
Bancos de dados NoSQL: bancos de dados em escala da Web para alto tráfego e grandes conjuntos de dados
Publicados: 2022-11-18Os bancos de dados Nosql são bancos de dados em escala da Web que podem lidar com alto tráfego e grandes conjuntos de dados. Eles são projetados para serem escaláveis e para lidar com altas cargas. Um banco de dados nosql pode ser dimensionado horizontalmente adicionando mais servidores ao sistema. Isso permite que o sistema lide com mais tráfego e armazene mais dados.
O aumento da demanda por aplicações complexas exige maior flexibilidade. É igualmente importante selecionar armazenamentos de dados fáceis de dimensionar e executar com eficiência. A questão mais significativa é se os bancos de dados 'ASL' ou 'NoSQL' são melhores para executar um aplicativo. Os bancos de dados SQL estão em uso há algum tempo, mas os bancos de dados NoSQL são conhecidos por serem mais fáceis de escalar. Para bancos de dados NoSQL, a suposição é que a fragmentação deve ser executada em todas as operações. Um nó pode ser identificado por uma função de qualificação, que é esperada de cada operação de dados no banco de dados. Como os dados são armazenados em várias máquinas, é muito eficiente lidar com operações de dados até mesmo nas máquinas mais básicas.
Com esse recurso, máquinas de commodities simples podem ser usadas para dimensionar armazenamentos NoSQL. O NoSQL assume que o usuário pode planejar e estruturar os dados para que sejam recuperados apenas do mesmo nó em um determinado momento para qualquer operação. Além disso, a desnormalização de dados entre os nós (dados pré-preparados para inicialização) pode ser executada. Há um lugar para junções NoSQL, mas não espere que elas sejam ricas em SQL ou otimizadas. Na prática, assume-se que os dados serão sempre consistentes com aplicações NoSQL. Existem vários sistemas NoSQL que fornecem opções para modificar a consistência ao longo do tempo, se a consistência for importante. O objetivo de qualquer decisão de arquitetura, como o objetivo de avaliar o caso de uso, é selecionar o armazenamento de dados apropriado.
Um pool de recursos de dimensionamento horizontal pode ser expandido adicionando mais máquinas a ele, enquanto um pool de dimensionamento vertical pode ser expandido adicionando mais máquinas a ele.
Bancos de dados SQL e bancos de dados NoSQL usam escala vertical devido à maneira como os dados são armazenados (tabelas relacionadas versus coleções não relacionadas), enquanto bancos de dados NoSQL usam escala horizontal porque não usam tabelas relacionadas.
O tipo de dimensionamento suportado pelo NoSQL é horizontal.
Para escalar horizontalmente, o MongoDB emprega um mecanismo integrado que permite mover dados entre vários servidores. Esse processo é conhecido como sharding e você pode realizá-lo pressionando um botão de alternância na página de configuração da IU do Atlas. Além disso, o processo também pode ser concluído sem tempo de inatividade.
Como funciona o dimensionamento horizontal no Nosql?
