
Os bancos de dados NoSQL são a solução perfeita para recuperação de dados em alta velocidade!
Publicados: 2023-02-09Os bancos de dados NoSQL costumam ser usados em situações em que as junções seriam muito lentas ou criariam muita duplicação de dados. Além disso, muitos bancos de dados NoSQL são projetados para serem escalonáveis horizontalmente, o que significa que podem ser facilmente divididos em vários servidores. As junções não são adequadas para escalabilidade horizontal porque exigem que todos os dados estejam em um único servidor.
Os operadores de junção gerais usados em bancos de dados mais tradicionais, como o Oracle, não oferecem suporte ao Oracle NoSQL Database. No entanto, ele oferece suporte a um tipo separado de junção entre tabelas dentro da mesma hierarquia de tabelas. Linhas colocalizadas podem permitir junções eficientes porque somente linhas com coordenadas idênticas podem ser unidas.
O processo combina linhas de duas ou mais tabelas usando uma coluna relacionada entre elas na cláusula JOIN. Na maioria dos bancos de dados Oracle NoSQL, quando um usuário está tentando extrair dados de tabelas cujas relações hierárquicas foram diferenciadas, são usadas junções.
a incorporação é um dos padrões comumente encontrados no MongoDB. A normalização ocorre quando as partes de um processo são divididas em componentes separados. As partes geralmente são um único documento no mongo, portanto, nenhuma junção é necessária.
Por que você não se junta? Bancos de dados orientados a documentos, como o MongoDB, destinam-se a armazenar dados desnormalizados. Não deve haver nenhuma relação entre as coleções. Se os mesmos dados forem exigidos em dois ou mais documentos, deve-se repetir.
Joins são possíveis em Nosql?

Sim, junções são possíveis em bancos de dados nosql. No entanto, eles não são tão comuns quanto em bancos de dados relacionais porque os bancos de dados nosql geralmente são projetados para serem mais escaláveis e com melhor desempenho. As junções podem ser usadas para combinar dados de várias coleções nosql, mas podem ser mais caras do que outras operações.
O novo operador $lookup permite executar uma operação de junção externa esquerda em duas ou mais coleções usando o operador $lookup do MongoDB 3.2. A agregação é mais difícil de entender do que as consultas de localização simples e geralmente leva mais tempo para ser concluída. Eles são poderosos e essenciais em operações de busca complexas, mas também são vulneráveis. Uma consulta agregada para MongoDB é executada da mesma maneira que qualquer outra consulta, passando uma matriz de operadores de pipeline. O documento contém uma data, uma classificação e uma referência ao usuário que o escreveu, além do texto, data e informações de classificação. Atualmente, exibimos as vinte postagens mais recentes em ordem cronológica inversa com base nas avaliações dos usuários. O recurso $lookup é uma adição importante ao MongoDB 3.2.
Ao usar pequenas quantidades de dados relacionais em um banco de dados NoSQL, pode ser benéfico superar alguns dos problemas mais difíceis. O operador $lookup não deve ser usado regularmente. Se você precisar de muitos dados, use um banco de dados relacional (SQL).
O Mongodb é bom para junções?

O recurso MongoDB Joins agora é suportado pelo MongoDB 3.2, graças à introdução de uma nova operação Lookup para operações MongoDB Collections Join.
O MongoDB não tem medo de consumir dados não estruturados. Ao comparar junções do MongoDB com junções de mesclagem e junções de hash , ainda não podemos fazer junções de mesclagem e junções de hash. Ao fornecer um índice que permite unir loops aninhados de um índice para outro, podemos ajudar na pesquisa. No entanto, em termos de melhorias drásticas no desempenho de qualquer 'JOIN', não podemos fazê-lo. Para a consulta a seguir, executamos o seguinte script do MongoDB com a ajuda do recurso de consulta SQL no Studio 3T, a interface gráfica do usuário do MongoDB. Os resultados revelam o número de pedidos individuais, bem como o valor total desses pedidos, ambos medidos pelo número de clientes individuais e contatos da loja. O índice é discutido nesta nota.
