
Solr – Uma poderosa plataforma de pesquisa
Publicados: 2022-11-18O Solr é uma poderosa plataforma de pesquisa que permite consultar grandes quantidades de dados rapidamente. Ele é construído sobre a biblioteca de pesquisa Apache Lucene e fornece uma API semelhante a REST para facilitar a integração com seu aplicativo. Um dos principais recursos do Solr é sua escalabilidade – ele pode lidar com bilhões de documentos e consultas com facilidade. O Solr é frequentemente descrito como um banco de dados NoSQL porque não usa o modelo tradicional de banco de dados relacional. No entanto, é importante observar que o Solr não é um banco de dados tradicional e não deve ser usado como tal. Ele é projetado para indexação e pesquisa, não para armazenar dados. Se precisar armazenar dados, você deve usar um banco de dados NoSQL, como MongoDB ou Cassandra.
Com o Elasticsearch como o único projeto de código aberto capaz de competir com o Solr, o Solr é um dos dois mecanismos de pesquisa de código aberto mais populares do mundo. NoSQL significa Not Only SQL, o que significa que ele usa linguagens de consulta separadas do SQL tradicional e não apenas bancos de dados. Apesar de seu excelente recurso de pesquisa de texto completo, o Solr pode ser extremamente útil em um banco de dados NoSQL. Os dados de integridade foram extraídos diretamente do HBase por meio de aplicativos Explorys e Worklist mais antigos. O Solr deu ao Worklist três recursos essenciais: era extremamente fácil de usar e os recursos eram muito intuitivos. O processo de filtragem e classificação é muito eficiente. Como a filtragem do Solr é baseada em IDs de documentos e cache, ele pode calcular quase instantaneamente o número de documentos que atendem aos critérios de filtro.
