
Fatores de decisão do fragmento do banco de dados NoSQL
Publicados: 2023-02-13Quando fragmentar em um banco de dados NoSQL é uma decisão que deve ser tomada com base em vários fatores, incluindo, entre outros: tamanho dos dados e taxa de crescimento, carga e complexidade da consulta, requisitos de disponibilidade e escalabilidade e modelo de dados. Não existe uma resposta única para todos, e a decisão deve ser tomada caso a caso. No entanto, existem algumas diretrizes gerais que podem ser seguidas. Se o conjunto de dados for pequeno e a carga da consulta não for muito pesada, a fragmentação pode não ser necessária. Nesse caso, uma única instância de banco de dados NoSQL provavelmente pode lidar com a carga. À medida que o conjunto de dados cresce e a carga da consulta aumenta, a fragmentação pode se tornar necessária para manter um bom desempenho. O modelo de dados também pode ditar quando fragmentar. Se os dados estiverem estruturados de forma que possam ser facilmente divididos em partições separadas, a fragmentação pode ser uma boa opção. Por outro lado, se o modelo de dados for complexo e interconectado, a fragmentação pode não ser possível ou pode não ser a melhor opção. Finalmente, os requisitos de disponibilidade e escalabilidade devem ser levados em consideração. Se os dados devem estar altamente disponíveis e sempre acessíveis, a fragmentação pode ser necessária para fornecer redundância e eliminar pontos únicos de falha. Se a escalabilidade for uma grande preocupação, o sharding pode ajudar a distribuir a carga em vários servidores.
Quando devo começar a fragmentar?
Não há uma resposta definitiva para a questão de quando começar a fragmentação. A decisão depende de vários fatores, incluindo a quantidade de dados sendo armazenados, a taxa na qual os dados estão sendo adicionados, o crescimento futuro previsto do conjunto de dados, o nível de desempenho desejado e os recursos disponíveis. Em geral, a fragmentação deve ser considerada quando o conjunto de dados é muito grande ou está crescendo muito rapidamente para ser gerenciado de forma eficaz por um único servidor de banco de dados.
Por que fragmentar seu Mongodb é essencial para grandes conjuntos de dados
Quando devo começar a fragmentar o MongoDB? Quando um único banco de dados pode manipular ou armazenar uma grande quantidade de dados crescentes, a revenda é uma ótima opção. Um aumento de dez vezes na capacidade de armazenamento do banco de dados melhora o desempenho de um aplicativo. Também adiciona complexidade ao seu sistema. A fragmentação melhora o desempenho? Usar hash para melhorar o desempenho do banco de dados foi um dos primeiros métodos. O produto tornou-se um dos melhores como resultado dos recentes avanços tecnológicos. Apesar de os dados serem o ativo mais valioso de uma empresa, os bancos de dados estão recebendo mais atenção. Por que a fragmentação é melhor do que a replicação? Se você puder ler dados que não são os mais recentes, a replicação pode ser benéfica para dimensionar as leituras horizontalmente. Em um pool de dados compartilhado, os dados são distribuídos por vários servidores com a ajuda de uma chave compartilhada, permitindo escalabilidade horizontal. Escolher a chave de fragmentação certa é fundamental. Por que fragmentamos o MongoDB? Com o MongoDB, implantações com um grande número de conjuntos de dados e operações de alto throughput podem ser suportadas com sharding. Um sistema de banco de dados que contém grandes quantidades de dados ou possui um grande número de usuários simultâneos pode ser difícil de gerenciar em um único servidor. É possível que um servidor fique sem recursos de CPU quando altas taxas de consulta são encontradas. Por que a fragmentação é necessária? A normalização refere-se à partição de banco de dados horizontal (em linha), enquanto a partição de época refere-se à partição horizontal (em linha). Os fragmentos de dados são divididos em partes menores, mais rápidas e fáceis de gerenciar de bancos de dados muito grandes dessa maneira. é um exemplo de como sistemas distribuídos podem ser alcançados Qual banco de dados é o melhor para sharding? Usar Sharding, também conhecido como Particionamento Horizontal, como um método de dimensionamento é uma abordagem comum para bancos de dados. O Amazon RDS é um serviço de banco de dados relacional gerenciado baseado em nuvem que inclui vários recursos que simplificam a execução de fragmentação em várias nuvens.
O sharding é necessário no Nosql?
