentos hierárquicos, armazenar matrizes e lidar com estruturas mais complexas.
Uma linha de colunas é criada no MongoDB quando você adiciona um valor a um campo na tabela. Em geral, uma linha é um registro de todos os dados da tabela, incluindo os valores dos campos da tabela e quaisquer outras propriedades que tenham sido definidas.
É um banco de dados Nosql onde os dados são armazenados por coluna em vez de linhas?
Este é o tipo de descrição que eu gostaria de usar. O objetivo de bancos de dados NoSQL como esses é permitir que os usuários executem consultas complexas e analisem dados de maneira altamente eficiente. Bancos de dados colunares , ao contrário de bancos de dados relacionais, usam colunas para armazenar dados. Essas colunas são usadas para formar um subgrupo de colunas.
O banco de dados de código aberto MongoDB é conhecido por sua velocidade, escalabilidade e facilidade de uso, e é um dos bancos de dados mais populares. Como não é um produto empacotado, você mesmo precisará instalá-lo e gerenciá-lo, em vez de comprá-lo de um fornecedor como Oracle ou Microsoft SQL Server.
Um dos principais recursos do MongoDB é sua capacidade de integração com outros softwares.
O banco de dados MongoDB contém todos os seus registros como documentos, o que significa que você não precisa se preocupar com estruturas de linha ou coluna.
Por causa de sua representação BSON de dados, o MongoDB é um banco de dados rápido.
MongoDB suporta grandes conjuntos de dados, bem como processamento em lote.
Instale e gerencie o MongoDB: a facilidade de uso do MongoDB o torna uma escolha popular para desenvolvedores.
Todos os bancos de dados Nosql são colunas?
Alguns bancos de dados NoSQL são bancos de dados orientados a colunas, enquanto outros são bancos de dados orientados a SQL. Tanto as linhas quanto as colunas podem conter detalhes de implementação de armazenamento físico para um banco de dados relacional ou não relacional.
Como o banco de dados de valor-chave Nosql armazena dados?
Os bancos de dados NoSQL têm um dos armazenamentos de valor-chave menos complexos. É exatamente isso que torna esse modelo tão atraente. O programa possui funções muito simples para armazenar, recuperar e remover dados. É importante observar que os bancos de dados de armazenamento de valor -chave não possuem uma linguagem de consulta.
O objetivo deste artigo é aprender sobre o armazenamento de chave-valor do NoSQL. Um banco de dados NoSQL é um banco de dados não SQL ou não relacional que serve como um mecanismo para armazenar e recuperar dados. O design do banco de dados, o dimensionamento horizontal e o controle do usuário sobre a disponibilidade são recursos importantes em um banco de dados NoSQL. Um banco de dados de valor-chave é um tipo de banco de dados NoSQL que emprega o método de valor-chave. As chaves, que podem representar uma variedade de objetos, como strings ou até mesmo um tipo específico de valor, são chamadas de identificadores exclusivos. Os nomes das chaves, por exemplo, podem ser simples como números ou complexos como descrições dos valores.
Quando velocidade, escalabilidade e facilidade de uso são aspectos críticos de um aplicativo, um banco de dados chave-valor é o ideal. Um banco de dados de valor-chave é adequado para armazenar pequenas quantidades de dados, como uma lista de clientes, ou para armazenar dados que não requerem manipulação ou consulta. Um banco de dados chave-valor é classificado em várias categorias, incluindo Berkeley DB, HBase, MongoDB e Redis. Cada um vem com seu próprio conjunto de recursos e pode ser usado de várias maneiras. É fundamental considerar cada um deles minuciosamente para determinar qual é o mais adequado para o seu projeto. Um banco de dados de valor-chave pode ser usado para armazenar dados que não precisam ser consultados ou manipulados da maneira tradicional. Um banco de dados de valor-chave, por exemplo, pode ser usado para armazenar pequenas quantidades de dados, como uma lista de clientes, ou para armazenar dados que não requerem manipulação ou consulta de maneiras tradicionais. O banco de dados de valor-chave também fornece um alto nível de escalabilidade e velocidade. A função principal de um banco de dados de valor-chave é um array associativo, permitindo que ele lide com um grande número de dados em um curto período de tempo. Além disso, como os valores são associados apenas a chaves, os bancos de dados de valor-chave não dependem tanto de índices quanto os bancos de dados relacionais tradicionais. É possível para eles processar grandes quantidades de dados mais rapidamente do que era possível anteriormente. Uma desvantagem dos bancos de dados de valor-chave é que eles não podem lidar muito bem com dados complexos. A matriz associativa é uma estrutura de banco de dados básica e não é tão sofisticada quanto um banco de dados relacional mais tradicional . Como resultado, os bancos de dados de valor-chave são incapazes de lidar com grandes quantidades de dados que precisam ser organizados de maneira mais sofisticada. Para atender às necessidades de aplicativos com alta velocidade, escalabilidade e facilidade de manutenção, os bancos de dados chave-valor são uma excelente escolha. Eles são ideais para armazenar pequenas quantidades de dados, para lidar com dados que não precisam ser manipulados ou consultados de maneira tradicional e para processar grandes quantidades de dados de forma rápida e eficiente.