Solr é uma excelente solução de banco de dados NoSQL frequentemente combinada com outros serviços de big data. Fornecemos feedback imediato aos nossos usuários enquanto eles trabalhavam na adição e configuração de filtros enviando o parâmetro linhas = 0 para o Solr. É fundamental considerar mais do que apenas manter um esquema Solr para criar um mecanismo de pesquisa bom para relevância.
Você pode usar o Solr como um banco de dados?
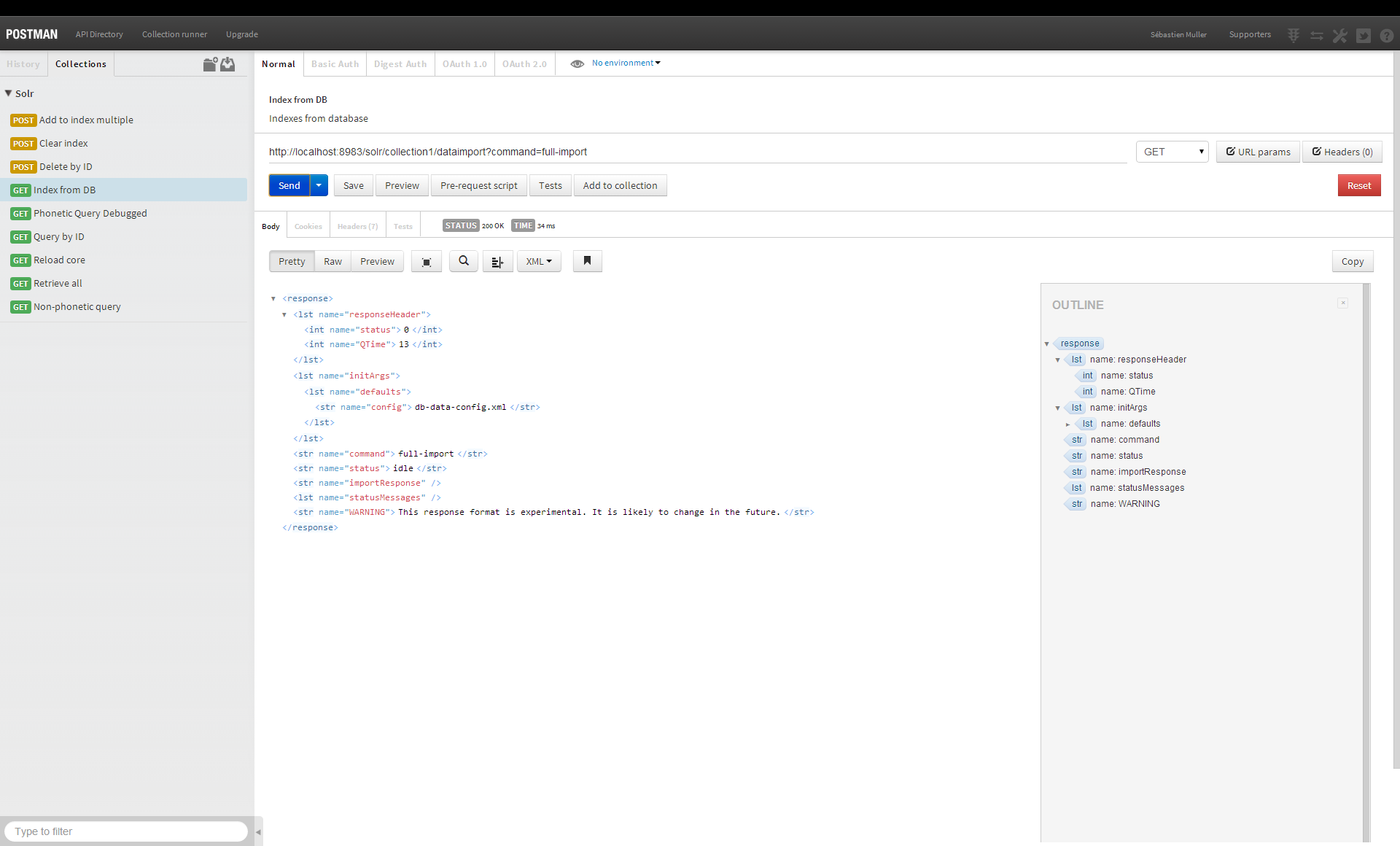
Sim, você pode usar o Solr como banco de dados. É um poderoso mecanismo de pesquisa que pode ser usado para indexar e pesquisar dados. Ele pode ser usado para armazenar dados em um formato estruturado e recuperá-los rapidamente.
Usar um índice de pesquisa como banco de dados é errado? No meu caso, tive uma ideia semelhante de armazenar alguns elementos básicos de dados no Solr. No entanto, o processo de atualização do Solr mudou de ideia e devo admitir que estava errado sobre isso. Se você atualizou 2 versões principais, mas não reindexou (por exemplo, exclua os documentos originais e, em seguida, os próprios arquivos de índice), o núcleo não é mais reconhecido.
Algolia, Elastic Observability, Coveo e Yext são apenas algumas das alternativas populares ao Apache Solr. Algolia é um mecanismo de busca de linguagem natural que analisa e processa consultas de pesquisa com base no que sabemos sobre uma pessoa ou um tópico em linguagem natural. Elastic Observability é uma plataforma de dados que fornece informações em tempo real sobre dados e aplicativos. Coveo, uma plataforma de marketing de mecanismo de pesquisa, permite que você direcione e meça seus esforços de marketing de mecanismo de pesquisa. Ao utilizar o Yext, você pode segmentar e medir suas campanhas de marketing de mecanismo de pesquisa.
Quais são os bancos de dados Nosql?
