
Banco de dados NoSQL: Impala
Publicados: 2023-03-03NoSQL é um termo usado para descrever um banco de dados que não usa a estrutura de banco de dados relacional tradicional. Em vez disso, os bancos de dados NoSQL geralmente são projetados para fornecer uma solução mais simples e escalável.
O Impala é um banco de dados NoSQL projetado para fornecer uma solução rápida e escalável para o gerenciamento de grandes conjuntos de dados. O Impala é baseado no modelo de dados do Google Bigtable e usa um formato de armazenamento colunar. O Impala está disponível como um projeto de código aberto e é suportado pela Cloudera.
O Apache Impala é um mecanismo de consulta SQL de software livre instalado em um cluster Hadoop e executa processamento paralelo massivo (MPP) para dados armazenados no sistema. Originalmente desenvolvido em 2012, o projeto de código aberto é conhecido como “Microsoft Fórmula 1”.
A plataforma Impala permite que os usuários executem consultas SQL de baixa latência para dados Hadoop armazenados em HDFS e Apache HBase sem precisar mover ou transformar os dados.
O Impala é baseado em SQL?
O Impala é um mecanismo de consulta baseado em SQL executado no Apache Hadoop. Ele permite que os usuários consultem dados armazenados em HDFS e HBase usando SQL. O Impala oferece alto desempenho e baixa latência em comparação com outros mecanismos de consulta do Hadoop, como Hive e Pig.
O banco de dados MPP analítico da Impala fornece o tempo de insight mais rápido do setor. Ele é integrado ao CDH e pode ser acessado por meio do Cloudera Enterprise. Bancos de dados MPP para Apache Hadoop, como Impala, usam HDFS para fornecer tempo de percepção mais rápido.
Impala é um banco de dados
É um banco de dados que eu acredito.
O Impala é uma ferramenta ETL?
O Impala não é uma ferramenta ETL, é um mecanismo de consulta SQL que pode ser usado para fazer consultas SQL após a limpeza dos dados por meio de um processo.
Para que serve o Apache Impala?
Usando consultas semelhantes a SQL, podemos ler dados de várias fontes usando o Impala. O Apache Impala tem um desempenho melhor do que o Hive e outros mecanismos SQL quando se trata de acesso aos dados armazenados no Hadoop Distributed File System . Usamos o Impala para armazenar dados no Hadoop HBase, HDFS e Amazon S3.
19 empresas que usam o Apache Impala em suas pilhas de tecnologia
O Apache Impala é um mecanismo de processamento de dados popular para uma variedade de grandes empresas. Segundo relatos, 19 empresas de tecnologia, incluindo Stripe, Agoda e Expedia.com, usam o Apache Impala. A plataforma Impala é flexível e eficiente, capaz de lidar com grandes conjuntos de dados de forma rápida e eficaz. O uso generalizado dessa ferramenta demonstra o quanto ela é útil e útil no processamento de dados.
Quais são as diferenças entre Sql Hive e Impala?
O objetivo do Hive é lidar com consultas de longa duração que requerem várias transformações e uniões. Devido à sua baixa latência e capacidade de lidar com consultas menores, o mecanismo de processamento de consultas Impala é ideal para computação interativa. O Spark oferece suporte a consultas de curto e longo prazo, além de consultas de curto e longo prazo.
O Hive é mais adequado para trabalhos em lote de longa duração
O objetivo principal das ferramentas não é processar lotes. O Hive é mais adequado para trabalhos em lote de longo prazo do que o Impulsa, que pode lidar com conjuntos de dados menores.
Impala é um banco de dados
Um impala é um banco de dados que armazena dados em um formato colunar. Ele foi projetado para ser escalável e fornecer alto desempenho para grandes conjuntos de dados.
Na versão inicial do Impala, os seguintes tipos de dados de colunas principais são suportados: STRING, VARCHAR, VARCHar2, INT e FLOAT em vez de número, e nenhum tipo BLOB é suportado. O Impala SQL-92 inclui alguns aprimoramentos de padrões SQL, mas não incorpora todos eles. Quando os dados são muito grandes para serem produzidos, manipulados e analisados em um único servidor, o Impala tem um desempenho melhor do que outros data warehouses e é mais habilitado para escalabilidade. Não há necessidade de remover o local original dos arquivos de dados ao carregar o Impala porque ele é leve. A primeira etapa para aprender sobre testes de desempenho, escalabilidade e configurações de cluster de vários nós geralmente é reunir grandes quantidades de dados. O Cloudera Impala é otimizado para carregamento de dados e leitura em massa em grandes conjuntos de dados, permitindo que você faça mais com menos. O tamanho de bloco de vários megabytes do HDFS permite que a Impala processe grandes quantidades de dados em paralelo em vários servidores em rede.
