
Bancos de dados NoSQL: tabela grande
Publicados: 2023-01-04Os bancos de dados NoSQL estão se tornando cada vez mais populares devido à sua flexibilidade, escalabilidade e desempenho. Um banco de dados NoSQL não requer um esquema predefinido e pode armazenar dados em qualquer formato. Isso o torna ideal para aplicativos que precisam armazenar grandes quantidades de dados que estão em constante mudança. Big table é um tipo de banco de dados NoSQL projetado para armazenar grandes quantidades de dados. Big table é usado por muitas grandes organizações, como Google, Facebook e Amazon. A tabela grande é altamente escalável e pode lidar com bilhões de linhas e milhões de colunas. A tabela grande também é muito rápida e pode fornecer acesso em tempo real aos dados.
O Google lançou uma série de atualizações geralmente disponíveis para seu serviço de banco de dados Cloud Bigtable . Como resultado das novas atualizações, até cinco vezes mais espaço de armazenamento está disponível por nó. O Google também adicionou recursos aprimorados de dimensionamento automático que permitem que um cluster de banco de dados cresça ou diminua automaticamente com base em suas necessidades. Uma nova métrica de utilização de CPU e roteamento de grupo de cluster permitem mais visibilidade sobre como os recursos de um aplicativo são usados. Devido à separação de computação e armazenamento, cada tipo de recurso pode ser dimensionado por conta própria no Bigtable. Os usuários agora podem gerenciar facilmente implantações de alta disponibilidade e melhorar o gerenciamento da carga de trabalho graças aos novos recursos.
NoSQL é uma escolha popular para armazenar grandes quantidades de dados. Atualmente, esse tipo de banco de dados está se tornando cada vez mais popular entre as empresas da web. Os defensores das soluções NoSQL dizem que oferecem escalabilidade mais simples e maior desempenho do que os bancos de dados tradicionais.
Bigtable é um tipo de serviço de banco de dados NoSQL que pode ser usado por desenvolvedores e administradores de banco de dados. O BigQuery é híbrido, porque usa dialetos SQL e é baseado na tecnologia de processamento de dados do Google, Dremel.
Bigtable SQL ou Nosql?
Não há uma resposta definitiva para essa pergunta, pois depende de como você define cada termo. No entanto, se considerarmos uma definição ampla de SQL como qualquer banco de dados que usa uma linguagem de consulta estruturada e NoSQL como qualquer banco de dados que não usa uma linguagem de consulta estruturada, o Bigtable seria considerado um banco de dados NoSQL.
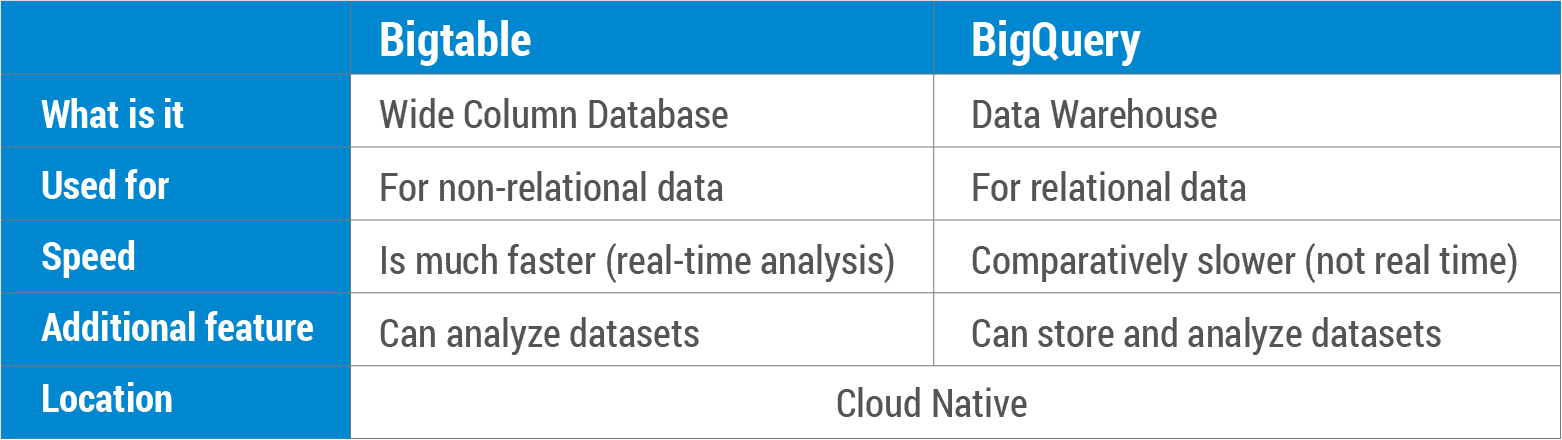
O que é uma comparação entre Bigtable e BigQuery? Bigtable é um banco de dados NoSQL que permite armazenar dados de maneira segura e escalável. O BigQuery é um data warehouse relacional que armazena grandes quantidades de dados em um banco de dados SQL. O Bigtable foi integrado aos produtos do Google, como Analytics, Finance, Pesquisa personalizada, Earth e Writely para suas operações diárias. Bigtable, um banco de dados NoSQL de dados mutáveis , funciona bem com cenários OLTP. O BigQuery é um data warehouse SQL relacional que pode ser usado para aplicativos OLAP. Tanto o Bigtable quanto o BigQuery são nativos da nuvem, com acordos de nível de serviço líderes do setor. Além disso, eles oferecem backup automático (com replicação), bem como escalabilidade infinita, sharding automático e recuperação automática de falhas (com replicação).
