
Os diferentes tipos de clusters de computador
Publicados: 2023-02-16Na computação, um cluster é um grupo de sistemas de computador independentes que trabalham juntos para que, em muitos aspectos, possam ser vistos como um único sistema. Os clusters geralmente são implantados para melhorar o desempenho e a disponibilidade em relação a um único computador, embora normalmente sejam muito mais econômicos do que computadores individuais de velocidade ou disponibilidade comparáveis. Existem diferentes tipos de clusters de computadores, incluindo clusters de computação de alto desempenho, clusters de computadores usados para fins comerciais e clusters de armazenamento. Em cada tipo de cluster, os sistemas componentes trabalham juntos para executar uma ou mais tarefas comuns. Os clusters de computação de alto desempenho (HPC) são usados para aplicativos científicos e de engenharia que exigem grande capacidade de computação e/ou armazenamento de dados. Esses clusters geralmente consistem em um grupo de computadores comuns, conectados por uma rede local (LAN) rápida. Os computadores em um cluster HPC geralmente executam o mesmo sistema operacional (SO) ou similar e possuem componentes de hardware iguais ou semelhantes. Os clusters comerciais são usados para executar aplicativos de negócios que exigem um alto grau de disponibilidade e/ou escalabilidade. Esses clusters geralmente consistem em servidores que executam uma variedade de sistemas operacionais e possuem uma variedade de componentes de hardware. Em muitos casos, os servidores em um cluster comercial também são conectados a uma rede de área de armazenamento (SAN) para que possam acessar armazenamentos de dados comuns. Clusters de armazenamento são usados para fornecer um repositório de armazenamento centralizado que pode ser acessado por um grupo de computadores. Os clusters de armazenamento geralmente consistem em um grupo de servidores de armazenamento conectados a uma SAN. Os servidores em um cluster de armazenamento geralmente executam uma variedade de sistemas operacionais e possuem vários componentes de hardware.
O que é um cluster mongodb fragmentado e qual é o objetivo de se conectar a um no MongoDB? Como faço para conectar a um ou apenas conectar ao localhost? A medalha de ouro é concedida no distintivo Noob 7461. Dez insígnias de prata e 23 insígnias de bronze foram produzidas. Um cluster replicado é composto por dez servidores, sendo um para a interface mongos, três para cada conjunto de réplicas e um para cada conjunto de réplicas do servidor de configuração. Em um sistema de replicação, um componente é duplicado para que haja sempre um backup caso algo dê errado. Todos os fragmentos devem ser réplicas para que possam ser fabricados.
Um cluster mongodb, por exemplo, é comumente usado para descrever um cluster fragmentado no MongoDB. Um mongodb fragmentado atende às seguintes funções: Scale lê e grava de vários nós. Como cada nó não manipula todo o conjunto de dados, você só pode particionar os dados em regiões no estilhaço.
Um cluster de banco de dados , como o nome sugere, é uma coleção de bancos de dados que podem ser executados por uma instância de um servidor de banco de dados em execução. Postgres, que significa banco de dados “padrão” em PostgreSQL, será incluído como banco de dados padrão em um cluster de banco de dados após sua criação.
Um cluster MongoDB também pode ser chamado de “conjunto de réplicas” ou “cluster fragmentado”. Em um conjunto de réplicas, vários servidores carregam cópias dos mesmos dados. Os nós em um conjunto de réplicas geralmente são três. Quando um aplicativo cliente executa qualquer operação em um nó, todas as leituras e gravações são enviadas para esse nó; se algo der errado, dois nós secundários o protegem.
Cluster e banco de dados são iguais?