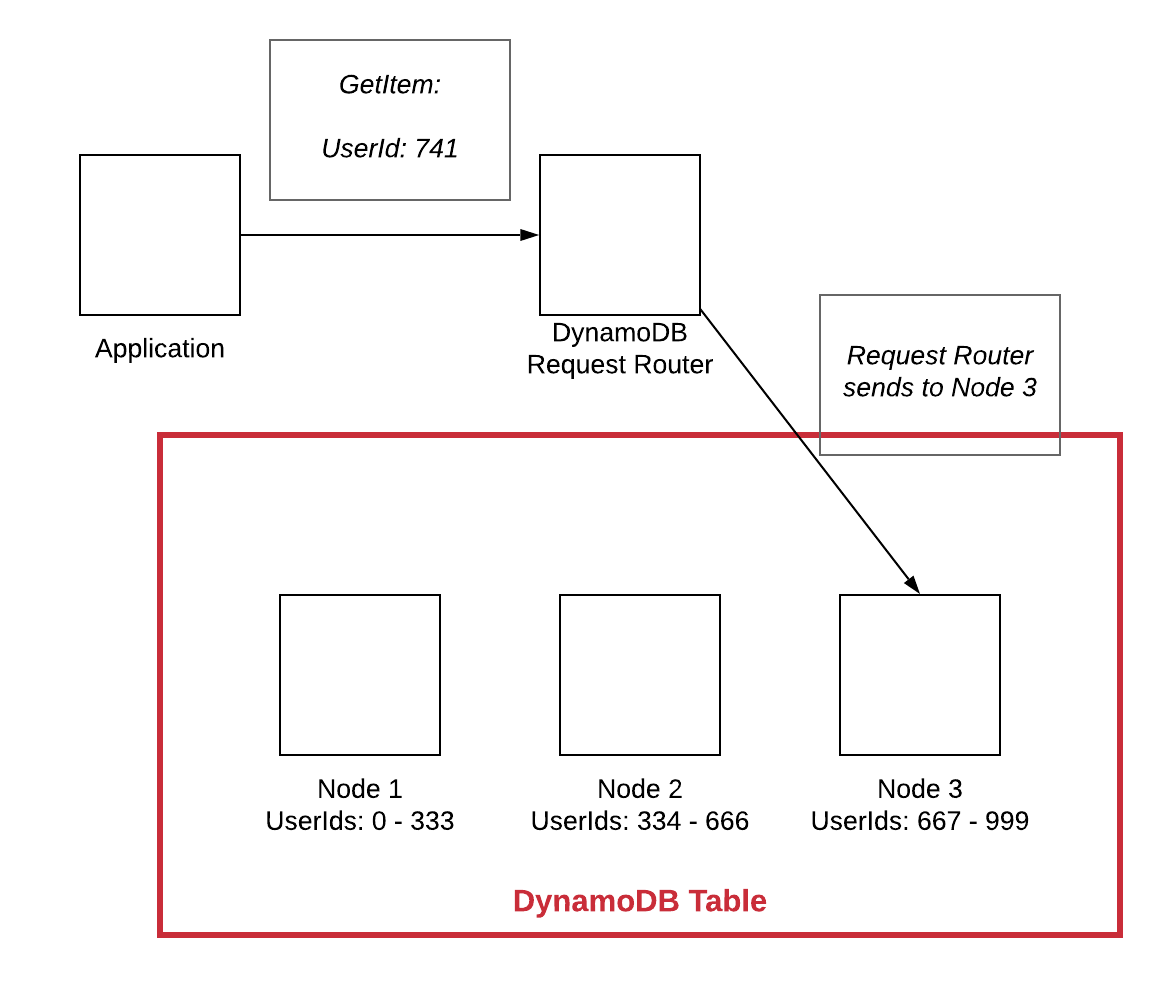
O dimensionamento horizontal em um banco de dados NoSQL significa que o banco de dados pode ser dimensionado adicionando mais máquinas ao sistema, em vez de tornar uma única máquina mais rápida ou mais poderosa. Isso permite que o sistema lide com mais tráfego e dados sem problemas de desempenho.
As vantagens do dimensionamento horizontal são inúmeras: você pode adicionar facilmente mais servidores para lidar com o aumento do tráfego e não precisa se preocupar em carregar linhas de vários servidores ao mesmo tempo. Como resultado, os bancos de dados NoSQL são excelentes opções para empresas que desejam armazenar dados sob demanda e, ao mesmo tempo, economizar dinheiro com armazenamento de dados .
Bancos de dados Nosql são melhores para lidar com grandes conjuntos de dados
Devido às limitações dos bancos de dados relacionais , eles não podem lidar com grandes conjuntos de dados. Os bancos de dados NoSQL, como o MongoDB, armazenam seus dados em um formato de documento independente, permitindo que você distribua seus dados em vários nós. Com esse recurso, o banco de dados é capaz de lidar com grandes conjuntos de dados de forma rápida e fácil.
