
Bancos de dados NoSQL: uma alternativa aos bancos de dados relacionais tradicionais
Publicados: 2023-01-13Os bancos de dados NoSQL estão se tornando cada vez mais populares como uma alternativa aos bancos de dados relacionais tradicionais. Um banco de dados NoSQL não requer um esquema fixo e é fácil de escalar. Uma fila é um tipo de armazenamento de dados NoSQL. Uma fila é uma estrutura de dados que armazena dados da maneira primeiro a entrar, primeiro a sair (FIFO). Uma fila geralmente é usada para armazenar dados que precisam ser processados em uma ordem sequencial, como uma lista de tarefas a serem concluídas. Uma fila é um tipo de armazenamento de dados NoSQL porque não requer um esquema fixo. Uma fila pode ser facilmente dimensionada à medida que o número de tarefas aumenta.
Se vou usar MongoDB ou RavenDB como uma fila de mensagens , qual vou preferir? O objeto de mensagem pode ser enviado para um serviço da Web por meio do cliente e, em seguida, recuperado pelo serviço da Web. O serviço que está executando o trabalho pode selecionar um tipo de mensagem com base em qualquer critério que possa surgir. Posso criar índices com base nos cenários para acelerar as coisas. Se você está apenas construindo uma fila, você deve considerar o NoSQL para nada mais do que isso. Provavelmente terá um impacto maior no desempenho, confiabilidade e eficiência se você tomar uma decisão sobre qual implementação deseja usar.
Os bancos de dados NoSQL (também conhecidos como SQL) armazenam dados de maneira diferente dos bancos de dados relacionais, além de não serem tabulares. Um banco de dados NoSQL pode vir em uma variedade de tipos diferentes com base em seu modelo de dados. Tipos de documento, tipos de valor-chave, tipos de coluna larga e gráficos são os mais comumente usados.
Datastore é um banco de dados NoSQL altamente escalável que oferece suporte a uma ampla variedade de aplicativos. Como resultado, o Datastore gerencia automaticamente a fragmentação e a replicação, permitindo que você use um banco de dados altamente disponível e durável que escala automaticamente para lidar com a carga de seus aplicativos.
O que é um armazenamento de dados Nosql?
Existem muitos tipos diferentes de armazenamentos de dados NoSQL, cada um com seus próprios pontos fortes e fracos. Os armazenamentos de dados NoSQL mais populares são MongoDB, Cassandra e HBase.
Os bancos de dados NoSQL baseados em documentos armazenam dados com mais eficiência do que os bancos de dados relacionais. Eles devem ser adaptáveis, escaláveis e capazes de responder rapidamente aos requisitos de negócios para gerenciamento de dados. Os tipos de banco de dados comumente referidos como NoSQL incluem bancos de dados de documentos puros, armazenamentos de valores-chave, bancos de dados de colunas largas e bancos de dados de gráficos. As empresas globais 2000 estão adotando rapidamente bancos de dados NoSQL para alimentar aplicativos de missão crítica. Isso se deve a cinco tendências que apresentam desafios técnicos que dificultam o uso da maioria dos bancos de dados relacionais. O gerenciamento de banco de dados é uma grande barreira para o desenvolvimento ágil porque eles não têm a capacidade de suportar o modelo de dados fixo que é essencial para o desenvolvimento ágil. O modelo de aplicativo define o modelo de dados em NoSQL.
Modelar os dados em NoSQL não é estático. O formato JSON é o formato padrão para armazenar dados em um banco de dados orientado a documentos. Isso elimina a necessidade de estruturas ORM e melhora o processo de desenvolvimento. N1QL (pronuncia-se níquel), uma poderosa linguagem de consulta que estende SQL para JSON, foi lançada como parte do Couchbase Server 4.0. Além disso, inclui suporte para instruções SELECT / FROM / WHERE padrão, bem como agregação (GROUP BY), classificação (SORT BY), junções (LEFT OUTER / INNER) e outros. Por causa de sua arquitetura de expansão e nenhum ponto de falha único, os bancos de dados distribuídos NoSQL têm vantagens operacionais atraentes. A disponibilidade está se tornando um problema importante à medida que mais clientes interagem com empresas online e por meio de aplicativos móveis.