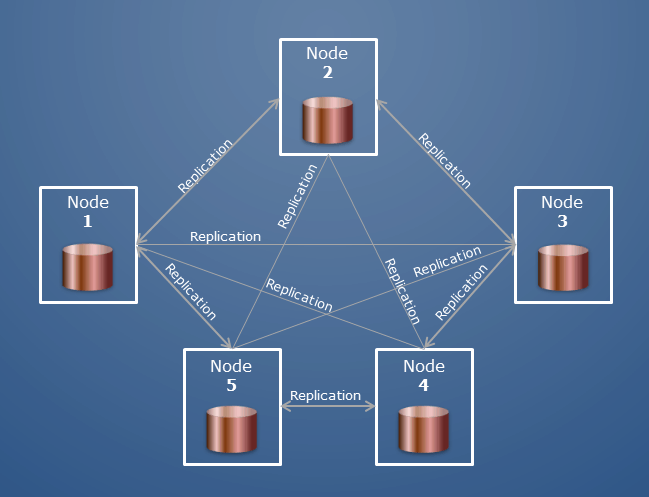
Existem vários clusters de hosts que compõem um cluster. Os hosts de um cluster fragmentado são classificados em várias funções. Um banco de dados é uma coleção de coleções; no Oracle, seria equivalente a um banco de dados e aschema.
Um cluster de banco de dados é uma coleção de servidores ou instâncias que conectam um banco de dados a outro. O agrupamento de banco de dados é usado por servidores por diversos motivos, sendo os principais redundância de dados, balanceamento de carga, alta disponibilidade e monitoramento e automação. Como resultado, se um computador falhar, todos os nossos dados estarão disponíveis para outros, dando-nos a vantagem da redundância de dados. Com o clustering, há uma oportunidade de automatizar muitos dos processos do banco de dados e, ao mesmo tempo, criar regras para identificar possíveis problemas. Na arquitetura de cluster, todas as solicitações são roteadas para vários computadores, cada um dos quais é capaz de lidar com a solicitação e produzi-la para o usuário. Um failover ou cluster de alta disponibilidade replica servidores e reconfigura o hardware para garantir a disponibilidade do serviço. Esses tipos de clusters são lucrativos para usuários de computador que dependem totalmente de seus sistemas. O objetivo dos clusters de alto desempenho é aumentar a capacidade da rede e, ao mesmo tempo, melhorar o desempenho.
Em um sistema distribuído Hadoop, os nós atuam como centros de processamento e armazenamento de dados. A principal distinção entre um cluster e um servidor é que o cluster emprega vários nós que se comunicam entre si para executar um conjunto de operações. Um cluster contém vários nós que executarão um conjunto de operações. O sistema distribuído Hadoop pode suportar até 10.000 bancos de dados. Resultados de consulta semelhantes podem ser obtidos quando dados de várias tabelas no mesmo banco de dados são combinados em uma consulta de vários bancos de dados no mesmo cluster.
Os benefícios do cluster
Usando um cluster, você pode gerenciar facilmente vários bancos de dados, fornecendo tabelas uniformes e armazenamento de colunas em todos eles. Isso melhora o desempenho e a integridade dos dados, tornando o sistema mais eficiente.
Onde está o nome do cluster no Mongodb?
Não há uma resposta definida para esta pergunta, pois o nome do cluster pode ser encontrado em locais diferentes, dependendo do tipo de cluster MongoDB que está sendo usado. Por exemplo, em um conjunto de réplicas, o nome do cluster geralmente é armazenado na coleção local.system.replset, enquanto em um cluster fragmentado ele geralmente é encontrado na coleção config.shards.
O MongoDB Atlas é uma oferta de banco de dados como serviço NoSQL do MongoDB como serviço que está disponível nas nuvens públicas do Microsoft Azure, Google Cloud Platform e Amazon Web Services. Você pode criar um cluster MongoDB funcional em questão de minutos usando seu navegador da Web favorito clicando em um link para configurá-lo. Não há necessidade de instalar software em sua estação de trabalho para se conectar à web por meio dela, e você pode usar a interface da web para fazer isso. Quando os conjuntos de réplicas do MongoDB são usados em conjunto com vários servidores MongoDB, a redundância de dados e a alta disponibilidade são garantidas. O cluster MongoDB possui capacidade adicional de operações de leitura, permitindo direcionar clientes para servidores adicionais. Em uma replicação, um ou mais membros do conjunto de réplicas são replicados de forma assíncrona do oplog do nó primário para os secundários, permitindo que o conjunto de réplicas funcione apesar de qualquer falha potencial de seus membros. No MongoDB, você pode executar operações adicionais de leitura e gravação, além dos comandos padrão de entrada e saída.