Como o Mongodb pode escalar horizontalmente?
MongoDB pode escalar horizontalmente usando sharding. Sharding é um processo de divisão de dados em vários servidores. Cada servidor tem sua própria parte do conjunto de dados e os dados são distribuídos uniformemente pelos servidores. Quando uma solicitação é feita, o servidor MongoDB determinará qual servidor possui os dados que estão sendo solicitados e os recuperará desse servidor. Esse processo permite que o MongoDB seja dimensionado horizontalmente e lide com grandes quantidades de dados.
Quando se trata de dimensionar a infraestrutura, muitas empresas acham que estão passando por momentos difíceis. A plataforma de banco de dados como serviço do MongoDB oferece suporte a uma ampla variedade de opções de dimensionamento e é incorporada ao back-end. A técnica de dimensionamento horizontal é conhecida como sharding (porque é a preferida). O termo “escalonamento em camadas” refere-se à capacidade de um único servidor ou cluster de escalar em uma direção ascendente. É um método de dimensionamento horizontal que envolve a distribuição de dados em vários nós. A plataforma MongoDB Atlas configura automaticamente uma chave de fragmentação, que ainda depende de nós. É claro que os conjuntos de réplicas e fragmentação são semelhantes, mas os conjuntos de dados não são os mesmos.
Além disso, eles podem causar problemas com grandes quantidades de transações de gravação para aplicativos. O MongoDB Atlas também suporta escala horizontal e vertical. A implantação de um cluster fragmentado permite o dimensionamento horizontal. Resumindo, o dimensionamento vertical é tão simples quanto configurar uma camada de cluster. No caso de um desligamento completo, o cluster pode ser pausado para manter o cluster em 0, dimensionando efetivamente todo o cluster para 0, exceto para o armazenamento.
O MongoDB é um excelente banco de dados NoSQL, pois é um aplicativo moderno que precisa escalar horizontalmente para lidar com grandes conjuntos de dados. O MongoDB tem uma API simples que simplifica o acesso e a manipulação de dados pelos desenvolvedores, e seu armazenamento sem esquema simplifica o armazenamento e a recuperação de dados. Além disso, como o MongoDB oferece suporte à replicação, os dados podem ser facilmente replicados em vários servidores, garantindo que permaneçam disponíveis para uso futuro.
Escalabilidade do Mongodb
MongoDB é uma das linguagens de programação mais elásticas. Em um banco de dados orientado a documentos como o MongoDB, os dados são armazenados em documentos semelhantes a JSON. O processo do MongoDB é dimensionado horizontalmente por meio do uso de sharding. Srave é uma técnica de distribuição de dados que usa várias coleções e máquinas para distribuir dados entre bancos de dados e máquinas.
O Sql Db é escalonável horizontalmente?
No dimensionamento horizontal, os bancos de dados são adicionados ou removidos para executar uma tarefa específica, como aumentar ou diminuir a capacidade ou o desempenho geral. O dimensionamento horizontal é normalmente implementado combinando dados de vários bancos de dados estruturados de forma idêntica e, em seguida, separando-os em tabelas separadas.
Todo banco de dados, todos os dias, deve ser dimensionado para lidar com o volume de dados gerados. O dimensionamento é classificado em dois tipos: vertical e horizontal. A memória de um servidor de 2 TB é suficiente para armazenar mais dados. É comprar um grande servidor a um preço extremamente alto. A adição de mais máquinas ao servidor é referida como escala horizontal. Seu objetivo é dividir o conjunto de dados em vários servidores ou fragmentos. Seria inútil ter um único ponto de verdade baseado na desnormalização. Essa abordagem tem uma desvantagem: se o mestre falhar em atualizar as réplicas do escravo durante uma gravação, o mestre não atualizará as réplicas do escravo.