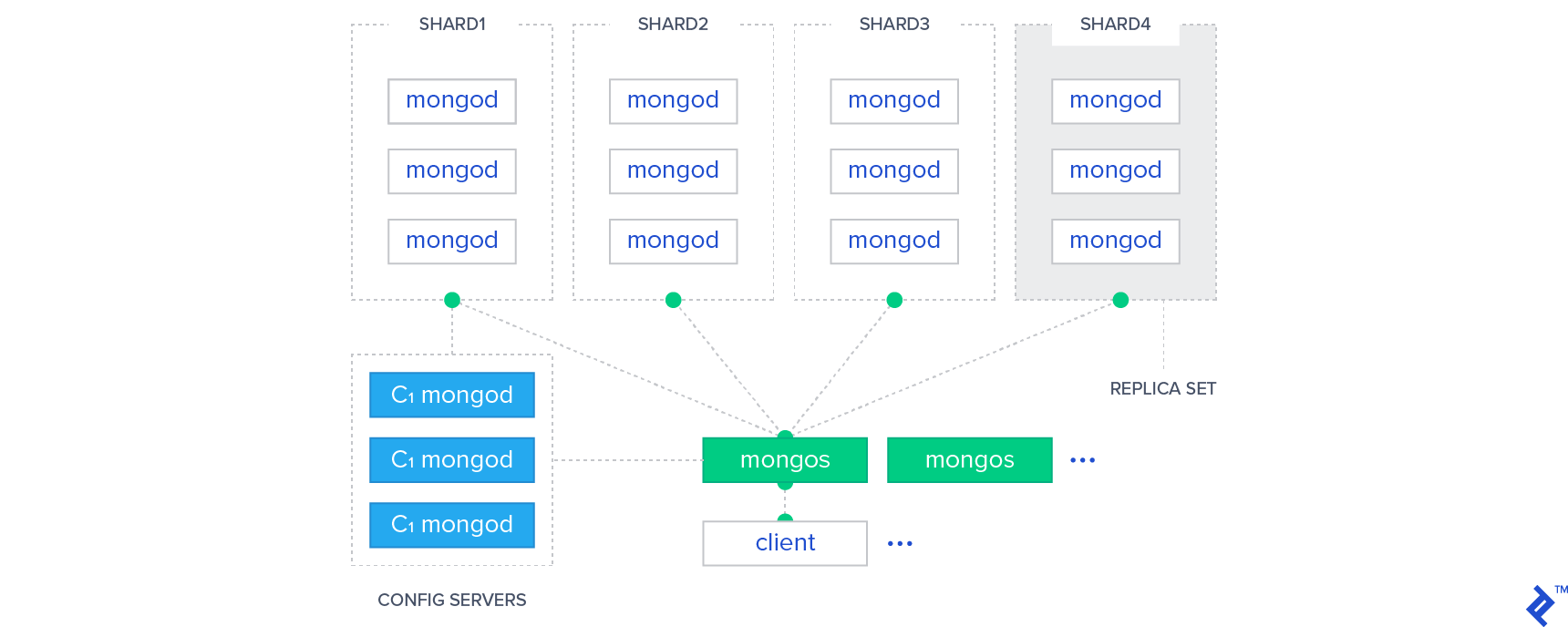
No NoSQL, o padrão Sharding é usado para particionar dados. O particionamento é um método de colocar cada partição em servidores potencialmente separados espalhados pelo mundo. A expansão permite que as pessoas acessem o conjunto de dados em vários pontos do mundo sem problemas.
O MongoDB possui uma importante ferramenta em seu banco de dados conhecida como Sharding. Ele pode ser usado para aumentar o desempenho distribuindo grandes conjuntos de dados em vários servidores. Um pedaço de dados em um servidor é identificado como um pedaço de dados em outro servidor usando uma chave de fragmentação. Como resultado, os dados podem ser copiados entre os servidores sem a necessidade de reindexá-los.
O sharding é a solução certa para o seu banco de dados?
Como resultado, se o único banco de dados do seu aplicativo não puder manipular ou armazenar uma grande quantidade de dados crescentes, armazená-los em uma instância de Sharding é uma ótima opção. A presença do Sharding melhora o desempenho do banco de dados e dimensiona o aplicativo. Há, no entanto, alguma complexidade adicional em seu sistema como resultado. Se você ainda não tem certeza se o sharding é a solução certa para você, lembre-se de que o MongoDB também oferece suporte ao dimensionamento horizontal.