O BigQuery, em vez de um banco de dados NoSQL, não faz isso.
Que tipo de banco de dados Nosql é o Bigtable?
O Cloud Bigtable é um banco de dados NoSQL que pode ser usado para analisar dados e executar operações. É uma alternativa ao HBase, que é um sistema de banco de dados colunar usando HDFS. Aplicativos com largura de banda inferior a 10 MB são adequados para Cloud Bigtable, que pode oferecer suporte a um alto nível de taxa de transferência e escalabilidade.
Os bancos de dados Big Table, como são conhecidos, são um subconjunto dos bancos de dados NoSQL. O Bigtable, um aplicativo do Google, é semelhante ao Kleenex. Os bancos de dados Bigtable são o padrão da indústria para imitação e inspiração. Embora o artigo se preocupe principalmente com o Bigtable, ele também analisa outros bancos de dados NoSQL. O Bigtable foi projetado principalmente para uso interno do Google, sem acesso externo. O Bigtable foi apresentado ao Google em 2004 e desde então tem sido usado por mais de 60 aplicativos do Google. Uma implementação do Bigtable requer um servidor mestre para acompanhar os tablets em um cluster de outros servidores.
A Apache Software Foundation contribuiu para várias iniciativas técnicas excelentes, particularmente no campo de bancos de dados. Accumulo e HBase empregam os mesmos princípios de design do Google Bigtable, mas em um formato disponível comercialmente. Atualmente, o Apache HBase executa o sistema de mensagens do Facebook e está totalmente integrado ao Hadoop, permitindo o processamento de grandes conjuntos de dados. O banco de dados Hypertable é baseado no Bigtable, que é um banco de dados tabular simples. O Hypertable é executado da mesma forma que o Hadoop e o HFS. O Baidu, um dos maiores mecanismos de busca da China, é um dos principais patrocinadores da Hypertable. Os clientes incluem sites de leilões online, como eBay, Groupon e Rediff.com, bem como varejistas offline, como Lowe's e TJ Maxx.
O Hadoop é uma plataforma de software de código aberto que permite aos usuários armazenar e processar grandes quantidades de dados de maneira eficiente. Isso permite bancos de dados NoSQL, que podem reduzir a quantidade de dados necessários para armazenamento em servidores únicos. Um banco de dados NoSQL, por outro lado, não requer um esquema fixo porque é baseado em escalabilidade. Por causa disso, eles são uma excelente opção para armazenar grandes quantidades de dados de maneira distribuída.
Em que tipo de armazenamento de dados Nosql o Bigtable se encaixa?
Um dos poucos recursos disponíveis no mercado de genéricos. Em seu nível mais básico, o Bigtable é um banco de dados NoSQL que abrange uma ampla variedade de colunas.
O Bigtable é um banco de dados colunar?