Os prós e os contras de usar um banco de dados de valor-chave
A função de coleção do MongoDB é uma coleção de documentos que compartilham o mesmo tipo de valor de campo. Uma coleção pode conter uma variedade de documentos e cada documento possui seu próprio ID de coleção. O controle de versão do documento também está disponível para o MongoDB, o que permite acompanhar as alterações em documentos individuais dentro de uma coleção do MongoDB. O MongoDB atualiza os valores de campo de uma coleção e também atualiza o número da versão do documento e salva um carimbo de data/hora no processo. Como é o uso de bancos de dados chave-valor? Quais são os benefícios? Ter um banco de dados chave-valor é simples de configurar, o que é uma de suas vantagens. Você não precisa criar nenhuma tabela ou índice no MongoDB apenas para começar. Além disso, usar um banco de dados chave-valor pode ser extremamente eficiente. Como o MongoDB armazena dados em uma série de pares chave-valor, você pode recuperar um valor digitando a chave na caixa de pesquisa. Quais são as desvantagens de usar um banco de dados chave-valor? Os dados são difíceis de manter com um banco de dados chave-valor. Se quiser adicionar um novo campo a um documento da coleção, você precisará atualizar manualmente todos os documentos da lista. Além disso, um banco de dados de valor-chave está sujeito a problemas de dimensionamento porque é difícil dimensionar horizontalmente. Como o MongoDB armazena dados em um conjunto de pares chave-valor, é necessária a adição de mais servidores se você quiser oferecer suporte a mais usuários.
O que é Nosql e como os documentos são armazenados?
Bancos de dados de documentos são considerados bancos de dados NoSQL em geral e não são classificados como tal. Documentos flexíveis, em vez de linhas e colunas fixas, são usados para armazenar dados em bancos de dados de documentos. Os bancos de dados de documentos são mais populares do que os bancos de dados tabulares e relacionais.
Bancos de dados orientados a documentos (também conhecidos como bancos de dados agregados, bancos de dados de documentos ou armazenamentos de documentos) armazenam registros individuais, bem como suas informações associadas em documentos únicos. Os armazenamentos de documentos são um subconjunto do guarda-chuva NoSQL e são sistemas populares de gerenciamento de banco de dados que usam modelos 'não relacionais'. DocumentDB é um dos sistemas de armazenamento de documentos mais populares, junto com MongoDB, CouchDB, OrientDB e DocumentDB. Os bancos de dados de documentos não dependem de esquemas de tabela de forma alguma. Cada entidade está alojada em um único documento e os dados associativos podem ser encontrados nesse documento. Com esse método, os dados podem variar, a integração e a modelagem podem ser aprimoradas e os relacionamentos agudos entre as entidades podem ser reforçados com mais eficiência. Os armazenamentos de documentos dependem fortemente de armazenamentos de valor-chave, que são mais do que capazes de criar essas regras de imposição por conta própria. Os bancos de dados de documentos precisam de mais documentação antes de serem removidos de comunidades e fóruns de nicho.
Armazenamentos orientados a banco de dados: No banco de dados, cada tabela contém um conjunto de colunas. Cada coluna pode conter uma variedade de informações. MongoDB, Cloudant e HBase são apenas algumas das lojas orientadas a colunas no mercado. Este grupo é composto por aplicativos de código aberto baseados no documento MapReduce do Google. Armazenamentos de documentos são bancos de dados que armazenam todos os dados pertencentes a um documento. Um documento, em essência, contém apenas conjuntos de valores-chave. Os armazenamentos de documentos são um tipo de armazenamento para documentos, como Nimble e CouchDB. Ambos os programas são de código aberto e baseados no documento Apache CouchDB. Bancos de dados gráficos são bancos de dados que usam gráficos para armazenar dados. Um grafo é formado por nós e arestas conectados. Existem arestas em ambos os nós e arestas que representam as relações entre eles. Bancos de dados gráficos como Redis e Neo4j são exemplos de como construir um. Esses aplicativos são de código aberto e feitos com o Facebook Graph Paper.
Bancos de dados Nosql: a nova onda de gerenciamento de dados
Uma variedade de fatores está levando os bancos de dados NoSQL a se tornarem mais populares. Eles são menos complicados de usar e mais flexíveis do que os bancos de dados tradicionais . Além disso, eles podem lidar com uma gama mais ampla de dados do que os bancos de dados relacionais.
Lista de bancos de dados Nosql
Existem muitos tipos de bancos de dados NoSQL, cada um com seus próprios pontos fortes e fracos. Os bancos de dados NoSQL mais populares são MongoDB, Apache Cassandra, Redis e Amazon DynamoDB.