Na maioria dos casos, o nó primário é a origem de todas as operações de leitura, mas o roteamento para os secundários pode ser configurado. O risco de dados potencialmente obsoletos é maior quando o nó mais próximo é um nó secundário. Para que a gravação se propague com sucesso pelo cluster, você precisará incluir opções para gravar dados em um conjunto de réplicas do MongoDB. Como parte desse processo, uma propriedade de preocupação de gravação deve ser adicionada à inserção. Quando uma solicitação de gravação é recebida, o cluster é solicitado a reconhecer que foi bem-sucedido na grande maioria dos nós de suporte de dados. A configuração de um cluster fragmentado também permite que ele seja configurado como um conjunto de réplicas. Um conjunto de réplicas contém processos mongod primários e secundários. Se o mestre falhar, é recomendável que o número total desses processos seja ímpar para garantir que a maioria seja executada.
Os clusters do MongoDB , como o nome indica, são clusters de nós que trabalham juntos para armazenar e gerenciar dados. Ao criar um cluster MongoDB, você especifica quantos nós incluir e para o que eles devem ser configurados. Você pode conectar seu aplicativo ao cluster MongoDB com o Node depois de criado. O MongoDB Compass pode ser pensado como um driver para a biblioteca MongoDB JS ou um driver PyMongo para MongoDB. A principal vantagem de conectar seu aplicativo a um cluster é que ele pode ler e gravar dados nele. Com o MongoDB Compass, você pode explorar, modificar e visualizar seus dados de várias maneiras. Um exemplo de como você pode visualizar seus dados pode ser encontrado em uma grade, que permite observar como os dados mudam ao longo do tempo e quem está distribuindo dados em seu cluster.
Onde está o cluster no Mongodb Atlas?
Não há uma resposta definitiva para essa pergunta, pois a localização de um cluster no MongoDB Atlas pode variar dependendo de vários fatores, incluindo a região geográfica em que está localizado e as necessidades específicas do aplicativo que está alimentando. No entanto, em geral, um cluster no MongoDB Atlas pode ser encontrado na seção “Clusters” do console do MongoDB Atlas.
Um cluster pode ser um conjunto de réplicas ou um conjunto fragmentado. O número total de nós de cada projeto é limitado por uma restrição específica com base em sua gama de funções nas regiões. Cada projeto Atlas pode implantar até 25 bancos de dados. Entre em contato com os administradores do banco de dados para qualquer dúvida sobre o limite de implantação do banco de dados. A versão 1.2 do TLS é a versão TLS padrão para clusters criados após 1º de julho de 2020.

O que é um cluster no Mongodb
No MongoDB, um cluster é um grupo de servidores de banco de dados que mantém cópias dos mesmos dados. Cada servidor em um cluster é referido como um nó. Um cluster pode ter um ou mais nós.
Para que serve o agrupamento de banco de dados? O processo de conectar vários servidores ou instâncias a um único banco de dados é chamado de conexão SQL. No MongoDB, um cluster é um conjunto de réplicas ou um cluster fragmentado, dependendo do tipo de MongoDB. Examinarei cada um dos aspectos distintos desses clusters com mais profundidade nos parágrafos seguintes. Devido ao balanceamento de carga e ao número de máquinas do MongoDB, ele possui um alto nível de disponibilidade. Um cluster pode ser usado para automatizar muitos processos de banco de dados, além de permitir a criação de regras para alertar possíveis problemas. Um banco de dados MongoDB pode ser dividido em dois tipos: conjuntos de réplicas e clusters de fragmentação.
Os dados são armazenados em várias máquinas em um Shard. O método do MongoDB de fornecer escalabilidade de dados é baseado nisso. Isso reduz o tempo necessário para gerenciar grandes quantidades de dados. Devido à quantidade de dados que as réplicas fornecem, os aplicativos distribuídos também podem se beneficiar delas.
Problemas de desempenho e conflito de dados podem ocorrer se vários projetos do Atlas forem implantados no mesmo cluster. A Atlas recomenda que você use apenas um cluster gratuito por projeto Atlas. Uma boa ferramenta de agrupamento de dados é necessária em uma ampla variedade de aplicativos de análise e mineração de dados. Para evitar possíveis problemas de desempenho e conflitos de dados em projetos do Atlas, o Atlas recomenda que você use apenas um cluster gratuito por projeto.