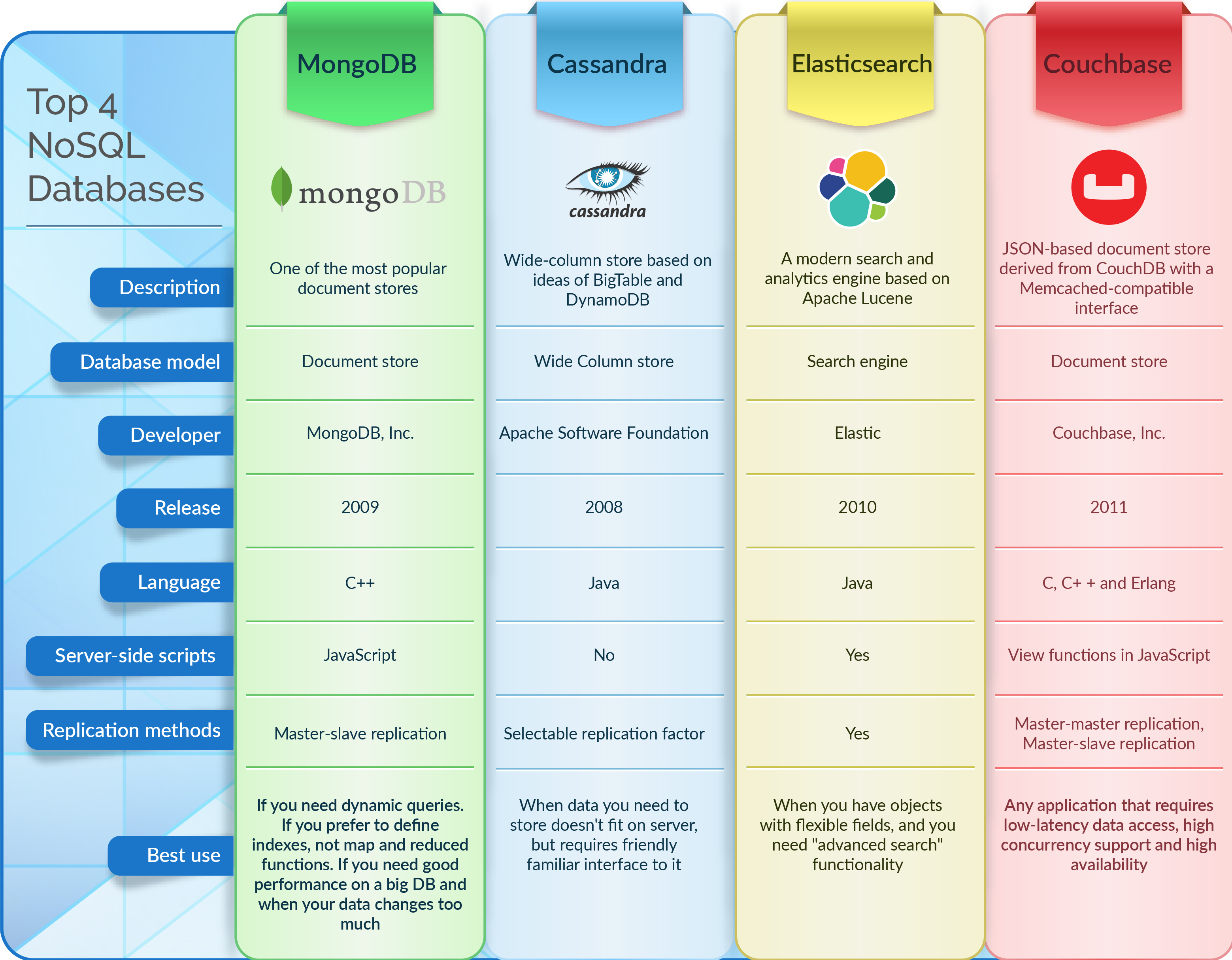
Bancos de dados Nosql são bancos de dados que não usam o modelo de banco de dados relacional tradicional. Em vez disso, eles usam uma variedade de modelos, incluindo bancos de dados de valores-chave, documentos, colunas e gráficos.
Os bancos de dados NoSQL baseados em documentos armazenam dados da mesma forma que os bancos de dados relacionais. O software de gerenciamento de dados foi desenvolvido para ser adaptável, escalável e capaz de responder às necessidades das empresas modernas em tempo hábil. Bancos de dados de documentos , armazenamentos de valores-chave, bancos de dados de colunas largas e bancos de dados de gráficos são apenas alguns dos tipos de bancos de dados NoSQL. A maioria das 2.000 maiores empresas do mundo está adotando rapidamente bancos de dados NoSQL para alimentar aplicativos de missão crítica. Nesse contexto, cinco tendências estão apresentando desafios técnicos muito difíceis de abordar para a maioria dos bancos de dados relacionais. Devido ao modelo de dados fixo, os bancos de dados relacionais são um grande impedimento para o desenvolvimento ágil. O modelo de aplicativo define o modelo de dados do NoSQL.
