
Escalando um banco de dados NoSQL: dicas e truques
Publicados: 2022-11-18Os bancos de dados NoSQL estão se tornando cada vez mais populares, pois a quantidade de dados gerados pelas empresas continua a crescer exponencialmente. No entanto, muitas organizações relutam em mudar para o NoSQL porque temem que seja mais difícil de escalar. Dimensionar um banco de dados NoSQL não é tão diferente de dimensionar um banco de dados relacional. A principal diferença é que os bancos de dados NoSQL são projetados para serem escalonáveis horizontalmente, o que significa que podem ser dimensionados adicionando mais nós ao sistema. Isso contrasta com os bancos de dados relacionais , que são verticalmente escaláveis, o que significa que eles só podem ser dimensionados adicionando mais recursos a um único servidor. Há algumas coisas a serem lembradas ao dimensionar um banco de dados NoSQL: 1. Certifique-se de que seus dados sejam distribuídos uniformemente em todos os nós. 2. Adicione nós gradualmente para evitar sobrecarregar o sistema. 3. Monitore de perto o desempenho do sistema para identificar quaisquer gargalos. 4. Ajuste o sistema regularmente para garantir o desempenho ideal. Com essas dicas em mente, dimensionar um banco de dados NoSQL não deve ser mais difícil do que dimensionar um banco de dados relacional.
Existem vários métodos e princípios para dimensionar um banco de dados, dependendo de seu tipo. O dimensionamento de bancos de dados NoSQL e sql depende do conceito de fragmentação do banco de dados. Os benefícios de poder armazenar mais dados aumentam quando os servidores são distribuídos, mas também herdamos os problemas decorrentes da distribuição. A fragmentação automática não é suportada por um banco de dados monolítico e os engenheiros teriam que escrever manualmente a lógica para lidar com isso. Para resolver esse problema, um proxy, como um balanceador de carga, pode ser instalado na frente do serviço de consulta e do banco de dados. Podemos obter consultas mais rápidas quando o shard é grande porque esse proxy pode ser usado novamente. Devido à falta de conhecimento dos usuários finais, o dimensionamento de bancos de dados NoSQL é praticamente invisível.
Cada fragmento é único, ao contrário de uma arquitetura mestre-escravo. Se houver alguma consulta de leitura no estilhaço mestre, uma solicitação será enviada aos estilhaços escravos. No nível do data center, podemos replicar o banco de dados para garantir que tenhamos um backup. O Node é um nodo que pode se comunicar e trocar informações com outros nodos. Cada nó se comunica com um número fixo de outros nós por meio de um protocolo. Como todos os nós são iguais no Cassandra, um nó pode replicar seus dados de um para o outro sem precisar se preocupar em perder nenhum dado. O protocolo fofoca é uma das muitas maneiras pelas quais os nós podem compartilhar informações.
Um banco de dados distribuído pode ter várias vantagens além de obter propriedades adicionais. Um componente crítico para garantir a disponibilidade é a replicação de dados. Quando você usa replicação assíncrona para seu banco de dados, nem sempre será totalmente consistente no início, mas ficará mais consistente com o passar do tempo. Os bancos de dados SQL são usados em aplicativos financeiros que exigem alta precisão de dados, enquanto os bancos de dados NoSQL são usados em aplicativos menos significativos, como contagens de visualizações.
A escala vertical refere-se ao processo de aumentar gradualmente a carga de trabalho de computação com o uso de atualizações de hardware. Mudar para uma arquitetura distribuída e adicionar mais computadores para resolver nosso problema implica em escalabilidade horizontal, também conhecida como escalabilidade horizontal ou expansão horizontal.
NoSQL pode suportar escalabilidade baseada em métodos horizontais.
O MongoDB, como banco de dados NoSQL, é escalável porque seus dados não são armazenados em bancos de dados relacionais. Os dados são armazenados como documentos do tipo JSON que são facilmente acessíveis por meio de uma solicitação HTTP. A distribuição de documentos pode ser executada horizontalmente em vários nós usando esse método.
Como você dimensiona o banco de dados Nosql?