Armazenamentos de colunas largas, como Bigtable e Apache Cassandra, não são colunas no sentido tradicional do termo porque não usam estruturas de dados colunares nos dois níveis.
O Bigtable é um banco de dados não relacional?
Não há uma resposta definitiva para essa pergunta, pois depende de como você define um “banco de dados não relacional”. O Bigtable é um armazenamento de dados orientado a colunas, que algumas pessoas consideram um tipo de banco de dados NoSQL. No entanto, ele tem suporte para transações e indexação, que normalmente são associadas a bancos de dados relacionais. Portanto, realmente depende de como você define um banco de dados não relacional.
A instrução CREATE EXTERNAL TABLE pode ser usada para criar uma tabela no BigQuery especificando uma tabela da qual extrair dados. A opção uri pode ser usada para especificar uma tabela da qual extrair dados. O esquema da tabela inclui o nome da tabela, o tipo da tabela, os nomes das colunas e os tipos de dados, bem como o esquema da tabela da opção bigtable_options.
Se você usa MySQL, a ferramenta de importação do BigQuery pode ser usada para importar dados de uma tabela MySQL automaticamente para o BigQuery. Um nome de tabela e um grupo de colunas são inseridos na ferramenta, que importa os dados para uma tabela do BigQuery.
Ao usar o console do Google Cloud, você deve inserir manualmente o nome da tabela e os parâmetros de qualificação do grupo de colunas. A importação de dados de várias fontes é possível na plataforma Google Cloud, incluindo MySQL, PostgreSQL, MongoDB e Redis.
Principais recursos do Bigtable
Quais são alguns dos recursos do Bigtable?
A velocidade de leitura e gravação do Bigtable, sua enorme escalabilidade e a capacidade de lidar com grandes quantidades de dados são apenas alguns de seus muitos recursos. Além disso, como o Bigtable é um banco de dados NoSQL, as consultas SQL não são suportadas. Isso elimina a necessidade de operações SQL serem executadas em bancos de dados separados.
O Bigtable é um banco de dados?
O Bigtable não é um banco de dados relacional. É um sistema de armazenamento distribuído para gerenciamento de dados estruturados projetado para escalar para um tamanho muito grande: petabytes de dados em milhares de servidores comuns. O Google usa o Bigtable para alimentar muitos de seus serviços de grande escala, como o Google Analytics e o Google Maps.
O Cloud BigTable fornece um conjunto exclusivo de recursos, permitindo escalar para mais de 100.000 colunas e bilhões de linhas. Ele suporta o armazenamento de aproximadamente petabytes e terabytes de dados. Em comparação com o BigTable, tem latência muito baixa, mas também tem potencial para armazenar uma grande quantidade de dados. O BigTable pode armazenar dados estruturados em colunas, permitindo que ele manipule serviços da Web e dados de pesquisa na Internet da empresa. Algoritmos de compressão também são usados para aumentar a capacidade do sistema. O BigTable tem servidores de back-end impactantes que oferecem vantagens melhores do que a instalação autogerenciada do HBase incluída no BigTable. As linhas na BigTable compartilham a mesma borda, portanto, também são chamadas de blocos.
Esses dispositivos, chamados de 'tablets', ajudam você a gerenciar sua carga de trabalho de consulta. O sistema de arquivos baseado em nuvem do Google Colossus é usado para armazenar todos os tablets. Todas as operações de gravação no BigTable são armazenadas no log compartilhado do Colossus, assim como os arquivos SSTable. Os sete recursos principais do BigTable são essenciais para o sucesso de uma empresa. O BigTable tem o potencial de personalizar, acelerar e automatizar sua vida de várias maneiras. linhas e colunas são as duas dimensões de dados no BigTable. Cada linha contém um identificador ou índice exclusivo que pode ser acessado usando a chave de linha única.
Cada uma das colunas em uma família tem uma coluna de qualificação. O uso de unidades de qualificação de coluna, como chaves de linha, auxilia na identificação da coluna. Quando se trata de bancos de dados, o BigTable é conhecido como esparso. Cada uma das versões de timestamp do BigTable é representada por uma célula, que é uma das dimensões dentro da estrutura do mapa 3D. Esse poderoso banco de dados, que pode ser personalizado e sensível à velocidade, pode ser usado para alimentar sites e aplicativos móveis. Se você pensar no passado, poderá descobrir quais interações produziram os melhores resultados. Isso ajudará você a implementar mais análises de dados e levará a um melhor atendimento ao cliente.