Os dados devem ser modelados em um modelo NoSQL, independentemente de como estão estruturados. O formato JSON é o padrão para armazenar dados em um banco de dados orientado a documentos. As estruturas ORM podem ser reduzidas dessa maneira, reduzindo os custos indiretos de desenvolvimento de aplicativos. N1QL (pronuncia-se níquel) é uma linguagem de consulta SQL para JSON lançada como parte do Couchbase Server 4.0. A ferramenta também suporta agregação (GROUP BY), classificação (SORT BY), junções (LEFT OUTER / INNER) e uma variedade de outros recursos. Um banco de dados NoSQL distribuído com uma arquitetura escalável, nenhum ponto de falha único e vantagens operacionais atraentes é um dos recursos mais atraentes. À medida que mais interações com os clientes ocorrem on-line por meio da Web e de aplicativos móveis, a disponibilidade é um problema.
Os bancos de dados NoSQL são simples de aprender e usar. Eles são destinados a armazenar informações, escrever e ler livros. Eles também são capazes de gerenciar e monitorar clusters de tamanhos variados em qualquer tamanho. A replicação integrada incluída em um banco de dados NoSQL distribuído é fornecida pelo próprio banco de dados – nenhum software adicional é necessário. Além disso, os roteadores de hardware garantem acesso imediato e consistente a dados críticos. Enquanto os administradores de banco de dados estão investigando um problema, os aplicativos não precisam esperar que o banco de dados descubra um problema antes de realizar sua própria recuperação. A tecnologia NoSQL está ganhando popularidade como uma plataforma para os aplicativos web, móveis e IoT de hoje.
Existem inúmeras razões pelas quais os bancos de dados NoSQL estão se tornando cada vez mais populares. Eles podem ser dimensionados para atender às necessidades de grandes organizações e são adaptáveis. Como exemplo, considere a Ryanair e a Marriott como clientes do MongoDB. Essas organizações, além de usar o MongoDB para alimentar seus aplicativos móveis e sistemas de reservas, também o estão usando para alimentar seus sites. O sistema de gerenciamento de conteúdo Presto da empresa também é construído com NoSQL. O sistema auxilia na gestão eficiente do conteúdo proprietário da empresa.
O futuro do trabalho O futuro do trabalho é remoto
Qual não é um banco de dados Nosql?
Qual é a diferença entre bancos de dados NoSQL e não NoSQL? O Microsoft SQL Server, o sistema de gerenciamento de banco de dados relacional da empresa, é o principal produto.
Durante o final dos anos 2000, o foco no dimensionamento, resultados rápidos de consulta e na facilidade de programação foi alcançado pelos bancos de dados NoSQL. Os bancos de dados NoSQL são simples de criar porque possuem um modelo de dados flexível, um modelo de dados escalonável e uma interface de usuário simples de usar. Bancos de dados relacionais SQL (Structured Query Language) são normalmente construídos com esquemas rígidos, complexos e tabulares, bem como escala vertical proibitivamente grande. A versão 4.0 do MongoDB incluiu suporte para transações ACID de vários documentos, e sua versão 4.2 adicionou suporte para clusters fragmentados. Não há modelos de dados na lista. Na maioria dos bancos de dados NoSQL, as consultas são otimizadas em vez da duplicação de dados. Além disso, alguns n.
Os bancos de dados NoSQL oferecem suporte à compactação para reduzir a pegada de armazenamento. Bancos de dados gráficos, por exemplo, podem ser úteis para analisar relacionamentos, mas podem não ser os mais convenientes para recuperar dados diários. O uso do MongoDB ou outro banco de dados em seu caso de uso será demonstrado no white paper Onde usar o MongoDB. Usar o MongoDB Atlas como ponto de partida é uma das maneiras mais simples de aprender bancos de dados NoSQL. MongoDB University oferece treinamento on-line totalmente gratuito para ajudá-lo a aprender MongoDB.