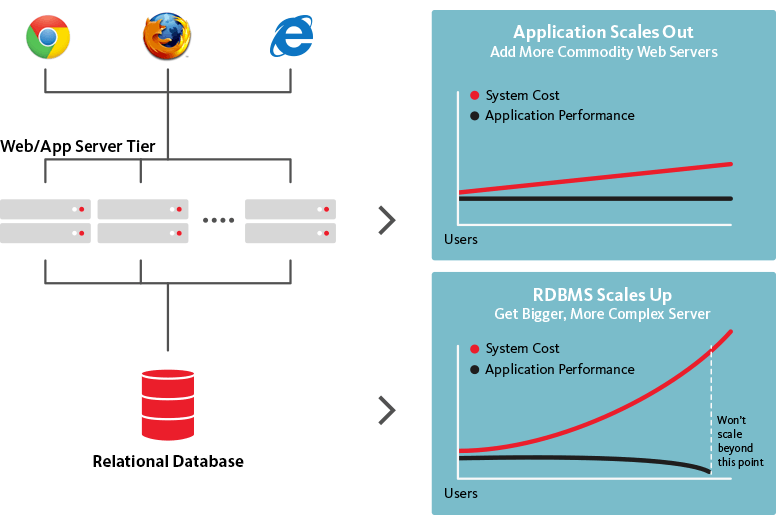
Os bancos de dados NoSQL, por outro lado, são escalonáveis horizontalmente, o que significa que eles podem lidar com o aumento do tráfego conforme necessário simplesmente adicionando mais servidores ao banco de dados. Como os bancos de dados NoSQL podem ser transformados em estruturas muito maiores e mais poderosas, é a escolha lógica para grandes conjuntos de dados e bancos de dados em constante evolução.
Para que este tutorial funcione, você deve ter um ambiente Node.js funcional. Nesta postagem, descompactarei os arquivos do DynamoDB em uma pasta chamada nodejs-dynamodb-sample. Para uma versão detalhada disso, acesse minha página do GitHub: https://www.gofundme.com/adamfowleruk/nodesurvey.html. O aplicativo de amostra pode pesquisar e recuperar informações de filmes do DynamoDB. Estaremos armazenando dados no S3 no Amazon Web Services e acessando o DynamoDB por meio do serviço de gerenciamento de identidade e acesso (IAM) da Amazon. Para usar o serviço In-App Analytics da Amazon, você deve primeiro se registrar e criar uma conta. Anote o ano e o título de cada filme que deseja POSTAR /movies.
Você pode inserir um campo digitado para encontrar filmes de um determinado ano. Depois disso, você pode criar seu próprio aplicativo desde o início. Você pode usar suas tabelas até terminá-las, mas deve excluí-las assim que forem usadas. Visite o console do DynamoDB no Amazon Web Services para ver quanto armazenamento você usou até agora. A guia 'Filmes' permite visualizar os itens em uma tabela e as métricas de seu aplicativo, bem como o custo mensal estimado por mês na guia Capacidade. Este código pode ser encontrado na minha página do GitHub: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
MongoDB, Apache HBase e Cassandra são três bancos de dados NoSQL ideais para dimensionamento horizontal. Como suas estruturas de dados são mais horizontais, isso facilita a adição de mais servidores ao sistema, além de eliminar a necessidade de alterá-los. Além disso, esses bancos de dados são relativamente novos, portanto ainda estão sendo desenvolvidos e refinados, o que significa que provavelmente melhorarão com o tempo.
Por que é fácil dimensionar o Nosql?
O Nosql é fácil de escalar porque foi projetado para ser escalável horizontalmente. Isso significa que ele pode ser dimensionado adicionando mais nós a um cluster nosql . O Nosql também é fácil de escalar porque pode lidar com grandes quantidades de dados e um grande número de consultas por segundo.
Os aplicativos exigem um alto nível de escalabilidade para funcionar corretamente. Escolher armazenamentos de dados com uma interface de usuário simples e eficiente é igualmente importante. O principal ponto de discórdia é se usar um banco de dados 'ASL' ou 'Nosql' é melhor. Os bancos de dados NoSQL, ao contrário dos bancos de dados SQL, são populares porque são simples de construir. A interrupção de todas as operações em um banco de dados NoSQL depende inerentemente da fragmentação. Em geral, toda operação de dados requer o uso de um operador qualificador, que pode ser usado para identificar um nó com os dados. Os dados são armazenados em várias máquinas e isso torna muito simples realizar operações de dados até mesmo nas menores máquinas.

Como resultado, os armazenamentos NoSQL podem ser dimensionados para usar uma máquina de commodity relativamente simples. Presume-se que os usuários planejem e estruturem os dados de forma que possam ser obtidos de uma só vez do mesmo nó para executar uma operação específica no banco de dados NoSQL. A desnormalização de dados dessa maneira também pode significar que o nó está pronto para executar dados pré-preparados. Junções em NoSQL são possíveis, mas não são tão robustas quanto as junções SQL. No mundo prático do NoSQL, os designers de aplicativos acreditam que a consistência dos dados acabará por ocorrer. Além de fornecer opções para ajustar a consistência em diferentes sistemas NoSQL, muitos sistemas NoSQL fornecem rotinas para tornar a consistência mais proeminente. Uma parte importante de qualquer decisão de arquitetura é avaliar o caso de uso e escolher o armazenamento de dados apropriado com base nesse caso.
Todos os bancos de dados Nosql são escaláveis?