O Google Cloud Bigtable, um banco de dados NoSQL de código aberto, é integrado à nuvem do Google. O fato de ser compatível com tantos ecossistemas existentes de big data e Hadoop significa que pode ser usado para dados não estruturados ou dados que precisam de baixa latência.
Bigtable: uma excelente escolha para aplicativos com uso intensivo de dados
O Bigtable, um serviço de banco de dados NoSQL, é usado para grandes cargas de trabalho analíticas e operacionais. Como resultado, é uma excelente escolha para aplicativos de tempo real e com uso intensivo de dados. Além disso, por ser orientado a colunas, é ideal para armazenar dados em três dimensões.
Bigtable x Mongodb
Existem algumas diferenças importantes entre o Bigtable e o MongoDB. Primeiro, o Bigtable é um banco de dados orientado a colunas, enquanto o MongoDB é um banco de dados orientado a documentos. Isso significa que no Bigtable, os dados são armazenados em colunas, enquanto no MongoDB, os dados são armazenados em documentos. Em segundo lugar, o Bigtable não suporta índices secundários, enquanto o MongoDB suporta. Isso significa que, se você deseja consultar dados no Bigtable, precisa conhecer a coluna específica que deseja consultar. No MongoDB, você pode consultar qualquer campo em um documento. Por fim, o Bigtable foi projetado para escalar horizontalmente, enquanto o MongoDB foi projetado para escalar verticalmente. Isso significa que no Bigtable você pode adicionar mais máquinas ao seu cluster para aumentar a capacidade, enquanto no MongoDB você pode adicionar mais RAM e CPU ao seu servidor para aumentar a capacidade.
Cloud Bigtable do Google: não apenas para big data
O Bigtable ainda é um componente da infraestrutura do Google, tendo sido criado em 2007. Embora o Cloud Bigtable seja ideal para armazenar grandes quantidades de dados com baixa latência, não é ideal para dados que não exijam acesso frequente. O Cloud Bigtable, por exemplo, não seria uma boa opção para um data lake.
banco de dados Bigtable
Um banco de dados bigtable é um banco de dados que usa uma estrutura de dados bigtable . Um bigtable é um sistema de armazenamento distribuído para dados estruturados projetado para escalar para um tamanho muito grande.
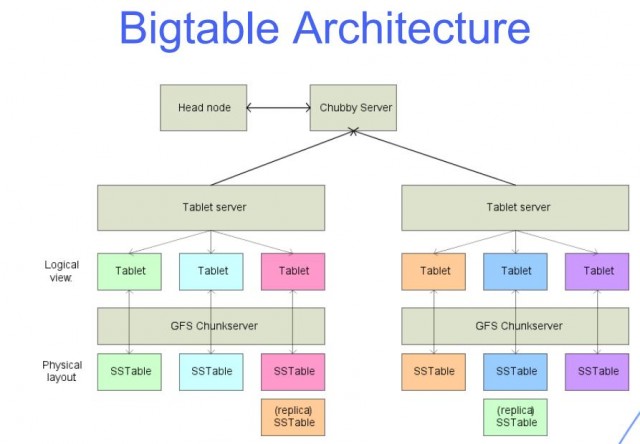
Uma tabela grande é aquela que tem muitas linhas e colunas e geralmente é preenchida de forma esparsa. O Bigtable é ideal para grandes conjuntos de dados devido à sua baixa latência e alta densidade. Essa fonte de dados é ideal para operações de MapReduce porque suporta alta taxa de transferência de leitura/gravação em baixa latência e é ideal para grandes conjuntos de dados. Os dados de uma tabela Bigtable são fragmentados em blocos de linhas contíguas, cada uma delas chamada de tablet, para reduzir a carga de consulta. O formato SSTable é usado para armazenar tablets do Google no Colossus, o sistema de arquivos da empresa. Cada tablet está vinculado a um nó específico na instância do Bigtable, também conhecido como nó. Adicionar nós a um cluster pode aumentar a capacidade do cluster de lidar com várias solicitações simultâneas.
