
Bancos de dados NoSQL: fragmentação e replicação
Publicados: 2022-11-21Os bancos de dados NoSQL são frequentemente usados para armazenamento de dados em grande escala devido à sua capacidade de dimensionar horizontalmente. Isso significa que eles podem escalar adicionando mais nós ao sistema, em vez de atualizar o hardware de um único nó. Uma maneira de alcançar essa escalabilidade horizontal é por meio de sharding, que é um processo de distribuição de dados em vários nós. A replicação é outra maneira pela qual os bancos de dados NoSQL podem ser dimensionados e envolve a criação de cópias de dados em vários nós.
Em bancos de dados SQL e NoSQL, o conceito de fragmentação do banco de dados é fundamental para o dimensionamento. O banco de dados é dividido em vários pedaços (shards) como o nome sugere.
Você também pode usar a replicação de dados NoSQL para garantir que não perderá dados quando um servidor travar, copiando e armazenando perfeitamente seus dados estruturados, não estruturados e semiestruturados. Você pode aprender mais sobre bancos de dados NoSQL visitando esta página.
Um banco de dados relacional pode ser particionado usando o método Sharding, também conhecido como partição horizontal. O Amazon Relational Database Service ( Amazon RDS ) é um serviço de banco de dados relacional gerenciado que simplifica o uso na nuvem, fornecendo uma variedade de recursos.
Um método de replicação copia dados de vários servidores e os coloca em um local onde possam ser encontrados. Na replicação, as cópias mestre e escrava são criadas, com as cópias mestre se tornando cópias autorizadas que lidam com dados gravados e as cópias escravas se tornando cópias assíncronas que lidam com dados gravados.
O Nosql usa sharding?
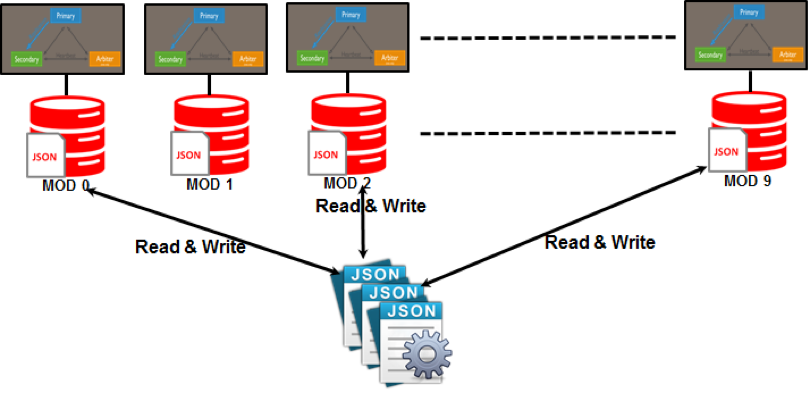
Padrões de partição, como compartilhamento, são usados no NoSQL. O particionamento é um processo que atribui cada partição a um servidor que provavelmente será independente do resto da rede. Com essa expansão, você pode fornecer aos usuários globais acesso a um conjunto diversificado de dados, mantendo o nível de desempenho o mais alto possível.
MySQL Cluster é a solução. O MySQL Cluster é um conjunto de software que fragmenta tabelas automaticamente entre os nós e permite que os bancos de dados sejam dimensionados horizontalmente em hardware de commodity de baixo custo para atender a cargas de trabalho intensivas de leitura e gravação usando SQL, bem como diretamente por meio de APIs NoSQL. MySQL Cluster tem potencial para ser usado para muito mais do que apenas blockchains. Ele também pode ser usado para dimensionar seus aplicativos usando MySQL Cluster. A razão para isso é que MySQL Cluster é um sistema de agendamento. Como resultado, você pode dimensionar seus aplicativos decidindo quando e como os shards serão gerados. Esta é uma grande vantagem porque você não precisa depender da computação em nuvem . Isso se deve ao fato de que os shards são produzidos nos nós onde a carga de trabalho está sendo executada. Como resultado, você pode controlar quanta simultaneidade é necessária. Como resultado, o MySQL Cluster possui um conjunto muito poderoso de recursos. Ele pode ser usado para dimensionar seus aplicativos e controlar quanta simultaneidade você precisa.