Como resultado da era da internet e da computação em nuvem, os bancos de dados NoSQL foram criados para facilitar a implementação de uma arquitetura scale-out. a escalabilidade é obtida combinando o armazenamento de dados com o trabalho necessário para processá-los em um grande número de computadores em uma arquitetura de expansão.
O sistema deve ser capaz de lidar com bancos de dados extremamente grandes com latência muito baixa e, ao mesmo tempo, lidar com taxas de solicitação muito altas. Quando se trata de sites de grande volume como eBay, Amazon, Twitter e Facebook, escalabilidade e alta disponibilidade são essenciais. Você pode executar várias instâncias de um servidor ao mesmo tempo com dimensionamento horizontal.
O banco de dados do MongoDB é escalável horizontal e verticalmente em sua escala e número de usuários. No MongoDB, você pode dimensionar seu cluster vertical ou horizontalmente adicionando mais recursos e dividindo seus dados em partes menores. Como resultado, o MongoDB é uma escolha popular para aplicativos e armazenamentos de dados em larga escala .
Melhores bancos de dados Nosql para dimensionamento rápido e alto volume de dados
Outros bancos de dados NoSQL podem ser dimensionados para atender às suas necessidades específicas, assim como você pode fazer com outros bancos de dados. O MongoDB, por exemplo, é uma linguagem de programação popular porque pode escalar rapidamente e lidar com muitos dados. Os armazenamentos de dados baseados em Redis são amplamente usados devido a seus recursos e velocidade na memória.
Escala Vertical Nosql
Os bancos de dados Nosql são escaláveis horizontalmente, o que significa que eles podem lidar com o aumento do tráfego adicionando mais nós ao sistema. Isso contrasta com o dimensionamento vertical, em que o sistema é dimensionado adicionando mais recursos a um único nó.
Todo banco de dados deve ser dimensionado para lidar com o volume de dados gerado diariamente. O termo “escala” é classificado em dois tipos: vertical e horizontal. Se você deseja armazenar mais dados, deve investir em um servidor de 2 TB. Um único servidor está se tornando cada vez mais caro e maior. O processo de adicionar máquinas a um servidor resulta em escala horizontal. Nesse caso, os dados são divididos em um conjunto e distribuídos em vários servidores ou shards. Por seguir o modelo de desnormalização, não há necessidade de um único ponto de verdade. Essa abordagem pode não resultar em uma atualização de informações quando o mestre falha em executar uma gravação porque não atualiza as informações nas réplicas do escravo quando o mestre falha em executar uma gravação.
O que é escala vertical no SQL?
O objetivo da abordagem de dimensionamento vertical é aumentar a capacidade de uma única máquina aumentando os recursos do mesmo servidor lógico. O software existente deve ser atualizado com recursos como memória, armazenamento e capacidade de processamento para ter o melhor desempenho.
Como dimensionar o banco de dados horizontalmente
O que é dimensionamento horizontal e como funciona? Um método de escalonamento horizontal é aquele que requer a adição de nós adicionais para acomodar a carga. Isso é extremamente difícil com bancos de dados relacionais devido à dificuldade em distribuir dados relacionados entre os nós.
Além de adicionar mais instâncias para compartilhar a carga, dimensionar horizontalmente (ou escalar horizontalmente) implica aumentar o número de instâncias de um aplicativo ou serviço. Por outro lado, o dimensionamento vertical requer a adição de mais recursos à instância, como capacidade de CPU e memória. Devido aos protocolos subjacentes de HTTP, a maioria dos aplicativos da Web e APIs, eles podem ser facilmente dimensionados independentemente uns dos outros. Alguns bancos de dados agora permitem que você sincronize e compartilhe seus dados gravados entre várias instâncias. Se o tráfego for roteado dessa maneira, mais recursos serão dedicados aos itens solicitados com mais frequência. Embora os proxies reversos sejam comumente usados para lidar com solicitações HTTP, os bancos de dados nem sempre são usados para fazer isso. A maioria dos bancos de dados pode ser encaminhada com software como nginx ou HAproxy, ambos os quais podem ser feitos no nível TCP.
Se o seu proxy puder entender como as conexões funcionam em um nível de protocolo, ele poderá determinar se uma réplica de leitura está fora de sincronia ou incapaz de reagir mesmo se a conexão de rede estiver ativa. A rota pode ser ajustada dependendo da carga na réplica, bem como do número de conexões. Existem alguns servidores proxy que podem executar uma variedade de funções. Alguns avanços foram feitos em volumes e declarações persistentes, mas também há dificuldades inerentes se você não selecionar um banco de dados que valorize cada instância igualmente. Como os contêineres estão sendo movidos pelo cluster, reiniciar uma de suas réplicas de leitura deve funcionar. Se isso acontecer com o banco de dados principal , é improvável que você fique entusiasmado.