Um banco de dados NoSQL é um banco de dados que pode capturar e processar grandes quantidades de dados, em vez de um banco de dados tradicional que não inclui SQL. Um banco de dados NoSQL pode ter vários tipos, cada um dos quais emprega uma abordagem única para modelagem de dados e pode ou não ser usado no mesmo contexto. Os tipos de bancos de dados mais comumente usados incluem valores-chave, baseados em documentos, baseados em gráficos e em colunas largas. A grade de dados, que é uma rede de sistemas que armazena dados na nuvem, é o que compõe os bancos de dados e grades. Os modelos de banco de dados são uma coleção de recursos que são compartilhados por dois ou mais modelos de banco de dados. Para bancos de dados NoSQL em 2021, a tabela abaixo é dividida em seções com base no tipo. O banco de dados gráfico de código aberto Neo4J é baseado em Java e vem com recursos adicionais que estão disponíveis como parte da Graph Data Platform.
RedisGraph, um módulo de banco de dados gráfico para Redis, converte consultas em expressões de álgebra linear usando a linguagem de consulta Cypher. Outra solução baseada em Hadoop é o Accumulo, baseado no Bigtable do Google. ObjectDB, Infinispan, Hazelcast e ArangoDB são apenas alguns dos bancos de dados NoSQL disponíveis no mercado. Embora esta seja uma lista, existem inúmeras outras opções disponíveis para você. Sua solução de banco de dados provavelmente será mais adequada às suas necessidades usando essas listas.
Por que o Mongodb é o banco de dados Nosql mais popular
O MongoDB é o banco de dados NoSQL mais usado, de acordo com o site database-engines.com. Além do MySQL, Cassandra e DynamoDB, os bancos de dados NoSQL surgiram como uma alternativa popular aos bancos de dados relacionais.
Exemplos de bancos de dados Nosql
Existem muitos bancos de dados NoSQL disponíveis hoje, cada um com suas próprias vantagens e desvantagens. Alguns dos bancos de dados NoSQL mais populares incluem MongoDB, Cassandra e Redis. O MongoDB é um poderoso banco de dados orientado a documentos, perfeito para aplicativos que exigem alto desempenho e escalabilidade. O Cassandra é um banco de dados orientado a colunas altamente escalável, perfeito para aplicativos que exigem alta disponibilidade. O Redis é um armazenamento de valor-chave na memória que é perfeito para aplicativos que exigem acesso a dados extremamente rápido.
Bancos de dados não relacionais, como bancos de dados NoSQL, armazenam dados em um formato diferente daquele usado por bancos de dados relacionais. Não há necessidade de usar um esquema fixo, as funções de junção são evitadas e o NoSQL escala facilmente. O objetivo principal dos bancos de dados NoSQL é atender a armazenamentos de dados distribuídos com enormes requisitos de armazenamento. Empresas como Twitter, Facebook e Google estão coletando terabytes de informações de usuários por dia. Os bancos de dados NoSQL são distribuídos, o que significa que não há uma única unidade de controle ou armazenamento dentro deles. Como resultado, não há necessidade de implantação ou gerenciamento de diferentes bancos de dados para os mesmos dados. A vantagem de usar um banco de dados distribuído é que ele armazena os dados em um estado contínuo, garantindo que eles estejam sempre disponíveis.
Tudo em um armazenamento de valor-chave é uma chave e também um valor. As Column Family Stores são o local ideal para armazenar e processar grandes quantidades de dados distribuídos por uma ampla gama de máquinas. Os bancos de dados de documentos, em geral, contêm versões de coleções de valores-chave usadas anteriormente. Os documentos em formato semiestruturado são armazenados em arquivos JSON. SQL e outras linguagens de consulta declarativas não são usadas em bancos de dados gráficos. Esses bancos de dados podem ser acessados usando apenas modelos de dados, não bancos de dados. As interfaces RESTful são possíveis em várias plataformas NoSQL .
Por ser um banco de dados multi-relacional, é mais semelhante a um banco de dados relacional do que a um banco de dados gráfico. Os bancos de dados gráficos podem processar vários tipos de dados no mesmo banco de dados enquanto usam um único back-end. Os bancos de dados multimodelos são um novo tipo de banco de dados NoSQL que ganhará popularidade no futuro. As classificações dos bancos de dados mais populares e seu progresso podem ser encontradas em http://db-engines.com/en/rankings.html.
A Amazon é Nosql ou SQL?
SQL é a linguagem de programação preferida para o desenvolvimento de aplicativos orientados a banco de dados, e há várias ferramentas disponíveis para auxiliar nesse processo. Você pode executar tarefas ad hoc do DynamoDB usando o Console de gerenciamento da AWS, a AWS CLI ou o NoSQL WorkBench .