Arquitetura de cluster do Mongodb
Um cluster MongoDB é um grupo de servidores MongoDB que trabalham juntos para manter seus dados. Cada servidor em um cluster é chamado de nó. Um cluster pode ter qualquer número de nós. Um cluster é formado por um conjunto de réplicas, que é um grupo de nós, cada um com uma cópia de seus dados. Um conjunto de réplicas tem pelo menos três nós, de modo que, se um nó ficar inativo, seus dados ainda estarão disponíveis.
A arquitetura dos conjuntos de réplicas é um fator importante na capacidade e funcionalidade do MongoDB. Os clusters do MongoDB são normalmente distribuídos em três réplicas de nós. A recuperação do banco de dados após um desastre deve ser constantemente estável, especialmente no rescaldo. Uma das melhores maneiras de implantar um cluster fragmentado é usar uma estratégia de replicação. Os dados contidos nas Shard Keys devem ser distribuídos da mesma forma. Você deve dimensionar o banco de dados horizontalmente e reduzir o número de operações que podem ser executadas em uma única instância. Com poucos fragmentos, as operações de leitura e gravação podem se tornar lentas devido ao fato de que o número de fragmentos limita o número de operações.
Cada parte dos dados em um fragmento é composta por um subconjunto dessa parte com base em um conjunto específico de critérios. É comum que o número mínimo de shards necessários para atingir a significância de sharding seja dois. As consultas Scatter-gather só devem ser usadas se puderem ser usadas simultaneamente umas com as outras em todos os estilhaços. Ao selecionar um cluster, é fundamental ter pelo menos sete membros votantes para que o processo de eleição seja o mais simples possível. Se você tiver apenas sete ou menos membros votantes, mas um número igual de membros, o árbitro deve ser usado. Os árbitros não armazenam cópias de dados, resultando em menos recursos necessários para processar os dados. O uso do nome de host DNS lógico em vez do endereço IP é preferencial ao configurar membros do conjunto de réplicas ou membros de cluster fragmentados. Como algumas conexões de conjuntos de réplicas de grupos de drivers são por nomes de conjuntos de réplicas, esses nomes devem ser usados separadamente para os conjuntos. A distribuição geográfica dos nós do conjunto de réplicas é ideal para lidar com redundância redundante e garantir tolerância a falhas se um dos datacenters estiver ausente.
Nome do cluster Mongodb
Um cluster MongoDB é um grupo de servidores MongoDB que trabalham juntos para fornecer alta disponibilidade e escalabilidade. Um cluster normalmente tem um servidor principal que atua como servidor mestre e um ou mais servidores secundários que atuam como escravos. O servidor principal contém os dados e os servidores secundários copiam os dados do servidor principal.
Programas de banco de dados orientados a documentos são criados para armazenamento de alto volume com a ajuda do MongoDB, um programa de plataforma cruzada. O MongoDB, um programa de banco de dados NoSQL, é classificado como tal porque emprega documentos no estilo JSON com esquemas opcionais. Você pode melhorar o desempenho instalando seu banco de dados no mesmo datacenter que seus outros recursos da DigitalOcean. A região tem um ou mais datacenters e cada um tem sua própria rede VPC. O tipo de máquina, número e tamanho dos nós do banco de dados podem ser selecionados. Em outras palavras, você pode adicionar até dois nós de espera ao seu cluster. Adicione um nome de projeto, torne-o completo e use quaisquer tags que desejar ao criá-lo. Um cluster pode levar até cinco minutos para ser concluído.
O poder do agrupamento Mongodb Atlas
O MongoDB Atlas Cluster é uma solução de banco de dados como serviço NoSQL na nuvem pública executada no MongoDB. É uma plataforma de dados robusta e escalável que permite criar e implantar aplicativos rapidamente. Ao usar o MongoDB Atlas Cluster, você pode se conectar com segurança ao MongoDB de qualquer local do mundo.