Em vez de planejar índices normalizados e o tempo e esforço necessários para criá-los, você fará isso no Impala. O mecanismo de consulta do Impala pode lidar com grandes quantidades de dados provenientes de data warehouses. Ele analisa um cluster e distribui tarefas entre os nós para reduzir a quantidade de recursos consumidos. O particionamento de um data warehouse é um conceito familiar no Impala. O particionamento reduz a E/S do disco e aumenta a escalabilidade da consulta no Impala. Os arquivos de dados são necessários, pois você não poderá acessar nenhuma tabela integrada no Impala. INSERT é uma das opções disponíveis.
Para construir duas mesas de brinquedo, use uma declaração de valor. Se você usa software orientado a lotes, pode experimentá-lo. Você pode incorporar a tecnologia SQL-on-hadoop em sua configuração do Apache Hive. As tabelas do Hive no Impala não são carregadas ou convertidas de forma demorada.
Impala: uma poderosa ferramenta de gerenciamento de dados para Hadoop
A sintaxe SQL é familiar aos usuários do Impala, que podem consultar dados armazenados em HDFS e Apache HBase. Dessa forma, Hadoop e Impulsa podem ser usados em vez de bancos de dados relacionais tradicionais . Além disso, é uma poderosa ferramenta de gerenciamento de dados graças às suas características. Além disso, seus recursos para grandes conjuntos de dados são impressionantes e ele pode lidar com eles com grande facilidade.
Impala em Big Data
O Impala é um mecanismo de consulta MPP SQL de software livre executado no Apache Hadoop. Ele fornece consultas SQL rápidas e interativas sobre dados armazenados em HDFS e HBase. O Impala foi projetado para melhorar o desempenho do Apache Hadoop, fornecendo uma interface SQL rápida e interativa para dados armazenados em HDFS e HBase.
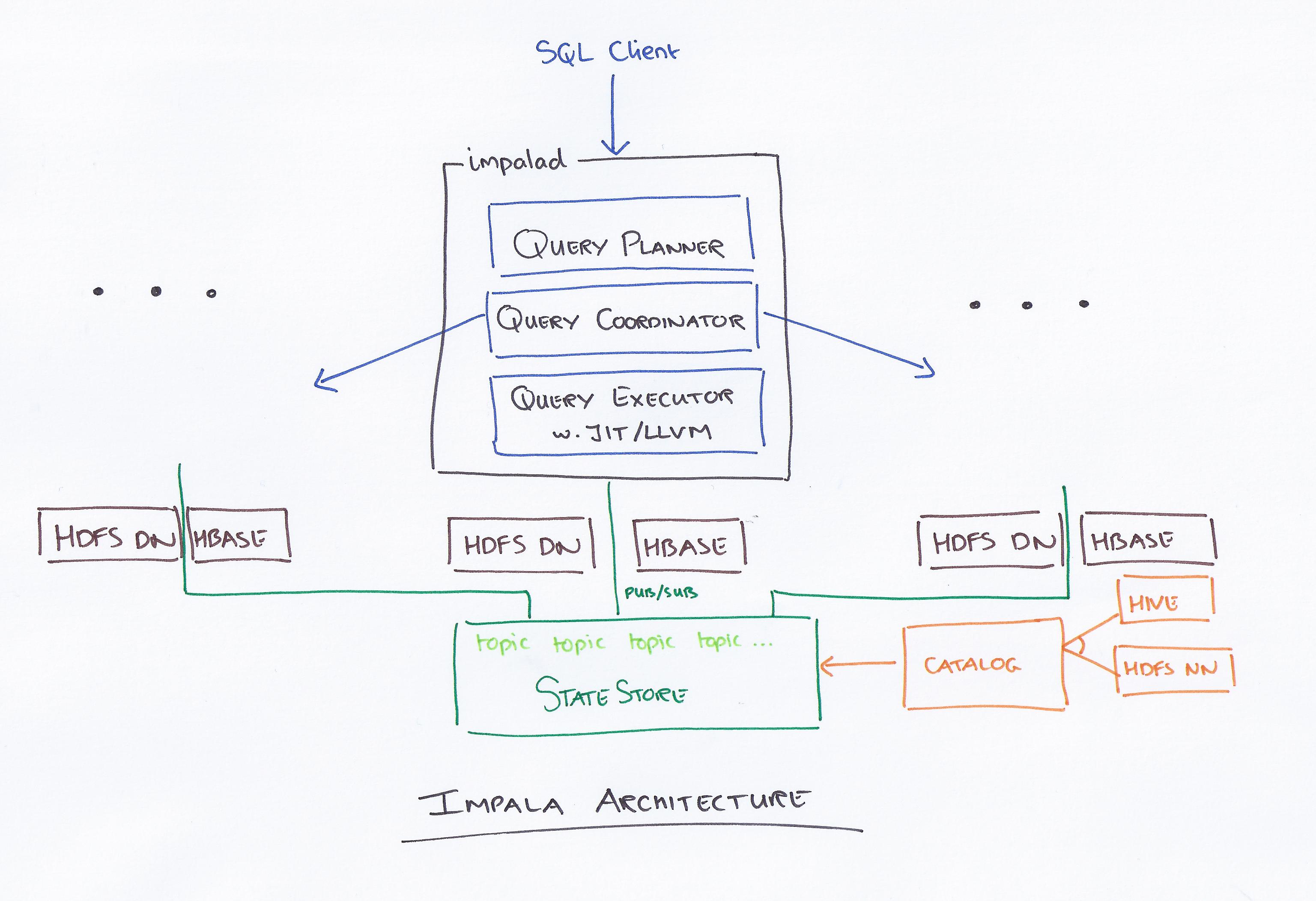
O Impala, liderado pela Cloudera, é um novo sistema de consulta. O Hadoop possui HDFS e HBase, portanto, pode consultar big data em nível de PB armazenado lá. Essa tecnologia é baseada em hive e memória para cálculo, além de levar em conta o data warehouse, e fornece processamento em lote em tempo real e processamento simultâneo múltiplo. Um cliente envia uma solicitação de consulta para um nó dentro de uma rede impalad, onde um ID de consulta