Cada linha contém uma combinação da família de colunas, o identificador de coluna e o registro de data e hora, essencialmente uma matriz de entradas de chaves/valores. Na grande maioria das vezes, o Bigtable converte todos os dados em strings de bytes brutos. Como o Bigtable armazena mutações sequencialmente e as compacta apenas uma vez a cada poucos meses, as mutações ocupam mais espaço de armazenamento quando são alteradas para uma linha. O Bigtable comprime dados usando um algoritmo inteligente e emprega tecnologia de compressão. Como as deleções são um tipo especializado de mutação, elas precisam de espaço de armazenamento extra a curto prazo. Os métodos de armazenamento proprietários do Google permitem que ele resista ao teste do tempo para dados além do alcance da replicação HDFS de três vias padrão. Os usuários podem acessar suas tabelas do Bigtable usando as funções atribuídas a eles por seu projeto do Google Cloud e pelo gerenciamento de identidade e acesso (IAM). A maioria dos dados do Google Cloud é criptografada em repouso usando os mesmos sistemas de gerenciamento de chaves reforçados que usamos em nossos dados criptografados. Um backup pode ser usado para salvar uma cópia do esquema e dos dados da tabela, bem como para restaurar o backup em uma nova tabela posteriormente.
O Bigtable é um sistema de armazenamento distribuído e bem projetado, capaz de armazenar até petabytes de dados. Por ser simples de usar, é uma excelente opção para armazenamento de dados em larga escala .

O poder do Cloud Bigtable
O banco de dados Cloud Bigtable tem capacidade para armazenar dezenas de milhares de linhas e colunas e pode ser acessado de qualquer lugar do mundo. Como resultado, é adequado para armazenamento de dados em grande escala. O Cloud Bigtable agora está disponível no Google Cloud desde 6 de maio de 2015. Isso resultou em mais de 10 EXAbytes de dados sendo atendidos e mais de 5 bilhões de solicitações sendo processadas por segundo desde então. Como resultado, o Cloud Bigtable ainda está em uso e é uma ferramenta valiosa para armazenamento de dados.
Bigtable x Cassandra
Cada nó é escolhido para operações de leitura e gravação usando seu próprio método. No Cassandra, uma chave de partição é identificada, enquanto no Bigtable, uma chave de linha é usada. A política de balanceamento de carga do Cassandra é inspecionada primeiro pelo cliente.
Sistemas de banco de dados como Bigtable e Cassandra são distribuídos. Eles criam armazenamentos de valores-chave multidimensionais que podem processar dezenas de milhares de consultas por segundo (QPS). O objetivo deste documento é explicar as diferenças e semelhanças entre os dois sistemas de banco de dados. O Bigtable contém muitos dos principais recursos descritos no Bigtable. O artigo descreve um sistema de armazenamento distribuído para dados estruturados. Quando o Bigtable identifica a atribuição de intervalo conforme necessário para um conjunto de dados, os intervalos de dados para um nó de processamento são simples de alterar porque a camada de armazenamento é separada da camada de processamento. Além disso, o Bigtable permite a replicação assíncrona entre clusters distribuídos geograficamente em topologias de até quatro.
A tolerância a falhas é fornecida pelo Cassandra, que está correlacionada com o nível de consistência. Usando uma estratégia de topologia de replicação de dados configurável, você pode definir a replicação geográfica. Na maioria das topologias de vários centros de dados, QUORUM (ou LOCAL_QUORUM) é a configuração padrão. A maioria de resposta de um nó de réplica ao nó coordenador é necessária para que essa configuração de nível seja considerada bem-sucedida. As réplicas de dados no Cassandra podem ser aprimoradas em termos de tolerância a falhas usando configurações de data center e rack. A topologia determina quais nós são necessários para garantir a consistência durante as operações de leitura e gravação. A instância do Bigtable pode ter um ou mais clusters ou pode ter uma coleção de até quatro clusters replicados.