O que é sharding e replicação no Nosql?
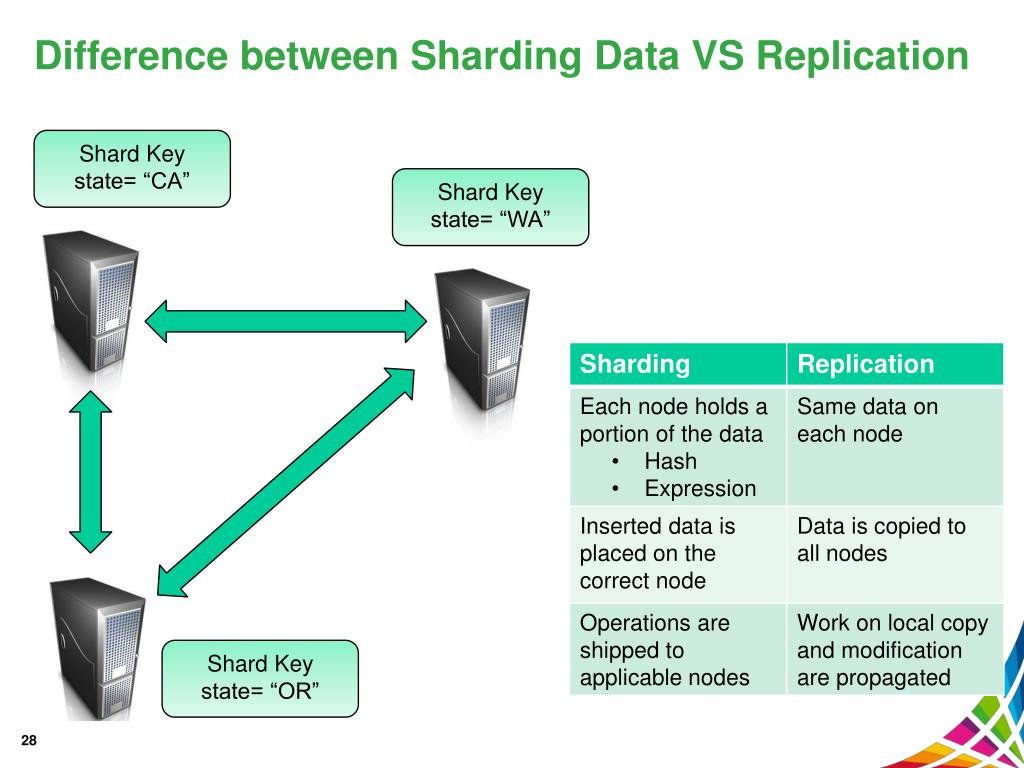
Qual é a diferença entre replicação e sharding? A replicação de dados é o ato de transferir dados do nó do servidor principal para os nós do servidor secundário . Como um backup em caso de falha do servidor principal, isso pode ajudar a garantir que os dados estejam disponíveis. Esta função pode ser usada para dimensionar servidores horizontalmente usando uma chave de fragmentação.
As vantagens da fragmentação
Quando você está lidando com dados que precisam ser particionados, mas carecem de recursos para replicá-los, o espaçamento pode ser benéfico em diversas situações. Quando você precisa dimensionar as leituras, a replicação é útil, mas as gravações de dados podem ser tratadas com mais eficiência com a fragmentação. Escolher a chave de fragmentação errada pode ter um impacto negativo no desempenho do sistema.
O Mongodb usa sharding?