Uma replicação é o ato de trocar dados entre nós em um cluster. Ao replicar dados, você pode aumentar a disponibilidade e a recuperação de um servidor. Além disso, a replicação pode ser usada para distribuir a carga entre vários clusters de nós. Uma organização pode dividir horizontalmente seus dados em blocos menores e distribuir esses blocos em vários nós. O particionamento horizontal melhora o desempenho. Existem vários tipos diferentes de clusters MongoDB , além dos clusters MongoDB padrão. O cluster de nó único, em geral, é o tipo mais simples de cluster e é adequado para teste e desenvolvimento. Um cluster de dois nós é o tipo mais comum de cluster e é adequado para aplicativos de médio a grande porte. Um cluster de três nós também é popular e é adequado para aplicativos de grande escala. Em um cluster de dois nós, por exemplo, os dados são divididos em dois fragmentos separados em cada nó. Nesse caso, cada nó possui uma cópia dos dados. Quando a carga de um nó aumenta, o outro nó pode ser capaz de lidar com a carga. Um cluster com balanceamento de carga é um dos tipos mais comuns de clusters. Um cluster de três nós é composto por três datacenters separados, cada um contendo três shards separados. Se a carga de um nó aumentar, os outros dois nós poderão assumir o controle. Um cluster balanceado é um desses clusters. O banco de dados MongoDB é um banco de dados moderno baseado em documentos com recursos de dimensionamento horizontal: replicação e particionamento horizontal (ou fragmentação). O processo de dimensionamento horizontal de um banco de dados envolve a adição de mais instâncias ou nós para lidar com o aumento da demanda. Quando você precisar de mais capacidade, basta adicionar mais servidores ao cluster. Além disso, os servidores geralmente são menores e mais baratos do que os usados para computação de desktop. É um processo de cópia de dados entre nós em um cluster. O particionamento de dados horizontalmente os divide em pedaços menores e os distribui em vários nós em um sistema distribuído. Existem vários tipos de clusters MongoDB, cada um com um conjunto distinto de recursos. Clusters de três nós também são comuns, embora não sejam tão eficazes quanto um cluster de quatro nós.
Dimensionar horizontalmente com um banco de dados relacional
Um banco de dados SQL tradicional normalmente não pode ser dimensionado horizontalmente porque precisa hospedar mais servidores, mas ainda podemos adicionar réplicas de outras máquinas. O Write Ahead Log é usado para propagar todas as operações de gravação do servidor principal para outras máquinas. Devido à flexibilidade da sintaxe de consulta, os bancos de dados relacionais não podem ser dimensionados horizontalmente. Para garantir que nenhuma parte de seus dados seja buscada até que você execute sua consulta, o SQL permite adicionar tantas condições e filtros a seus dados que é impossível para seu banco de dados prever quais partes serão recuperadas. Como resultado, o banco de dados pode ficar lento ao tentar processar grandes quantidades de dados. Como os bancos de dados relacionais podem ser dimensionados horizontalmente, eles podem ajudar a cobrir áreas em que o Spark normalmente é menos eficaz, seja atuando como um meio de armazenamento para Spark Streaming ou cálculos em lote. A plataforma Cloud SQL não oferece suporte nativo a essas configurações, mas elas podem ser implementadas usando ferramentas do setor, como o ProxySQL. No entanto, o conceito subjacente do Cloud SQL não se destina a esses tipos de cenários.
Por que o Nosql é escalável horizontalmente
Os bancos de dados NoSQL podem ser dimensionados horizontal ou verticalmente, dependendo de seus requisitos. Você pode lidar com situações de alto tráfego fragmentando seu banco de dados NoSQL, adicionando mais servidores ao processo. Os bancos de dados NoSQL são a escolha preferida para conjuntos de dados grandes e que mudam com frequência porque podem ser dimensionados horizontalmente em vez de verticalmente.