Bigtable e Cassandra funcionam como armazenamentos de colunas largas NoSQL. A chave de linha determina a ordem na qual a classificação de dados globais de uma tabela é exibida no Bigtable. No Bigtable, os nós são usados para equilibrar a responsabilidade por intervalos de chave, que são comumente chamados de tablets. O serviço Bigtable não impõe tipos de dados de coluna que o cliente envia. A família de colunas Bigtable seleciona quais colunas em uma tabela devem ser armazenadas e recuperadas de uma para a outra. Cada tabela deve ter pelo menos um grupo de colunas, mas as tabelas frequentemente têm mais (o número máximo de colunas que uma tabela pode ter é 100). Uma chave de linha está localizada em uma célula e um nome de coluna está localizado na outra.
Cassandra e Bigtable usam métodos diferentes para escolher o nó de processamento para operações de leitura e gravação. No Cassandra, a chave de partição é diferenciada, enquanto no Bigtable, a chave de linha é usada. Ao criar uma política de vários clusters, uma política de balanceamento de carga que reconhece os datacenters fornece os benefícios do failover. Ambos os bancos de dados foram otimizados para gravação rápida e usam um processo semelhante para fazer isso. Ambos os bancos de dados armazenam dados em arquivos SSTable, que são arquivos imutáveis. No Cassandra, várias réplicas devem ser contatadas antes que o coordenador informe ao cliente que a escrita foi concluída. Como cada chave de linha no Bigtable é atribuída apenas a um nó, é necessária uma resposta desse nó para confirmar que uma gravação foi bem-sucedida.
Como resultado da fusão SSTable, ambos os bancos de dados podem excluir células. Ao retornar dados para Cassandra, a cláusula WHERE em uma consulta CQL restringe o número de linhas. Somente o nó responsável pelo intervalo de chaves precisa ser consultado ao usar o Bigtable. Os resultados da leitura de um nó podem ser limitados de várias maneiras. Durante uma fase de compactação, Bigtable e Cassandra armazenam dados em SSTables, que são mesclados regularmente. O Bigtable não limita o número de versões de timestamp para cada célula, mas outros tamanhos de linha podem. A replicação fornecida pelo Colossus garante alta durabilidade dos dados.
A interface de linha de comando do Bigtable, bem como suas bibliotecas de cliente para uma variedade de linguagens de programação comuns, complementam os recursos do Cassandra. Cada nó do Bigtable deve atender a uma série de SSTables contendo dados armazenados nessas tabelas. Você não precisa mais calcular as réplicas de armazenamento no Bigtable da mesma forma que faria no Cassandra ao determinar o tamanho do cluster. As instâncias do Bigtable geralmente armazenam dados em unidades de estado sólido (SSDs) ou discos rígidos (HDDs). Ao contrário do Cassandra, que se baseia na teoria de que não há perda de densidade de armazenamento para atingir a tolerância a falhas, a carga de trabalho não perde densidade. É simples escalar uma instância do Bigtable para cima ou para baixo conforme necessário para atender aos requisitos de carga de trabalho, mantendo o mínimo de esforço e tempo de inatividade. Uma instância pode ter apenas quatro clusters, mas eles podem ser agrupados em qualquer região de nuvem suportada no planeta.
Para criar uma métrica para o pernode QPS, o Google recomenda usar o desempenho do Bigtable com dados e consultas representativos. O Bigtable inclui componentes gerenciados para funções comuns de administração do Cassandra. Uma tabela que faz parte do cluster é criada como uma cópia restaurável da tabela em um backup bigtable. O preço de um backup é menor que o do Cloud Storage ou não consome recursos do nó. Outra opção é usar uma exportação de dados gerenciados para o Cloud Storage para fazer backup do Bigtable. O Bigtable gerencia tarefas comuns de manutenção interna do Cassandra, como correção do sistema operacional, recuperação de nós, reparo de nós, monitoramento de compactação de armazenamento e rotação de certificados SSL com facilidade. Os painéis são pré-criados para rastrear as métricas de taxa de transferência e utilização nos níveis de instância, cluster e tabela na página do console Bigtable Google Cloud. Você pode usar o painel de monitoramento para conduzir o ajuste de desempenho avançado.
O SQL é usado no Bigtable, assim como o acesso de chave de linha aos dados em um banco de dados NoSQL. Os nós são distribuídos pela rede e a fofoca é usada para manter a consistência da rede. Com este sistema, a capacidade de armazenamento de dados é aumentada e a disponibilidade é mantida sem um único ponto de falha.