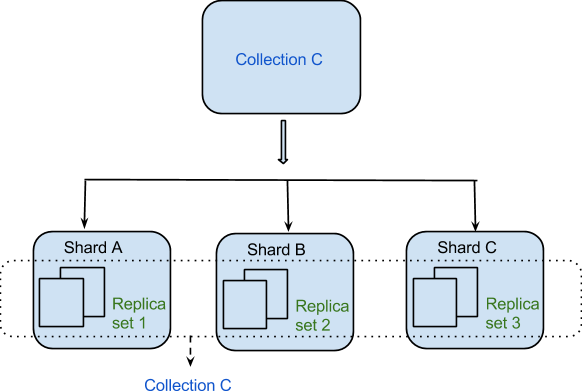
Os dados são distribuídos entre as máquinas de maneira distribuída em virtude do Sharding. O MongoDB emprega sharding para oferecer suporte a implantações em grande escala que exigem um alto nível de taxa de transferência. Pode ser difícil construir um único servidor para um sistema de banco de dados com um grande número de conjuntos de dados ou um aplicativo de alto rendimento.
A estratégia mais comum para resolver problemas de Ranged Sharding é abordá-lo em seu sentido mais geral. O nó raiz do cluster tem um número predeterminado de shards que podem ser divididos com base em sua distância do datacenter do cluster. O nó primário é chamado de nó raiz porque é o primeiro nó a ser criado no conjunto de dados. Outro tipo de fragmento é chamado de fragmento secundário. Uma transação variada ou de hash é possível. O valor da chave de hash de um fragmento específico determina quantos dados ele pode gerar. Um identificador é criado pela chave de hash para cada dado em uma transação. Existem inúmeras vantagens e desvantagens para cada estratégia. É mais simples implementar fragmentação de intervalo quando o conjunto de dados é pequeno, em oposição a um conjunto grande, e é mais eficiente quando é pequeno. Quando o conjunto de dados é grande, o hashing é mais eficiente. A reputação de velocidade do MongoDB deriva do fato de que ele oferece suporte à delegação de dados para outros serviços do MongoDB. Os fragmentos do conjunto de dados podem ser distribuídos entre vários servidores no MongoDB para melhorar a velocidade de processamento de dados. O MongoDB oferece suporte a várias opções de replicação, além de sharding. Como resultado, a replicação permite que um conjunto de dados seja distribuído em vários servidores para manter a consistência. A replicação de dados é necessária se você quiser garantir que as informações sejam sempre precisas e atualizadas. Além disso, clusters dispersos no MongoDB podem ser úteis para melhorar o desempenho. Sraving é uma técnica para transferir grandes quantidades de dados de um servidor para outro da mesma forma que a replicação. Uma chave de estilhaço é um item de dados que pode ser copiado (ou “estilhaços”) de um servidor para outro. Os dois métodos principais para distribuir dados em clusters fragmentados no MongoDB são baseados em intervalo e distribuídos. O hashing pode ser feito usando um servidor criptografado. Ao dividir as coisas, você pode realizar mais de uma coisa.

Você deve fragmentar seu Mongodb?
Não é certo se o sharding melhora ou não o desempenho em alguns casos, mas foi demonstrado que aumenta o desempenho em alguns casos. Além disso, como resultado, o sharding apresenta seu próprio conjunto de desafios, como garantir backups e restaurações robustos. Antes de decidir sobre uma estratégia de sharding , você deve pensar nos prós e contras de fazê-lo.