Os bancos de dados NoSQL são simples de instalar, configurar e dimensionar. Com suas leituras, gravações e armazenamento distribuídos, eles foram projetados para simplificar a leitura, a gravação e o armazenamento. Eles podem operar em uma ampla variedade de escalas, incluindo aquelas que gerenciam e monitoram clusters de tamanhos variados. Não há necessidade de desenvolver software para replicar entre datacenters; um banco de dados NoSQL distribuído inclui replicação integrada entre datacenters. Além disso, ele permite que os aplicativos executem seu próprio failover em vez de esperar que o banco de dados detecte um problema e execute um processo de recuperação com base no banco de dados. Os bancos de dados NoSQL são cada vez mais usados em aplicativos da Web, móveis e IoT devido à sua facilidade de uso e integração.
O armazenamento de tabelas é uma excelente solução para dados que não são armazenados em um banco de dados relacional. O armazenamento de tabelas permite armazenar dados em um contêiner flexível o suficiente para acomodar o crescimento de seu aplicativo. Um sistema de armazenamento de tabela pode ser usado para armazenar dados difíceis de armazenar em um modelo relacional, como dados de vídeo ou imagem.
Bancos de dados Nosql do Azure: Documentdb, Graph e Keyvalue
Os três tipos de bancos de dados NoSQL no Azure são Azure DocumentDB, Azure Graph e Azure KeyValue. Com o Azure DocumentDB, não há necessidade de gerenciar arquivos de dados no servidor ou recuperá-los de arquivos; é sem servidor, valor-chave e pode lidar com até milhões de solicitações por segundo. Este é um banco de dados gráfico que pode ser usado para consultar e gerenciar dados em várias camadas em um aplicativo. O Azure Graph é um banco de dados gráfico que pode ser usado para consultar e gerenciar dados em várias camadas em um aplicativo. Ele permite que você organize e filtre dados nas listas classificadas e filtradas do Azure KeyValue.
Uma fila é um banco de dados?
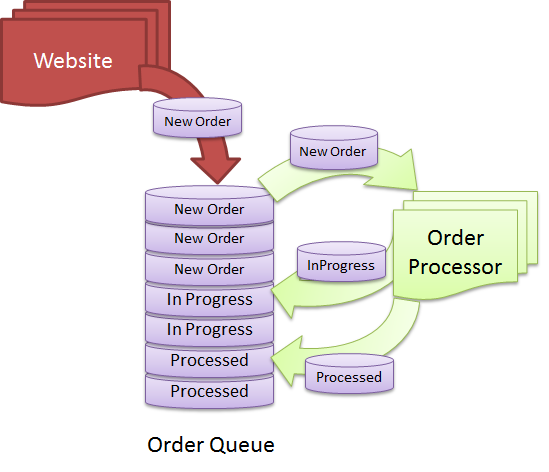
Não há uma resposta definitiva para essa pergunta, pois depende de como você define um banco de dados. De um modo geral, um banco de dados é uma coleção de dados organizados de uma maneira específica para que possam ser acessados e atualizados conforme necessário. Uma fila é uma estrutura de dados que permite armazenar e recuperar dados em uma ordem específica. Portanto, se você considerar uma fila como uma coleção de dados, ela poderá ser considerada um banco de dados. No entanto, se você considerar um banco de dados apenas como uma coleção de dados que podem ser acessados e atualizados, uma fila não será considerada um banco de dados.
Quando é o momento certo para usar um banco de dados para um sistema baseado em fila? É fundamental manter uma fila ordenada e organizada para que todas as solicitações sejam processadas o mais rápido possível. Há uma fila de mensagens projetada para lidar com esse tipo de situação, simplificando a remoção ou enfileiramento de mensagens . Imagine que você tenha centenas de solicitações de criação de PDF em seu banco de dados a qualquer momento. É desejável poder processar mais solicitações por segundo de forma contínua. Não há necessidade de conectar mais trabalhadores (processos que tratam de solicitações) porque você pode dimensionar sua solução. Para receber a solicitação, o trabalhador precisará fornecer uma informação adicional.