Como criar um cluster no Mongodb
Use as etapas a seguir para criar um cluster no MongoDB:
1. Escolha uma topologia de implantação.
2. Selecione o tipo de conjunto de réplicas que deseja implantar.
3. Escolha o número de conjuntos de réplicas que deseja implantar.
4. Configure os conjuntos de réplicas.
5. Conecte-se ao roteador mongos.
6. Configure a chave de fragmentação.
7. Adicione fragmentos ao cluster.
8. Verifique se o cluster está operacional.
O MongoDB Atlas é um nível gratuito do MongoDB, que é o serviço de banco de dados em nuvem totalmente gerenciado do MongoDB. O serviço é projetado para cargas de trabalho corporativas, bem como clusters globais . Você não precisa criar uma conta com Amazon Web Services (AWS), Google Cloud Platform ou Microsoft Azure. Ele solicitará que você crie uma conta de administrador para acessar o serviço. Para acessar o serviço, um cluster deve estar vinculado a um endereço IP. As configurações de segurança padrão do MongoDB Atlas impedem todas as conexões externas. Sua senha não deve conter caracteres especiais e apenas caracteres alfanuméricos para facilitar a conexão com o Studio 3T. Ao criar uma string de conexão para o MongoDB, os caracteres especiais devem ser codificados. Na Etapa 1, escolha Java na lista suspensa DRIVER e, em seguida, na lista suspensa VERSÃO. Se você selecionar o driver e a versão, o serviço atualizará automaticamente a string de conexão na Etapa 2.
Cluster Mongodb: uma ótima opção para throughput de alta demanda
Usando o clustering do MongoDB , você pode atender aos requisitos de alta taxa de transferência, disponibilidade e taxa de transferência para grandes ambientes. Os clusters do MongoDB podem ser configurados para oferecer suporte a uma ampla variedade de tipos de conjunto de réplicas do MongoDB, desde configurações simples de nó único até configurações de vários nós altamente disponíveis.
Tutorial do cluster Mongodb
Um cluster MongoDB é um grupo de servidores MongoDB que trabalham juntos para manter seus dados. Um cluster MongoDB pode ser tão pequeno quanto um único servidor ou tão grande quanto centenas de servidores. Ao criar um cluster MongoDB, você especifica o número de servidores (nós) que deseja no cluster. Cada nó em um cluster MongoDB armazena um subconjunto de seus dados. Os clusters do MongoDB são projetados para serem escaláveis e fornecer alta disponibilidade. Você pode adicionar nós a um cluster a qualquer momento para aumentar sua capacidade ou substituir um nó com falha. Quando você remove um nó de um cluster, os outros nós redistribuem os dados do nó removido para que os dados ainda sejam distribuídos uniformemente no cluster.
O Easy Guide to MongoDB Clustering da Hevo é o primeiro passo. Quando um banco de dados é muito pequeno ou muito lento para executar um sistema, as operações de uma organização continuam. O MongoDB possui vários recursos avançados que foram projetados para a nuvem, como sharding e replicação. O MongoDB possibilita o armazenamento de várias cópias dos mesmos dados, tornando-os extremamente acessíveis. Se um servidor falhar, os dados do outro podem ser recuperados imediatamente. Você pode automatizar, simplificar e enriquecer o processo de replicação de dados usando o Hevo Data. A replicação de dados é simples e fácil de usar quando você tem acesso ao nosso teste gratuito de 14 dias.
Para configurar clusters do MongoDB, você deve primeiro instalar todos os três componentes necessários. Com a plataforma automatizada e sem código da Hevo, você pode acompanhar tudo o que precisa fazer para uma experiência de replicação de dados tranquila. Para garantir a disponibilidade máxima, vários servidores ou roteadores de configuração devem estar presentes. Quando o roteador determina em qual fragmento os dados estão alojados, ele envia solicitações para o cluster apropriado. No processo de estabelecimento de clusters do MongoDB, as etapas a seguir serão necessárias para adicionar shards a eles. Em uma configuração em cluster, a porta 27018 é usada como padrão para os servidores de fragmentos. Isso significa que é um servidor de fragmentos em vez de um servidor de configuração.