Quando você deve fragmentar o Mongodb?
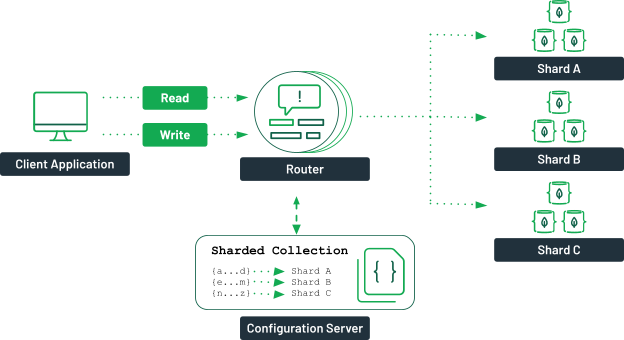
O MongoDB deve ser fragmentado quando o tamanho dos dados exceder a capacidade de um único servidor e quando for necessário um alto desempenho de consulta.
Quando fragmentar seu banco de dados Mongodb
Você deve considerar fragmentar seu banco de dados MongoDB? Você deve considerar vários fatores ao decidir se deve ou não usar um shard para seu banco de dados MongoDB. Em primeiro lugar, se o seu aplicativo MongoDB estiver apresentando altas taxas de consulta, é uma boa ideia usar o sharding. O Sraving também pode ajudar a expandir o banco de dados, se necessário. Antes de decidir se deve usar fragmentação, você deve considerar os benefícios e custos dela. Como você fragmenta o MongoDB? Se você planeja fragmentar seu banco de dados MongoDB, recomendamos usar o Amazon Relational Database Service (Amazon RDS). Os recursos do Amazon RDS tornam a fragmentação simples de usar na nuvem e também tem potencial para escalar.
Por que você fragmentaria um banco de dados?
O que é fragmentação de banco de dados ? Um conjunto de dados de amostra pode ser distribuído em vários bancos de dados usando a técnica de troca de época, que é armazenada em várias máquinas. A capacidade total de armazenamento do sistema será aumentada como resultado da divisão de conjuntos de dados maiores em partes menores e do armazenamento em vários nós de dados.
Sharding é a resposta para seus problemas de banco de dados?
Por que é necessário fragmentar um banco de dados? A fragmentação é uma ótima solução quando um único banco de dados em seu aplicativo não consegue lidar/armazenar uma grande quantidade de dados crescentes. Em geral, ao dimensionar o banco de dados, você pode melhorar o desempenho do seu aplicativo. Além disso, adiciona complexidade ao seu sistema. O que é um shard em um banco de dados? O objetivo da replicação de banco de dados é dividir um grande número de conjuntos de dados em partições ou fragmentos. Cada nó pode armazenar sua própria linha de dados dentro de cada estilhaço na forma de linhas únicas, que são armazenadas separadamente umas das outras. O esquema ou design original do banco de dados é compartilhado por todos os estilhaços, mas os nós que executam os estilhaços diferem um pouco. Você pode usar um servidor SQL para sharding? Usando blocos, um grande conjunto de dados pode ser dimensionado e gerenciado com mais eficiência. Existem vários métodos para dividir um conjunto de dados em estilhaços. Um banco de dados NoSQL ou SQL pode ser usado para executar o Sharding. Podemos fragmentar o banco de dados MySQL? Em um cluster, as linhas de partições (clusters) são executadas automaticamente nos nós, permitindo que os bancos de dados sejam dimensionados horizontalmente em hardware de baixo custo para lidar com cargas de trabalho intensivas de leitura e gravação, bem como APIs SQL e NoSQL diretamente do servidor. O sharding para banco de dados relacional só é possível? Um dos métodos de expansão mais populares para bancos de dados relacionais é o método Sharding de dimensionamento horizontal. O Amazon Relational Database Service (Amazon RDS) é um serviço de banco de dados relacional gerenciado que simplifica a fragmentação na nuvem devido a seus recursos abrangentes.

Por que precisamos de sharding no Mongodb?
O processo de distribuição de dados em várias máquinas é conhecido como hashing. Com o MongoDB, implantações com grandes conjuntos de dados e operações de alta velocidade podem se beneficiar do uso de sharding. Um sistema de banco de dados com uma grande quantidade de dados ou um aplicativo que pode lidar com um grande número de solicitações pode ser difícil de executar em um único servidor.