As filas de mensagens não exigem que o usuário execute nenhuma transação para garantir que as mensagens sejam armazenadas e processadas. Em vez de pesquisar manualmente as mensagens de um banco de dados, as filas de mensagens são enviadas em tempo real. Se você ficar sem energia da CPU ao conectar-se a muitas conexões ou executar outras tarefas que exijam muita CPU, poderá usar mais energia da CPU para alimentar seu servidor de fila de mensagens. Nos casos em que um grande número de mensagens assíncronas é necessário, uma fila de mensagens é altamente recomendada. Se um trabalhador morrer durante a execução de uma tarefa, ele deve ficar na fila até que a solicitação seja resolvida. Quando uma mensagem é recebida e processada, um trabalhador envia uma confirmação de volta à fila de mensagens para notificá-los sobre o andamento.

Uma fila é uma estrutura de dados que pode armazenar uma coleção de itens em uma ordem lógica. Os itens colocados em uma fila são processados o mais rápido possível após serem adicionados à fila. Uma fila pode ser útil quando você deseja processar itens em uma ordem específica. Uma instrução SELECT é um método que pode ser usado para alterar o conteúdo de uma fila. Uma instrução SELECT é um método que permite selecionar itens de uma fila e enviá-los para outro local, se desejar. A instrução SELECT também é usada para enviar itens de outro local para uma fila apropriada , bem como para inseri-los em uma fila. Uma instrução INSERT, UPDATE, DELETE ou TRUNCATE não pode tentar direcionar uma fila. Se você precisar processar itens em uma ordem específica, uma fila é útil; no entanto, você não deve modificar os itens na fila.
A importância dos sistemas de filas em sistemas de banco de dados
Um banco de dados com mecanismos de fila é um excelente complemento para qualquer data center. É fundamental ter a funcionalidade DBMS para sistemas de fila porque eles podem ser usados para uma variedade de propósitos. Ao integrar a funcionalidade de fila em um sistema de banco de dados padrão , outros aplicativos podem obter maior acesso a eles. Com esta atualização, os sistemas de filas são mais poderosos e versáteis, e sua utilidade e potencial são aumentados.
O Mongodb tem uma fila?
Uma fila é uma coleção de documentos inseridos em um banco de dados MongoDB em ordem crescente com base nos dados de criação do documento ou em uma classificação de documentos com base em uma determinada prioridade.
Se você já usa o MongoDB, pode usar esse método para criar filas com uma boa API. Se você tiver um driver MongoDB v3 ou um banco de dados mais antigo, a opção mongodb- [email protected] é recomendada. Este pacote é classificado como recurso completo e estável. Apesar de seu uso generalizado, há muito pouco desenvolvimento acontecendo com ele. Por favor, deixe-nos saber se você tiver algum problema ou se você usá-lo incorretamente. Cada fila que você criar será uma única. Uma coleção do MongoDB pode ser criada chamada resizing-image-queue ou notify-owner-queue, ambas as quais podem ser usadas.
Se você não receber uma mensagem dentro de 30 segundos após recebê-la, ela será colocada de volta na fila para que possa ser recuperada. Pesquise sua fila morta para ver se alguma mensagem morta foi encontrada. Quando retornamos todas as mensagens da fila original para a fila morta when.get(), a carga útil da fila morta é a mensagem. Se um item for removido da fila, mas não reconhecido, ele será movido para esta fila morta na próxima vez que tentar sair. Se um item for removido da fila, mas não reconhecido, ele será movido para esta fila morta na próxima vez que tentar sair. A fila ainda pode ser visualizada por meio de ping de uma mensagem para informar que você está ativo e processando a solicitação. O tempo de visibilidade que você passa na operação de ping também é determinado pelo método // visibilidade time (neste caso, esta fila viu%d mensagens%d mensagens%d contagens; ); // queue.ping(msg.ack, (err, id) = O número de mensagens que estiveram na fila nas últimas 24 horas, bem como as mensagens atuais.
Podemos calcular o número de novas mensagens recebidas, mas ainda não ativadas. Deve ser possível obter.total() se você adicionar up.size() +.inFlight() +.done(), mas isso será apenas aproximado porque as duas são operações diferentes usadas para calcular o total. Às vezes, as estações são muito diferentes. Use a opção setInterval para limpar seu sistema regularmente. Console.log('As mensagens processadas foram deletadas da fila')*).