Existem, no entanto, algumas desvantagens nos bancos de dados NoSQL. Os bancos de dados NoSQL, além de serem livres de ACID, não possuem as mesmas propriedades dos bancos de dados relacionais. As transações em seu aplicativo podem resultar em problemas se o seu sistema depender delas. Além disso, os bancos de dados NoSQL normalmente não fornecem o mesmo nível de flexibilidade de tempo de execução que os bancos de dados SQL. Você deve evitar o uso de bancos de dados NoSQL se seu aplicativo precisar alterar dinamicamente seus modelos de dados.
Qual das opções a seguir não é um banco de dados?
Como todas as consultas, relatórios e tabelas estão relacionados a bancos de dados, os relacionamentos não são objetos de banco de dados; eles estão relacionados com a matemática.
O Mongodb é um banco de dados Nosql?
O programa de gerenciamento de banco de dados MongoDB NoSQL é de código aberto e gratuito. A linguagem NoSQL é uma alternativa aos bancos de dados relacionais tradicionais. Os bancos de dados NoSQL são excelentes para distribuição de dados em larga escala. Informações orientadas a documentos podem ser gerenciadas, armazenadas ou recuperadas usando o MongoDB, que é uma ferramenta de gerenciamento de documentos.
Como o Solr armazena dados
O Apache Solr indexa dados no sistema de arquivos local, como o próprio nome sugere. Como resultado do HDFS (Hadoop Distributed File System), os usuários podem desfrutar de uma variedade de benefícios, incluindo armazenamento em larga escala e distribuído com recursos redundantes e de failover. O Apache Solr inclui suporte para HDFS.
Ao contrário de muitos outros mecanismos de pesquisa, o Solr pode produzir resultados imediatos porque pesquisa um índice em vez de pesquisar diretamente o texto. Ao digitalizar o índice na parte de trás de um livro, o índice pode ser usado para recuperar páginas relacionadas a uma palavra-chave. Esse índice é armazenado no diretório de dados como um índice em um diretório conhecido como diretório de dados. O mecanismo de pesquisa Solr é alimentado por Lucene, um mecanismo de pesquisa de texto completo de código aberto. A relação entre Solr e Lucene é semelhante à de um carro e seu motor. Examinaremos as diferenças entre Lucene e Solr em detalhes neste artigo.

Como usar campos armazenados no Sol
O formato de campo de um documento é usado no Solr. Um documento pode conter algum tipo de campo, que é simplesmente uma coleção de dados. Ao pesquisar um documento usando o Solr, os resultados incluirão as correspondências de todos os campos do documento que ele indexa.
Um campo armazenado é um campo que não precisa ser pesquisado, mas ainda precisa ser exibido ao pesquisar algo. No Solr, eles são conhecidos como campos armazenados. O Solr indexa todos os campos armazenados como resultado de seu algoritmo de indexação, portanto, quando você procura um documento, o Solr retorna resultados que incluem todos os campos armazenados.
Existem inúmeras vantagens em armazenar campos. Se você deseja exibir o título de um documento na lista de resultados, pode ser necessário salvar o título como um arquivo. Se quiser localizar todos os documentos que já pesquisou usando o mesmo ID, você pode acompanhar o ID de um documento por meio de várias pesquisas.
Os resultados da pesquisa também podem ser exibidos armazenando campos. O título de um documento pode aparecer na lista de resultados se estiver rotulado. Você também pode exibir a ID do documento para que possa localizá-la facilmente pesquisando o documento em vários sites.
Os recursos do Solr incluem a capacidade de indexar dados, bem como armazená-los. Para indexar um documento, o Solr deve primeiro criar um banco de dados de todos os campos nele, e então as informações sobre a posição de cada campo serão salvas. Você pode pesquisar e exibir resultados desse tipo de informação.
Além de seus poderosos recursos de pesquisa, o Solr permite que você use aplicativos poderosos de recuperação de documentos. Quando você fornece dados aos usuários com base em suas consultas, eles são baseados em suas consultas.