O Bigtable, por outro lado, é mais escalável e oferece um maior nível de disponibilidade do que o Cassandra. O Bigtable também é mais fácil de usar do que outras linguagens de programação, tornando-o uma excelente opção para conjuntos de dados com menos recursos.
O Google ainda usa o Bigtable?
Google Analytics, indexação da web, MapReduce e muitos outros aplicativos do Google, como Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code hosting, use-o para gerar e modificar dados armazenados no Bigtable, Google Maps , Google Livros, Minha pesquisa
O Google usa Cassandra?
A topologia DataStax Astra Cassandra as a Service foi implantada no Google Cloud usando o sistema operacional TensorFlow, bem como usando o sistema operacional Apache Cassandra em três zonas do Google Cloud.
Bigtable é o mesmo que Hbase?
Um registro de data e hora do Bigtable é armazenado em microssegundos, enquanto um registro de data e hora do HBase é armazenado em milissegundos. Essa distinção pode ser útil ao usar a biblioteca de cliente HBase para Bigtable e observar carimbos de data/hora invertidos.
Para que serve o Bigtable?
O banco de dados Bigtable NoSQL é um banco de dados de coluna ampla ideal para uso em um banco de dados NoSQL. O sistema é otimizado para fornecer baixa latência, um grande número de leituras e gravações e alto desempenho em escala. O uso de casos de tabela geralmente é limitado a uma escala ou taxa de transferência específica que exige alta latência, como Internet das Coisas (IoT), AdTech, FinTech e assim por diante.
Bigtable x Bigquery
Existem algumas diferenças importantes entre bigtable e bigquery. O Bigtable foi projetado para ser um banco de dados dimensionável e orientado a colunas, enquanto o bigquery foi projetado para ser um banco de dados relacional escalável. Bigtable não suporta SQL, enquanto bigquery sim. O Bigtable não é tão usado quanto o bigquery, mas tem algumas vantagens em relação ao bigquery, como a capacidade de escalar para um número maior de colunas e linhas.
O Google fez progressos significativos no armazenamento em nuvem de dados massivos ao longo dos anos. O Bigtable é um serviço de banco de dados NoSQL totalmente gerenciado em escala de petabytes, baseado em Object Oriented Database Administration (OOPA). O BigQuery é construído usando o Bigtable e o Google Cloud Platform, bem como o sistema de banco de dados Dremel do Google. Existem três diferenças principais entre o BigQuery e o Bigtable. Uma solução de Big Data como serviço (BaaS) é aquela fornecida pelo Google Cloud BigQuery. O BigQuery é usado por produtos do Google, como Analytics, Finanças, Pesquisa personalizada, Earth, Orkut e Writely. Quando o processamento de dados extremamente rápido do BigQuery é usado, 35 bilhões de linhas podem ser processadas em questão de segundos.
Um banco de dados NoSQL é um acrônimo para um serviço de banco de dados; em outras palavras, não é um banco de dados relacional. As colunas-chave podem ter vários tamanhos e as barras-chave podem ser roladas horizontalmente. Elementos de dados individuais com uma capacidade de armazenamento maior de 10 megabytes podem prejudicar o desempenho. Se você precisa de uma solução de armazenamento abrangente para objetos não estruturados (por exemplo, arquivos de vídeo), o armazenamento em nuvem provavelmente será uma opção melhor. É uma escolha excelente para consultas que exigem uma varredura de tabela ou para examinar um banco de dados grande de uma só vez. É impossível que um objeto enviado mude ao longo de sua vida útil no BigQuery, e seus dados são sempre imutáveis. As tabelas dentro de um bigtable armazenam dados escalonáveis que foram classificados em mapas de chaves/valores classificados por chave, linha e carimbo de data/hora.
Com o Integrate.io, você pode automatizar um processo de ETL e integração de dados para vincular suas fontes de dados e data warehouses na nuvem. A plataforma de integração inclui mais de 100 integrações pré-criadas, incluindo BigQuery, e uma interface de arrastar e soltar que torna o gerenciamento de seus processos de integração mais fácil do que nunca. Entre em contato com nossa equipe de especialistas em dados para discutir sua situação ou para iniciar um piloto de 14 dias da plataforma Integrate.