Fila do Mongodb
As filas do MongoDB (ou filas de mensagens) fornecem um mecanismo para armazenar mensagens de maneira ordenada, primeiro a entrar, primeiro a sair. As mensagens podem ser inseridas na fila a qualquer momento e serão processadas na ordem em que forem recebidas. Isso torna as filas do MongoDB ideais para tarefas de processamento que precisam ser executadas em uma ordem específica ou para tarefas que podem ser processadas de forma assíncrona.
A missão da FloQast é permitir que as equipes de produtos acelerem e automatizem o desenvolvimento de produtos inovadores. Tradicionalmente, o AWS SQS serviu como nosso serviço de fila de mensagens . Isso resultou em problemas em termos de manutenção da funcionalidade e duplicação. Em vez disso, escolhemos o MongoDB como nossa fila de mensagens. No AWS Lambda, você pode adicionar mensagens facilmente a qualquer fila. Ele elimina a necessidade de atualizar os serviços existentes para usar um Lambda separado. Quando uma fila é acessada, o serviço usa o método atômico findAndModify do MongoDB para pegar o primeiro item e invocar o Lambda com base nas instruções do desenvolvedor.
O que é fluxo de mudança no Mongodb?
Em tempo real, os desenvolvedores de aplicativos podem ver as alterações nos dados sem medo de seguir seu oplog ou ter que lidar com a complexidade e os riscos de estruturas de dados complexas. Um fluxo de mudança pode ser usado por um aplicativo para assinar todas as alterações nos dados em qualquer coleção, banco de dados ou implantação e reagir a elas imediatamente.
Use gatilhos para automatizar operações de banco de dados
Usando mecanismos de gatilho, você pode automatizar as operações do banco de dados e tornar seu sistema mais eficiente. Quando um documento é adicionado, atualizado ou removido de um cluster vinculado do MongoDB Atlas, os gatilhos podem lidar com a lógica do lado do servidor. Você será capaz de manter seu sistema funcionando sem problemas e automatizar as operações de banco de dados como resultado.
Banco de Dados de Documentos Nosql
Um banco de dados NoSQL, também chamado de banco de dados não relacional, é um banco de dados que não usa a estrutura tradicional de banco de dados relacional baseada em tabela. Os bancos de dados NoSQL são frequentemente usados para big data e aplicativos da Web em tempo real.
Um banco de dados orientado a documentos é uma maneira moderna de armazenar dados em JSON em vez de usar colunas e linhas tradicionais. Esses dados semiestruturados podem ser usados para lidar com problemas difíceis que, de outra forma, exigiriam um RDBMS. Os armazenamentos de documentos são uma solução natural e flexível que pode ser usada por desenvolvedores que desejam trabalhar mais rapidamente com software ágil. Você pode consultar de várias maneiras com a linguagem de consulta expressiva e os recursos versáteis de indexação. Um banco de dados relacional possui um conjunto de garantias com as quais você está familiarizado ao executar transações ACID. Ter sistemas distribuídos permite dimensionar e proteger seus dados de maneira mais eficiente e adaptável. Cada documento é distribuído em vários servidores em uma unidade independente, o que reduz a necessidade de localidade de dados.
Os bancos de dados de documentos são intuitivos e simples de usar, com velocidades de dados mais rápidas do que os bancos de dados relacionais. A qualidade dos dados será menor e as tabelas serão rígidas. Como a expansão nativa não pode ser executada, você deve pagar por sistemas de expansão caros se quiser particionar seu banco de dados relacional tradicional. É possível escolher entre uma ampla variedade de tipos de documentos em bancos de dados orientados a documentos; no entanto, os campos encontrados em cada loja podem ser opcionais. Cada documento tem a mesma estrutura, mas seus campos diferem. Cada documento tem seu próprio ID exclusivo que pode ser usado para adicionar, alterar, excluir e consultar informações. Normalmente, acredita-se que as codificações de documentos sejam o processo de conversão de dados encapsulados (ou informações) em um formato padrão.
Uma estrutura de banco de dados orientada a documentos é menos rígida e, portanto, menos propensa a inconsistências. Quando você consulta informações diretamente do documento em vez de colunas no banco de dados, os dados são armazenados mais diretamente no documento. Os dados podem ser adicionados ao armazenamento de documentos com um único campo que contém campos de informações relevantes para os dados.