Tutorial de banco de dados Solr
Um banco de dados solr é um tipo de banco de dados que usa o software solr para indexar e pesquisar dados. É uma ferramenta poderosa que pode ser usada para indexar e pesquisar grandes quantidades de dados rapidamente.
Como este tutorial foi verificado com o Solr 8, ele também pode funcionar com versões mais antigas. O campo id já está pré-definido em todo Lucene e Solr, então deve-se entender quais tipos de campos ele pode indexar da maneira correta. Os campos dinâmicos podem ser criados em tempo real sem a necessidade de pré-definições, permitindo que você os altere a qualquer momento. A biblioteca Lucene que o Solr usa para pesquisa de texto completo emprega instantâneos pontuais que devem ser atualizados regularmente para garantir que novos detalhes sejam apresentados às consultas. Solr, ao contrário do formato de dados agnóstico JSON ou XML, é agnóstico de formato de dados.
Como usar o mecanismo de pesquisa Solr em Java
O cliente Java é necessário para se conectar ao servidor Solr, portanto, use o arquivo org.apache.solr.client.solrjimpl. A classe que usa o protocolo HttpSolrServer é denominada HttpSolrServer. Esta classe usa Java Socket para se comunicar com o servidor Solr. Ao criar um aplicativo de servidor Solr, você deve primeiro carregar as classes apropriadas. Em Java, por exemplo, a funcionalidade de pesquisa do Solr pode ser acessada usando o arquivo org.apache.solr.client.solrj.impl. A classe org.apache.solr.client.solrj.request é o componente da classe SolrServer. Essa classe cria uma classe RequestHandler. Este poderoso mecanismo de pesquisa permite que você encontre facilmente as informações de que precisa. Para acessar o servidor Solr, use o cliente Java.
Solr Vs Lucene
Quando se trata dos projetos Apache Solr e Lucene, eles são compostos pelos mesmos componentes. O Apache Solr, por outro lado, é um servidor autônomo, embora com muitos recursos avançados. O Apache Lucene, por outro lado, é uma solução baseada em biblioteca Java que indexa (armazena) e pesquisa dados.
Por causa de seu cache, o Solr tem uma vantagem no campo de dados estáticos, o que pode facilitar a recuperação dos resultados. Os dados de séries temporais são frequentemente processados pelo Elasticsearch, que emprega seus filtros e recursos de agrupamento, além dos dados de séries temporais.
Solr x Elasticsearch
Não há uma resposta definitiva para essa pergunta, pois depende das necessidades e preferências individuais. No entanto, algumas diferenças importantes entre Solr e Elasticsearch incluem:
-Solr é baseado em um modelo de banco de dados relacional tradicional, enquanto o Elasticsearch usa uma abordagem orientada a documentos.
-Solr é normalmente mais rápido para indexar e pesquisar grandes conjuntos de dados, enquanto o Elasticsearch é geralmente mais escalável.
-Solr oferece suporte a recursos de consulta mais avançados, como junções e objetos aninhados, enquanto o Elasticsearch possui uma sintaxe de consulta mais simples.
Há uma grande comunidade de contribuidores para ambas as tecnologias e assistência especializada está disponível. O Elasticsearch era conhecido anteriormente como Apache 2.0 e era de código aberto. A partir de 2021, com o lançamento da versão 7.11, o Elasticsearch será gratuito para uso sob a licença pública do lado do servidor. Destina-se a pesquisas de texto de nível empresarial que requerem a recuperação de informações e/ou análise. Pesquisas de texto completo também são possíveis no Elasticsearch, e documentos avançados, como PDF e Word, podem ser lidos. O Elasticsearch requer mais memória heap do que o Solr (1 GB x 512 MB), mas esses padrões podem ser alterados. A plataforma Elasticsearch permite mais automação ao combinar o reequilíbrio do cluster com a limpeza de dados, que geralmente é manual.
Sharding é um método de distribuição de dados em vários servidores compatível com Solr e Elastic. Tanto o Solr quanto o ElasticSearch são bancos de dados de mecanismos de pesquisa populares com grandes comunidades envolvidas e recursos semelhantes. O Elasticsearch é mais fácil de usar do que o Solr, mais fácil de escalar e tem melhores recursos de análise e consulta. A biblioteca Apache Tika, que pode ser usada por ambos os bancos de dados, permite que eles realizem pesquisas de texto completo e leiam documentos avançados.