Se você precisar apenas de alguns campos de uma coleção, poderá fazer muito melhor usando um 'índice de cobertura' que inclua esses campos com os critérios de consulta reais. Como resultado, criamos um índice de vendas. Número de identificação da pessoa. ID da entidade e vendas associadas a uma pessoa. OrderHeaders para vendas Um único campo _id, semelhante a um índice clusterizado, é usado nesses tipos de campos. A ordem de agregação refletida na ordem de junção reflete a ordem das junções no Studio 3T, resultando em um tempo de execução mais rápido de 4,2 segundos. O MongoDB e o SQL Server compartilham o mesmo servidor, com o último gerenciando a mesma agregação do MongoDB em 160 milissegundos.
Estamos analisando registros de negociação de faturas neste caso. Há uma série de razões válidas pelas quais eles não devem mudar, e não mudam. Simplesmente preparamos e mantemos nossos dados históricos no formato pré-preparado do MongoDB. Ao pré-agregar com uma coleção intermediária como esta, reduzimos o tempo de nosso relatório para 25 milissegundos. A amostra completa do código pode ser encontrada aqui: Isso agregará 120 ms na minha máquina, o que é bastante impressionante quando você considera as etapas envolvidas. Da mesma forma, o relatório de um vendedor deve ser preciso. Isso é feito em segundos combinando as palavras 'vendas' e 'posições'.
Podemos eliminar todos os registros em 48 milissegundos removendo primeiro todos os registros dos vendedores $null (clientes por correspondência). A classificação deve ser adiada até que você tenha os documentos necessários para o relatório final, bem como uma lista de todas as pesquisas. Você deve começar a combinar e projetar antes de começar. À medida que o pipeline passa por cada documento, é fundamental mantê-lo enxuto, garantindo que apenas os dados necessários sejam inseridos nele. Por fim, é fundamental encontrar a ordem em que os estágios serão executados em um pipeline de agregação.
Isso permite uma gama mais ampla de opções ao realizar a análise de dados porque permite a agregação de dados de duas ou mais fontes. Além disso, os dados podem ser classificados em categorias específicas e facilmente encontrados, graças à sua capacidade de agrupar dados em categorias específicas.
A estrutura do MongoDB difere daquela de outros sistemas de banco de dados de várias maneiras. Isso permite uma recuperação de dados mais rápida, bem como melhor gerenciamento e armazenamento de dados. Além disso, devido à capacidade do banco de dados para um número maior de dados, ele é capaz de escalar.
Devido ao seu enorme poder, o MongoDB possui diversos recursos que não são encontrados em outros sistemas de banco de dados. Como resultado, é um método muito eficiente para análise e armazenamento de dados.
Função Join do Mongodb
O MongoDB permite que você combine duas coleções em um banco de dados, que é um recurso extremamente popular. A sintaxe de junção do MongoDB é mais poderosa que a do SQL Server e a operação de junção é mais eficiente.
No entanto, o MongoDB não oferece suporte a junções de consulta entre coleções. No MongoDB, a função de agregação $lookup pode ser usada para realizar operações de junção.
Por que você não deve usar Nosql?
A plataforma NoSQL também não suporta operações dinâmicas. Não há garantia de que as propriedades ácidas serão constantes. Você pode optar por bancos de dados SQL se estiver lidando com dados confidenciais, por exemplo. Além disso, se você precisar de flexibilidade de tempo de execução, evite o NoSQL.
O banco de dados NoSQL é otimizado para uma área de armazenamento menor e menos CPU e memória quando comparado ao banco de dados NoSQL. Também é menos flexível e mais eficaz para usar em escala. Várias coleções do mesmo tipo de dados são afetadas pela estrutura de dados anormal. Como resultado, o número de índices e nós de sincronização é aumentado, o que aumenta o volume de dados e, portanto, o tempo gasto para atualizá-los. Os servidores NoSQL tradicionais destinam-se a manter a consistência eventual, portanto, nenhuma alteração precisa se propagar por meio de índices ou nós antes de serem feitas. Alguns membros NoSQL podem ocultar a criação de novos índices (por exemplo, RavenDB cria índices automáticos). Outros podem verificar todo o banco de dados MongoDB sem precisar indexá-lo.

Se um banco de dados NoSQL for usado, ele deve ser projetado para atender aos padrões de acesso. Se forem desconhecidos ou mudarem com frequência, pode ser necessário alterá-los. Os bancos de dados NoSQL orientados a documentos não são destinados ao consumo atômico, pois os sistemas OLAP devem dividir e dividir seus dados. A opção To Be Continued pode ser usada para resolver problemas de integridade de dados em NoSQL (exceto NoSQL baseado em gráfico). O Amazon DynamoDB estava um pouco atrasado no jogo, pois só se tornou compatível com ACID no ano passado.