Fragmentação em Nosql
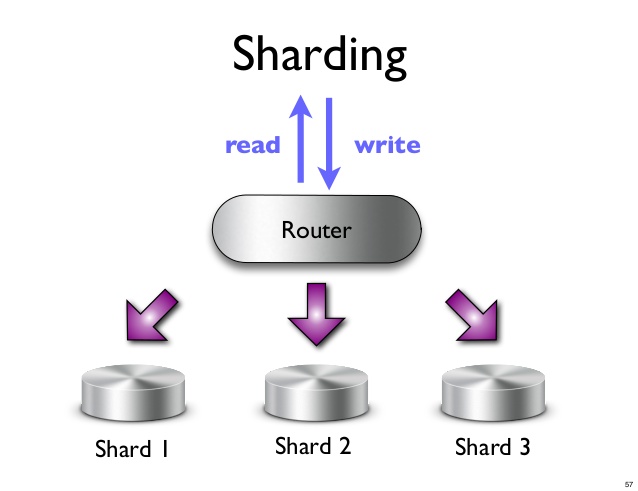
Um fragmento é uma partição horizontal de dados em um banco de dados ou mecanismo de pesquisa. Cada fragmento é um banco de dados independente ou uma instância do mecanismo de pesquisa. Em um banco de dados NoSQL, uma coleção de documentos pode ser dividida em fragmentos, cada um armazenado em um servidor separado.
Fragmentação Vs Replicação
A distinção entre replicação e fragmentação é que a replicação é a duplicação de dados, enquanto a fragmentação é a divisão de dados em blocos discretos. Nesse caso, você dividiu sua coleção em várias partes com base na fragmentação. Recuperar seu banco de dados produz imagens de todos os seus conjuntos de dados.
Os benefícios da fragmentação
Os dados são divididos em várias máquinas para aumentar o número de usuários simultâneos e melhorar o desempenho. Os dados são armazenados em partições separadas em cada uma das máquinas.
Replicação em Nosql
Existem algumas maneiras diferentes de lidar com a replicação em um banco de dados NoSQL. Uma maneira é o banco de dados se replicar automaticamente para um servidor secundário sempre que houver uma alteração. Isso garante que sempre haja um backup disponível caso o servidor principal fique inoperante. Outra maneira é replicar manualmente os dados para um servidor secundário regularmente. Isso dá ao administrador mais controle sobre quando a replicação ocorre, mas também significa que há uma chance de o servidor secundário não estar atualizado em caso de falha.
O que é fragmentação no banco de dados
Sharding é um processo de particionamento horizontal de dados em um banco de dados. No sharding, um banco de dados é dividido em partes menores, chamadas shards. Cada fragmento é armazenado em um servidor separado. O processo de sharding ajuda a melhorar o desempenho de um banco de dados distribuindo a carga entre vários servidores.
Um único dado pode ser replicado em uma única transação com a ajuda de sharding. Como resultado da divisão de um conjunto de dados em partes menores e sua distribuição em vários servidores, a capacidade geral de armazenamento do sistema pode ser aumentada. Em alguns casos, isso pode ser útil se os dados forem grandes e exigirem vários servidores para mantê-los atualizados. Wrappers de dados estrangeiros também são usados para ler dados de servidores remotos, dando ao armazenamento de dados ainda mais flexibilidade.
Qual é a diferença entre particionamento e sharding?
Particionamento e fragmentação são duas abordagens para estruturar grandes coleções de dados em pequenos fragmentos. Tanto a fragmentação quanto a partição significam que os dados estão espalhados por vários computadores, mas são distintos. O procedimento para particionar uma instância de banco de dados envolve o agrupamento de subconjuntos de dados dentro dela.
Qual banco de dados é melhor para sharding?
A fragmentação de banco de dados é suportada por Cassandra, HBase, HDFS, MongoDB e Redis. Os bancos de dados que não suportam nativamente PostgreSQL, Memcached, Zookeeper, MySQL e Sqlite são considerados bancos de dados. A lógica Jarryd deve estar presente em um aplicativo se ele não tiver suporte integrado para bancos de dados.
O sharding é possível no SQL?
É possível, no entanto, implementar sharding baseado em intervalo (essencialmente horizontal), de forma a torná-lo mais transparente para o aplicativo. A maneira típica de fazer isso no SQL Server é por meio de uma exibição particionada, mas isso não precisa ser o caso.