Precisamos de sharding no Nosql?
A fragmentação do banco de dados é necessária para dimensionar os bancos de dados SQL e NoSQL , que são bancos de dados SQL e NoSQL. Estamos dividindo o banco de dados em várias partes (shards) como o nome indica. Cada fragmento tem seu próprio índice, que é usado para determinar quais dados ele armazena.
Os benefícios da fragmentação
O ato de distribuir dados por vários servidores em um cluster é conhecido como sharding. É possível melhorar o desempenho de um banco de dados distribuindo o trabalho que ele deve realizar em vários servidores.
O serviço MongoDB usa uma chave de fragmentação para distribuir documentos de uma coleção para outra. O MongoDB divide os dados em pedaços, que são divididos em intervalos não sobrepostos de acordo com o alcance dos valores-chave. O back-end do MongoDB tenta distribuir esses pedaços uniformemente entre os clusters.
Não há uma maneira única de usar o Cassandra para fragmentação. No Mongodb, cada nó secundário armazena todos os dados do nó primário, enquanto no Cassandra, apenas algumas partições de chave são mantidas por cada nó secundário. Se o Cassandra for fragmentado, ele poderá atingir os mesmos níveis de desempenho do MongoDB sem a necessidade de um nó secundário.
Por que precisamos de sharding em bancos de dados relacionais?
Devido à melhor distribuição de dados e carga de trabalho em uma arquitetura de banco de dados bem projetada, todos os fragmentos de banco de dados podem ser distribuídos igualmente. Sempre que uma consulta passa por um conjunto diferente de fragmentos, ela é consistente com a expectativa de desempenho.
Qual banco de dados é melhor para sharding?
A fragmentação do banco de dados é possível em Cassandra, HBase, HDFS, MongoDB e Redis. MySQL, PostgreSQL, Memcached, Zookeeper e Sqlite são apenas alguns dos bancos de dados que não oferecem suporte nativo à fragmentação de PostgreSQL e MySQL. Quando um banco de dados não oferece suporte à lógica de fragmentação integrada, ele deve ser armazenado no aplicativo.
Fragmentação em Nosql
Existem algumas maneiras diferentes de abordar a fragmentação em um banco de dados NoSQL. O mais comum é usar uma função de hash para determinar em qual fragmento um determinado dado deve ser armazenado. Isso pode ser feito no nível do aplicativo ou no nível do banco de dados. Outra abordagem é usar o sharding baseado em intervalo, que envolve o armazenamento de dados em diferentes shards com base no intervalo de valores em que ele se enquadra. Isso geralmente é usado para coisas como dados de séries temporais. Existem também algumas outras abordagens menos comuns, mas essas são as duas mais comuns.
Por que a fragmentação é a chave para escalar um banco de dados Cassandra
Ao escalar um banco de dados nosql, a chave é usar fragmentação. O banco de dados é particionado em várias partes conhecidas como slabs, que podem ser acessadas de várias máquinas. O sistema pode armazenar conjuntos de dados maiores em pedaços menores e clusters de nós, aumentando a capacidade total de armazenamento.
O sraving, especificamente, pode assumir a forma de sharding baseado em chave e automatizar a distribuição de dados entre nós no Cassandra. Em outras palavras, o Cassandra pode lidar com grandes conjuntos de dados sem exigir hardware ou software adicional.
Em qual categoria de bancos de dados Nosql é recomendável não fragmentar dados?
Não há uma resposta definitiva para essa pergunta, pois depende das necessidades específicas do aplicativo. No entanto, geralmente é recomendável não fragmentar dados em armazenamentos de valores-chave ou bancos de dados orientados a documentos.
Fragmentação Nosql Vs Particionamento
O particionamento e a fragmentação são métodos de dividir uma grande quantidade de dados em subconjuntos menores. O particionamento difere do sharding porque envolve a divisão de dados em vários computadores, em vez de distribuí-los entre eles. A função de partição de uma instância de banco de dados é usada para dividir subconjuntos de dados entre eles.