Existem algumas desvantagens nos bancos de dados NoSQL, incluindo a incompatibilidade das instruções SQL com os bancos de dados NoSQL e sua falta de suporte para problemas de desempenho relacionados aos dados de desempenho. Além disso, os bancos de dados noSQL não seguem as mesmas especificações dos bancos de dados relacionais, dificultando a localização e o uso de softwares compatíveis.
Bancos de dados Por que os bancos de dados SQL são melhores que o Nosql
É mais estável e rápido usar bancos de dados SQL do que um banco de dados nosql.
Equivalente de Junção Nosql
Não há equivalente direto de uma junção no nosql, mas existem algumas maneiras de obter um resultado semelhante. A maneira mais comum é desnormalizar seus dados, o que significa que você duplica dados em vários documentos. Isso pode ser feito manualmente ou você pode usar uma ferramenta como o MongoMapper, que cuidará disso para você. Outra maneira de fazer isso é usar map/reduce, que é um pouco mais complicado, mas pode ser mais flexível.
Juntando-se a um banco de dados relacional
Quais são as semelhanças entre as operações de junção no banco de dados relacional?
As junções SQL em um banco de dados relacional são semelhantes às operações de pipeline, pois executam operações de consulta, filtro e grupo.
Junções do Mongodb
Junções do MongoDB são uma maneira de o MongoDB unir duas coleções de dados. Isso é útil quando você precisa combinar dados de várias coleções para criar um único resultado. Por exemplo, você pode usar uma junção para combinar dados de uma coleção de usuários com uma coleção de suas postagens.
O banco de dados NoSQL de software livre MongoDB é uma excelente opção para armazenar uma grande quantidade de dados. A principal diferença entre os bancos de dados tradicionais e o MongoDB é o uso de tabelas e linhas em vez de coleções e documentos. Os pares chave-valor são uma das unidades mais fundamentais do MongoDB. Neste blog, mostraremos como usar MongoDB Joins, que são os principais tipos de Joins e Lookups. O MongoDB 3.2 introduz uma nova operação Lookup que pode realizar operações Join em Collections. A sintaxe para subconsultas correlacionadas é simples de usar no MongoDB 5.0 em diante. Existem algumas restrições e limitações que devem ser seguidas ao usar MongoDB Joins.
Como exemplo, o trecho a seguir cria Coleções contendo restaurantes e pedidos usando os seguintes documentos: restaurantes. Os pedidos devem ser feitos para ambas as coleções. Qual é o nome do restaurante e seu endereço? É necessário fornecer um nome, bem como uma correspondência de matriz entre os pedidos. Na seguinte ordem, você encontrará uma bebida e uma bebida. Os seguintes resultados serão fornecidos.
Bancos de dados Nosql
Bancos de dados Nosql são bancos de dados que não usam o modelo relacional tradicional usado pela maioria dos bancos de dados. em vez disso, eles usam uma abordagem sem esquema mais flexível. Isso os torna mais escaláveis e fáceis de trabalhar para muitos aplicativos.
Os dados em bancos de dados NoSQL são armazenados em documentos e não em bancos de dados relacionais. Seus recursos incluem flexibilidade, escalabilidade e capacidade de atender aos requisitos de gerenciamento de dados que mudam rapidamente. Bancos de dados de documentos, armazenamentos de valores-chave, bancos de dados de colunas largas e bancos de dados de gráficos são exemplos de bancos de dados NoSQL. As organizações globais 2000 estão adotando rapidamente bancos de dados NoSQL para potencializar aplicativos de missão crítica. A razão para isso é que existem cinco tendências que são muito difíceis de lidar para a maioria dos bancos de dados relacionais. Um banco de dados relacional, ao contrário de um banco de dados MongoDB, não pode ser usado no desenvolvimento ágil porque é baseado em um modelo de dados fixo. O modelo de aplicativo define o modelo de dados ao usar NoSQL.