Ele deve ser capaz de lidar com bancos de dados muito grandes , com taxas de solicitação muito altas, com latência muito baixa. Dimensionamento e disponibilidade são requisitos críticos para sites de alto volume, como eBay, Amazon, Twitter e Facebook. Quando você tem a capacidade de executar várias instâncias em um servidor ao mesmo tempo, o dimensionamento horizontal é ideal.
Devido à sua escalabilidade e flexibilidade, os bancos de dados NoSQL estão ganhando popularidade em comparação aos bancos de dados SQL. Além disso, eles têm melhor desempenho quando comparados a bancos de dados baseados em tabelas para dados não estruturados, que podem ser difíceis de processar e armazenar.
Como dimensionar o banco de dados Nosql
Não há uma resposta única para essa pergunta, pois a melhor maneira de dimensionar um banco de dados NoSQL depende das necessidades específicas do aplicativo e dos dados armazenados. No entanto, algumas dicas sobre como dimensionar um banco de dados NoSQL incluem adicionar mais nós ao cluster para aumentar a capacidade e o desempenho, usar fragmentação para distribuir dados em vários nós e replicar dados para vários nós para garantir alta disponibilidade.
Vários pontos importantes são abordados enquanto Rahim Yaseen, da Couchbase, nos orienta através deles. As organizações estão lutando para gerenciar, armazenar e monetizar suas enormes quantidades de dados. Uma decisão importante do banco de dados é expandir ou não. O registro é distribuído para cabines de check-in em fragmentação manual. Isso é conseguido devido a um esquema pré-definido e bem definido. Como parte do autosharding, você teria que ir a cada estande para descobrir quem fez check-in com um sobrenome começando com S. Os bancos de dados de documentos têm padrões de acesso que exigem que os usuários naveguem para outro documento por meio de uma chave específica e acessem os dados por meio de um único chave. À medida que o tamanho de um conjunto de dados distribuído cresce, torna-se cada vez mais difícil indexá-lo e consultá-lo.
É inútil usar uma técnica de redução de mapa porque cada nó na consulta deve participar dela. À medida que os dados crescem em volume, a expansão do modelo RDBMS torna-se cada vez menos viável. No caso de um grande conjunto de dados, a falha de uma arquitetura de expansão provavelmente será um ponto de falha muito grande. A Internet é um exemplo de um cluster de ultraescala sem compartilhamento.
Bancos de dados Nosql: o futuro da escalabilidade
Como os dados são enviados por várias máquinas em bancos de dados Nosql, eles são extremamente escalonáveis. Como resultado, em vez de comprar máquinas caras que requerem equipamentos especializados, podemos facilmente adicionar potência de CPU. Além disso, os bancos de dados Nosql podem conter uma grande quantidade de dados sem limite, tornando-o um sistema de gerenciamento de dados muito versátil.
O banco de dados Sql pode escalar horizontalmente
Sim, os bancos de dados SQL podem ser dimensionados horizontalmente. Isso significa que eles podem ser distribuídos por vários servidores, cada um dos quais lida com uma parte do total de dados. Isso permite maior escalabilidade do que um único servidor poderia fornecer.
Por que os bancos de dados Sql não são escalonáveis horizontalmente?
Devido à flexibilidade da sintaxe de consulta, é impossível escalar horizontalmente em um banco de dados relacional . Como resultado do SQL, você pode adicionar qualquer número de condições e filtros aos seus dados que impedem o sistema de banco de dados de saber quais partes serão retornadas até que a consulta seja concluída.
Por que o SQL escala verticalmente?
O objetivo do escalonamento vertical é aumentar o consumo de energia e a capacidade de RAM dos sistemas existentes, aumentando essencialmente os recursos disponíveis. O dimensionamento vertical não é apenas mais fácil, mas também mais barato. O problema também não requer uma correção de longo prazo.