Escalando seu banco de dados com sharding
Os bancos de dados Nosql podem escalar horizontalmente replicando o esquema e dividindo-o em estilhaços. Particionar bancos de dados é o processo de replicar o esquema e dividi-lo em várias partes com base em um identificador de chave em uma instância separada do servidor de banco de dados para distribuir a carga. Cada tabela distribuída contém uma chave de fragmentação.
Um grande conjunto de dados pode ser manipulado ingerindo e armazenando-os em microsserviços. Existem inúmeras maneiras de dividir uma grande quantidade de dados em pequenos pedaços. Os bancos de dados SQL e NoSQL podem ser usados para combinar e descartar dados.
Os bancos de dados SQL e NoSQL se distinguem por sua capacidade de gerenciar escala e heterogeneidade de dados, enquanto os bancos de dados SQL se beneficiam da capacidade do mecanismo de particionamento do banco de dados. Shrsiting é um método eficiente de gerenciar seus dados, independentemente de você precisar aumentar ou diminuir.
Qual é uma maneira pela qual um banco de dados Nosql distribuído geralmente fragmenta os dados?
Existem algumas maneiras diferentes pelas quais um banco de dados NoSQL distribuído pode fragmentar dados, mas uma abordagem comum é usar uma função de hash. Esta função é usada para determinar em qual nó do banco de dados um dado deve ser armazenado. Quando um novo dado chega, a função hash é usada para determinar em qual nó ele deve ser armazenado. Se o nó já estiver cheio, os dados serão enviados para o próximo nó no banco de dados.
O fragmento em um banco de dados
O que é um fragmento em um banco de dados?
O fragmento de um servidor de banco de dados é um subconjunto de dados armazenados nesse servidor. Uma coleção de dados, conhecida como Shard, é composta de partes iguais. Como conjuntos de dados maiores podem ser armazenados em vários servidores menores, os clientes podem acessá-los mais rapidamente.
Fragmentação Mongodb
A fragmentação do Mongodb é um processo de distribuição de dados em várias máquinas. É uma maneira de dimensionar um banco de dados mongodb dividindo os dados em partes menores e distribuindo-os em vários servidores. Isso permite o dimensionamento horizontal do banco de dados, o que significa que mais servidores podem ser adicionados ao sistema conforme necessário para acomodar o aumento do tráfego.
Fragmentando seu banco de dados
Uma variedade de tipos de sharding está disponível, incluindo ranged/dinâmico, algorítmico/hash, baseado em entidade/relacionamento e baseado em geografia. A divisão dos dados em intervalos e a atribuição de servidores a cada um deles é feita por meio de fragmentação dinâmica . O servidor é movido para diferentes regiões à medida que os dados são adicionados à matriz, dependendo do tamanho da matriz. A fragmentação algorítmica/hashed divide os dados em buckets e atribui um servidor a cada bucket. Se os dados forem adicionados ao depósito, será atribuído um valor de hash ao servidor. Um método de fragmentação baseado em relacionamento divide dados em entidades e relacionamentos entre entidades. Cada entidade tem uma lista de todas as entidades às quais se conecta. A fragmentação baseada em geografia divide os dados em regiões, atribui a cada região um servidor e, em seguida, divide os dados em regiões.
Estratégia de partição de intervalo de chave
Uma estratégia de partição de intervalo de chave define como os dados em uma tabela particionada são distribuídos em várias partições físicas. O intervalo de chaves é baseado nos valores de uma coluna de particionamento e cada partição recebe um intervalo de valores com base nas chaves de particionamento. Essa estratégia geralmente é usada para distribuir dados uniformemente em vários servidores ou para garantir que os dados sejam armazenados no mesmo local físico.
Particionamento de intervalo: a abordagem do serviço de integração para distribuição de dados
O Serviço de Integração, que distribui linhas de dados com base em uma porta ou conjunto de portas definidas como chaves de partição, emprega particionamento de intervalo para distribuir linhas de dados. Os intervalos de valores para cada porta são especificados no seguinte formato. Como resultado, o Serviço de Integração usa a chave e o intervalo para enviar linhas à partição apropriada.
O Serviço de Integração distribui linhas de dados com base em uma porta ou conjunto de portas que você define como a chave de partição usando o particionamento de intervalo.
Quando você está carregando novos dados e removendo dados antigos, essa é uma ótima maneira de fazer isso. O processo de partição de intervalo é facilitado por ele. O roll-out de dados, por exemplo, é uma prática comum, mantendo online os dados dos últimos 36 meses.