Uso do Apache Solr
Como ele pode indexar e pesquisar documentos e anexos de e-mail, bem como indexar e pesquisar vários sites, é uma ferramenta popular para sites e pesquisa corporativa.
É uma plataforma de pesquisa de código aberto usada para criar aplicativos de pesquisa. Ele é baseado no popular mecanismo de pesquisa de texto completo Lucene . O Solr é uma plataforma altamente flexível, nativa da nuvem, pronta para operações corporativas. As consultas paralelas foram habilitadas na versão mais recente do Solr, Solr 6.0, lançada em 2016. A plataforma Solr nos permite dimensionar, distribuir e gerenciar índices para aplicativos de grande escala (Big Data). Ao trabalhar com o Solr, você não precisa ser um programador com habilidades em Java. Em vez do Lucene, ele fornece um serviço muito simples e fácil de usar para criar uma caixa de pesquisa que inclui preenchimento automático.
Os muitos benefícios do Apache Sol
O mecanismo de pesquisa Apache Solr é um mecanismo de pesquisa popular entre organizações pequenas e grandes. Este software é muito versátil, permitindo que seja utilizado em diversas situações, incluindo análise e recuperação de dados. O Solr é um serviço que oferece recursos de pesquisa corporativa, tornando-o uma escolha ideal para gerenciar grandes quantidades de dados.
Solução útil de banco de dados Nosql
Existem muitas soluções úteis de banco de dados NoSQL disponíveis hoje. Os bancos de dados NoSQL geralmente são mais escaláveis e têm melhor desempenho do que os bancos de dados relacionais tradicionais. Eles também são geralmente mais flexíveis, permitindo modelagem de dados e evolução de esquema mais fáceis. Alguns bancos de dados NoSQL populares incluem MongoDB, Cassandra e HBase.
Os bancos de dados NoSQL não serão mais usados por desenvolvedores no futuro. O futuro está aqui, onde esses bancos de dados serão uma ferramenta comum para alimentar aplicativos populares. Você pode não estar ciente de que alguns aplicativos populares são executados em bancos de dados NoSQL e por que o NoSQL é ideal para esses aplicativos. Em 1996, a Forbes foi a primeira publicação de negócios a lançar um site. A Forbes está migrando seu serviço para o MongoDB Atlas para atender às necessidades de seus 140 milhões de usuários online. Por causa do impacto da pandemia de COVID-19, a publicação mudou para uma infraestrutura de nuvem e conseguiu lidar com os momentos difíceis. O BangDB foi escolhido pela Accenture para ser o banco de dados NoSQL para seu aplicativo de pontuação de leads.
O Facebook Messenger é executado no banco de dados Cassandra NoSQL sem nenhum ponto único de falha, permitindo escalar suas operações em várias plataformas. Bigtable é um componente do Google Mail que auxilia o Google Bigtable, uma empresa on-line que fornece uma variedade de transações do Google Mail. O banco de dados do Espresso garante que todos os aplicativos do LinkedIn funcionem normalmente. Baixe BangDB grátis para ver se é a ferramenta certa para você.
Os benefícios dos bancos de dados Nosql
Muitos bancos de dados NoSQL podem ser usados para armazenar e modelar dados estruturados, semiestruturados e não estruturados em um banco de dados, tornando-os ideais para armazenar e modelar estruturas e semântica de dados. Eles podem ter um desempenho melhor e ser mais estáveis do que os bancos de dados relacionais tradicionais e podem ser mais fáceis de implementar para os desenvolvedores. Com a crescente popularidade dos bancos de dados NoSQL, é provável que eles continuem a crescer em popularidade.
Mongodb »
O MongoDB é um poderoso sistema de banco de dados orientado a documentos. Possui um recurso de pesquisa baseado em índice que torna a recuperação de dados rápida e fácil. O MongoDB também oferece um recurso de escalabilidade, permitindo lidar com dados em grande escala.