O Google BigQuery se destaca em termos de recursos, apesar do MySQL ainda ser amplamente utilizado. Isso é especialmente verdadeiro para recursos comumente usados em aplicativos de negócios, como importação e exportação de dados, análise de dados e federação de dados. O MySQL, por outro lado, possui apenas 28 recursos, o que significa que pode não ser capaz de atender às necessidades de muitas empresas. O Google BigQuery é baseado em nuvem, permitindo que seja acessado de qualquer local com conexão à Internet. O MySQL, por outro lado, é executado em uma arquitetura cliente-servidor e não está disponível na nuvem.
Qual é a diferença entre Bigquery e Bigtable?
O Bigtable é um banco de dados NoSQL de colunas largas otimizado para leituras e gravações pesadas. Em contraste com o BigQuery, que é um data warehouse corporativo para grandes quantidades de dados relacionais, o Oracle Data Warehouse serve como um serviço de desduplicação.
O Bigquery é construído no Bigtable?
O Bigtable, um serviço de consulta baseado em nuvem desenvolvido em colaboração com o Google e a Microsoft, e o sistema Dremel do Google para consultas ad hoc logo seguiram, respectivamente.
Quando devo usar o Bigtable?
O Bigtable é ideal para aplicativos que exigem alta taxa de transferência e escalabilidade ao lidar com dados de chave/valor, com no máximo 10 MB de dados por valor. Os pontos fortes do Bigtable estão em operações de MapReduce em lote, processamento/análise de fluxo e aprendizado de máquina.
Serviço de banco de dados Nosql escalável
Um serviço de banco de dados nosql escalável é um tipo de banco de dados que pode lidar com dados em grande escala. É um serviço baseado na web que pode ser usado para armazenar e gerenciar grandes quantidades de dados. Esse tipo de banco de dados é projetado para ser escalável para que possa lidar com dados em grande escala.
Este tutorial pressupõe que você tenha um ambiente Node.js funcionando. Criei uma pasta chamada nodejs-dynamodb-sample para descompactar os arquivos do DynamoDB. A página GitHub do projeto é https://www.gofundme.com/adamfowleruk/nodesurvey.html. O aplicativo de amostra usa o DynamoDB para pesquisar e recuperar dados de filmes. Para armazenar dados no S3, usaremos o serviço de gerenciamento de identidade e acesso (IAM) da Amazon e, para acessar o DynamoDB na AWS, usaremos o serviço DynamoDB da Amazon. Para usar o serviço iADM da Amazon, você deve primeiro se registrar e criar um usuário. O título e o ano do filme podem ser adicionados à seção POST/movies da sua pesquisa.
Faça uma lista de filmes de um determinado ano inserindo o campo digitado. Agora você pode criar seu próprio aplicativo seguindo este exemplo básico. Se você pretende usar suas tabelas novamente, deverá excluí-las assim que terminar de usá-las, o que acarretará custos de hospedagem e serviço da AWS. Na AWS, acesse o console do DynamoDB e insira a quantidade de armazenamento que você usou. Você pode visualizar os itens em uma tabela clicando em 'Filmes', ver as métricas que vê em seu aplicativo e ver os custos mensais estimados clicando na guia Capacidade. Na minha página do GitHub, incluo uma amostra do código neste exercício: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Banco de dados Google Cloud Bigtable
O Google Cloud Bigtable é um serviço de banco de dados NoSQL rápido, totalmente gerenciado e em escala de petabytes, ideal para grandes cargas de trabalho analíticas e operacionais.
O armazenamento de dados do Google é mais adequado para aplicativos que precisam de respostas rápidas às solicitações do usuário.
No banco de dados Bigtable do Google, não há banco de dados relacional. Consultas SQL, junções e transações de várias linhas não são suportadas. Como resultado, se você estiver procurando por suporte de banco de dados padrão, não pode esperar. O Bigtable, por outro lado, não fornece uma grande quantidade de dados ou análises. A natureza otimizada do Bigtable se deve em parte a seus recursos analíticos e de manipulação de dados de alto desempenho. O armazenamento de dados, por outro lado, foi projetado para permitir que dados transacionais de alto valor sejam fornecidos aos aplicativos. Como resultado, o Datastore é mais adequado para aplicativos que exigem respostas rápidas às solicitações do usuário.