é retornado para operações subsequentes do cliente. Durante a primeira etapa do processo de criação do analisador, um plano de execução autônomo (plano de máquina única, plano de execução distribuído) é gerado e o SQL também será executado, como alterações na ordem de junção, push downs de predicado e assim por diante. Todos os nós mantêm uma cópia das informações de metadados mais recentes para garantir que você não fique de fora do loop. Antes de usar Hadoop, Hive ou Impurbia, você deve primeiro instalar o software de processamento de dados necessário.

O arquivo de configuração do Impala pode ser alterado. Cada nó realiza uma mudança de configuração no Impala. Todos os nós são responsáveis por conectar o pacote do driver MySQL a um banco de dados. Os nós alteram o caminho Java do Bigtop.
Uma comparação entre Hive e Impala
Existem algumas pequenas diferenças também, além dessas três principais. No Hive, há um subconjunto do HiveQL, enquanto no Implicit, há um subconjunto do HiveQL. Hive e Impala são usados para armazenamento de dados e consulta interativa, respectivamente. O Hive, ao contrário do Impala, não se destina à computação interativa.
O que é Impala no Hadoop
O Impala é um mecanismo de consulta SQL de software livre para dados armazenados em um cluster Hadoop. Ele foi projetado para fornecer consultas SQL rápidas e interativas em dados armazenados em HDFS, HBase ou qualquer outra fonte de dados Hadoop .
A Impala emprega uma ampla variedade de componentes familiares do Hadoop . INSERT só pode gravar dados que são do tipo que o Impala pode ler, enquanto SELECT pode ler dados que são do tipo que o Impala pode ler. Ao usar um formato de arquivo Avro, RCFile ou SequenceFile, os dados são carregados no Hive. Estatísticas de tabela e estatísticas de coluna podem ser usadas além das estatísticas de tabela e coluna. Todas as instruções DDL e DML são atualizadas automaticamente usando o daemon catalogado no Impala 1.2 e superior se forem enviadas por meio do daemon catalogado. O método INVALIDATE METADATA retorna metadados para todas as tabelas no metastore que foram acessadas. Os arquivos de dados são armazenados em diretórios para uma nova tabela e são lidos independentemente do nome do arquivo quando o Impala está em execução.