O NoSQL não impõe nenhum método fixo na modelagem dos dados. Um banco de dados orientado a documentos geralmente é armazenado em JSON como um formato de fato para armazenar dados. Nesse caso, os frameworks ORM não são mais necessários porque não há sobrecarga. N1QL (pronuncia-se níquel) foi introduzido no Couchbase Server 4.0 como uma poderosa linguagem de consulta que pode ser usada para estender SQL para JSON. Ele não apenas suporta instruções SELECT / FROM / WHERE padrão, mas também pode suportar agregação (GROUP BY), classificação (SORT BY), junções (LEFT OUTER / INNER) e assim por diante. Uma das principais vantagens de um banco de dados distribuído NoSQL é sua arquitetura escalável e nenhum ponto único de falha. À medida que mais interações com clientes são realizadas on-line por meio de aplicativos móveis e da Web, a disponibilidade de serviços está se tornando uma consideração cada vez mais importante.
Os bancos de dados NoSQL são simples de instalar, configurar e dimensionar, tornando-os ideais para uma variedade de aplicativos. Eles foram projetados para organizar o conteúdo de um livro, escrever uma nota e armazená-la. Também pode ser usado em qualquer tamanho – de pequenos clusters a grandes clusters. Nenhum software separado é necessário para executar um banco de dados NoSQL; ele é distribuído e inclui replicação integrada entre datacenters. Além disso, permite failover imediato por meio de roteadores de hardware para que os aplicativos não precisem esperar que o banco de dados descubra a falha e execute sua própria recuperação. A popularidade do NoSQL está aumentando, tornando-o a tecnologia de banco de dados mais popular para os aplicativos atuais da Web, móveis e Internet das Coisas (IoT).
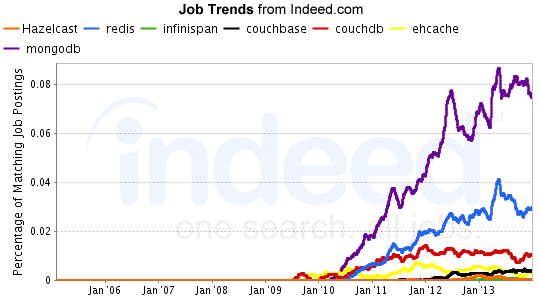
O MongoDB é o líder claro em uma variedade de métricas importantes.
Se você está procurando um banco de dados com alto nível de popularidade e estabilidade, o MongoDB é o caminho certo. Muitos aplicativos o preferem porque possui um grande número de recursos que o tornam um dos bancos de dados mais populares do mercado. Como o MongoDB não oferece suporte a transações ACID, pode ser benéfico manter isso em mente ao tomar uma decisão.
Bancos de dados Nosql: uma visão geral
Os bancos de dados NoSQL baseados em documentos podem armazenar dados nos formatos JSON e XML. Este é um banco de dados NoSQL baseado em documento com um modelo de armazenamento baseado em coluna. Os dados em bancos de dados NoSQL de valor-chave são armazenados em pares. O banco de dados Redis NoSQL é um excelente exemplo de banco de dados chave-valor. Os bancos de dados SQL geralmente contêm colunas maiores que as dimensões dos bancos de dados NoSQL. O MongoDB, um exemplo de banco de dados NoSQL de coluna larga, é um banco de dados NoSQL popular. Os dados são armazenados em gráficos usando um banco de dados NoSQL baseado em gráfico. Neo4j é um banco de dados NoSQL baseado em gráfico que usa MongoDB.
Banco de Dados Oracle Nosql
Um banco de dados Oracle NoSQL é um banco de dados de valor-chave distribuído projetado para fornecer alta disponibilidade e escalabilidade horizontal com pouca ou nenhuma administração de banco de dados. O banco de dados Oracle NoSQL é baseado no Berkeley DB Java Edition e usa um modelo de valor-chave simples com um rico conjunto de tipos de dados.
O módulo de implementação do Spring Data para Oracle NoSQL SDK para Spring Data é integrado ao SDK. Ele pode ser usado para se conectar a um cluster Oracle NoQL Database ou ao Oracle NoQL Cloud Service. Ao incorporar a dependência do maven ao arquivo pom.xml do seu projeto, você pode usar o SDK. Seria conveniente se você pudesse selecionar o seguinte como ponto de partida. O Oracle Spring está disponível em Oracle.com. Os métodos usados em NosqlDbConfig são os seguintes. A classe de entidade deve ser definida.
O repositório deve ser criado para armazenar dados Nosql . Em seguida, escreva a classe principal do aplicativo. Ao instalar org.springframework.boot:spring-boot, você pode obter acesso a todos os componentes.