No geral, o Apache Hive funciona bem como plataforma de armazenamento de dados, enquanto o Impala é mais adequado para processamento paralelo. O Hive é tolerante a falhas, enquanto o Impulsa não é.
Apache Impala
Apache Impala é um mecanismo de consulta SQL rápido e interativo para Apache Hadoop. Ele permite que os usuários emitam consultas SQL de baixa latência para dados armazenados em HDFS e Apache HBase sem exigir movimentação ou transformação de dados.
O conceito de arquitetura do Impala permite lidar com consultas interativas usando HDFS com mais eficiência do que qualquer outro mecanismo de consulta. O Hive é muito mais lento devido às suas operações de E/S de disco, mas o Apache é muito mais rápido porque é um mecanismo completamente diferente. Não há distinção entre o Impulsa e o Presto porque o Impulsa usa uma tecnologia muito mais rápida e o Presto emprega uma arquitetura semelhante. Quando se trata de arquivos Parquet, o Impala tem o melhor desempenho. Determine quais dados você deve particionar com base nas consultas de seus analistas. Com o Compute Stats Statistics, suas consultas ficarão muito mais fáceis, principalmente se envolverem mais de uma tabela (joins). Tínhamos um travamento do servidor de catálogo Impala quatro vezes por semana e nossas consultas demoravam muito para serem concluídas.
Além disso, a quantidade de arquivos que criamos afeta muito o desempenho de nossas consultas. Como resultado, começamos a gerenciar nossas partições e mesclá-las no tamanho de arquivo ideal de aproximadamente 256 MB. Afirma-se que cada partição possui apenas um arquivo (a menos que seu tamanho seja > 256 MB). O tipo de coluna mais apropriado deve ser escolhido entre todos os tipos de dados suportados pelo Implicit. Para limitar o número de consultas simultâneas ou memória Y acessada por um usuário, use o Impala Admission Control. Se uma consulta durar mais de 30 minutos, ela será considerada morta.
O Melhor Motor para Big Data: Impala
O mecanismo Impala é um mecanismo de processamento de dados Hadoop projetado especificamente para grandes clusters. Ele usa muito menos energia e consome significativamente menos recursos do que o mecanismo MapReduce padrão do Hadoop. A Implicit emprega o HDFS do sistema de arquivos distribuído como seu meio de armazenamento de dados principal, contando com a redundância do HDFS para evitar interrupções de hardware ou rede em cada nó. Os arquivos de dados que representam dados de tabela são representados fisicamente por formatos de arquivo HDFS familiares e codecs de compactação.
Mecanismo de Consulta de Processamento Paralelo
Um mecanismo de consulta de processamento paralelo é um tipo de mecanismo de banco de dados projetado para processar consultas em paralelo. Isso pode ser feito usando vários processadores, vários núcleos ou várias máquinas. O processamento paralelo pode melhorar muito o desempenho de um mecanismo de consulta, especialmente para consultas complexas.
Um computador multiprocessador é usado para transformar consultas complexas em planos de execução que podem ser executados simultaneamente, permitindo processar grandes quantidades de dados de uma só vez. Uma execução eficiente, como bom tempo de resposta de consulta ou alta taxa de transferência de consulta, é necessária para alto desempenho. Isso é realizado por meio do uso de técnicas eficientes de execução paralela e otimização de consultas.
Processamento paralelo: o futuro do ETL?
Uma consulta de alto nível pode ser transformada em um plano de execução que pode ser executado de forma eficiente por um computador multiprocessador usando o processamento paralelo de consultas. O processamento paralelo emprega a técnica de combinar dados paralelos e distribuídos, bem como as várias técnicas de execução fornecidas pelo sistema de banco de dados paralelo . O processamento de consulta paralela é implementado em ETL dividindo o conjunto de registros em cada tabela de origem atribuído para transferência em partes do mesmo tamanho e, em seguida, realizando o processo de transformação de dados para cada tabela de origem em um ciclo, selecionando os dados consecutivamente, parte por parte .